使用FileBeat+Logstash+ES實現分布式日志收集
在大型項目中?,往往服務都是分布在非常多不同的機器上?,每個機器都會打印自己的log日志
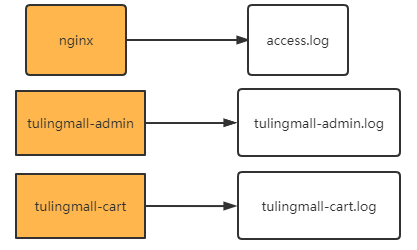
但是?,這樣分散的日志?,本來就無法進行整體分析。再加上微服務的負載均衡體系?,甚至連請求打到了哪個服務器?上都無法確定。給問題排查帶來了很多的困難。?因此就需要將分散的日志收集到一起?,這樣才能整體進行分析。
在Java應用中?,后續我們會介紹使用skywalking?,基于微服務架構進行整體鏈路追蹤。但是這種方式會顯得比較??重。如果只是分析nginx這樣的中間件?,skywalking顯然就無能為力了。?因此?,還需要一個比較簡單快捷?,對應用?無侵入的方式統一收集日志。通常?,業界常用的還是通過ELK中間件來收集日志。整體的流程是這樣的。
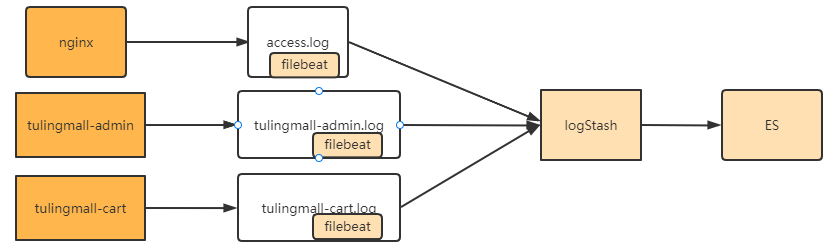
?le?beat,logstash和es都是ELK組件中的標準處理組件。其中?,?ES是一個高度可擴展的全文搜索和分析引擎?,能夠????對大容量的數據進行接近實時的存儲、搜索和分析操作?,通常會跟Kibana部署在一起?,?由Kibana提供圖形化的操????作功能。?LogStash是一個數據收集引擎?,他可以動態的從各種數據源搜集數據?,并對數據進行過濾、分析和統一格?式等簡單操作?,并將輸出結果存儲到指定位置上。但是LogStash服務過重?,如果在每個應用上都部署一個
logStash?,會給應用服務器增加很大的負擔。?因此?,通常會在應用服務器上?,部署輕量級的?le?beat組件。?le?beat 可以持續穩定的收集簡單數據?,比如Log日志?,統一發給logstash進行收集后?,再經過處理存到ES。
這一套流程是企業中最為基礎的分布式日志收集方案。這一章節就帶大家實際搭建一個?le?beat和logstash服務,?用來收集前端項目的nginx日志?,然后將nginx日志經過logstash保存到es中。
搭建LogStash
去官網下載與ES配套的LogStash?7.17.3版本發布包logstash-7.17.3-linux-x86_64.tar.gz。 下載地址:
Past Releases of Elastic Stack Software | Elastic?。
使用tar?-zxvf?logstash-7.17.3-linux-?x86_64.tar.gz?將壓縮包解壓到es用戶根目錄。
解壓完成后需要配置Logstash需要的JDK。這個JDK不需要額外下載?,在logstash的安裝目錄下有一個jdk目錄?,里?面有內置的配套JDK。這時?,需要配置一個環境變量LS_JAVA_HOME指向這個內置的JDK即可。
接下來可以簡單啟動一下logstash進行測試。進入logstash的安裝目錄?,啟動一個簡單的logstash任務。
bin/logstash -e 'input { stdin { } } output { stdout {} }'
?? 這個任務啟動需要一定的時間。
? 啟動完成后,就可以從logstash的控制臺輸入信息,然后又重新輸出到控制臺中。使用ctrl_+D退出控制臺。
#控制臺輸入hello
hello
# 控制臺輸出logstash處理結果
{"message" => "hello","@version" => "1","host" => "es-node3","@timestamp" => 2022-09-14T02:14:05.709Z
}?這樣一個簡單的logstash就安裝完成了。
? 接下來需要對logstash的輸入和輸出目錄進行配置。進入config目錄,在目錄下直接修改logstash-sample.conf文件即可。
配置文件名字可以隨便取,后續啟動時需要指定配置文件。
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.input {beats {port => 5044}
}filter {grok {match => { "message" => "%{COMBINEDAPACHELOG}"}}
}output {elasticsearch {hosts => ["http://localhost:9200"]#index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"index => nginxloguser => "elastic"password => "123456"}
}這個配置中:
input表示輸入,這里表示從filebeat輸入消息,接收的端口是5044。
output表示數據的輸出,這里表示將結果輸出到本機的elasticsearch中,索引是nginxlog。
filer表示對輸入的內容進行格式化處理。這里指定的grok是logstash內置提供的一個處理非結構化數據的過濾器。他可以以一種類似于正則表達式的方式來解析文本。簡單的配置規則比如:%{NUMBER:duration} %{IP:client} 就是從文本中按空格,解析出一個數字型內容,轉化成duration字段。然后解析出一個IP格式的文本,轉換成client字段。而示例中使用的COMBINEDAPACHELOG則是針對APACHE服務器提供的一種通用的解析格式,對于解析Nginx日志同樣適用。
一條nginx的日志大概是這樣:
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-search.png
HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel
Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"
解析出來的是一個json格式的數據,包含以下字段
| Information | Field Name |
|---|---|
| IP Address | clientip |
| User ID | ident |
| User Authentication | auth |
| timestamp | timestamp |
| HTTP Verb | verb |
| Request body | request |
| HTTP Version | httpversion |
| HTTP Status Code | response |
| Bytes served | bytes |
| Referrer URL | referrer |
| User agent | agent |
? 配置好這個文件后,就可以直接啟動了。
nohup bin/logstash -f config/logstash-sample.conf --config.reload.automatic &
config.reload.automatic表示配置自動更新,也就是說以后只要改動了配置文件,就會及時生效,不需要重啟logstash
nohup指令只是表示不要占據當前控制臺,將控制臺日志打印到nohup.out文件中。
logstash更詳細的配置說明參見官方文檔:Logstash Reference [7.17] | Elastic
??然后,搭建filebeat
? 之前已經啟動了logstash服務,通過5044端口監聽filebeat服務。接下來就需要在各個應用服務器上部署filebeat,往logstash發送日志消息即可。
? filebeat的下載地址:?Past Releases of Elastic Stack Software | Elastic?。同樣選擇配套的7.17.3版本filebeat-7.17.3-linux-x86_64.tar.gz。并使用tar -zxvf filebeat-7.17.3-linux-x86_64.tar.gz指令解壓。
? 在解壓目錄下已經提供了一個模版配置文件filebeat.yml,我們只需要修改這個文件即可。 這個模板文件里面的示例非常清楚,從文件讀取日志,輸出到logstash的配置,文件當中都有。這里只列出修改的部分。
? 先修改文件輸入的部分配置
# ============================== Filebeat inputs ===============================
filebeat.inputs:
-?type:?filestream# Change to true to enable this input configuration.enabled:?true?# Paths that should be crawled and fetched. Glob based paths.paths:-?/www/wwwlogs/access.log#- c:\programdata\elasticsearch\logs\*? 然后修改輸出到logstash的部分配置
# ------------------------------ Logstash Output -------------------------------
output.logstash:# The Logstash hostshosts:?["192.168.65.114:5044"]
默認打開的是output.elasticsearch,輸入到es,這部分配置要注釋掉。
? 這樣就完成了最簡單的filebeat配置。接下來啟動filebeat即可
nohup ./filebeat -e -c filebeat.yml -d "publish" &
? filebeat任務啟動后,就會讀取nginx的日志,一旦有新的日志記錄,就會將日志轉發到logstash,然后經由logstash再轉發到ES中。并且filebeat對于讀取過的文件,都是有記錄的,即便文件改了名字也不會影響讀取的進度。比如對log日志,當前記錄的log文件,即便經過日志輪換改成了其他的名字,讀取進度也不會有變化。而新生成的log日志也可以繼續從頭讀取內容。如果需要清空filebeat的文件記錄,只需要刪除安裝目錄下的data/registry目錄即可。
更詳細的配置參見官方文檔:?Configure the Logstash output | Filebeat Reference [7.17] | Elastic
??接下來,進入ES查看數據是否生效
? 進入Kibana的前端頁面,即可查詢到nginxlog索引下的日志記錄
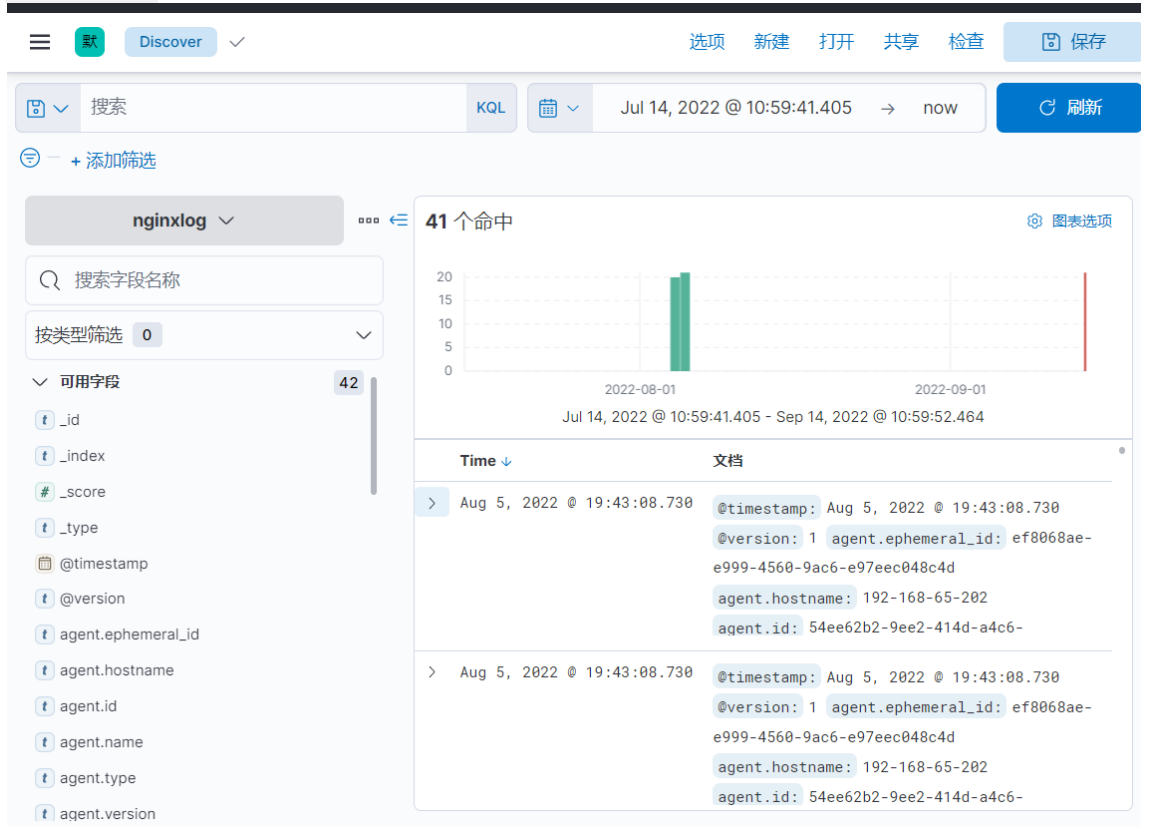
?后續就可以針對這些nginx的日志信息,進行分析。nginx的日志基本上是所有大型項目進行日志收集必不可少的一個重要數據來源,從nginx的日志中可以分析出大量有用的結果。比如最常見的PV,UV,還有熱點功能等。
? 例如,在Kibana中,可以通過統計Nginx的日志條數,計算出每天的PV
GET nginxlog/_count
{"query": {"range": {"timestamp": {"gte": "2022-10-21"}}}
}
? 用clientip來區分不同訪客,就可以統計出每天的UV
GET nginxlog/_search
{"query": {"range": {"timestamp": {"gte": "2022-10-21"}}},"size": 0,"aggs": {"visitOrder": {"terms": {"field": "clientip.keyword","size": 10}}}
}
? 課上就只帶大家搭建最簡單的一組服務了。在搭建過程中可以看到,filebeat和logstash對于常見的輸入輸出源都已經提供了實現,大部分情況下,只需要簡單配置即可。在實際項目中,往往會以此為基礎構建更復雜的分布式日志處理方案。 比如在logstash后增加一個Kafka,將LogStash收集的日志消息存入到kafka ,再經過基于Kafka的流式計算,將PV,UV這類的統計結果存入ES。


行為型:策略模式詳解)


)

)





)

)
)


