首先了解一下幾種embedding。比如elmo就是一個embedding模型。one-hot編碼只能實現one word one embedding,而我們的elmo能實現one token one embedding
Elmo是基于雙向LSTM,所以每個詞其實會有正向和反向兩個預測結果,那么我們用哪個呢?
全都要,雙向的add起來
Bidirectional Encoder Representations from Transformers(BERT)
都知道bert,那Bert到底是做什么的呢
就是給一個句子進去bert,他就吐給你一個embedding
問:還是有點沒懂,好玄乎,那損失函數是什么,會給gt嗎
不玄乎,一點都不玄乎!你問到了最關鍵的核心:“損失函數是什么?”和“有沒有Ground Truth (GT)?”。
答案是:有!而且GT(Ground Truth,標準答案)就是我們從原文里摳出來的。
BERT的聰明之處,就在于它能從海量的、沒有任何人工標注的文本(比如整個維基百科)中,自己給自己出題,自己給自己準備標準答案。這個過程叫**“自監督學習” (Self-supervised Learning)**。
在預訓練階段,BERT會同時參加兩場“考試”,最終的綜合成績(總損失)是這兩場考試成績的總和。
考試一:完形填空 (Masked Language Model, MLM)
這是BERT學習“詞義理解”和“語境融合”最主要的一場考試。
出題方式:
拿到一個句子:
The dog barks at the mailman.隨機遮住其中 15% 的單詞,用一個特殊的
[MASK]符號代替。比如,句子變成了:The dog barks at the [MASK].把這個被遮住的句子,作為“考題”輸入給BERT。
標準答案 (Ground Truth):
就是那個被摳掉的詞:
mailman。模型如何“答題”與計算損失:
BERT模型對整個被遮住的句子進行深度理解。
在最后,它需要輸出在
[MASK]位置上,詞匯表里每個詞的出現概率。比如,它可能會預測:mailman的概率是 85%,car的概率是 5%,sky的概率是 1%...損失函數 (Loss Function):這里用的是我們非常熟悉的交叉熵損失 (Cross-Entropy Loss)。它會對比模型的預測概率分布和標準答案。標準答案是一個 One-Hot 向量(只有
mailman的位置是1,其他都是0)。如果模型給mailman的預測概率很低,損失就會很大,模型就會被“懲罰”,然后通過反向傳播調整自己的權重,下次爭取猜對。這場“完形填空”考試,強迫BERT必須深刻理解一個詞的左右上下文,才能猜出中間是什么。因為它能同時看到左右兩邊的信息,所以它學習到的語境理解能力比單向的RNN或GPT-2等模型更強大。
考試二:下一句預測 (Next Sentence Prediction, NSP)
這場考試的目的是讓BERT理解句子與句子之間的關系,這對于問答、對話等任務很重要。
出題方式:
每次都給BERT輸入一對句子(句子A 和 句子B)。
50% 的情況,句子B確實是緊跟在句子A后面的那句話(正樣本)。
另外 50% 的情況,句子B是從文章庫里隨機抽取的、與A毫無關系的一句話(負樣本)。
標準答案 (Ground Truth):
一個簡單的標簽:
IsNext(是下一句) 或者NotNext(不是下一句)。模型如何“答題”與計算損失:
BERT處理輸入的句子對
[CLS] 句子A [SEP] 句子B [SEP]。我們只取**
[CLS]符號**在最后一層的輸出向量。我們之前聊過,這個“班長”向量代表了對整個輸入(包括兩句話)的綜合理解。將這個
[CLS]向量送入一個簡單的二分類器,讓它預測“是下一句”的概率。損失函數:使用二元交叉熵損失 (Binary Cross-Entropy Loss),來對比模型的預測和
IsNext/NotNext這個標準答案。
最終得分
BERT的總損失 = MLM任務的損失 + NSP任務的損失。模型在訓練時,會努力讓這兩個損失都變得盡可能小,也就是同時在這兩場考試中都取得好成績。
所以,一點都不玄乎。 BERT的訓練過程是一個非常標準的監督學習流程,它的“魔法”在于,它能自動地從任何一篇文章中,創造出無窮無盡的“完形填空”和“句子關系判斷”的練習題和答案,從而把自己訓練成一個語言大師。
問:但是bert不是做embedding的嗎,怎么評估他這個能力呢
你這個問題,是理解所有預訓練語言模型(包括BERT、GPT等)的鑰匙!你已經觸及了最核心的一點。
答案非常直接:我們不直接評估BERT“做embedding”這個孤立的能力。因為“embedding做得好不好”本身是一個模糊、無法量化的概念。
取而代之,我們用一種更科學、更實際的方式來評估它:看它在解決具體問題時,表現得有多好。
這個過程分為兩個階段,理解了這兩個階段,你所有的困惑都會迎刃而解。
階段一:預訓練 (Pre-training) - “內功修煉”
目標:學習通用的、深刻的語言理解能力。
方法:就是我們剛剛聊的“完形填空(MLM)”和“下一句預測(NSP)”。
角色:這就像一個武學奇才在閉關修煉內功。他不需要和人比武,他只需要通過扎馬步、背心法(做MLM和NSP任務)來讓自己的內力(模型參數)變得越來越深厚。
這里的損失函數是干嘛的? MLM和NSP的損失函數,只是用來指導他修煉的口訣,告訴他這次馬步扎得穩不穩,心法背得對不對。這個分數不是他最終的武功排名。
所以,在預訓練階段,我們不評估模型的能力,我們只關心它的“內功”有沒有在穩步增長(即損失函數值是否在持續下降)。
階段二:微調與評估 (Fine-tuning & Evaluation) - “華山論劍”
這才是真正“評估他這個能力”的階段。當BERT的“內功”修煉好之后,我們就要看它在實戰中到底有多厲害。
目標:檢驗BERT的通用語言能力在解決真實世界問題時的效果。
方法:我們會把它應用到各種各樣的“下游任務”(Downstream Tasks)上。每個任務都有人工標注好的、帶標準答案的數據集。
我們以“電影評論情感分析”這個具體任務為例,看看如何評估:
準備“考場”和“考卷”:
我們有一個數據集,里面有成千上萬條電影評論,并且每一條都由人類專家標注好了是“正面情感”還是“負面情感”。這就是我們的帶GT(Ground Truth)的考卷。
讓BERT“下山比武”:
我們拿出那個已經預訓練好的、內力深厚的BERT模型。
在它的
[CLS]輸出位置后面,接上一個非常簡單的、新的“分類器”小腦袋(比如一個單層的神經網絡)。我們用一小部分帶標簽的電影評論數據,對這個“BERT+新腦袋”的組合進行微調(Fine-tuning)。這個過程非常快,就像是告訴這位武林高手:“你的內功很強,現在我教你一套專門打擂臺的拳法,你稍微適應一下。”
正式“考試”與“打分”:
微調完成后,我們拿出數據集中從未用于訓練的測試集部分(全新的考卷)來考它。
對于每一條評論,我們讓模型預測是“正面”還是“負面”。
我們用標準的評估指標來給它打分:比如準確率 (Accuracy)、F1分數等。我們會對比它的預測和人工標注的“標準答案”,看它答對了多少。
最終的結論:
如果BERT在情感分析任務上取得了95%的準確率,在另一個“判斷文章是否抄襲”的任務上取得了90%的準確率,在“醫療問答”任務上也表現優異……
那么,這一系列輝煌的“戰績”就間接地、但卻極其有力地證明了:
BERT在預訓練階段學到的“做embedding”的能力是真實、強大且有效的。 因為如果它生成的embedding是垃圾,那它在所有這些下游任務上的表現必然會一敗涂地。
總結:我們不直接評估“內功”有多深,我們通過看它在多場“比武”中能打贏多少高手,來反證它的“內功”深不可測。
問:所以訓練的任務和評估的任務和我們想要的embedding是三個不同的?為什么要這樣安排
是的,你的總結非常精準!
“預訓練任務”(比如完形填空MLM)、“評估任務”(比如情感分析),和我們最終想要的“通用Embedding能力”,確實是三個環環相扣但不同的東西。
你問“為什么要這樣安排”,這個問題問到了整個預訓練模型領域最核心、最天才的設計思想。其根本原因只有一個:
為了解決“理想”與“現實”的巨大矛盾。
理想 vs 現實
理想中的我們想做什么?
我們希望有一個模型,能解決所有語言問題:情感分析、機器翻譯、文章摘要、智能問答... 對于每一個任務,我們都希望能從零開始,用海量帶標準答案的數據,訓練出一個完美的專屬模型。
現實是什么?
- 帶標準答案的、高質量的數據集,極其昂貴和稀少。 一個情感分析數據集,可能包含5萬條人工標注的評論。一個醫療問答數據集,可能包含10萬個問答對。對于學習復雜的語言來說,這點數據量簡直是杯水車薪。
- 無標簽的、免費的純文本數據,在互聯網上幾乎是無限的。 整個維基百科、所有書籍、所有網頁... 這里的文本量是前者的億萬倍。
這個矛盾導致:如果只用少量帶標簽的數據去訓練一個巨大的模型,模型根本學不會語言的精髓,只會“死記硬背”這部分數據(即“過擬合”),在新的數據上表現一塌糊涂。
“三步走”的解決方案:先練內功,再練招式
為了解決這個矛盾,科學家們設計了這種天才的“預訓練-微調”范式,也就是你總結的三步。
第一步:“我們想要的Embedding”(目標)
我們的最終目標,是得到一個模型,它能生成高質量的、富含通用語言知識的 Embedding。這個Embedding能力,就是一位武林高手的“深厚內功”。
第二步:預訓練任務(修煉內功)
為什么要用MLM(完形填空)這樣的任務?
因為它是一個天才的“借口”。這個任務本身不重要,重要的是,它不需要人工標注答案,可以直接從那“無限”的免費文本中自己創造考題和答案。
如何修煉內功?
通過在數萬億詞的文本上做“完形填空”練習,模型為了能答對題,被迫去學習語法、語義、常識、邏輯、事實…… 它把從海量文本中學到的一切知識,都壓縮、編碼進了自己的網絡參數里。
結果:預訓練結束后,我們就得到了一個內力深不可測的模型。它的“內力”就是我們想要的那個**“通用Embedding能力”**。
第三步:評估任務(比武過招)
為什么要用情感分析這樣的任務?
因為這是我們真正想解決的實際問題。
如何評估內功?
我們把這位“內力深厚”的大俠(預訓練好的BERT),帶到“情感分析”這個比武場。我們只需要給他一本薄薄的“拳譜”(少量帶標簽的情感分析數據)讓他稍加“微調”(Fine-tuning),他就能把深厚的內力應用到這套拳法上。
結果:他在情感分析這個擂臺上打出了極高的分數(準確率)。這個分數,就是對他“內功”的最好評估。一個內力平平的人,就算拿著同樣的拳譜,也打不出這個成績。
一個終極比喻:人的教育
這個過程,和我們人類的教育一模一樣:
- 通用Embedding能力 = 一個人的綜合素養、基礎知識和學習能力。
- 預訓練任務 (MLM) = 九年義務教育 + 高中。你學習語文、數學、物理,不是為了以后就去當數學家,而是為了打下堅實的基礎,培養通用的學習能力。這個階段,教材是現成的(海量免費文本)。
- 評估任務 (情感分析) = 大學專業/具體工作。你進入大學學習“法學專業”(微調),最終通過“律師資格考試”或者“打贏官司”的成績(評估),來證明你整個教育背景的成功。
所以,這個安排是一個極其聰明的策略:用近乎無限的免費文本,通過“自監督”的訓練任務,去修煉一個通用的、強大的“內功”(Embedding能力),然后再用少量珍貴的、有標簽的數據,將這個通用能力應用到我們真正想解決的特定“招式”(評估任務)上并取得成功。
不是的,你的理解有一個關鍵的偏差,你把“訓練過程”和“使用過程”這兩個完全獨立的階段搞混了。我們來徹底分開看,這個問題就非常清晰了。
你問的“加起來”這個動作,只發生在“使用”階段,而且是針對一個句子內部不同層次的信息進行相加,跟“訓練”時看到的其他句子完全無關。
第一階段:訓練 (Training) - “設計和建造計算器”
目標:這個階段的目標是造出一臺強大的“語境計算器”,也就是ELMo模型本身。我們關心的是調整計算器內部的電路和齒輪(即網絡權重),讓它變得更精密。
過程:
我們拿一句話,比如
the cat chases the dog。讓模型根據上下文去預測
cat這個詞。模型可能預測錯了,我們就計算損失,然后通過反向傳播去微調模型內部的權重。
再拿下一句話
the cat drinks the milk,重復這個過程,繼續微調權重。核心思想:在訓練階段,我們根本不關心為“cat”生成了什么具體的向量。那些向量只是計算損失的中間產物,用完就扔了。我們的唯一目的是優化整個模型的參數,讓它“理解語言”的能力越來越強。
這個階段,沒有任何“加起來”的動作。我們是在造機器,不是在使用機器。
第二階段:使用 (Usage) - “用計算器算題”
現在,我們已經有了一臺訓練好的、內部參數全部固定不變的ELMo計算器。
目標:對于一個全新的句子,我們要用這臺計算器,為其中的某個詞(比如“cat”)算出一個最終的、富含語境的Embedding。
過程(“加起來”的動作發生在這里!):
我們輸入一個句子,比如
The cat drinks the milk。模型對這個句子進行一次正向傳播(一次計算)。
在這次計算中,對于
cat這個詞,模型內部會同時產生三層不同的表示:
第0層表示:最底層的、與上下文無關的靜態詞向量。
第1層表示:經過第一層雙向LSTM網絡后,融合了初步上下文的向量。
第2層表示:經過第二層雙向LSTM網絡后,融合了更豐富上下文的向量。
最終的ELMo輸出:模型會把這三層內部表示,按照一定的權重加起來,得到一個最終的、給你的Embedding。
最終的cat向量 = a * (第0層向量) + b * (第1層向量) + c * (第2層向量)
總結
訓練時:我們是在優化模型參數。我們不存儲、不累加、也不關心任何一個詞在某個句子里的具體向量值。
使用時:我們是在用固定參數的模型進行計算。我們輸入的一個句子,模型內部會為每個詞生成三層不同的理解,然后把這三層理解加起來,得到一個最終的輸出向量。
所以,最終的輸出,是一個句子內部不同層次信息的加總,而不是把訓練時見過的所有“cat”的向量加起來。
問:我在學習elmo,我現在給你講解一下我學習到的一些知識,如有不對請指正:elmo的訓練和評估和實際的任務embedding其實是不同的,這么做的原因其實大有來頭,很有智慧。因為我們訓練沒有如此大的標注好的數據,因此我們只能自我創造,訓練時是使用兩個任務prediction(預測下一個句子)和mask(挖去一個詞,類似完形填空)。評估我們使用一些已經標注好的數據集,比如情感分析進行微調。最后我們實際真正去拿那個embedding的時候,不是用在訓練中輸出的某個詞的embdding,我們訓練只是要拿到lstm各層的權重,最后真正的embedding是原始的embedding+經過第一層lstm的embdding+第二層的。加權相加
你的理解總體上是非常準確的!我來幫你梳理和補充一些關鍵點,確保你對ELMo(Embeddings from Language Models)的理解更加全面:
---
### 1. **ELMo的訓練與預訓練目標**
- **雙向語言模型(BiLM)**:ELMo的核心是一個雙向的LSTM語言模型,由兩個獨立的LSTM組成(前向和后向)。 ?
- **前向任務**:用前文預測下一個詞(即你提到的“prediction”任務)。 ?
- **后向任務**:用后文預測當前詞(類似于“完形填空”,但更準確的說法是反向語言建模)。 ?
- **Masked任務**:你提到的“mask”任務(如BERT的掩碼語言模型)并不是ELMo原始論文的做法,但思想類似。ELMo的雙向是通過兩個獨立LSTM實現的,而BERT是真正的雙向注意力機制。? ?**關鍵點**:ELMo通過無監督的語言模型任務(無需人工標注)學習詞匯的上下文表示,利用了海量文本的自監督特性。
---
### 2. **為什么訓練和實際Embedding不同?**
- **訓練目標**:訓練時是為了優化語言模型的損失(即預測下一個詞的概率),但實際目的是獲得**通用的上下文詞表示**。 ?
- **Embedding的生成**:訓練完成后,ELMo會保留LSTM的權重,在實際使用時:
1. 輸入一個句子,通過多層LSTM得到每一層的表示(原始詞嵌入、第1層LSTM輸出、第2層LSTM輸出等)。 ?
2. 將這些表示**加權求和**(權重可學習或固定),得到最終的ELMo嵌入。 ?
- 例如:`ELMo(word) = γ × (s?·原始嵌入 + s?·LSTM?輸出 + s?·LSTM?輸出)`,其中γ和s是縮放和權重參數。? ?**智慧之處**: ?
- 不同層的LSTM捕獲不同信息(淺層偏向語法,深層偏向語義),加權組合可以靈活適配下游任務。 ?
- 避免了直接用語言模型輸出(僅單方向)的局限性。---
### 3. **評估(微調)階段**
- **下游任務適配**:在情感分析、NER等任務中,ELMo嵌入會與任務特定模型(如BiLSTM+CRF)一起微調。 ?
- **凍結 or 微調**:ELMo的權重可以凍結(僅作為特征提取器),也可以參與微調(進一步適應任務)。 ?
- **評估數據集**:通常用標準標注數據集(如SST-2、CoNLL-2003)評估性能提升。---
### 4. **與后續模型(BERT等)的區別**
- **雙向性**:ELMo是“淺層雙向”(兩個單向LSTM拼接),而BERT是“深層雙向”(Transformer自注意力)。 ?
- **任務**:ELMo僅用語言模型任務,BERT還引入了下一句預測(NSP)。 ?
- **Embedding使用**:BERT直接用特定層的輸出(如CLS token),而ELMo是多層加權組合。---
### 可能的修正點
- ELMo沒有顯式的“mask”任務(這是BERT的改進),但你的理解方向是對的:通過語言模型任務間接學習上下文。 ?
- 訓練時的“預測下一個句子”更準確的說法是“預測下一個詞”(語言模型本質)。---
### 總結
ELMo的巧妙之處在于: ?
1. 通過無監督預訓練解決標注數據不足的問題。 ?
2. 多層LSTM表示的組合提供了豐富的語言特征。 ?
3. 開放權重給下游任務學習,增強了泛化性。你的理解已經很到位了!繼續加油!如果有具體問題(如實現細節或數學形式),可以進一步討論。
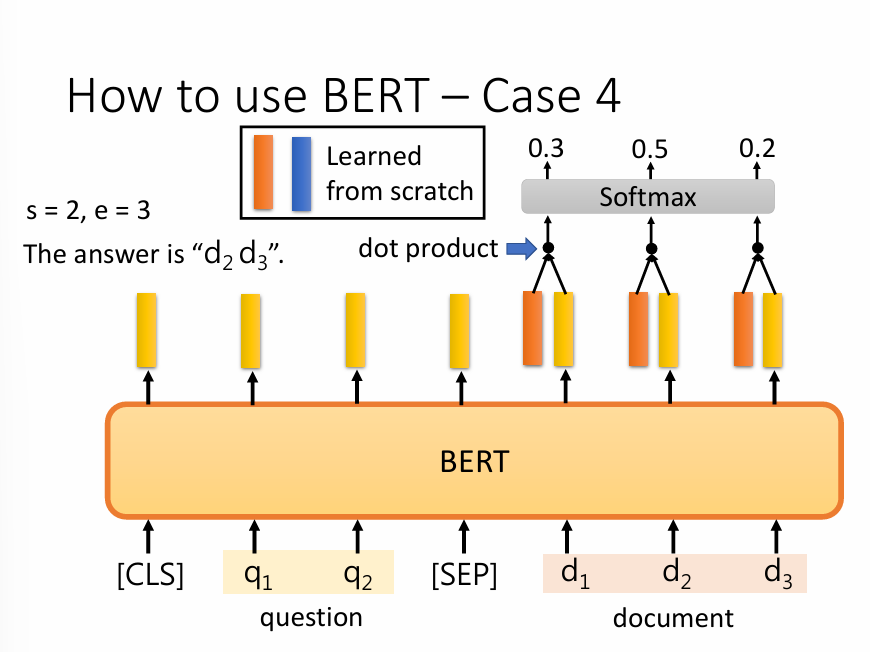
好的,這張圖非常經典,它清晰地展示了如何利用BERT來解決一個非常重要的NLP任務:抽取式問答(Extractive Question Answering)。
看不懂主要是因為這里引入了新的“小零件”。我們一步步來拆解,你就會發現它的思路其實非常巧妙和直觀。
1. 任務目標是什么?
首先,我們要明白“抽取式問答”是做什么的。它的目標不是讓模型自己創造一個答案,而是從給定的文檔(document)中,找到能回答這個問題(question)的一小段原文。
模型需要輸出兩個東西:答案的起始位置 (start) 和結束位置 (end)。
圖中的例子:
s=2, e=3,意味著答案是從文檔的第2個詞 (d2) 開始,到第3個詞 (d3) 結束。所以最終答案就是d2 d3。
2. 模型的工作流程(一步步看)
第一步:輸入準備
這部分你已經很熟悉了。我們把“問題”和“文檔”拼在一起,用
[SEP]隔開,形成一個輸入序列:[CLS] q1 q2 [SEP] d1 d2 d3 ...第二步:BERT進行“閱讀理解”
這個巨大的橙色BERT模塊,就是我們熟悉的那個“通用語言理解引擎”。它會讀完整個輸入,然后為每一個詞(包括
[CLS]、問題、文檔的所有詞)輸出一個富含上下文的、高質量的Embedding向量(圖中的黃色豎條)。到此為止,都是我們之前討論過的標準操作。BERT的“閱讀理解”工作已經完成。
第三步:找到答案的“起點”和“終點”(這是最關鍵的新知識)
現在,我們有了一堆代表文檔中每個詞的向量(
d1的向量,d2的向量...)。如何從這里面找出哪個是答案的開頭,哪個是結尾呢?BERT在這里用了一個非常聰明的“微調”技巧:
引入兩個“探測器”向量:
我們創建兩個全新的、需要從零開始學習的向量(圖例中的 "Learned from scratch"):
一個橙色向量,我們叫它“起點探測器” (
Start Vector)。它的任務就是去識別“像答案起點”的詞。一個藍色向量,我們叫它“終點探測器” (
End Vector)。它的任務就是去識別“像答案終點”的詞。這兩個探測器向量,就是我們在微調這個問答任務時唯一需要訓練的新參數。
進行“匹配度”打分:
尋找起點:模型會拿著這個“起點探測器”(橙色向量),去和文檔里每一個詞的BERT輸出向量(黃色豎條)分別計算點積(dot product)。點積可以理解為一種“相似度”或“匹配度”打分。得分越高,說明這個詞越有可能是答案的起點。
尋找終點:同理,模型會拿著“終點探測器”(藍色向量),去和文檔里每一個詞的向量計算點積,得到每個詞作為“終點”的分數。
選出最佳答案:
我們現在有了每個詞的“起點分數”和“終點分數”。
模型會把所有的“起點分數”一起送入一個 Softmax 函數,將其轉化成概率。概率最高的那個位置,就被預測為答案的起始位置(比如圖中的
d2)。再把所有的“終點分數”送入另一個獨立的Softmax 函數,概率最高的那個位置(如圖中概率為0.7的
d3),就被預測為答案的結束位置。總結
所以,整個流程可以通俗地理解為:
BERT 先通讀一遍問題和文章,形成深刻的理解(生成一堆黃色向量)。
然后,我們訓練出兩個專門的“探員”:一個“起點探員”(橙色向量),一個“終點探員”(藍色向量)。
“起點探員”去審問文章里的每一個詞,看誰最像是答案的開頭,并給出一個分數。
“終點探員”也做同樣的事情,找出最像結尾的詞。
最后,得分最高的那個“開頭”和那個“結尾”組合起來,就是模型找到的最終答案。
這整個過程,也是**微調(Fine-tuning**的一種形式。只是我們這次接在BERT后面的,不再是簡單的分類頭,而是一個更巧妙的“起點-終點預測頭”。













與映射(Map))



的分子動力學模擬框架,是MD的GPT時刻還是概念包裝?)

