模擬面試-C++
第一題(開發音視頻處理模塊)
在開發音視頻處理模塊時,FFmpeg資源(AVFrame*)需要自動釋放。如何用unique_ptr定制刪除器替代手動av_frame_free()?寫出代碼并解釋RAII優勢。
參考答案:
auto frame_deleter=[](AVFrame* ptr){av_frame_free(&ptr);}; std::unique_ptr<AVFrame,decltypt(frame_deleter)>frame(av_frame_alloc(),frame_deleter);優勢:
異常安全:函數提前退出時自動釋放資源
所有權明確:禁止拷貝,轉移需用std::move
第二題(日志系統需要創建LogEntry對象)
日志系統需要創建LogEntry對象,其構造函數含std::string初始化。為何用emplace_back替代push_back可提升性能?移動語義在此過程如何生效?
=====================================================================參考答案:
push_back問題:先構造臨時對象,再移動/拷貝到容器
emplace_back優化:直接在容器內存構造對象(完美轉發參數)
//性能對比 std::vector<LogEntry> logs; logs.push_back(LogEntry("Error", 404)); // 1次構造+1次移動 logs.emplace_back("Error", 404); // 僅1次構造移動語義的作用:減少對象傳遞的開銷
移動語義允許對象的資源(如
std::string的底層字符數組)在不同對象間轉移所有權,而非深拷貝。當使用push_back時:
- 若傳入臨時對象(右值),編譯器會優先調用移動構造函數,將資源從臨時對象轉移到容器元素中(O(1)開銷)。
- 若傳入左值對象,則仍需調用拷貝構造函數(O(n)開銷,n為字符串長度)。
LogEntry(LogEntry&& other) noexcept: message(std::move(other.message)), // 轉移string資源,而非拷貝code(other.code) {}第三題(兩個類Device和Controller互相持有shared_ptr)
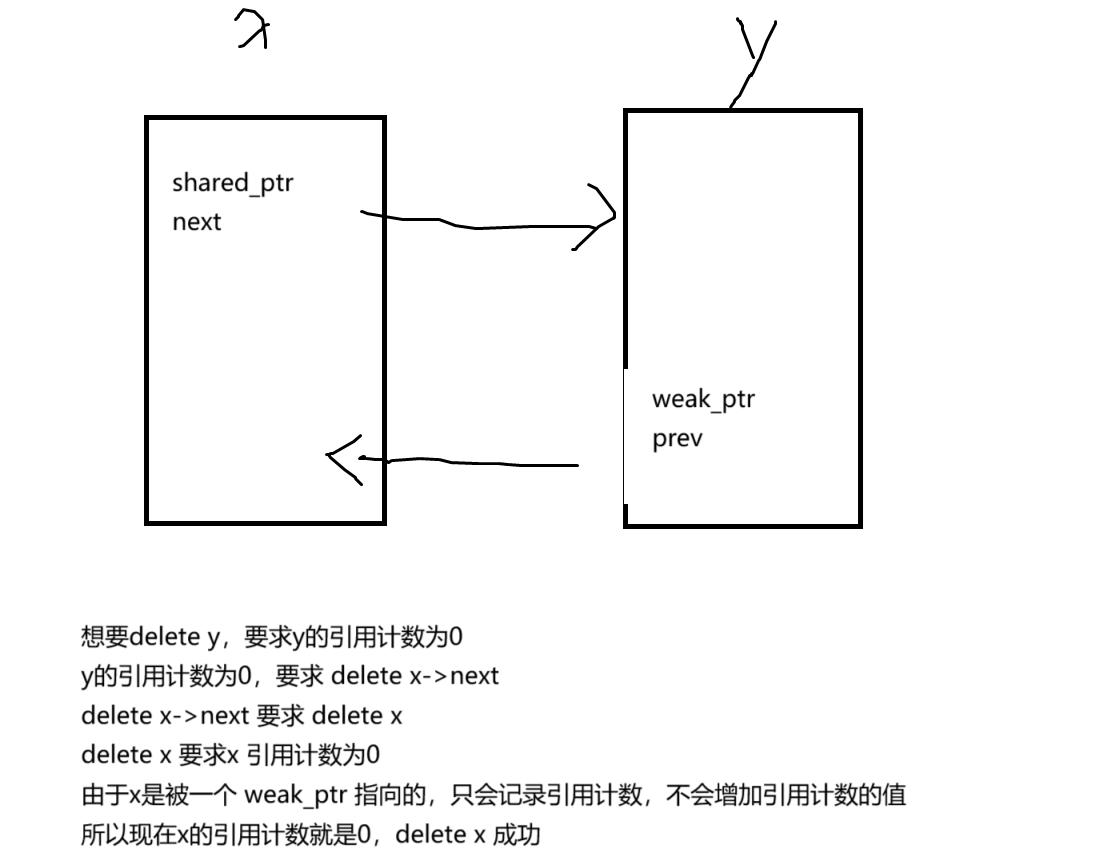
兩個類Device和Controller互相持有shared_ptr,導致內存泄漏。如何用weak_ptr打破循環引用?畫出引用計數變化圖。
=====================================================================
參考答案:
class Controller { public:std::shared_ptr<Device> dev; // 強引用 };class Device { public:std::weak_ptr<Controller> ctrl; // 弱引用不增加計數 };弱智能指針:專門用來解決循環引用問題的一個智能指針
weak_ptr 雖然有引用計數,但是被 weak_ptr 指向的地址,僅僅會被 weak_ptr 觀察并記錄引用計數的值,并不會增加
weak_ptr 的特點
weak_ptr 是專門、也只能用來解決 shared_ptr 循環引用的問題
所以 weak_ptr 是沒有任何針對指針的操作
說人話就是:weak_ptr 沒有重載 operator* 和 operator-> 函數使用時候,將weak_ptr 臨時轉換成 shared_ptr
使用 weak_ptr 里面一個叫做 lock的函數
通過lokc函數轉換出來的shared_ptr也是一個臨時的shared_ptr,用完就會被釋放,不影響引用計數weak_ptr<int> p2=p1;//弱智能指針可以直接指向共享智能指針,并獲取該共享智能指針的引用計數,但是不會+1; cout<<*p2.lock()<<endl;
第四題(游戲引擎需頻繁創建/銷毀Enemy對象)
游戲引擎需頻繁創建/銷毀Enemy對象,直接new/delete導致內存碎片。如何用placement new和內存池優化?說明避免malloc次數統計的方法。
=====================================================================
參考答案:
核心步驟: 01.預分配大塊內存:char* pool = new char[POOL_SIZE] 02.對象構造:Enemy* e = new (pool + offset) Enemy() 03.手動析構:e->~Enemy() 04.統計技巧:重載類專屬operator new/delete一、內存池核心設計:預分配+內存塊管理
1. 預分配大塊內存
const size_t POOL_SIZE = 1024 * 1024; // 1MB內存池 const size_t OBJECT_SIZE = sizeof(Enemy); char* memory_pool = new char[POOL_SIZE]; // 預分配連續內存 char* free_ptr = memory_pool; // 空閑內存指針2. 空閑塊管理(鏈表法)
struct FreeBlock { FreeBlock* next; }; FreeBlock* free_list = reinterpret_cast<FreeBlock*>(memory_pool);// 初始化空閑鏈表(將內存池分割為OBJECT_SIZE大小的塊) for (size_t i = 0; i < POOL_SIZE / OBJECT_SIZE - 1; ++i) {free_list[i].next = &free_list[i + 1]; } free_list[POOL_SIZE / OBJECT_SIZE - 1].next = nullptr;二、placement new:在指定內存地址構造對象
1. 分配對象(從內存池獲取內存)
Enemy* create_enemy() {if (free_list == nullptr) {// 內存池耗盡,可擴容或返回nullptrreturn nullptr;}// 1. 獲取空閑塊地址void* mem = free_list;free_list = free_list->next;// 2. placement new構造對象(不分配內存,僅調用構造函數)return new (mem) Enemy(); // 在mem地址上構造Enemy }2. 銷毀對象(手動析構+歸還內存塊)
void destroy_enemy(Enemy* enemy) {if (!enemy) return;// 1. 手動調用析構函數enemy->~Enemy();// 2. 將內存塊歸還到空閑鏈表FreeBlock* block = reinterpret_cast<FreeBlock*>(enemy);block->next = free_list;free_list = block; }三、避免malloc次數統計的關鍵:重載operator new/delete
通過類專屬內存分配器,確保
Enemy對象只能從內存池分配,從而繞過系統malloc:class Enemy { public:// 重載operator new:從內存池分配void* operator new(size_t size) {// 直接調用內存池分配函數return create_enemy();}// 重載operator delete:歸還到內存池void operator delete(void* ptr) {destroy_enemy(static_cast<Enemy*>(ptr));}// ... 其他成員 ... };
第五題(實現高性能網絡服務器)
在實現高性能網絡服務器時,接收到的數據包Packet對象需要傳遞給處理線程。已知Packet包含大量數據(如std::vector<uint8_t> payload)。
問:
如何通過移動語義避免數據復制?請說明push_back時std::move的作用原理,并解釋為何移動構造函數應聲明為noexcept。// 使用場景 std::queue<Packet> packet_queue; Packet new_packet = receive_packet(); packet_queue.push_back(std::move(new_packet)); // 避免payload深拷貝關鍵點:
std::move將左值轉為右值,觸發移動構造
noexcept保證容器重分配時不回退到拷貝構造
移動后源對象處于有效但未定義狀態(不應再使用)
AI答案:
一、移動語義避免數據復制的核心實現
1. 定義
Packet類的移動構造函數class Packet { public:// 移動構造函數:接管資源而非復制Packet(Packet&& other) noexcept: payload(std::move(other.payload)) // 轉移vector內存所有權, size(other.size) {other.size = 0; // 源對象狀態重置}private:std::vector<uint8_t> payload; // 大量數據存儲size_t size; };2. 使用
std::move觸發移動構造std::queue<Packet> packet_queue; Packet new_packet = receive_packet(); // 接收數據包(左值)// 關鍵:std::move將左值轉為右值引用,觸發移動構造 packet_queue.push_back(std::move(new_packet)); // new_packet此時處于“有效但未定義狀態”,不應再使用二、
std::move在push_back中的作用原理
左值轉右值:
new_packet是左值(有名稱的對象),std::move(new_packet)將其轉換為右值引用(Packet&&)。- 這告訴編譯器:“允許接管此對象的資源,無需保留其原始狀態”。
容器的構造選擇:
queue::push_back接收右值時,會優先調用Packet的移動構造函數(而非拷貝構造函數)。- 對于
std::vector<uint8_t> payload,移動構造僅轉移指針和大小(O(1)操作),避免深拷貝數據(O(n)操作)。三、移動構造函數聲明
noexcept的必要性1. 確保容器內存重分配時的性能
當容器(如
vector、queue)需要擴容時,若元素類型的移動構造函數標記為noexcept:// 偽代碼:容器擴容邏輯 if (std::is_nothrow_move_constructible_v<Packet>) {move_elements_to_new_buffer(); // 高效移動 } else {copy_elements_to_new_buffer(); // 安全但低效的拷貝 }
- 無
noexcept:容器無法保證移動操作的異常安全性,會退回到拷貝構造,導致性能退化。- 有
noexcept:容器可安全使用移動構造,確保資源高效轉移。自己的理解:
int main(int argc,const char** argv){Stu zs;Stu ls = zs;// 拷貝構造 = 創建新對象ls,并且將zs里面的值賦值給lsStu ww = Stu();// 這里是一次普通構造,最終結果是,Stu()構建的臨時對象,他內部所有數據的最終所有權,被編譯器優化,變成了ww,即ww 的地址和 = 右側 Stu() 臨時對象地址是一樣的 )return 0; }什么樣的高效操作:臨時對象管理的內存直接移交給 = 左側的長生命周期對象進行管理
Stu zs; 普通構造 Stu ls = move(zs); 移動構造 move(zs)會創建一個新的臨時對象,并讓ls接管該對象 Stu ww = zs; 拷貝構造 ww會創建新的對象,并且去拷貝zs里面的所有數據所以從描述上來說,一定是移動構造效率更高
第六題(匿名函數)
在算法中使用自定義比較或操作邏輯時,定義完整的命名函數或仿函數 (functor) 類有時顯得繁瑣,尤其當邏輯很簡單且只使用一次時。我們需要一種更簡潔、更靈活的方式在調用點就地定義匿名函數。
參考答案:
=====================================================================
1:C++11 Lambda 表達式的基本語法結構是什么?[capture-list] (parameters) -> return-type { body } 各部分的作用是什么?(特別強調 capture-list)
- [capture-list](捕獲列表):指定外部變量如何被Lambda訪問(按值/按引用),為空則不捕獲任何變量。
- (parameters):參數列表,與普通函數參數相同(可省略,若無參數)。
- -> return-type:返回類型(可省略,編譯器會根據return語句自動推斷)。
- { body }:函數體,包含具體邏輯。
int x = 10; auto add = [x](int y) -> int { return x + y; }; // 捕獲x,接收y,返回int,函數體返回x+y2:捕獲列表 (capture-list) 有幾種主要捕獲方式?解釋 按值捕獲 [=]、按引用捕獲 [&]、捕獲特定變量 [x, &y] 的含義和行為。按值捕獲的變量在 Lambda 體內能被修改嗎?如何使其可修改?(mutable)
(1)按值捕獲?
[=]
- 含義:捕獲所有外部變量的副本(值傳遞)。
- 行為:Lambda體內使用的是變量的快照,外部變量后續修改不影響Lambda內的值。
int a = 1, b = 2; auto func = [=]() { return a + b; }; a = 3; // 外部修改不影響Lambda內的a(仍為1)(2)按引用捕獲?
[&]
- 含義:捕獲所有外部變量的引用(引用傳遞)。
- 行為:Lambda體內直接訪問外部變量,修改會影響原值。
int a = 1; auto func = [&]() { a++; }; func(); // a變為2(3)捕獲特定變量?
[x, &y]
- 含義:顯式指定捕獲變量,
x按值捕獲,y按引用捕獲。- 行為:僅捕獲列表中的變量可被訪問,未列出的變量無法使用。
int x = 1, y = 2, z = 3; auto func = [x, &y]() { return x + y; }; // 可訪問x(值)和y(引用),無法訪問z(4)按值捕獲的變量修改問題
- 默認行為:按值捕獲的變量在Lambda體內不可修改(被視為
const)。- 修改方法:使用
mutable關鍵字解除常量性:int x = 1; auto func = [x]() mutable { x++; return x; }; func(); // x變為2(僅修改副本,外部x仍為1)3:Lambda 表達式在底層是如何實現的?(通常被編譯器轉換為一個匿名的函數對象類 (仿函數))。
// Lambda被轉換為類似這樣的匿名類 class AnonymousFunctor { private:// 捕獲的變量作為成員(按值捕獲為副本,按引用捕獲為引用)int captured_x; // 按值捕獲的xint& captured_y; // 按引用捕獲的y public:// 構造函數初始化捕獲的變量AnonymousFunctor(int x, int& y) : captured_x(x), captured_y(y) {}// 重載operator(),對應Lambda的函數體int operator()(int param) const { // 若有mutable,則去掉constreturn captured_x + captured_y + param;} };
- 調用Lambda?等價于創建該匿名類的對象并調用
operator()。- 捕獲列表?決定了匿名類的成員變量類型(值或引用)。
- mutable?關鍵字會移除
operator()的const修飾,允許修改按值捕獲的成員變量。4:以下代碼中,Lambda 捕獲了局部變量 factor 和 threshold。當 processData 函數返回后,存儲了該 Lambda 的函數指針 func 還能被安全調用嗎?為什么?
#include <functional> std::function<void(int&)> processData(int threshold){int factor=2;auto lambda=[factor,threshold](int& value) mutable{value=value*factor;if(value>threshold) value=threshold;};return lambda; } auto func=processData(100); int num=50;//// 危險!processData返回后,factor和threshold已銷毀 func(num);//安全嗎?????結論:不能安全調用,原因如下:
- 局部變量生命周期:
factor和threshold是processData函數的局部變量,函數返回后會被銷毀。- 引用捕獲的風險:Lambda按引用捕獲了這兩個變量,存儲的Lambda對象(或函數指針)持有的是懸垂引用。
- 未定義行為:調用
func時訪問已銷毀的變量,會導致內存訪問錯誤(未定義行為)。技術考察點:
掌握 Lambda 的基本語法和核心組成部分。
深入理解捕獲列表:這是 Lambda 的核心難點和易錯點。清楚區分按值和按引用捕獲的語義、生命周期影響以及 mutable 的作用。
理解 Lambda 的底層實現原理(仿函數),知道它是如何攜帶狀態的(捕獲的變量成為匿名類的成員)。
考察對 變量生命周期 和 懸空引用 問題的敏感度(按引用捕獲局部變量后,局部變量銷毀會導致 Lambda 內引用無效)。
第七題(自動推導變量類型)
C++ 類型系統強大但有時類型名非常冗長(如迭代器、模板實例化結果、復雜表達式結果),手動寫出完整類型既繁瑣又容易出錯。我們需要編譯器幫助我們自動推導變量類型。
參考答案:
=====================================================================
1:C++11 中 auto 關鍵字的主要用途是什么?
2:auto 的類型推導規則通常遵循什么原則?(與模板參數推導規則類似)
3:以下代碼片段的推導結果是什么?為什么?
4:使用 auto 時,哪些情況可能導致意外或不直觀的類型推導結果?(例如推導出 std::initializer_list 或代理對象類型如 vector<bool>::reference)
auto a=42;//a的類型是? const int ci=10; auto b=ci;//b的類型是什么?const屬性還在嗎? auto c=ci;//c的類型是? auto d=&ci;//d的類型是什么? std::vector<int> vec; auto it=vec.begin();//it的類型是什么?(迭代器類型通常很冗長)
auto a = 42;
- a的類型:
int- 原因:整數字面量
42的默認類型為int,auto直接推導為該類型。
const int ci = 10; auto b = ci;
- b的類型:
int- const屬性:不在
- 原因:
auto推導時會忽略頂層const(即變量本身的const),僅保留底層const(如指針/引用指向的對象是const)。
auto c = ci;
- c的類型:
int(與b完全相同,推導規則一致)
auto d = &ci;
- d的類型:
const int*(指向const int的指針)- 原因:
&ci是const int的地址,auto推導為const int*,此時const是底層const(指針指向的對象不可修改),會被保留。
std::vector<int> vec; auto it = vec.begin();
- it的類型:
std::vector<int>::iterator- 原因:
vec.begin()返回的迭代器類型為容器定義的iterator類型,auto推導時會精確匹配該類型,避免了冗長的手動聲明(如std::vector<int>::iterator it = vec.begin();)。核心規則:
auto推導時會忽略頂層const,但保留底層const;對于表達式類型會進行精確匹配,特別適合簡化復雜類型(如迭代器、函數指針等)的聲明。技術考察點:
理解 auto 的核心價值:簡化代碼、避免冗長類型名、提高可維護性、防止隱式類型轉換錯誤。
掌握 auto 推導的基本規則:忽略頂層 const 和引用(除非顯式指定 auto& 或 const auto&),推導表達式結果的類型。
理解 auto 與引用、指針、const 結合時的具體推導結果。
了解 auto 使用的潛在陷阱(如代理對象、initializer_list 推導),知道何時需要小心或顯式指定類型。
第八題(遍歷容器(如數組、vector、list、map)元素是常見操作)
遍歷容器(如數組、vector、list、map)元素是常見操作,使用傳統的迭代器或下標循環代碼相對冗長且容易出錯(如迭代器失效、下標越界)。我們需要一種更簡潔、更安全的遍歷語法。
考察點:
=====================================================================
1:C++11 范圍 for 循環 (for (elem : container),自動迭代法) 的基本語法和優勢是什么?
- 簡化寫法:可省略元素類型,用?
auto?自動推導:for (auto elem : container)- 引用寫法:如需修改元素或避免拷貝,使用引用:
for (auto& elem : container)核心優勢:
- 代碼簡潔:無需手動調用?
begin()/end()?或管理迭代器,減少模板代碼(如?std::vector<int>::iterator)。- 可讀性高:直接表達“遍歷容器中所有元素”的意圖,邏輯更清晰。
- 安全性強:自動處理容器邊界,避免迭代器越界風險(如?
it != container.end()?的漏寫)。- 通用性好:支持所有符合“范圍概念”的對象(如標準容器、原生數組、自定義容器)。
2:范圍 for 循環在底層是如何實現的?(通常被編譯器轉換為基于迭代器的傳統循環)
編譯器會將范圍 for 循環轉換為基于迭代器的傳統循環,等價邏輯如下:
// 偽代碼:編譯器對 for (auto elem : container) 的轉換 auto&& __range = container; // 保持容器生命周期(右值引用避免臨時對象銷毀) auto __begin = std::begin(__range); // 調用容器的 begin() auto __end = std::end(__range); // 調用容器的 end() for (; __begin != __end; ++__begin) {auto elem = *__begin; // 解引用迭代器獲取元素// 循環體 }3:以下兩種寫法在遍歷 std::vector<int> 時有何本質區別?哪種方式修改元素會影響原容器?哪種方式效率更高?
//寫法1 for(auto value:vec){/*...*/} //寫法2 for(auto& value:vec){/*...*/}// 寫法1:按值捕獲元素 for (int elem : vec) { ... }// 寫法2:按引用捕獲元素 for (int& elem : vec) { ... }寫法1(按值):修改?
value?不會影響原容器。 示例:std::vector<int> vec = {1, 2, 3}; for (auto value : vec) {value *= 2; // 僅修改副本,原容器元素不變 } // vec 仍為 {1, 2, 3}寫法2(按引用):修改?
value?會直接影響原容器。 示例:std::vector<int> vec = {1, 2, 3}; for (auto& value : vec) {value *= 2; // 直接修改原容器元素 } // vec 變為 {2, 4, 6}按值拷貝:
value?是容器元素的副本 |?按引用綁定:value?是容器元素的別名 |內存操作?| 每次迭代創建新副本(獨立內存空間) | 直接引用原容器內存(無額外內存分配)?
4. 最佳實踐建議
- 只讀場景:使用?
const auto&(避免拷貝且防止誤修改):for (const auto& value : vec) { /* 只讀訪問 */ }
- 修改場景:使用?
auto&(直接修改原容器)。- 副本修改場景:使用?
auto(明確需要獨立副本時)。(這題好像有問題,各位可以自己測試一下)
4:在范圍 for 循環體內修改容器本身(如添加或刪除元素)通常會發生什么?為什么?(引出 迭代器失效 問題)
一、現象:未定義行為(Undefined Behavior)
- 可能表現:程序崩潰、數據錯亂、循環提前結束或無限循環。
- 典型案例:對?
std::vector<int>?使用范圍 for 循環時執行?push_back,可能觸發內存重分配,導致原迭代器指向已釋放的內存。三、迭代器失效的具體場景
1.?添加元素(如?
push_back、insert)連續內存容器(
vector、string):
- 若添加元素后容器容量不足,會觸發內存重分配(新地址分配+元素拷貝),原?
__begin?和?__end?迭代器指向已釋放的舊內存,導致失效。- 即使容量足夠,
__end?仍指向原結束位置,新增元素無法被循環遍歷(循環范圍已固定)。鏈表容器(
list、forward_list):
- 添加元素不會導致迭代器失效,但?
__end?仍為初始值,新增元素無法被遍歷。2.?刪除元素(如?
erase、pop_back)
- 連續內存容器:刪除元素后,后續元素會前移,
__begin?可能指向被刪除元素的下一個位置(但?__end?未更新),導致循環訪問到錯誤元素。- 鏈表容器:刪除當前元素會導致指向該元素的迭代器失效,若?
__begin?恰好指向被刪除元素,會觸發未定義行為。五、為何范圍 for 循環無法處理迭代器失效?
- 迭代器固定:
__begin?和?__end?在循環開始時確定,無法動態更新。- 無迭代器調整機制:傳統 for 循環可通過?
erase?返回的新迭代器調整循環變量(如?it = vec.erase(it)),而范圍 for 循環無此接口。六、正確做法
1.避免在范圍 for 循環中修改容器,改用傳統 for 循環并處理迭代器失效:
for (auto it = vec.begin(); it != vec.end(); ) { if (*it == 2) { it = vec.erase(it); // 用返回的新迭代器更新} else { ++it; } }
- 使用支持安全修改的容器(如?
std::list?的迭代器在插入時不失效),但仍需注意?__end?固定的問題。參考答案:
=====================================================================
技術考察點:
理解范圍 for 的核心優勢:簡潔、安全(避免手動管理迭代器/下標)、語義清晰。
了解其底層實現依賴于容器的 begin() 和 end() 成員函數或自由函數(ADL)。
深刻理解按值遍歷 (auto elem) 與 按引用遍歷 (auto& elem 或 const auto& elem) 的區別:前者是元素副本,后者是元素別名。按引用遍歷才能修改原容器元素,且避免拷貝開銷(對大型對象或容器重要)。
理解在循環體內修改容器結構(增刪元素)極易導致迭代器失效,進而引發未定義行為 (UB)。知道范圍 for 循環對此不提供額外保護。
第九題(空指針字面量 NULL 為什么修改為nullptr??)
C++ 中傳統的空指針字面量 NULL 通常被定義為 0 或 (void*)0。這可能導致函數重載解析時的歧義(整型 0 vs 指針類型)和類型安全問題。
1:C++11 引入 nullptr 的主要動機是什么?它解決了 NULL 的什么問題?
1. 核心動機
解決傳統?
NULL?作為空指針表示時的類型二義性問題,提供更安全、明確的空指針語義。2.?
NULL?的缺陷在 C++98/03 中,
NULL?通常被宏定義為整數 0:#define NULL 0 // 常見實現NULL的不安全性:
重載歧義:無法區分傳遞的是空指針還是整數 0
類型不安全:NULL 可被隱式轉換為任何整數類型,可能意外賦值給非指針變量(如 int x = NULL;)。
nullptr的優勢:
明確的空指針類型:
nullptr?是獨立的空指針字面量,類型為?std::nullptr_t。消除重載歧義:編譯器能正確匹配指針重載版本:
類型安全:nullptr 僅可隱式轉換為指針類型(包括普通指針、函數指針、成員指針)和智能指針,不能轉換為整數類型,避免意外賦值。
2:nullptr 是什么類型?(std::nullptr_t,可以隱式轉換為任何指針類型和成員指針類型,但不能轉換為整數類型)
在C++11中,
nullptr的類型是std::nullptr_t。這是一種特殊的空指針類型,它可以隱式轉換為任何指針類型(包括對象指針、函數指針)和成員指針類型,但不能轉換為整數類型。這種設計解決了NULL作為空指針表示時的二義性問題,因為NULL通常被定義為整數0,可能導致重載解析錯誤。而std::nullptr_t類型的nullptr能更精確地表示空指針語義,提高代碼的類型安全性。3:給出一個例子說明 NULL 可能導致重載解析歧義,而 nullptr 可以避免。
void func(int); void func(char*); func(NULL);//可能調用哪個???(通常是func(int),不符合預期) func(nullptr);//可以明確調用哪個???參考答案:
=====================================================================
技術考察點:
理解 NULL 的歷史問題(本質是整數 0 而非真正的指針類型)。
理解 nullptr 的核心優勢:具有明確的指針類型 (std::nullptr_t),消除了重載歧義,提高了類型安全。
知道 nullptr 應該成為表示空指針的首選方式。
第十題(利用多核處理器提高性能或響應性)
現代程序需要利用多核處理器提高性能或響應性,C++11 之前缺乏標準化的線程庫,需要依賴平臺特定 API (如 pthreads, Win32 Threads),代碼可移植性差。
1:C++11 如何創建一個新線程?基本步驟是什么?(#include <thread>, std::thread t(func, args...))
- 包含頭文件:首先需要包含C++11線程庫的頭文件?
<thread>。- 定義線程函數:準備一個需要在新線程中執行的函數(可以是普通函數、Lambda表達式或函數對象)。
- 創建線程對象:使用?
std::thread?類創建線程對象,構造時傳入函數名和參數(如果有的話),語法為?std::thread t(func, args...)。- 管理線程生命周期:通過?
t.join()?等待線程執行完畢(阻塞當前線程),或?t.detach()?將線程與主線程分離(線程后臺運行)。注意:必須調用其中一個,否則程序會在?std::thread?析構時崩潰。#include <iostream> #include <thread>// 線程函數 void printMessage(const std::string& msg) {std::cout << msg << std::endl; }int main() {// 創建線程并傳入函數和參數std::thread t(printMessage, "Hello from new thread!");// 等待線程執行完畢t.join();return 0; }2:為什么在多線程環境下訪問共享數據通常需要同步?常見的同步原語有哪些?(引出 std::mutex)
1.?互斥鎖(std::mutex)
最基礎的同步原語,通過獨占訪問保護共享數據。線程必須先獲取鎖才能訪問資源,訪問結束后釋放鎖。
#include <mutex> #include <thread>std::mutex mtx; // 全局互斥鎖 int shared_data = 0;void increment() {mtx.lock(); // 獲取鎖shared_data++; // 臨界區:安全訪問共享數據mtx.unlock(); // 釋放鎖(需確保異常時也能釋放,推薦使用RAII封裝) }最佳實踐:使用
std::lock_guard(RAII)自動管理鎖的生命周期,避免忘記釋放鎖導致死鎖:void safe_increment() {std::lock_guard<std::mutex> lock(mtx); // 構造時加鎖,析構時自動解鎖shared_data++; }2.?條件變量(std::condition_variable)
用于線程間的等待-通知機制,允許線程阻塞等待某個條件成立(如數據就緒)。常與互斥鎖配合使用。
#include <condition_variable>std::condition_variable cv; bool data_ready = false;void producer() {// 生產數據...{ std::lock_guard<std::mutex> lock(mtx);data_ready = true;}cv.notify_one(); // 通知等待的消費者 }void consumer() {std::unique_lock<std::mutex> lock(mtx);cv.wait(lock, []{ return data_ready; }); // 等待條件成立// 消費數據... }3.?原子變量(std::atomic)
用于無鎖同步,適用于簡單數據類型(如計數器)。操作通過硬件支持保證原子性,無需顯式加鎖。
#include <atomic> std::atomic<int> atomic_counter(0); // 原子變量void atomic_increment() {atomic_counter++; } // 無需手動加鎖,操作本身是原子的3:如何使用 std::mutex 保護共享數據的訪問?基本代碼模式是怎樣的?
std::mutex mtx; int shared_data; void safe_increment(){std::lock_guard<std::mutex> lock(mtx);//RAII 鎖++shared_data; }4:std::lock_guard 的作用是什么?
std::lock_guard?是 C++11 引入的RAII(資源獲取即初始化)風格的互斥鎖封裝工具,其核心作用是自動管理互斥鎖(std::mutex)的生命周期,確保鎖在任何情況下(包括異常拋出時)都能被正確釋放,從而避免死鎖。主要作用:
自動加鎖與解鎖:
- 構造?
std::lock_guard?對象時,自動調用?std::mutex::lock()?獲取鎖。- 當?
std::lock_guard?對象超出作用域(如函數返回、異常拋出)時,其析構函數自動調用?std::mutex::unlock()?釋放鎖。防止死鎖風險: 避免手動調用?
lock()?和?unlock()?可能導致的遺漏解鎖問題(例如在復雜邏輯或異常分支中忘記解鎖)參考答案:
=====================================================================
技術考察點 (初級要求):
知道 C++11 提供了標準化的線程庫 <thread>。
理解創建線程的基本方法 (std::thread)。
理解 數據競爭 (Data Race) 的概念和危害。
知道最基本的同步機制是 互斥鎖 (std::mutex)。
掌握 std::lock_guard 的 RAII 用法:這是初級開發者必須掌握的安全加鎖模式,確保鎖在作用域結束時自動釋放,避免忘記解鎖導致死鎖。理解 RAII 在此處的應用。
第11題(override關鍵字作用,運行時多態計算薪資)
公司需要管理不同類型員工(普通員工Employee、經理Manager)的薪資計算。普通員工按月薪計算,經理有基本工資+獎金。要求統一接口計算薪資。
1:如何設計基類和派生類實現運行時多態計算薪資?
可以通過基類定義純虛函數,派生類重寫實現的方式實現多態薪資計算:
// 基類:員工 class Employee { public:virtual double calculateSalary() const = 0; // 純虛函數,定義接口virtual ~Employee() = default; // 虛析構函數,確保派生類析構正確調用 };// 派生類:普通員工(月薪) class RegularEmployee : public Employee { private:double monthlySalary; public:RegularEmployee(double salary) : monthlySalary(salary) {}double calculateSalary() const override { // 重寫基類方法return monthlySalary;} };// 派生類:經理(基本工資+獎金) class Manager : public Employee { private:double baseSalary;double bonus; public:Manager(double base, double b) : baseSalary(base), bonus(b) {}double calculateSalary() const override { // 重寫基類方法return baseSalary + bonus;} };2:若不將基類的calculateSalary()聲明為虛函數會怎樣?
若不將基類的
calculateSalary()聲明為虛函數,將無法實現多態行為,導致派生類的重寫函數無法被正確調用3:C++11的override關鍵字有什么作用?
C++11引入的
override關鍵字主要用于顯式標記派生類中重寫基類虛函數的方法,其核心作用是提升代碼安全性和可讀性。4:以下代碼輸出什么?為什么?
Employee* emp=new Manager("Alice",5000,2000); std::cout<<emp->calculateSalary();//基類方法未聲明virtual delete emp;01.此時?
emp->calculateSalary()?會調用?Employee::calculateSalary(),輸出?0(基類默認值),而非預期的?7000(5000+2000)。02.C++ 對非虛函數采用?靜態綁定(編譯期決議),函數調用根據指針聲明類型(
Employee*)而非實際指向的對象類型(Manager)決定。03.額外風險:析構函數未聲明virtual導致內存泄漏
參考答案:
=====================================================================
override作用:
顯式標記重寫虛函數
編譯器檢查簽名是否匹配
避免隱藏(hide)錯誤
第11題(安全數組容器)
需要實現安全數組容器,支持不同類型數據,提供邊界檢查。
1:如何用類模板實現通用數組?
#include <stdexcept> // 用于異常處理template <typename T> class SafeArray { private:T* data; // 動態數組存儲元素size_t size; // 數組大小public:// 1. 構造函數:初始化數組explicit SafeArray(size_t size) : size(size) {if (size == 0) {throw std::invalid_argument("Array size must be positive");}data = new T[size]; // 分配內存}// 2. 析構函數:釋放內存~SafeArray() {delete[] data; // 釋放動態數組}// 3. 拷貝構造函數:防止淺拷貝SafeArray(const SafeArray& other) : size(other.size) {data = new T[size];for (size_t i = 0; i < size; ++i) {data[i] = other.data[i]; // 深拷貝元素}}// 4. 拷貝賦值運算符:防止淺拷貝SafeArray& operator=(const SafeArray& other) {if (this != &other) { // 避免自賦值delete[] data; // 釋放原有內存size = other.size;data = new T[size];for (size_t i = 0; i < size; ++i) {data[i] = other.data[i]; // 深拷貝元素}}return *this;}// 5. 訪問元素:帶邊界檢查T& operator[](size_t index) {if (index >= size) {throw std::out_of_range("Index out of bounds"); // 拋出越界異常}return data[index];}// 6. const版本訪問元素(只讀)const T& operator[](size_t index) const {if (index >= size) {throw std::out_of_range("Index out of bounds");}return data[index];}// 7. 獲取數組大小size_t getSize() const { return size; } };關鍵特性說明
- 模板參數化:通過
template <typename T>使數組支持任意類型(int/double/自定義類型等)- 邊界檢查:在
operator[]中驗證index < size,越界時拋出std::out_of_range異常- 內存安全:
- 動態內存管理(
new[]/delete[])- 實現拷貝構造和拷貝賦值(深拷貝),避免淺拷貝導致的二次釋放
- 使用便捷性:重載
operator[]使訪問語法與原生數組一致2:成員函數在類外定義時要注意什么?
1.?類模板成員函數:必須指定模板參數列表
類模板的成員函數在類外定義時,需通過
<T>顯式指定模板參數,并在作用域前添加template <typename T>:// 類內聲明template <typename T>class SafeArray {public:T& operator[](size_t index); // 類內聲明};// 類外定義(必須帶模板參數)template <typename T>T& SafeArray<T>::operator[](size_t index) {if (index >= size) {throw std::out_of_range("Index out of bounds");}return data[index];}2.?作用域限定符:必須使用
類名::無論是否為模板類,類外定義時必須通過
類名::函數名指明作用域:// 非模板類示例 class MyClass { public:void func(); // 類內聲明 };// 類外定義必須帶作用域 void MyClass::func() {// 實現 }3.?函數簽名:必須與類內聲明完全一致
- 返回值類型、參數列表、
const限定符、引用限定符必須完全匹配- 模板參數名可不同,但位置和數量必須一致
4.?訪問權限:類外定義不改變成員的訪問級別
類外定義僅影響實現位置,不改變成員的
public/private/protected屬性:總結:類外定義檢查清單
? 模板類成員函數是否帶template <typename T>和類名<T>::
? 函數簽名是否與類內聲明完全一致(返回值、參數、const等)
? 是否使用了正確的作用域限定符
? 模板類成員函數是否在頭文件中定義(除非使用顯式實例化)
? 靜態成員函數是否正確聲明(無需this指針,可通過類名::直接調用)3:C++11的using別名相比typedef有何優勢?
1.?語法更直觀,可讀性更強
using采用更自然的"別名 = 類型"語法,符合人類閱讀習慣,尤其是對于復雜類型(如函數指針、數組等):2.?原生支持模板別名
這是
using最核心的優勢。typedef無法直接為模板定義別名,必須通過額外的模板結構體包裝(如上面的Vec示例),而using可以直接創建模板別名:3.?與模板參數結合更靈活
在類模板中定義成員別名時,
using可以直接使用類的模板參數,而typedef需要配合typename關鍵字才能正確解析依賴類型:4.?便于模板特化和偏特化
using定義的模板別名可以直接參與模板特化,而typedef需要通過模板結構體間接實現特化:5.?統一風格優勢
using語法與C++11后的現代特性(如auto推導類型、decltype類型獲取等配合時,風格更統一,代碼更具一致性:4:模板實例化過程是怎樣的?
一、模板實例化的觸發條件
編譯器僅在模板被實際使用時才會觸發實例化(延遲實例化機制),具體觸發場景包括:
- 對象創建:
TemplateClass<int> obj;- 成員函數調用:
obj.method();(僅調用的成員會被實例化)- 顯式實例化指令:
template class TemplateClass<double>;- 取模板地址:
&TemplateClass<char>::method參考答案:
=====================================================================
using優勢:
更清晰直觀(類似變量賦值)
支持模板別名
//typedef舊語法 typedef SafeArray<int,10> IntArray;//C++11 using using IntArray=SafeArray<int,10>;//模板別名(typedef無法實現) template<typename T> using Vec=std::vector<T>;
第12題(函數模板實現)
需要實現獲取兩個值中最大值的通用函數。
1:如何用函數模板實現?
template <typename T> T max(T a, T b) {return (a > b) ? a : b; }2:調用時類型如何推導?
一、基本類型推導規則
1. 單一模板參數情況
對于只有一個模板參數的函數模板:
template <typename T> T max(T a, T b); // 兩個參數類型相同編譯器會比較所有實參類型,必須完全匹配才能推導成功:
max(10, 20); // 成功推導 T = int max(3.14, 2.71); // 成功推導 T = double max('a', 'b'); // 成功推導 T = char // max(10, 3.14); // 編譯錯誤:無法推導 T(int 和 double 不匹配)2. 多個模板參數情況
對于有多個模板參數的函數模板:
template <typename T1, typename T2> auto max(T1 a, T2 b) -> decltype(a > b ? a : b);編譯器會獨立推導每個參數類型:
max(10, 3.14); // T1 = int, T2 = double max('a', 100L); // T1 = char, T2 = long類型推導的核心原則是根據實參類型自動確定模板參數,主要分為:
- 單一參數推導:要求所有實參類型完全匹配
- 多參數推導:獨立推導每個參數類型
- 顯式指定:無法自動推導時手動指定類型
- 特殊類型處理:引用、const、萬能引用有特殊推導規則
3:C++11的decltype和尾返回類型有什么用?
C++11引入的
decltype和尾返回類型(trailing return type)是解決類型推導問題的重要特性,尤其在泛型編程中發揮關鍵作用。總結 - **`decltype`**:編譯時類型查詢工具,用于獲取表達式的精確類型,是實現 類型感知代碼的基礎 - **尾返回類型**:解決了返回類型依賴參數的語法難題,提升了復雜函數的可 讀性和可維護性 - **組合使用**:`auto func(...) -> decltype(...)`是C++11泛型編程的標 配,使編寫類型無關的通用代碼成為可能4:以下代碼問題在哪?
template<typename T,typename U> auto max(T a,U b){return a>b?a:b;} auto result=max(3,4.5);//返回值類型是什么??類型推導過程:
模板參數推導:
T被推導為int(實參3的類型)U被推導為double(實參4.5的類型)條件表達式類型規則: 函數返回
a > b ? a : b,其中:
a是int類型,b是double類型- 根據C++隱式類型轉換規則,
int會被提升為double進行比較- 條件表達式的結果類型為提升后的公共類型
doubleauto返回類型推導: 在C++14及以上標準中,
auto會根據return語句的表達式類型(double)推導返回類型
- 若使用C++11標準,此代碼無法通過編譯,因為C++11要求
auto返回類型必須配合尾返回類型(-> decltype(a > b ? a : b))- 類型提升遵循"算術轉換"規則:小范圍類型向大范圍類型轉換(
int?→?double)因此,最終返回值類型為
double。decltype與尾返回類型?語法如下:
template<typename T,typename U> auto max(T a,U b)->decltype(a>b?a:b){return a>b?a:b; }解決返回類型依賴參數的問題
保持類型推導能力
第13題(多態機制對調試)
理解多態機制對調試和性能優化至關重要。
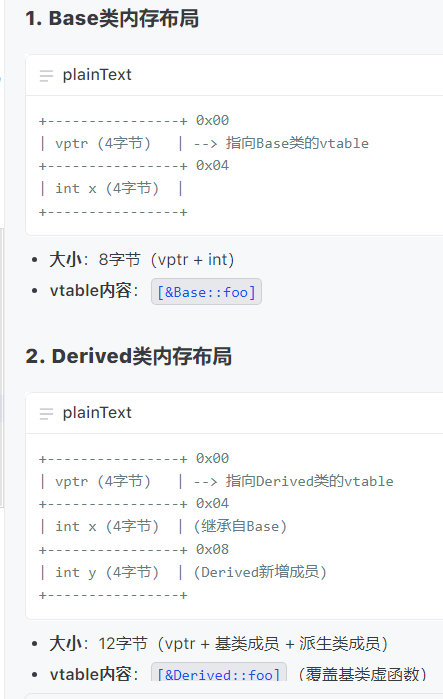
1:虛函數表(vtable)是什么?
核心作用
- 實現動態綁定:確保運行時根據對象實際類型調用正確的虛函數版本
- 存儲虛函數地址:每個包含虛函數的類擁有一個唯一的vtable,存儲該類所有虛函數的內存地址
實現機制
類層面:
- 編譯器為每個包含虛函數的類生成一個vtable(靜態數組)
- vtable中按聲明順序存儲虛函數指針,若派生類重寫基類虛函數,則替換對應位置的函數指針
- 類中會隱含一個指向vtable的指針成員(vptr),通常在對象內存布局的最開始位置
對象層面:
- 對象創建時自動初始化vptr,指向其所屬類的vtable
- 通過基類指針/引用調用虛函數時,CPU通過vptr找到vtable,再定位到具體函數地址
2:動態綁定如何實現?
一、動態綁定的核心條件
- 基類聲明虛函數:使用
virtual關鍵字- 派生類重寫虛函數:函數簽名(返回類型、參數列表)必須與基類完全一致(C++11可使用
override顯式標記)- 通過基類指針/引用調用:只有通過基類指針或引用訪問虛函數時才觸發動態綁定
3:C++11的final關鍵字有什么用?
一、修飾類:禁止繼承
當
final用于類聲明時,表示該類不能被任何類繼承。二、修飾虛函數:禁止重寫
當
final用于虛函數聲明時,表示該函數不能被派生類重寫。4:+以下代碼內存布局是怎樣的
class Base{virtual void foo(){}int x; }; class Derived:public Base{void foo() override{}int y; }
final作用:
禁止重寫虛函數:virtual void foo() final;
禁止類被繼承:class Base final {};

第14題(模板全特化)
通用打印函數需要對字符串類型特殊處理。
1:如何實現模板全特化?
1. 基本模板定義
首先定義通用的模板函數:
#include <iostream> #include <string>// 主模板定義 template <typename T> void print(const T& value) {std::cout << "Generic print: " << value << std::endl; }2. 對字符串類型進行全特化
為
const char*和std::string類型提供特化實現:// ... existing code ...// 對const char*類型全特化 template <> void print<const char*>(const char* const& str) {std::cout << "String print: [" << str << "]" << std::endl; }// 對std::string類型全特化 template <> void print<std::string>(const std::string& str) {std::cout << "String print: [" << str << "]" << std::endl; }全特化關鍵點說明
- 語法格式:
template <>開頭,明確指定特化類型- 函數簽名:必須與主模板完全匹配,包括參數類型和const限定
- 實現位置:類模板特化通常放在頭文件,函數模板特化可放在源文件
- 調用規則:編譯器會優先選擇最匹配的特化版本
2:部分特化在類模板中如何使用?
// 主模板 template <typename T, typename U> class MyClass {// 通用實現 };// 部分特化:當第二個參數為int時 template <typename T> class MyClass<T, int> {// 針對T, int的特化實現 };// 部分特化:當兩個參數都是指針時 template <typename T, typename U> class MyClass<T*, U*> {// 針對指針類型的特化實現 };三、關鍵要點
- 特化程度:部分特化必須比主模板更具體,但不需要特化所有參數
- 優先級規則:編譯器會優先選擇最匹配的特化版本
- 局限性:
- 函數模板不支持部分特化(可通過函數重載替代)
- 特化版本需要重新定義整個類結構
3:以下代碼輸出什么?
template<typename T> void print(T value){std::out<<"Generic:"<<value<<std::endl; }template<> void print<const char*>(const char* str){std::out<<"String:"<<str<<std::endl; }print(42); print("Hello");輸出結果:
Generic:42 String:Hello
模擬面試IO
第1題(文件 I/O 和標準 I/O 的區別)
“在開發訂單系統時,內存中的交易數據需實時寫入文件防止丟失。請解釋文件 I/O 和標準 I/O 的區別,以及為何標準 I/O 更適合高頻寫入?”
參考答案:
=====================================================================
文件 I/O:直接使用 Linux 系統調用(如 open/read/write),無緩沖區,每次操作觸發內核切換,適合低延遲場景。
標準 I/O:C 庫函數(如 fopen/fprintf)自帶緩沖區,減少系統調用次數。例如全緩沖模式填滿緩沖區才寫入磁盤,顯著降低高頻寫入的磁盤壓力。
選擇依據:訂單系統需頻繁寫小數據,標準 I/O 的緩沖機制可合并多次寫入,避免頻繁內核切換,提升吞吐量。
第2題(文件 I/O 和標準 I/O 的區別)
“用 lseek 跳過 1GB 后寫入 1 字節,實際磁盤占用僅 4KB。請解釋空洞文件的原理及應用場景。
參考答案:
=====================================================================
原理:文件偏移量超越物理存儲時,內核記錄“空洞”,實際磁盤塊僅分配寫入區域。du 命令顯示邏輯大小,ls 顯示物理占用。
應用:數據庫預分配大文件避免碎片,下載工具創建占位文件。
第3題(守護進程)
“如何將 Web 服務轉為守護進程?關鍵步驟為何要兩次 fork?”
參考答案:
=====================================================================
首次 fork 后父進程退出,子進程成為孤兒進程(脫離終端控制)。
調用 setsid() 創建新會話,脫離終端關聯。
二次 fork 避免子進程重新獲取終端(非會話首領進程無法打開終端)。
關閉文件描述符、重定向標準流到 /dev/null
AI答案:
守護進程化的完整關鍵步驟:
首次fork:父進程退出,子進程成為孤兒進程并被init進程收養,脫離終端控制
調用setsid():創建新會話,子進程成為會話首領,徹底脫離原終端
二次fork:
避免子進程成為會話首領,防止其重新打開控制終端
確保進程不是會話首領,符合守護進程安全標準
文件處理:
關閉所有不必要的文件描述符(0,1,2等)
將標準輸入/輸出/錯誤重定向到/dev/null(修正您回答中的/dev/null15筆誤)
環境清理:重置umask權限掩碼,設置工作目錄為根目錄
兩次fork的核心原因:
第一次fork:打破與父進程的關聯,使進程成為后臺進程
第二次fork:防止進程獲得控制終端(會話首領會優先獲取終端),確保嚴格的后臺運行狀態
這一標準流程遵循System V守護進程規范,可通過daemon(3)函數簡化實現(部分系統提供)。
第4題(守護進程)
“fork() 后子進程是否復制父進程的 100MB 堆內存?寫時復制(Copy-on-Write)如何解決此問題?”
參考答案:
=====================================================================
COW 機制:fork() 后子進程共享父進程內存頁,僅當修改內存時觸發缺頁中斷復制新頁。避免立即復制大內存,提升創建效率18。
例外:線程棧、文件描述符表等需獨立復制
第5題(多線程統計接口調用次數)
“多線程統計接口調用次數時,count++ 為何結果錯誤?如何用原子操作解決?,為什么能解決(工作原理)”??
參考答案:
=====================================================================
問題:count++ 非原子操作(包含讀-改-寫三步),多線程競爭導致計數丟失更新。
解決:
互斥鎖或者信號量
第6題(用條件變量和互斥鎖實現)
“異步日志系統中,生產者線程寫日志到隊列,消費者線程刷盤(寫入操作)。如何用條件變量和互斥鎖實現?”
參考答案:
=====================================================================
答:描述清楚生產者消費者模式
消費者循環讀取隊列中的數據,如果隊列中數據為空,則使用條件變量wait阻塞
當生產者將數據寫入隊列中后,使用signal喚醒消費者
關鍵點:條件變量避免忙等待,互斥鎖保護共享隊列
第7題(共享內存比管道更合適)
“視頻編輯進程需向編碼進程發送 100MB 幀數據。為何共享內存比管道更合適?如何同步訪問?”
參考答案:
=====================================================================
優勢:共享內存直接映射到進程地址空間,避免管道的數據拷貝(內核-用戶態切換)
同步:
信號量(如 sem_init)協調讀寫順序。
第8題(微服務間頻繁跨進程調用)
“微服務間頻繁跨進程調用,Binder 為何用線程池處理請求?對比傳統同步 IPC 的優勢。”
參考答案:
=====================================================================
線程池:服務端預創建線程,并行處理多個請求,避免同步 IPC 的串行阻塞。
優勢:
高并發:多請求同時處理。
資源復用:避免頻繁創建/銷毀線程
第9題(微服務間頻繁跨進程調用)
“在金融交易系統中,日志必須確保崩潰后不丟失。調用 fwrite() 后立刻掉電,數據會丟失嗎?如何用 fsync() 解決?代價是什么?”
參考答案:
=====================================================================
問題:fwrite() 寫入標準 I/O 緩沖區,未刷盤時掉電導致丟失。
解決:定期調用 fsync(fd) 強制內核緩沖區落盤(同步磁盤寫入)。
fflush():
作用于 用戶空間緩沖區(C標準庫的FILE*流緩沖區)。
將用戶緩沖區中的數據刷新到操作系統內核的頁面緩存(Page Cache)。
不保證數據寫入物理磁盤。
fsync():
作用于 內核空間緩沖區(操作系統的頁面緩存)。
將內核緩存中的數據強制寫入物理存儲設備(如磁盤)。
確保數據持久化到硬件。
學生如果回答fflush的話,需要跟他講fsync和fflush的區別
代價:磁盤 I/O 阻塞線程,吞吐量下降(需權衡持久化級別與性能)。
第10題(sendfile())
用 read() 和 write() 拷貝 10GB 文件,為何性能不如 sendfile()?sendfile() 如何減少數據拷貝次數?”
參考答案:
=====================================================================
傳統方式:read()(內核緩沖區→用戶緩沖區) + write()(用戶緩沖區→內核緩沖區),2 次拷貝 + 4 次上下文切換。
sendfile():內核直接在內核空間完成文件到套接字的拷貝(零拷貝技術),僅 2 次上下文切換,適合靜態文件服務器。
第11題(為何要設置 SA_RESTART)
“父進程未調用 wait() 的子進程會變成僵尸。如何用信號處理 + waitpid() 自動回收?為何要設置 SA_RESTART?”
參考答案:
=====================================================================
void sigchld_handler(int sig){while(waitpid(-1,NULL,WNOHANG)>0);//非阻塞回收所有僵尸進程 } int main(){struct sigaction sa={.sa_handler=sigchld_handler,.sa_flags=SA_RESTART//避免系統調用被信號中斷};sigaction(SIGCHLD,&sa,NULL);//...后續fork邏輯 }
第12題(保證日志不交叉混亂)
“兩個進程同時打開同一個文件并追加寫入,如何保證日志不交叉混亂?O_APPEND 標志如何解決?”
參考答案:
=====================================================================
問題:無同步時,進程 A 寫入中途可能被進程 B 覆蓋。
解決:open(file, O_WRONLY | O_APPEND) 確保每次 write() 前自動將偏移量移到文件末尾,內核保證原子性。
第13題(如何避免死鎖)
“線程 A 先鎖 M1 再鎖 M2,線程 B 先鎖 M2 再鎖 M1,導致死鎖。如何用鎖順序協議(Lock Ordering)解決?哪些工具可檢測死鎖?”
參考答案:
=====================================================================
鎖順序協議:所有線程按固定順序(如 M1→M2)申請鎖,破壞環路等待條件。
檢測工具:
gdb + thread apply all bt 查看線程棧
Valgrind 的 Helgrind 模塊
Clang 的 -Wthread-safety 靜態檢查
第14題(epoll模型)
“監控進程需實時感知 10 個工作進程的狀態變化。為何用信號量不如用事件文件描述符 + epoll?請給出實現框架。”
參考答案:
=====================================================================
信號量缺點:僅傳遞計數,無法區分事件來源。
epoll+事件描述符模型
int efd=epoll_create1(0); for(int i=0;i<10;i++){int event_fd=eventfd(0,EFD_NONBLOCK);//創建事件fd//工作進程狀態變化時寫 event_fdepoll_ctl(efd,EPOLL_CTL_ADD,event_fd,&(struct epoll_event){.events=EPOLLIN}); } while(1){epoll_wait(efd,events,10,-1);//阻塞等待事件for(每個觸發的事件fd) read(fd,&val,sizeof(val));//清空事件//根據fd定位到具體進程并處理 }
模擬面試網編
第1題(為什么需要設置 SO_REUSEADDR 選項)
"當實現TCP服務端時,客戶端頻繁重連會出現 Address already in use 錯誤。請解釋為什么需要設置 SO_REUSEADDR 選項?這與TCP的 TIME_WAIT 狀態有什么關系?"
參考答案:
=====================================================================
原因:服務端關閉連接后進入 TIME_WAIT 狀態(默認2MSL,約60秒),此期間端口被占用。
解決:setsockopt(fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt)) 允許重用 TIME_WAIT 狀態的端口。
風險:可能接收舊連接的殘留數據(需序列號校驗防護)。
第2題(TCP三次握手和四次揮手的流程)
"客戶端調用 connect() 后卡住,抓包顯示SYN報文無響應。請描述TCP三次握手流程,并分析哪些情況會導致SYN丟失?"
參考答案:
=====================================================================
握手流程:
Client → SYN(序列號x)→ Server
Server → SYN+ACK(序列號y,確認號x+1)→ Client
Client → ACK(確認號y+1)→ Server
SYN丟失原因:
防火墻攔截
服務端未監聽端口
網絡擁塞(超過重傳次數后返回 ETIMEDOUT)
第3題(select/poll/epoll 的性能比較)
"使用 select() 管理2000個并發連接時CPU占用率飆升。請對比 select/poll/epoll 的性能差異,為什么 epoll 更適合萬級連接?"
參考答案:
=====================================================================
?select 、?O(n) 、?固定大小fd_set 、?FD_SETSIZE(1024) 、
?poll 、?O(n) 、?動態數組 、?系統文件描述符上限 、
、epoll 、?O(1) 、?紅黑樹+就緒鏈表 、?十萬級 、
epoll 優勢:
僅返回就緒的fd,避免遍歷所有連接
邊緣觸發(ET)模式減少事件觸發次
第4題( epoll 的邊緣觸發模式)
在 epoll 的邊緣觸發模式下,為什么讀取數據時必須循環調用 recv() 直到返回 EAGAIN?水平觸發模式會有何不同?"
參考答案:
=====================================================================
ET模式:僅在fd狀態變化時通知一次,必須一次性讀完所有數據(否則剩余數據不會觸發新事件)
LT模式:只要緩沖區有數據就持續通知,可多次讀取
第5題( TCP/IP協議棧中MTU和MSS的關系)
發送2000字節數據時,抓包顯示被拆成2個IP分片。請說明TCP/IP協議棧中MTU和MSS的關系,如何避免IP分片?"
參考答案:
=====================================================================
MTU:網絡層最大傳輸單元(以太網默認1500字節)
MSS:傳輸層最大段大小(MTU - IP頭 - TCP頭 = 1460字節)
避免分片:
設置 setsockopt(fd, IPPROTO_TCP, TCP_MAXSEG, &size) 限制MSS
或由TCP自動分片(推薦)
第6題( 選擇UDP而非TCP)
"實時游戲服務需要低延遲通信,為什么選擇UDP而非TCP?如何在UDP上實現可靠傳輸?"
參考答案:
=====================================================================
UDP優勢:
無連接建立開銷(0-RTT)
無擁塞控制,可自定義重傳策略
可靠傳輸方案:
添加序列號+確認機制(類似QUIC協議)
前向糾錯(FEC)減少重傳
可以適當解釋什么是 FEC 技術,工作原理
模擬面試QT
第1題( 信號槽的本質)
在開發聊天軟件時,需實現“發送消息按鈕點擊后自動刷新消息列表”。如何解耦按鈕與消息列表的邏輯?
1:信號槽的本質是什么?與回調函數有何區別?410
2:connect的第五個參數(Qt::ConnectionType)有哪些?跨線程通信應選哪種?38:
3:信號槽的缺點是什么?如何優化高頻信號場景(如實時繪圖)?
參考答案:
=====================================================================
本質與區別:
信號槽是基于元對象系統(Meta-Object System)的回調機制,通過moc預編譯器生成中間代碼,將信號與槽的索引存儲在staticMetaObject中,通過映射表(Map)實現動態連接
對比回調函數:信號槽支持類型安全檢測(參數類型/數量必須匹配)和松散耦合(發送者無需知道接收者),但比直接回調慢約10倍(需遍歷連接、參數編組/解組)
連接方式與選擇
Qt::DirectConnection:槽函數在發送者線程同步執行(單線程常用)。
Qt::QueuedConnection:槽函數在接收者線程異步執行(跨線程安全)
優化策略:
避免高頻信號:如實時數據流改用定時器聚合刷新(QTimer)。
減少連接數:用Qt::UniqueConnection防止重復連接。
批處理數據:自定義信號傳遞數據容器(如QVector而非單條數據)
第2題( 繼承QThread)
視頻轉碼工具需后臺線程處理文件轉換,防止UI卡死。
1:繼承QThread重寫run() vs. QObject::moveToThread(),哪種是Qt官方推薦?為什么?910
2:子線程中為何不能直接操作UI控件?如何安全更新UI?
參考答案:
=====================================================================
推薦moveToThread:
原因:繼承QThread會混淆線程生命周期和任務邏輯;moveToThread將業務對象移至線程,通過信號槽通信更符合Qt設計哲學
線程安全規則:
禁止直接操作UI:GUI操作僅限主線程(如修改QLabel文本)。
安全更新方式:通過信號槽(自動使用QueuedConnection)傳遞數據,由主線程執行UI更新
第3題( 局域網內文件傳輸功能)
引子:實現局域網內文件傳輸功能,需穩定傳輸大文件。
1:描述Qt下TCP服務器與客戶端的通信流程,關鍵類有哪些?310
2:如何檢測網絡斷開?如何處理粘包問題?
3:QTcpSocket::readyRead()信號為何可能多次觸發?如何保證完整讀取數據?
參考答案:
=====================================================================
斷網檢測:
處理QTcpSocket::errorOccurred信號,常見錯誤QAbstractSocket::RemoteHostClosedError。
第4題(表格控件(QTableView)添加單元格懸浮提示)
為表格控件(QTableView)添加單元格懸浮提示。
- 如何不繼承QTableView實現懸浮事件監聽?
- QStandardItemModel與QAbstractItemModel的區別?如何自定義模型?
參考答案:
=====================================================================
使用事件過濾器監聽懸浮事件:
bool Widget::eventFilter(QObject *obj,QEvent *event){if(obj==tableView && event->type()==QEvent::HoverMove){QHoverEvent *he=static_cast<QHoverEvent*>(event);QModelIndex index=tableView->indexAt(he->pos());showTooltip(index);//顯示提示return true;//攔截事件}return QObject::eventFilter(obj,event); }回答邏輯:
事件過濾器過濾出懸浮事件,判斷懸浮事件坐標是否在tabWidget上面,如果在,判斷在哪個 cell里面,然后做出對應提示
QStandardItemModel:
簡單易用,內存存儲數據,適合小型數據集。
自定義模型:繼承QAbstractItemModel,重寫rowCount()、data()等方法,支持懶加載/大數據集
第5題(整個窗口實現快捷鍵保存功能)
為整個窗口實現快捷鍵保存功能(Ctrl+S),無論焦點在哪個控件上。
使用事件過濾器:
- 如何在不修改子控件代碼的情況下全局捕獲快捷鍵?
- 事件過濾器與重寫event()函數有何區別?
參考答案:
=====================================================================
//1.安裝事件過濾器到主窗口
bool MainWindow::eventFilter(QObject *obj,QEvent *event)
{if(event->type()==QEvent::KeyPress){QKeyEvent *KeyEvent=static_cast<OKeyEvent*>(event);if(keyEvent->modifiers()==Qt::ControlModifier && keyEvent->key()==Qt::Key_s){saveFile();//觸發保存return true;//攔截事件}}return QObject::eventFilter(obj,event);//其他事件繼續傳遞
}
//安裝:qApp->installEventFilter(this);(qApp指向全局QApplication對象)回答邏輯:過濾出鍵盤事件后,判斷是否按了 ctrl + s,如果是 則觸發保存函數=
區別:
事件過濾器:外部攔截(可監聽任何對象的事件)
重寫event():內部處理(僅當前對象有效)
第6題(根據網絡狀態切換不同處理函數)
根據網絡狀態切換不同處理函數(connected()/disconnected())。
參考答案:
=====================================================================
01.如何將信號關聯到重載函數?
connect(socket,static_cast<void(QTcpSocket::*) (QAbstractSocket::SocketError)>(&QTcpSocket:: errorOccurred), this,&MyClass::handleError);02.Lambda捕獲this指針有何風險?
//2.Lambda中捕獲this需注意生命周期 connect(socket,&QTcpSocket::connected,[this](){//若this已銷毀->程序崩潰//解決方案,用QPointer或disconnect });
第7題(動態創建的子窗口關閉后未被釋放)
動態創建的子窗口關閉后未被釋放。
- 如何利用Qt機制自動釋放內存?
- QPointer與普通指針的區別?
參考答案:
=====================================================================
設置父子組件,父組件析構自動調用子組件析構
QPointer析構的時候,會自動置空該指針,防止野指針。
QPointer<QLabel> label=new QLabel;
delete label;
if(label){/*不會進入,label自動變為nullptr*/}第8題(軟件運行時切換中英文界面)?
軟件運行時切換中英文界面。
- 如何實現tr()文本的動態刷新?
- 哪些文本需要特殊處理?
參考答案:
=====================================================================
重寫 changeEvent:
當控件的狀態屬性發生改變時(如啟用/禁用、焦點變化、語言切換、樣式更新等),Qt 會自動調用該函數。常見場景包括:
//1.重寫changeEvent() void Widget::changeEvent(QEvent *event){if(event->type()==QEvent::LanguageChange){ui->retranslateUi(this);//更新UI文本setWindowTitle(tr("Main Window"));} }QWidget::changeEvent(event); }動態文本需用tr()包裹:
錯誤示例:ui->label->setText("用戶名");
正確示例:ui->label->setText(tr("Username"));
第9題(多次點擊按鈕導致槽函數重復執行)?
多次點擊按鈕導致槽函數重復執行
如何確保信號只連接一次?
參考答案:
=====================================================================
//方案1:使用Qt::UniqueConnection(推薦) connect(btn,&QPushButton::clicked,this,&MyClass::onClick,Qt::UniqueConnection);//自動防重復 //方案2:手動斷開舊連接 disconnect(btn,SIGNAL(clicked()),this,SLOT(onClick())); connect(btn,SIGNAL(clicked()),this,SLOT(onClick()));
第10題(多次點擊按鈕導致槽函數重復執行)?
保存窗口大小、位置等配置到INI文件
- 如何讀寫INI文件?
- 配置項不存在時如何設置默認值?
參考答案:
=====================================================================
QSettings settings("config.ini",QSettings::IniFormat); //讀取配置(帶默認值) int width=settings.value("Window/width",800).toInt();//默認800 //寫入配置 settings.setValue("Window/height",600);
第11題(多次點擊按鈕導致槽函數重復執行)?
程序點擊按鈕后崩潰
1.如何快速定位崩潰代碼行?2.常見崩潰原因有哪些?
參考答案:
=====================================================================
調試步驟:
1.在Debug模式運行程序
2.崩潰時查看調用堆棧(Call Stack)
3.定位到最頂層的用戶代碼
常見崩潰原因:
1.空指針訪問:if (!obj) return;
2.數組越界:for(int i=0; i<list.size(); ++i)
3.野指針:connect后對象被提前刪除
模擬面試_UART總線
第1題(UART總線的特性?)
UART總線的特性?
參考答案:
=====================================================================
全雙工、異步、串行
第2題(UART總線協議格式??)
描述一下UART總線協議格式?解釋起始位、停止位的含義?
參考答案:
=====================================================================
描述一下UART總線協議格式?解釋起始位、停止位的含義?
協議格式
起始位:產生下降沿信號,標志著數據傳輸的開始
停止位:產生上升沿信號,標志著數據傳輸的結束
數據位:5~9位的數據位
奇偶校驗位:占用一位數據位,用于標識這段數據的高電平數是否符合奇數或者偶數,可以不啟用
起始位:低電平脈沖,宣告數據傳輸開始,是接收方同步的觸發信號。
停止位:高電平脈沖,標志幀結束,保證線路回歸空閑狀態并為下一幀準備。

第3題(為什么使用UART總線通信時需要設置波特率,通信雙方波特率不一致會出現什么情況?)
為什么使用UART總線通信時需要設置波特率,通信雙方波特率不一致會出現什么情況?
參考答案:
=====================================================================
設置波特率:
01.UART是異步通信,波特率用于替代時鐘同步,同步兩端的通信時序。
02.發送端按此刻度輸出數據,接收端依此采樣信號,確保數據位對齊
03.抗干擾與穩定性保障:(波特率與傳輸距離、噪聲環境強相關)
04.較低波特率(如9600 bps)在長距離或高噪聲環境中更穩定,因每比特持續時間長,抗干擾能力強;高速波特率(如115200 bps)則需短距離低干擾環境.波特率不一致:
傳輸數據錯位導致數據丟失。
嚴重錯位導致通信斷連。UART允許的波特率誤差通常需 ≤3%。
第4題(你常用的串口協議格式是什么)
你常用的串口協議格式是什么??
參考答案:
=====================================================================
常用的串口協議格式:8N1協議 + 9600
第5題(請寫出你了解的串行接口?)
請寫出你了解的串行接口 ??
參考答案:
=====================================================================
UART總線、IIC總線、SPI總線、USB總線
模擬面試_IIC總線
第1題(IIC總線?)
你使用過IIC總線嗎?使用在哪里?對IIC總線的了解有哪些?
參考答案:
=====================================================================
IIC總線一般用于
01.數據采集設備,比如溫濕度傳感器,壓力傳感器等
02.顯示設備控制,OLED、LCD屏幕驅動
03.雙MCU之間的通信了解自由發揮
01.半雙工,同步,串口通信總線
02.多主多從,一般一主多從
03.低成本,低功耗
04.雙線設計,硬件電路簡單
第2題(IIC總線的硬件連接?硬件連接的特點?)
IIC總線的硬件連接?硬件連接的特點?
參考答案:
=====================================================================
IIC總線是雙線設計,一根SCL串行時鐘線,一根SDA串行數據線
特點:開漏設計,雙線均連接上拉電阻,空閑時保持高電平(利于傳輸的穩定性)
第3題(IIC總線的時序是什么樣子?)
IIC總線的時序是什么樣子?描述一下IIC總線的數據傳輸信號的時序?
參考答案:
=====================================================================
時序框架:
空閑保持高電平
起始信號,SCL處于高電平時,SDA產生下降沿信號
停止信號,SCL處于高電平時,SDA產生上升沿信號
數據傳輸:
SCL處于高電平時,電平不允許變化,此時讀取數據
SCL處于低電平時,允許電平變化,此時寫入數據
每次傳輸8字節數據,必然跟隨一個對端的應答信號(ACK/NACK)
第4題(使用IIC總線接收數據時,需要注意哪些問題??)
使用IIC總線接收數據時,需要注意哪些問題?
參考答案:
=====================================================================
01.接收數據時,先保證發出發送數據信號,告訴從機需要接收數據的起始地址,
02.再發出接收數據信號,接收數據,每次接收數據回復ACK包
03.在結束數據接收時,確保發出NACK包,這樣從機才會結束發送數據
第5題(使用IIC讀取數據時,為什么需要讀寫轉換?為什么需要發送NACK非應答信號???)
使用IIC讀取數據時,為什么需要讀寫轉換?為什么需要發送NACK非應答信號?
01.讀取數據前,需要向從機發送讀取時的起始地址,方便后續讀取時從該地址開始讀取數據
02.讀取數據結束后,確保主機發送從機NACK信號,以便結束從機的數據發送
03.不進行該操作會導致從機數據繼續發送,干擾后續的數據傳輸操作(導致數據錯亂)



與映射(Map))



的分子動力學模擬框架,是MD的GPT時刻還是概念包裝?)


)

https://www.bilibili.com/video/BV1)






