Enable RAPTOR
????????一種遞歸抽象方法,用于長上下文知識檢索和摘要,在廣泛語義理解和細微細節之間取得平衡。
????????RAPTOR(遞歸抽象處理用于樹狀組織檢索)是一種在2024年論文中引入的增強文檔預處理技術。它旨在解決多跳問答問題,通過遞歸聚類和對文檔片段進行摘要化來構建層次樹結構。這使得在長文檔中的上下文感知檢索更加有效。RAGFlow v0.6.0在數據提取和索引之間的數據預處理管道中集成了RAPTOR用于文檔聚類,如下圖所示。
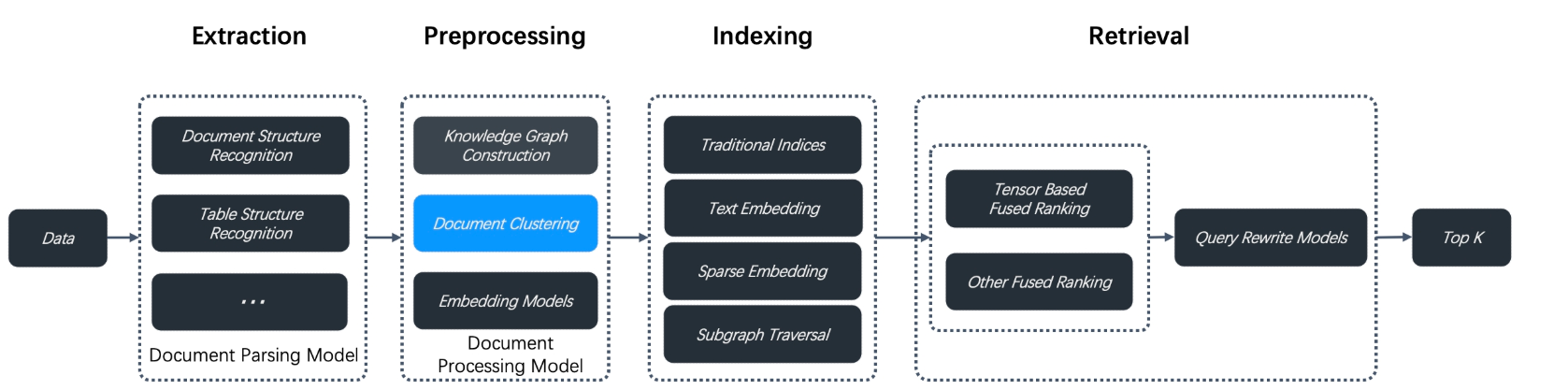
????????我們使用這種新方法進行的測試在需要復雜多步驟推理的問題回答任務中展示了最先進的(SOTA)結果。通過結合RAPTOR檢索與我們內置的分塊方法和其他檢索增強生成(RAG)方法,您可以進一步提高問題回答的準確性。
? ? ? ??警告:啟用RAPER需要大量的內存、計算資源和tokens。
Basic principles
????????在原始文檔被分割成塊之后,這些塊根據語義相似性進行聚類,而不是按照它們在文本中的原始順序。然后,通過系統的默認聊天模型將這些簇總結為更高層次的塊。這個過程遞歸地應用,形成一個從下到上具有不同層次摘要的樹結構。如圖所示,初始塊形成葉節點(顯示為藍色),并遞歸地總結為根節點(顯示為橙色)。
????????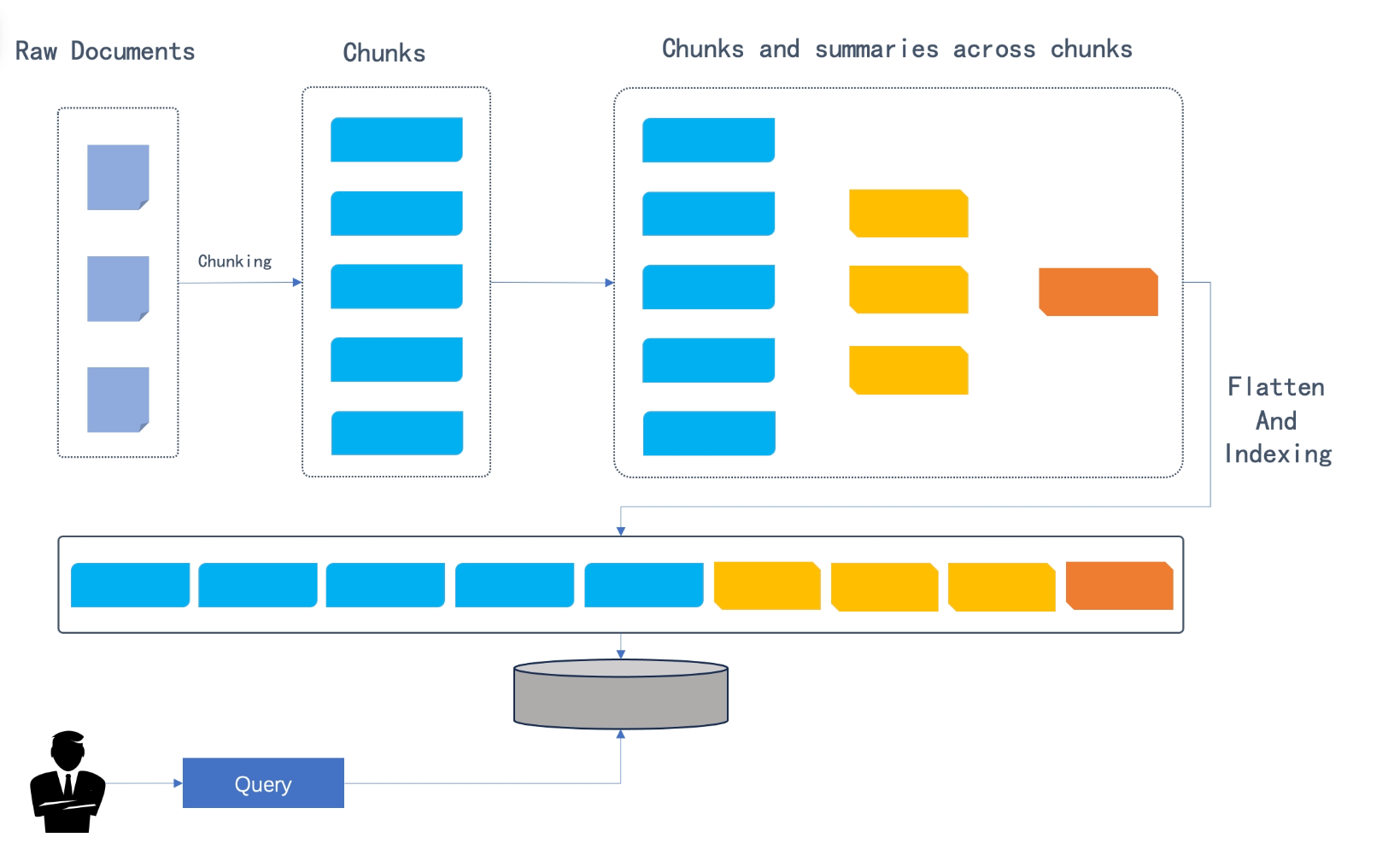
????????遞歸聚類和總結能夠捕捉到廣泛的理解(由根節點實現)以及多跳問答所需的細微細節(由葉節點實現)。
Scenarios
????????對于涉及復雜多步驟推理的多跳問答任務,問題和答案之間通常存在語義差距。因此,使用問題進行搜索往往無法檢索到有助于正確答案的相關片段。RAPTOR通過為聊天模型提供更豐富、更具上下文關聯性和相關性的片段來解決這一挑戰,使其能夠全面理解而不丟失細節。
????????知識圖譜也可以用于多跳問答任務。詳見構建知識圖譜的詳細信息。你可以使用任一方法或兩者結合,但要確保理解涉及的內存、計算和標記成本。
Prerequisites
????????系統的默認聊天模型用于總結聚類內容。在繼續之前,請確保已正確配置聊天模型。
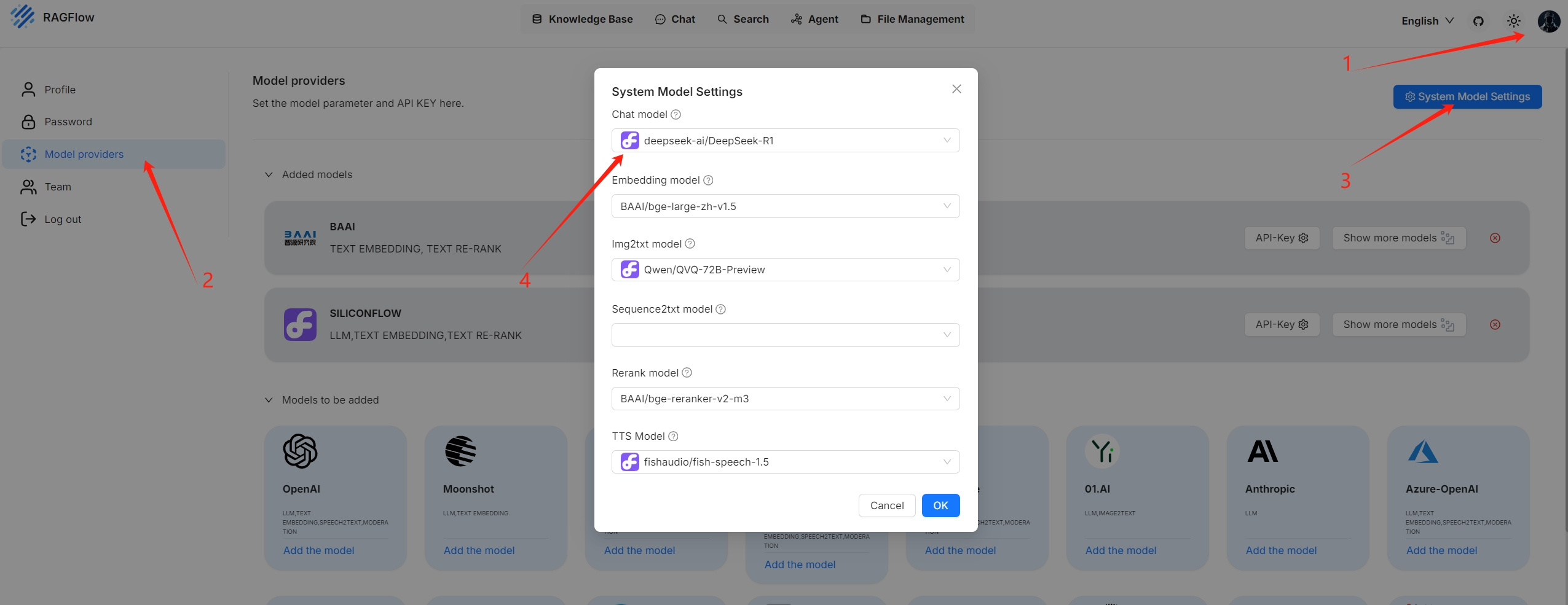
Configurations?
????????RAPTOR功能默認是禁用的。要啟用它,請手動在知識庫的配置頁面上打開“使用RAPTOR增強檢索”開關。
Prompt
????????以下提示將遞歸應用于聚類摘要,{cluster_content}作為內部參數。我們建議您現在保持不變。設計將在適當時候更新。
Please summarize the following paragraphs... Paragraphs as following:{cluster_content}
The above is the content you need to summarize.?Max token?
????????每個生成摘要塊的最大標記數。默認為256,最大限制為2048。
Threshold
????????在RAPTOR中,塊根據其語義相似性進行聚類。閾值參數設置塊被分組在一起所需的最小相似度。默認值為0.1,最大限制為1。較高的閾值意味著每個簇中的塊較少,較低的閾值則意味著更多。
Max cluster
????????創建的最大聚類數量。默認為64,最大限制為1024。
Random seed
????????一個隨機種子。點擊+以更改種子值。
相關資料:
? ? ? 1、?Enable RAPTOR | RAGFlow
??????2、??https://huggingface.co/papers/2401.18059

)

)
)





)








