1. 實現功能
M4-3: 智能后處理 - 停頓感知增強版 (終極版)
本腳本是 M4-3 的重大升級,引入了“停頓感知”能力:
- 利用 Whisper 分段信息: 將 Whisper 的 segments 間的自然停頓作為強信號 ([P]) 提供給 LLM。
- 全新 Prompt: 設計了專門的 Prompt,指導 LLM 理解并利用 [P] 標記,實現更精準、更自然的斷句。
- 保留了之前版本的所有優點:詳細的耗時統計、清晰的流程、支持多種模型加載方式等。
2.運行效果
conda activate whisper
(base) root@DESKTOP-8IU6393:/home/gpu3090# conda activate whisper
/root/anaconda3/envs/whisper/bin/python /home/gpu3090/vscode/M4-實用技巧/M4-3-大模型接入.py
(whisper) root@DESKTOP-8IU6393:/home/gpu3090# /root/anaconda3/envs/whisper/bin/python /home/gpu3090/vscode/M4-實用技巧/M4-3-大模型接入.py
🚀 開始 Whisper 語音轉錄與智能后處理流程 (v4.0 - 停頓感知版)
======================================================================
🔧 步驟 1: 正在加載 Whisper 模型 'large-v3' 到 cuda...🌐 使用在線模型: large-v3
? 模型加載完成。耗時: 0:00:27.998095🎙? 步驟 2: 正在轉錄音頻文件...📄 文件路徑: /home/gpu3090/vscode/M4-實用技巧/../audio/26.mp3🌍 語言設置: zh
100%|██████████████████████████| 17888/17888 [00:29<00:00, 608.34frames/s]
? 音頻轉錄完成。耗時: 0:00:32.950243
📊 原始文本長度: 508 字符, 分段數: 57📝 原始轉錄文本 (無標點拼接):
--------------------------------------------------
作品二十六號我們家的后園有半畝空地母親說,讓她慌著怪可惜的你們那么愛吃花生,就開辟出來種花生吧我們姐弟幾個都很高興埋種、翻地、播種、澆水沒過幾個月,居然收獲了母親說,今晚我們過一個收獲節請你們父親也來嘗嘗我們的新花生,好不好我們都說好母親把花生做成了好幾樣食品還吩咐就在后園的茅亭里過這個節晚上天色不太好可是父親也來了實在很難得父親說,你們愛吃花生嗎我們爭著答應,愛誰能把花生的好處說出來姐姐說,花生的味兒美哥哥說,花生可以榨油我說,花生的價錢便宜誰都可以買來吃,都喜歡吃這就是它的好處父親說,花生的好處很多有一樣最可貴它的果實埋在地里不像桃子、石榴、蘋果那樣把鮮紅嫩綠的果實高高地掛在枝頭上使人一見就生愛慕之心你們看它矮矮地長在地上等到成熟了就會吃了也不能立刻分辨出來它有沒有果實必須挖出來才知道我們都說是母親也點點頭父親接下去說所以你們要像花生它雖然不好看可是很有用不是外表好看而沒有實用的東西我說那么人要做有用的人不是外表好看不要做只講體面而對別人沒有好處的人了父親說對這是我對你們的希望我們談到夜深才散花生做的食品都吃完了父親的話卻深深地印在我的心上歡迎光臨普通話學習網3w.png.compthxx.com
--------------------------------------------------🔄 步驟 3 & 4: 正在進行熱詞替換與中英文空格處理 (逐段進行)...
? 熱詞與空格處理完成。耗時: 0:00:00.002897🤖 步驟 5: 正在調用 LLM 'qwen3:14b' 進行停頓感知智能標點...🔄 正在發送請求到 Ollama...? Ollama 處理完成。
? LLM 標點處理完成。耗時: 0:01:18.138540
📊 最終文本長度: 3054 字符? LLM 處理后最終文本:
==================================================
<think>
好的,我現在需要處理用戶提供的這段文本,添加合適的標點。首先,我要仔細閱讀用戶的要求,確保完全理解任務。用戶提到,原始文本由多個語音片段拼接而成,使用了[P]標記表示自然停頓點,這些地方需要優先考慮使用逗號或句號。同時,不能增刪或改動原文內容,最終輸出要移除所有[P]標記。首先,我會通讀整個文本,識別所有[P]的位置,并考慮每個位置應該使用哪種標點。例如,第一個[P]出現在“作品二十六號”之后,這里可能是一個段落的開始,所以可能需要句號,但根據上下文,可能更適合用逗號,不過需要看后面的內容。不過,根據指導原則,[P]是強烈的斷句提示,所以應該優先處理。接下來,我會逐段處理。例如,“作品二十六號[P]我們家的后園有半畝空地”這里,[P]后面是新的句子,所以應該在“作品二十六號”后面加句號,然后開始新句。不過,可能“作品二十六號”是一個標題,所以可能需要單獨處理,但用戶沒有說明,所以按照普通文本處理。然后,檢查每個[P]的位置,替換為逗號或句號。例如,“母親說,讓她慌著怪可惜的[P]你們那么愛吃花生”這里,[P]后面是新的句子,所以應該在“怪可惜的”后面加句號,然后開始新句。不過原句中的逗號可能已經存在,需要確認是否正確。另外,要注意句子的長度,如果在沒有[P]的片段內部句子過長,可以添加逗號。例如,“埋種、翻地、播種、澆水”這里可能需要逗號分隔動作,但原句中沒有,所以可能不需要,但根據指導原則,可以添加。還需要注意引號的使用,比如“母親說,讓她慌著怪可惜的”中的逗號是否正確,可能需要調整為句號,但用戶要求不能改動原文,所以只能在[P]處處理。最后,處理完所有[P]后,移除這些標記,并檢查整個文本的標點是否流暢,是否符合中文的標點習慣,同時確保沒有改動原文內容。現在,我需要逐步處理每個[P]的位置,并確保標點正確。例如:- 作品二十六號[P] → 作品二十六號。
- 母親說,讓她慌著怪可惜的[P] → 母親說,讓她慌著怪可惜的。
- 你們那么愛吃花生,就開辟出來種花生吧[P] → 你們那么愛吃花生,就開辟出來種花生吧。
- 我們姐弟幾個都很高興[P] → 我們姐弟幾個都很高興。
- 埋種、翻地、播種、澆水[P] → 埋種、翻地、播種、澆水。
- 沒過幾個月,居然收獲了[P] → 沒過幾個月,居然收獲了。
- 母親說,今晚我們過一個收獲節[P] → 母親說,今晚我們過一個收獲節。
- 請你們父親也來嘗嘗我們的新花生,好不好[P] → 請你們父親也來嘗嘗我們的新花生,好不好。
- 我們都說好[P] → 我們都說好。
- 母親把花生做成了好幾樣食品[P] → 母親把花生做成了好幾樣食品。
- 還吩咐就在后園的茅亭里過這個節[P] → 還吩咐就在后園的茅亭里過這個節。
- 晚上天色不太好[P] → 晚上天色不太好。
- 可是父親也來了[P] → 可是父親也來了。
- 實在很難得[P] → 實在很難得。
- 父親說,你們愛吃花生嗎[P] → 父親說,你們愛吃花生嗎。
- 我們爭著答應,愛[P] → 我們爭著答應,愛。
- 誰能把花生的好處說出來[P] → 誰能把花生的好處說出來。
- 姐姐說,花生的味兒美[P] → 姐姐說,花生的味兒美。
- 哥哥說,花生可以榨油[P] → 哥哥說,花生可以榨油。
- 我說,花生的價錢便宜[P] → 我說,花生的價錢便宜。
- 誰都可以買來吃,都喜歡吃[P] → 誰都可以買來吃,都喜歡吃。
- 這就是它的好處[P] → 這就是它的好處。
- 父親說,花生的好處很多[P] → 父親說,花生的好處很多。
- 有一樣最可貴[P] → 有一樣最可貴。
- 它的果實埋在地里[P] → 它的果實埋在地里。
- 不像桃子、石榴、蘋果那樣[P] → 不像桃子、石榴、蘋果那樣。
- 把鮮紅嫩綠的果實高高地掛在枝頭上[P] → 把鮮紅嫩綠的果實高高地掛在枝頭上。
- 使人一見就生愛慕之心[P] → 使人一見就生愛慕之心。
- 你們看它矮矮地長在地上[P] → 你們看它矮矮地長在地上。
- 等到成熟了[P] → 等到成熟了。
- 就會吃了[P] → 就會吃了。
- 也不能立刻分辨出來[P] → 也不能立刻分辨出來。
- 它有沒有果實[P] → 它有沒有果實。
- 必須挖出來才知道[P] → 必須挖出來才知道。
- 我們都說是[P] → 我們都說是。
- 母親也點點頭[P] → 母親也點點頭。
- 父親接下去說[P] → 父親接下去說。
- 所以你們要像花生[P] → 所以你們要像花生。
- 它雖然不好看[P] → 它雖然不好看。
- 可是很有用[P] → 可是很有用。
- 不是外表好看[P] → 不是外表好看。
- 而沒有實用的東西[P] → 而沒有實用的東西。
- 我說[P] → 我說。
- 那么人要做有用的人[P] → 那么人要做有用的人。
- 不是外表好看[P] → 不是外表好看。
- 不要做只講體面[P] → 不要做只講體面。
- 而對別人沒有好處的人了[P] → 而對別人沒有好處的人了。
- 父親說[P] → 父親說。
- 對[P] → 對。
- 這是我對你們的希望[P] → 這是我對你們的希望。
- 我們談到夜深才散[P] → 我們談到夜深才散。
- 花生做的食品都吃完了[P] → 花生做的食品都吃完了。
- 父親的話卻深深地印在我的心上[P] → 父親的話卻深深地印在我的心上。
- 歡迎光臨普通話學習網[P] → 歡迎光臨普通話學習網。
- 3w.png.com[P] → 3w.png.com。
- pthxx.com → pthxx.com。處理完所有[P]后,需要檢查是否有遺漏,確保所有[P]都被替換,并且標點正確。同時,檢查句子的連貫性和標點是否符合中文習慣,比如逗號和句號的使用是否恰當,引號內的標點是否正確等。最后,確保沒有改動原文的任何漢字或英文單詞,只添加了標點,并移除了所有[P]標記。
</think>作品二十六號。我們家的后園有半畝空地。母親說,讓她慌著怪可惜的。你們那么愛吃花生,就開辟出來種花生吧。我們姐弟幾個都很高興。埋種、翻地、播種、澆水。沒過幾個月,居然收獲了。母親說,今晚我們過一個收獲節。請你們父親也來嘗嘗我們的新花生,好不好?我們都說好。母親把花生做成了好幾樣食品。還吩咐就在后園的茅亭里過這個節。晚上天色不太好。可是父親也來了。實在很難得。父親說,你們愛吃花生嗎?我們爭著答應,愛。誰能把花生的好處說出來?姐姐說,花生的味兒美。哥哥說,花生可以榨油。我說,花生的價錢便宜。誰都可以買來吃,都喜歡吃。這就是它的好處。父親說,花生的好處很多。有一樣最可貴。它的果實埋在地里。不像桃子、石榴、蘋果那樣。把鮮紅嫩綠的果實高高地掛在枝頭上。使人一見就生愛慕之心。你們看它矮矮地長在地上。等到成熟了,就會吃了。也不能立刻分辨出來。它有沒有果實?必須挖出來才知道。我們都說是。母親也點點頭。父親接下去說。所以你們要像花生。它雖然不好看。可是很有用。不是外表好看,而沒有實用的東西。我說,那么人要做有用的人。不是外表好看,不要做只講體面,而對別人沒有好處的人了。父親說,對。這是我對你們的希望。我們談到夜深才散。花生做的食品都吃完了。父親的話卻深深地印在我的心上。歡迎光臨普通話學習網。3w.png.com。pthxx.com
==================================================💾 步驟 6: 正在保存最終文本...
📁 文件已保存: /home/gpu3090/26_whisper_final.txt
📁 文件已保存: /home/gpu3090/26_whisper_original.txt
📁 原始文本已保存: /home/gpu3090/26_whisper_original.txt
? 文件保存完成。耗時: 0:00:00.000570🎉 全部流程完成!
======================================================================
?? 各步驟耗時統計:步驟1 (模型加載): 0:00:27.998095步驟2 (音頻轉錄): 0:00:32.950243步驟3&4 (預處理): 0:00:00.002897步驟5 (LLM標點): 0:01:18.138540步驟6 (文件保存): 0:00:00.000570? 總計耗時: 0:02:19.314213📁 輸出文件:📄 最終文本: ./26_whisper_final.txt📄 原始文本: ./26_whisper_original.txt
======================================================================
3.實現過程
(base) root@DESKTOP-8IU6393:/home/gpu3090# conda activate whisper
/root/anaconda3/envs/whisper/bin/python /home/gpu3090/vscode/M4-實用技巧/M4-3-大模型接入.py
3.1 報錯處理
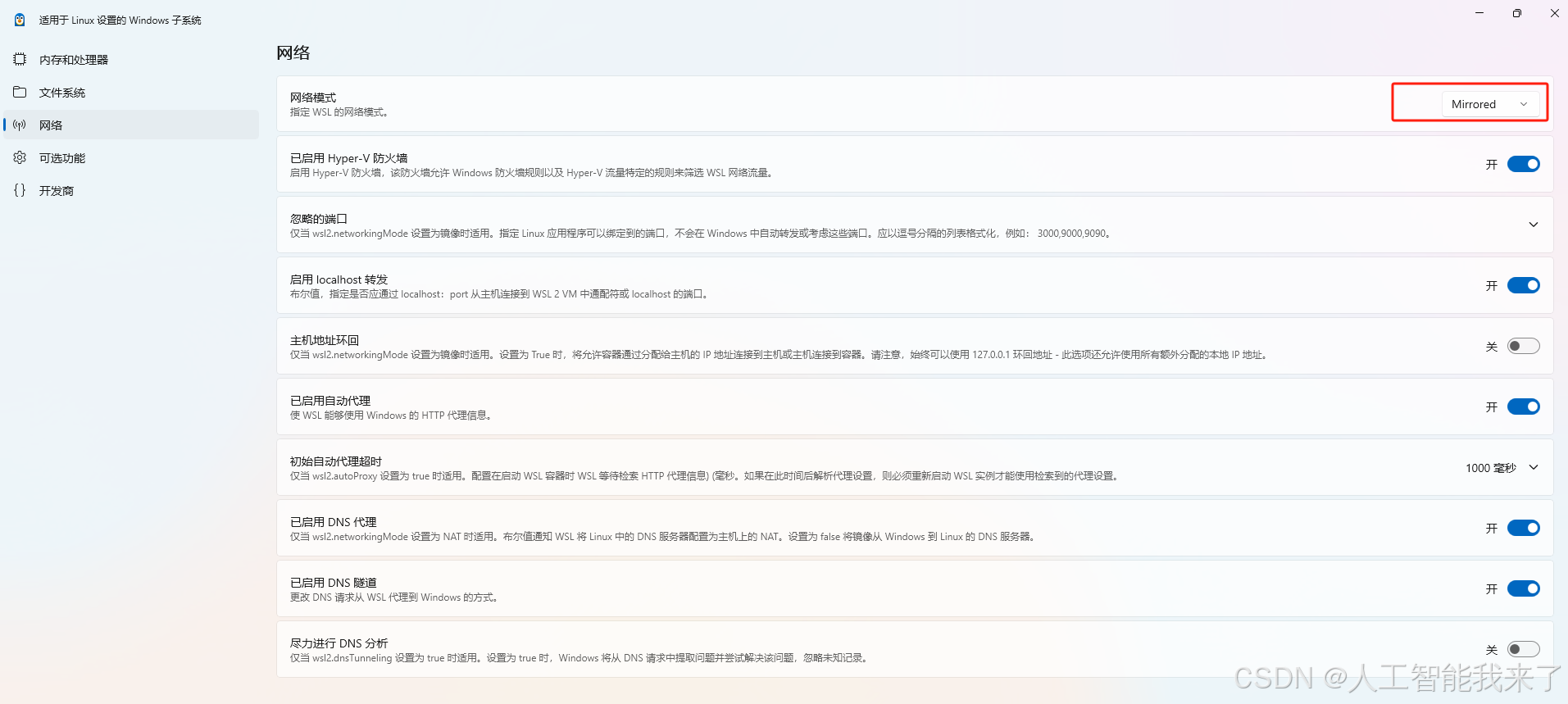
當遇到ollama連接失敗的時候,配置網絡模式為鏡像,重啟wsl即可

C:\Users\Administrator>wsl -- shutdown
wsl: 檢測到 localhost 代理配置,但未鏡像到 WSL。NAT 模式下的 WSL 不支持 localhost 代理。
Shutdown scheduled for Sun 2025-08-10 12:30:30 CST, use 'shutdown -c' to cancel.C:\Users\Administrator>wsl -u root
wsl: 檢測到 localhost 代理配置,但未鏡像到 WSL。NAT 模式下的 WSL 不支持 localhost 代理。
(base) root@DESKTOP-8IU6393:/mnt/c/Users/Administrator# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 198.18.0.1 netmask 255.255.255.252 broadcast 198.18.0.3inet6 fdfe:dcba:9876::1 prefixlen 126 scopeid 0x0<global>ether 00:15:5d:b2:6a:b2 txqueuelen 1000 (Ethernet)RX packets 10 bytes 628 (628.0 B)RX errors 0 dropped 0 overruns 0 frame 0TX packets 20 bytes 1376 (1.3 KB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0eth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1492inet 192.168.1.8 netmask 255.255.255.0 broadcast 192.168.1.255inet6 2409:8a5c:326:cf70:7d68:89e6:88c5:f000 prefixlen 128 scopeid 0x0<global>inet6 fe80::e56e:68b6:c226:6373 prefixlen 64 scopeid 0x20<link>inet6 2409:8a5c:326:cf70:1720:1956:e512:56ac prefixlen 64 scopeid 0x0<global>ether f0:2f:74:1a:39:e7 txqueuelen 1000 (Ethernet)RX packets 0 bytes 0 (0.0 B)RX errors 0 dropped 0 overruns 0 frame 0TX packets 20 bytes 1900 (1.9 KB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536inet 127.0.0.1 netmask 255.0.0.0inet6 ::1 prefixlen 128 scopeid 0x10<host>loop txqueuelen 1000 (Local Loopback)RX packets 12 bytes 972 (972.0 B)RX errors 0 dropped 0 overruns 0 frame 0TX packets 12 bytes 972 (972.0 B)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0loopback0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500ether 00:15:5d:81:e5:df txqueuelen 1000 (Ethernet)RX packets 0 bytes 0 (0.0 B)RX errors 0 dropped 0 overruns 0 frame 0TX packets 0 bytes 0 (0.0 B)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0(base) root@DESKTOP-8IU6393:/mnt/c/Users/Administrator#
3.2 代碼
import os
import whisper
import datetime
import torch
import re
import ollama# --- 1. 文本處理函數 ---
def apply_replacements(text, replacement_map):"""對單個文本片段應用熱詞替換規則。"""for old_word, new_word in replacement_map.items():text = text.replace(old_word, new_word)return textdef add_spaces_around_english(text):"""為中英文混排文本自動添加空格。"""pattern1 = re.compile(r'([\u4e00-\u9fa5])([a-zA-Z0-9]+)')pattern2 = re.compile(r'([a-zA-Z0-9]+)([\u4e00-\u9fa5])')text = pattern1.sub(r'\1 \2', text)text = pattern2.sub(r'\1 \2', text)return text# <--- 重點修改:此函數現在接收 segments,并使用帶 [P] 的 Prompt ---
def enhance_punctuation_with_llm(segments, llm_model_name):"""使用 LLM 為文本智能添加標點,利用 Whisper 的分段作為停頓信號。"""# 1. 在 segment 之間插入 [P] 標記作為停頓提示# ["你好", "今天天氣不錯"] -> "你好[P]今天天氣不錯"text_with_pauses = "[P]".join([s['text'].strip() for s in segments if s['text'].strip()])if not text_with_pauses.strip():print("?? 文本內容為空,跳過 LLM 處理。")return "" # 返回空字符串# 2. 構建新的、更智能的 Promptprompt = f"""# 角色
你是一位頂級的中文文案編輯,能深刻理解語音節奏和書面表達的轉換。# 任務
為下面的原始文本添加標點。這段文本由多個語音片段拼接而成,我使用了特殊標記 `[P]` 來表示原始語音中的自然停頓點。# 指導原則
1. **關鍵指令**: `[P]` 標記處是強烈的斷句提示。你應該在這些位置優先考慮使用逗號(,)或句號(。)。
2. **句內微調**: 即使在沒有 `[P]` 標記的片段內部,如果句子過長,你也可以根據邏輯添加逗號。
3. **忠實內容**: 絕對不允許增刪或改動原文的任何漢字或英文單詞。
4. **最終輸出**: 在最終結果中,必須移除所有的 `[P]` 標記。# 待處理文本
---
{text_with_pauses}
---# 輸出要求
直接輸出經過你精細編輯和標點優化后的最終文本,確保不含 `[P]` 標記。"""# 3. 調用 Ollama APItry:print(" 🔄 正在發送請求到 Ollama...")response = ollama.chat(model=llm_model_name,messages=[{'role': 'user', 'content': prompt}],options={'temperature': 0.2} # 較低的溫度讓輸出更穩定)punctuated_text = response['message']['content'].strip()print(" ? Ollama 處理完成。")return punctuated_textexcept Exception as e:print(f"? 調用 Ollama API 時出錯: {e}")# 出錯時,返回一個不帶標點的、拼接好的文本作為后備fallback_text = " ".join([s['text'].strip() for s in segments])print(" ?? 將使用未處理的原始拼接文本繼續。")return fallback_textdef save_text_file(text, output_path):"""將文本保存為 TXT 文件。"""with open(output_path, 'w', encoding='utf-8') as txt_file:txt_file.write(text)print(f"📁 文件已保存: {os.path.abspath(output_path)}")# --- 2. 主流程函數 ---
def run_transcription_pipeline(model_name, media_path, language, replacement_map, llm_model_name):"""執行完整的轉錄和后處理流程,每一步都有詳細的耗時統計。"""print("🚀 開始 Whisper 語音轉錄與智能后處理流程 (v4.0 - 停頓感知版)")print("=" * 70)total_start_time = datetime.datetime.now()script_dir = os.path.dirname(os.path.abspath(__file__)) if '__file__' in locals() else '.'output_dir = script_dirdevice = "cuda" if torch.cuda.is_available() else "cpu"# --- 步驟 1: 加載模型 (代碼不變) ---# ... (與您提供的代碼完全相同)step1_start = datetime.datetime.now()print(f"🔧 步驟 1: 正在加載 Whisper 模型 '{model_name}' 到 {device}...")if os.path.exists(model_name) or '/' in model_name or model_name.endswith('.pt'):model = whisper.load_model(model_name, device=device)print(f" 📂 使用本地模型文件: {model_name}")else:model = whisper.load_model(model_name, device=device)print(f" 🌐 使用在線模型: {model_name}")step1_end = datetime.datetime.now()step1_duration = step1_end - step1_startprint(f"? 模型加載完成。耗時: {step1_duration}\n")# --- 步驟 2: 轉錄音頻 (代碼不變) ---step2_start = datetime.datetime.now()print(f"🎙? 步驟 2: 正在轉錄音頻文件...")print(f" 📄 文件路徑: {media_path}")print(f" 🌍 語言設置: {language}")result = model.transcribe(media_path, language=language, verbose=False)# <--- 修改:現在我們保留 segments,原始文本僅用于展示 ---original_segments = result['segments']original_text_display = result['text'].strip()step2_end = datetime.datetime.now()step2_duration = step2_end - step2_startprint(f"? 音頻轉錄完成。耗時: {step2_duration}")print(f"📊 原始文本長度: {len(original_text_display)} 字符, 分段數: {len(original_segments)}")print("\n📝 原始轉錄文本 (無標點拼接):")print("-" * 50)print(original_text_display)print("-" * 50 + "\n")# <--- 修改:后續處理現在基于 segments ---# --- 步驟 3 & 4: 逐段進行熱詞替換和空格處理 ---step3_4_start = datetime.datetime.now()print("🔄 步驟 3 & 4: 正在進行熱詞替換與中英文空格處理 (逐段進行)...")processed_segments = []for segment in original_segments:# 復制 segment 以免修改原始數據new_segment = segment.copy()# 步驟 3: 熱詞替換text = apply_replacements(new_segment['text'], replacement_map)# 步驟 4: 中英文空格text = add_spaces_around_english(text)new_segment['text'] = textprocessed_segments.append(new_segment)step3_4_end = datetime.datetime.now()step3_4_duration = step3_4_end - step3_4_startprint(f"? 熱詞與空格處理完成。耗時: {step3_4_duration}\n")# --- 步驟 5: LLM 智能標點 (利用停頓信號) ---step5_start = datetime.datetime.now()print(f"🤖 步驟 5: 正在調用 LLM '{llm_model_name}' 進行停頓感知智能標點...")# <--- 修改:將處理過的 segments 傳遞給 LLM 函數 ---final_text = enhance_punctuation_with_llm(processed_segments, llm_model_name)step5_end = datetime.datetime.now()step5_duration = step5_end - step5_startprint(f"? LLM 標點處理完成。耗時: {step5_duration}")print(f"📊 最終文本長度: {len(final_text)} 字符\n")print("? LLM 處理后最終文本:")print("=" * 50)print(final_text)print("=" * 50 + "\n")# --- 步驟 6: 保存文件 (邏輯簡化) ---step6_start = datetime.datetime.now()print("💾 步驟 6: 正在保存最終文本...")base_name = os.path.splitext(os.path.basename(media_path))[0]txt_path = os.path.join(output_dir, f"{base_name}_whisper_final.txt")save_text_file(final_text, txt_path)original_txt_path = os.path.join(output_dir, f"{base_name}_whisper_original.txt")save_text_file(original_text_display, original_txt_path)print(f"📁 原始文本已保存: {os.path.abspath(original_txt_path)}")step6_end = datetime.datetime.now()step6_duration = step6_end - step6_startprint(f"? 文件保存完成。耗時: {step6_duration}\n")# --- 總結統計 ---total_end_time = datetime.datetime.now()total_duration = total_end_time - total_start_timeprint("🎉 全部流程完成!")print("=" * 70)print("?? 各步驟耗時統計:")print(f" 步驟1 (模型加載): {step1_duration}")print(f" 步驟2 (音頻轉錄): {step2_duration}")print(f" 步驟3&4 (預處理): {step3_4_duration}")print(f" 步驟5 (LLM標點): {step5_duration}")print(f" 步驟6 (文件保存): {step6_duration}")print(f" ? 總計耗時: {total_duration}")print("\n📁 輸出文件:")print(f" 📄 最終文本: {txt_path}")print(f" 📄 原始文本: {original_txt_path}")print("=" * 70)# --- 3. 配置與執行 (代碼不變) ---
if __name__ == "__main__":# ... (您的配置部分完全不變)REPLACEMENT_MAP = {"烏班圖": "Ubuntu", "吉特哈布": "GitHub", "Moddy Talk": "MultiTalk","馬克道": "Markdown", "VS 扣德": "VS Code", "派森": "Python","甲瓦": "Java", "JavaScript": "JavaScript",}WHISPER_MODEL_NAME = "large-v3"MEDIA_FILE = "../audio/26.mp3"LANGUAGE = "zh"LLM_MODEL_NAME = "qwen3:14b"script_dir = os.path.dirname(os.path.abspath(__file__)) if '__file__' in locals() else '.'media_path_full = os.path.join(script_dir, MEDIA_FILE)if not os.path.exists(media_path_full):print(f"? 錯誤: 音頻文件不存在 -> {media_path_full}")print("請檢查 MEDIA_FILE 路徑設置。")else:run_transcription_pipeline(model_name=WHISPER_MODEL_NAME,media_path=media_path_full,language=LANGUAGE,replacement_map=REPLACEMENT_MAP,llm_model_name=LLM_MODEL_NAME)
開發經典增強量子優化算法(CBQOA):開創組合優化新時代)






)
)










