使用vectorStore.similaritySearch遇到問題
最近需要做一個功能,用到了es做向量數據庫。在使用vectorStore.similaritySearch查詢的時候,發現filterExpression中加的條件并沒有完全生效,導致查詢出來的數據不準確,出現了不符合metadata篩選條件的數據。然后研究了一下,發現了問題所在。
先說結論,Spring AI調用es
elasticsearchClient.search方法查詢的時候,使用的是filter過濾,用的是queryString。導致出現特殊字符的時候,沒有轉義的話,會出現歧義調用或者報錯。
org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStore#doSimilaritySearch
插入數據
下面是添加數據到es的部分代碼,實際代碼是批量處理,這里改了一些。text做完向量化之后,會存到embedding字段。而metadata部分會存到metadata字段,是一個對象類型。這一部分沒有遇到問題,數據都正常插入了。
Document document = Document.builder().id(entity.bizid()).text(entity.description());.metadata("a1", entity.a1()).metadata("a2", entity.a2()).build();
// 使用vectorStore.add的時候,會自動調用embedding模型
vectorStore.add(documentList);
查詢數據
我現在的需求是metadata里面的數據,都需要精確查詢(完全匹配),就好比數據庫中的where a1 = 'xxx'。當我a1加上了某08_1表啥≠“2”(調)或 “7”(疊加)時條件時,發現查詢出來的數據,出現了a1為其他值的情況,這明顯不符合項目要求。
查詢數據的代碼,做了部分修改:
public List<Document> query(@RequestBody QueryDTO query) {SearchRequest.Builder searchBuilder = SearchRequest.builder().query(query.description()).similarityThreshold(0.7);FilterExpressionBuilder b = new FilterExpressionBuilder();FilterExpressionBuilder.Op finalOp = null;// 構建過濾表達式// 如果a1有值,就加上a1條件,key實際上會被處理成metadata.a1.keywordif (query.a1() != null) {finalOp = b.eq("a1.keyword", query.a1());}// 同上,但是可能會存在a1也有值的情況,所以下面要做個判斷if (query.a2() != null && !query.a2().isEmpty()) {finalOp = (finalOp != null) ? b.and(finalOp, b.eq("a2.keyword", query.a2())) : b.eq("a2.keyword", query.a2());}// 最后傳入過濾表達式if (finalOp != null) {searchBuilder.filterExpression(finalOp.build());}return vectorStore.similaritySearch(searchBuilder.build());}
定位問題
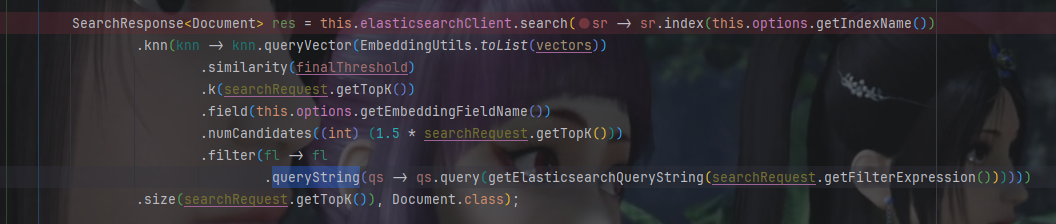
最后源碼定位到org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStore#doSimilaritySearch方法,里面使用了filter過濾,用的是queryString
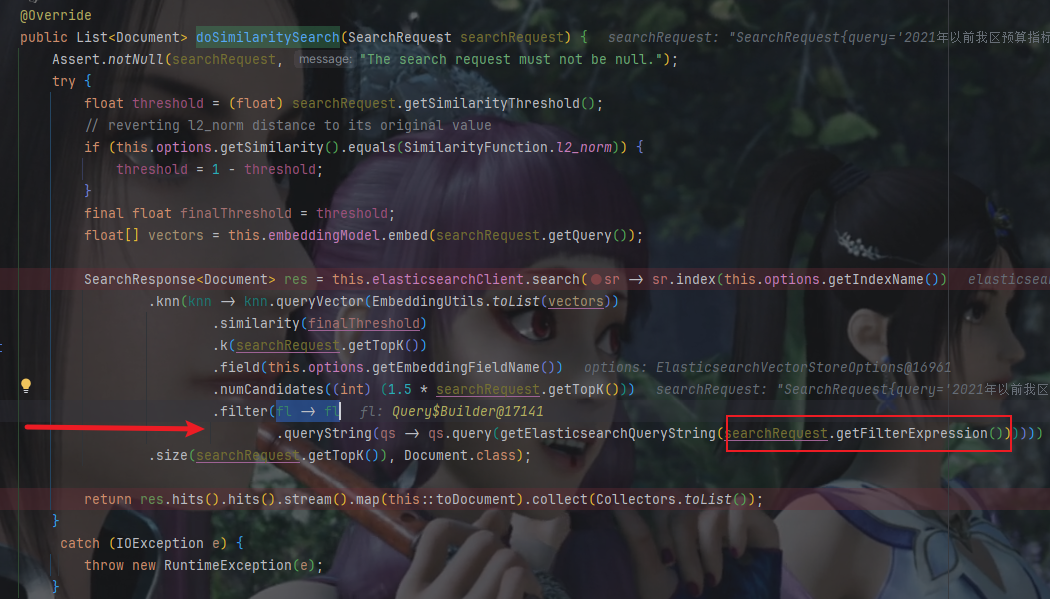
最后請求的body體,query_vector太長做了刪減,原本是1024維
{"knn":[ {"field":"embedding","query_vector":[-0.043929047882556915, 0.015229480341076851],"k":4,"num_candidates":6,"filter":[ {"query_string": {"query": "metadata.errorMessage.keyword:某08_1表啥≠“2”(調)或 “7”(疊加)時"}}],"similarity":0.699999988079071}],"size":4
}
co.elastic.clients.transport.rest_client.RestClientHttpClient#performRequest處打個斷點,執行new String(restRequest.getEntity().getContent().readAllBytes())就可以拿到請求體內容
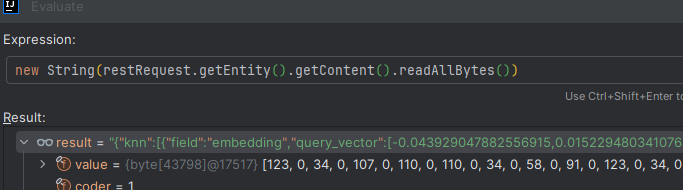
不管是代碼還是最后發送的請求體來看,都確定了使用的是query_string,而query_string對特殊字符是有要求的,這就是前面查詢出其他數據的原因。
query_string和term區別
問了AI,AI的答復:
| 特點 | query_string | term |
|---|---|---|
| 用途 | 搜一句話、一段話,支持復雜搜索(像百度搜索) | 精確查找一個完全一樣的詞、數字或狀態 |
| 怎么用 | 寫一個“搜索命令”:字段:要搜的內容 | 直接告訴它值:字段: 完全一樣的值 |
| 搜什么 | text 類型的長文本(如文章內容、錯誤信息) | keyword 類型的短詞、數字、狀態(如狀態碼、ID) |
| 是否分詞 | 會把“要搜的內容”拆開(分詞)再找 | 不分詞,必須完全一樣才能找到 |
| 性能 | 較慢(要分析、計算相關度) | 很快(直接匹配,結果可緩存) |
對特殊字符 @, #, !, *, (, ) 等的處理 | 非常麻煩! 這些符號有特殊含義(如 AND, OR)。如果當普通字用,必須: 1. 用 雙引號 " " 把整個詞或句子括起來,或者2. 用 反斜杠 \ 一個個轉義(在JSON里要寫 \\)。否則會報錯! | 完全不用管! 直接把包含特殊字符的完整字符串寫進去就行。 因為它不分詞,也不解析語法,就把整個值當普通文本比對。 |
| 例子 | 找包含 user@abc 的文檔:"query_string": { "query": "email:\"user@abc.com\"" }(必須加引號) | 找郵箱是 user@abc.com 的文檔:"term": { "email.keyword": "user@abc.com" }(直接寫,無需處理) |
一句話總結:
query_string:用來全文搜索,功能強但復雜,遇到特殊字符容易出錯,必須小心處理。term:用來精確匹配,簡單、快速、可靠,特殊字符不是問題,直接用就行。
es官網query-string-syntax中也有相關介紹,遇到這些特殊字符,都要進行處理。注意官網的NOTE,我這邊還沒有試這種情況。
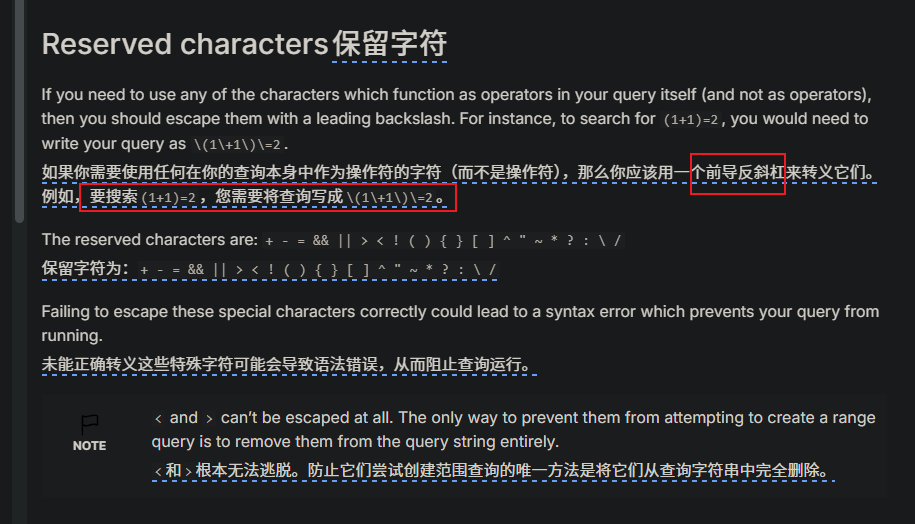
也就是說,符合我要求的,實際上是
term,使用query_string的話,還要轉義,就算不用轉義,速度也更慢。
解決辦法
- 轉義
所有可能出現的特殊字符,就是官網提到的那些,都加反斜杠轉義 - 雙引號包裹
某08_1表啥≠“2”(調)或 “7”(疊加)時改成"某08_1表啥≠“2”(調)或 “7”(疊加)時" - 改源碼
復制ElasticsearchVectorStore代碼,建一個全類名一樣的類,拷貝過去。query_string改成term。這種有個缺點,就是限制死了term查詢,不友好。更傾向于其他的方式。
改源碼的話,需要從getFilterExpression里面拿到過濾表達式,自行用term重新拼裝,處理起來比較復雜,這種不推薦 - 不使用
vectorStore.similaritySearch,自行調用es代碼查詢
注入EmbeddingModel、ElasticsearchClient,然后自己實現這個調用過程,這種是最靈活的,推薦使用,因為有些場景就是需要使用term。metadata.別忘了加
需要注意的一點是,// 先做向量搜索float[] vectors = embeddingModel.embed(query.description());// 下面三個參數是配置的,ElasticsearchVectorStore的options屬性對象里面可以拿到,但是是private的String index = "jap-index";Integer topK = 4;String embeddingFieldName = "embedding";// 查詢esSearchResponse<Document> res = this.elasticsearchClient.search(sr -> sr.index(index).knn(knn -> knn.queryVector(EmbeddingUtils.toList(vectors)).similarity(query.similarityThreshold()).k(topK).field(embeddingFieldName).numCandidates((int) (1.5 * topK)).filter(fl -> fl.term(t ->// metadata.別忘了加t.field("metadata.a1.keyword").value(query.errorMessage())))).size(topK), Document.class);// 拿結果List<Hit<Document>> hits = res.hits().hits();index等參數因為options是private的,所以需要通過其他方式拿到。- 配置文件拿,這種前提是通過application配置文件方式配置的向量數據庫(我不是這種)
- 自行創建bean方式,可以把這個配置類存放到某個地方或者注入到容器(我是這種)
@Beanpublic VectorStore vectorStore(RestClient restClient, EmbeddingModel embeddingModel) {// 可以把這個類也存起來,或者注冊成beanElasticsearchVectorStoreOptions options = new ElasticsearchVectorStoreOptions();options.setIndexName("jap-index"); // Optional: defaults to "spring-ai-document-index"options.setSimilarity(cosine); // Optional: defaults to COSINEoptions.setDimensions(1024); // Optional: defaults to model dimensions or 1536return ElasticsearchVectorStore.builder(restClient, embeddingModel).options(options) // Optional: use custom options.initializeSchema(true) // Optional: defaults to false.batchingStrategy(new TokenCountBatchingStrategy()) // Optional: defaults to TokenCountBatchingStrategy.build();}
- 反射方式拿
ElasticsearchVectorStore(也就是注入的VectorStore)的options屬性,不推薦 - 復制類,全類名一樣的,拷貝代碼,改成
options改成public,不推薦
)

)



![[網安工具] Web 漏洞掃描工具 —— AWVS · 使用手冊](http://pic.xiahunao.cn/[網安工具] Web 漏洞掃描工具 —— AWVS · 使用手冊)

中組合邏輯和時序邏輯是怎么劃分的)



如何理解MySQL的多版本并發控制(MVCC)?)






