最近體驗了一下 Deepwiki 的 AI 文檔生成功能,本文展示其自動生成的《SeaTunnel 云端數據倉庫連接器》文檔內容,歡迎大家一起“挑刺捉蟲”,看看 AI 寫技術文檔到底靠不靠譜?
本文檔介紹了 Apache SeaTunnel 的云數據倉庫連接器,這些連接器支持與現代云原生分析型數據存儲和搜索引擎進行數據集成。它們具備 Source 和 Sink 雙向能力,可從分布式云數據倉庫中讀取數據或寫入數據。
如需了解傳統數據庫連接器,請參閱?[JDBC Connectors]。如需了解基于文件的云存儲連接器,請參閱?[File System Connectors]。
概覽
目前,SeaTunnel 提供以下云數據倉庫連接器:
- Elasticsearch Connector:支持 Elasticsearch 2.x 到 8.x 版本的集群,具備向量化、模式演進和多種查詢 API 等高級功能。
- SelectDB Cloud Connector:提供面向 SelectDB Cloud 倉庫的 Sink 能力,支持精準一次性語義(Exactly-Once Semantics)。
這些連接器基于 SeaTunnel 的統一連接器框架構建,并與平臺的 Catalog 系統、Checkpoint 機制和分布式執行引擎集成。
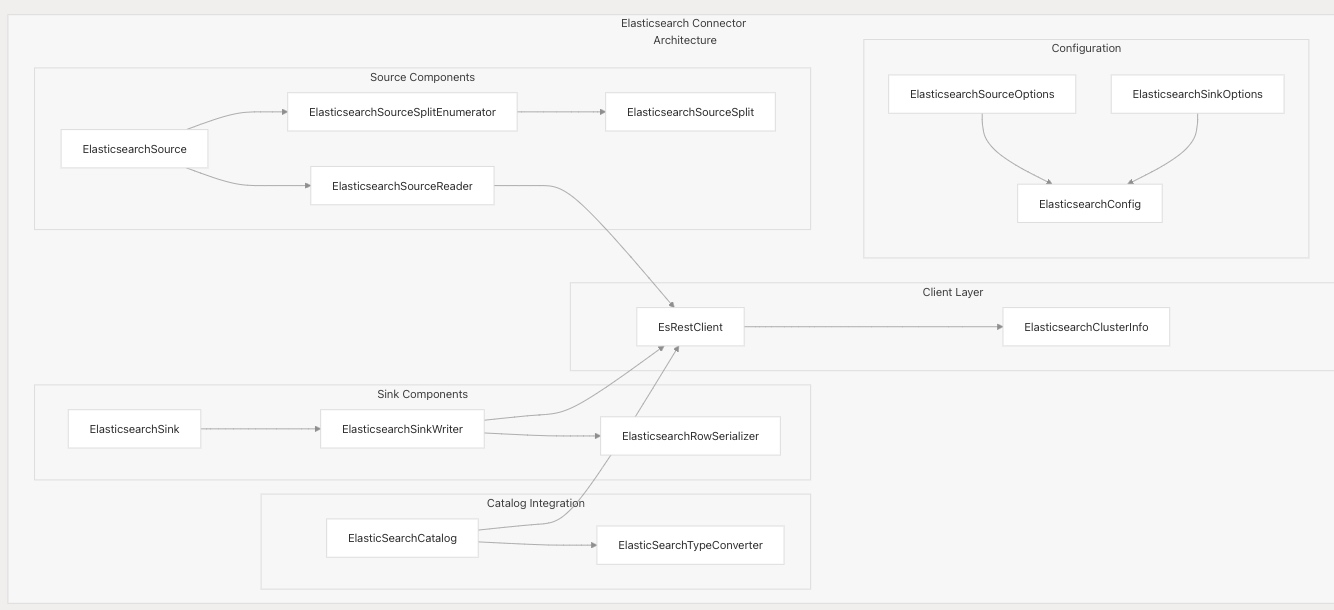
Elasticsearch 連接器架構
Elasticsearch 連接器通過完善的架構實現了 Source 和 Sink 雙功能,支持多種 Elasticsearch 部署場景。
核心組件
查詢 API 類型與查詢方式
Elasticsearch 連接器支持多種查詢方式,以滿足不同的性能和一致性需求:
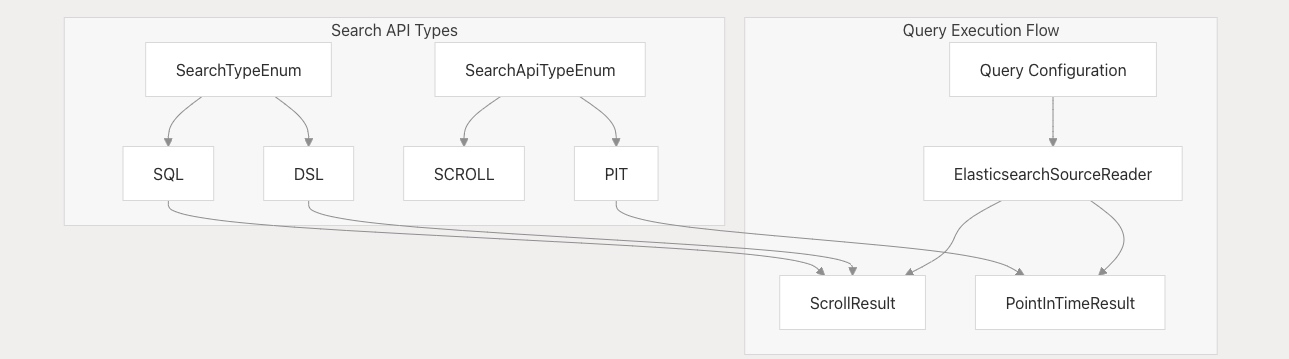
該連接器在?ElasticsearchSourceReader?中實現了多種搜索策略:
- Scroll API:使用?
searchByScroll()?和?searchWithScrollId()?方法的傳統分頁方式 - PIT(Point-in-Time)API:使用?
searchWithPointInTime()?方法,適用于大規模數據集的高效分頁方式 - SQL 查詢:通過?
searchBySql()?和?searchWithSql()?方法支持 X-Pack SQL 查詢
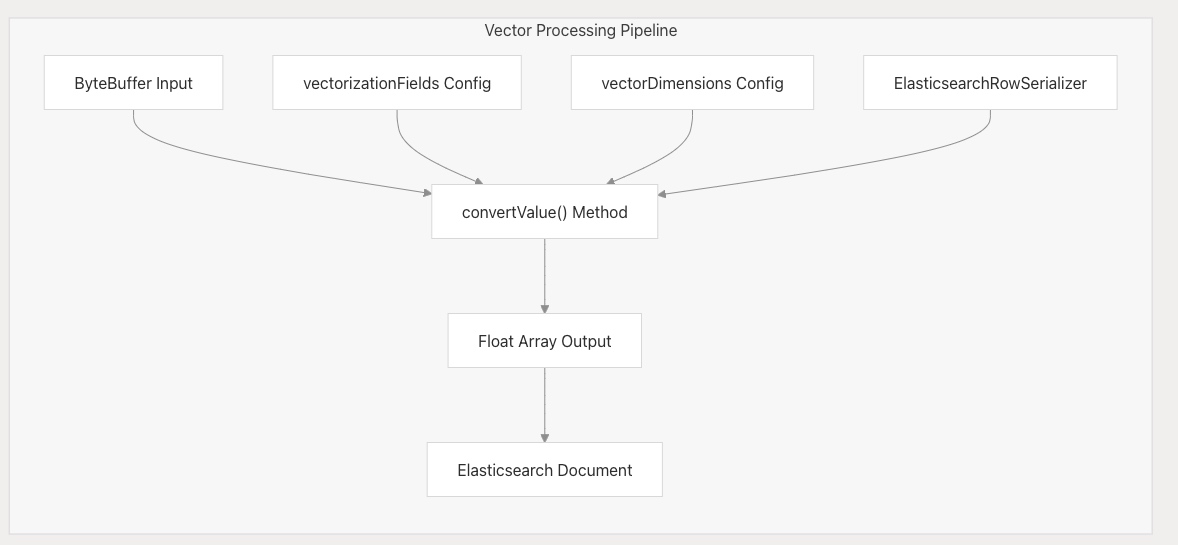
向量化支持
Elasticsearch Sink 支持向量字段處理,適用于機器學習與 AI 場景:
模式演進(Schema Evolution)
Elasticsearch Sink 支持部分模式演進功能:

模式演進通過?ElasticsearchSinkWriter.applySchemaChange()?方法實現,目前支持在現有索引中添加列。
SelectDB Cloud 連接器架構
SelectDB Cloud 連接器僅支持 Sink 功能,專注于高吞吐量批量加載與精準一次性語義(Exactly-Once Semantics)。
核心組件
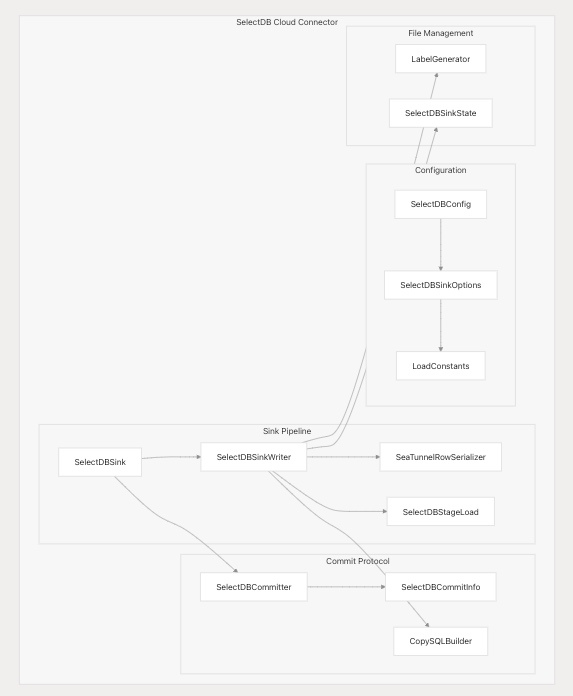
兩階段提交協議(2PC)
SelectDB Cloud 通過兩階段提交協議實現精準一次性寫入:
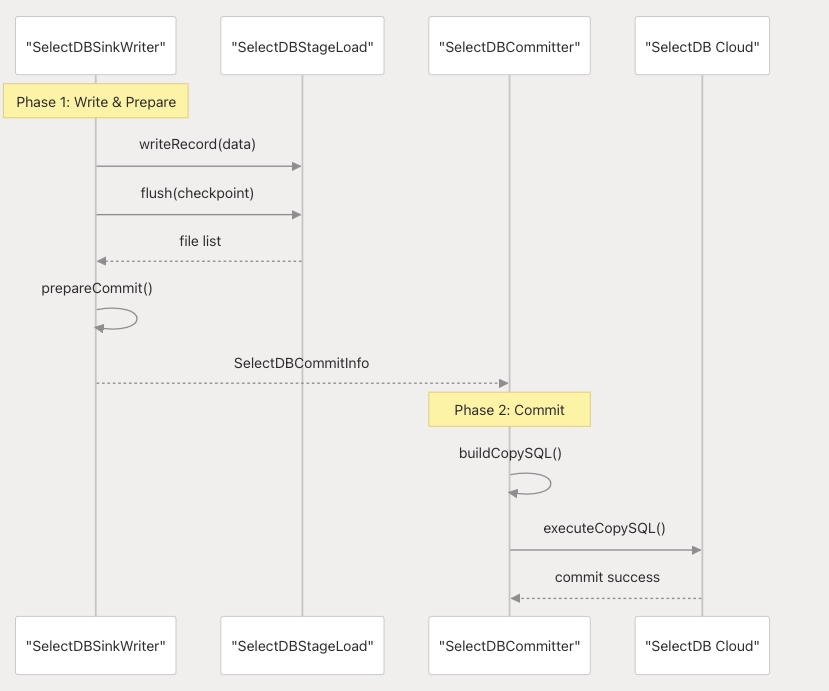
此兩階段提交過程由配置項?enable-2pc?控制,確保數據在 Checkpoint 之間的一致性。
數據序列化格式
SelectDB Cloud 支持多種數據格式用于批量導入:
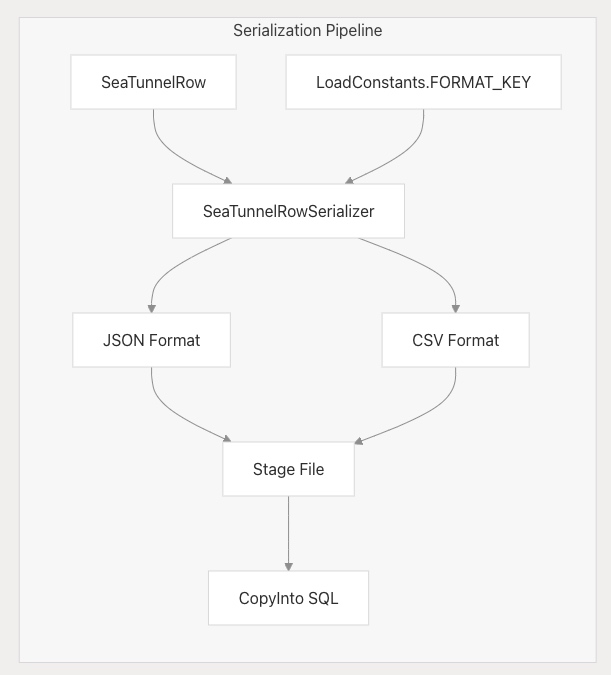
格式選擇通過?selectdb.config.file.type?配置,決定數據上傳前的序列化方式。
通用配置模式
兩個云數據倉庫連接器共享部分 SeaTunnel 核心系統的通用配置模式:
連接配置
| 配置類型 | Elasticsearch | SelectDB Cloud |
|---|---|---|
| 主機配置 | hosts: ["host:port"] | load-url + jdbc-url |
| 認證信息 | 用戶名/密碼 | 用戶名/密碼 + 集群名稱 |
| SSL/TLS | tls_verify_certificate,?tls_keystore_path | 不適用 |
| 批次控制 | max_batch_size,?scroll_size | sink.buffer-size,?sink.buffer-count |
Save Mode 集成
兩種連接器均集成了 SeaTunnel 的 Save Mode 系統:
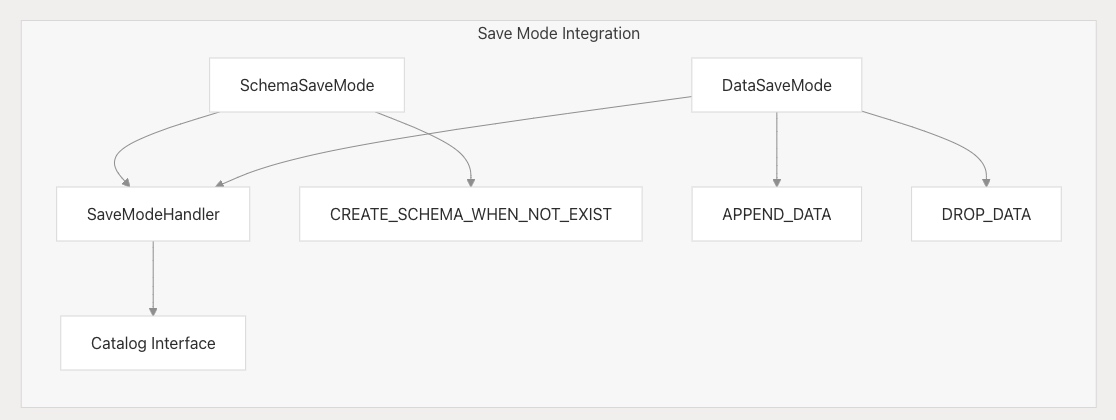
通過 Save Mode,連接器可自動管理 schema 和數據生命周期。
多表支持
Elasticsearch 連接器支持多表同步能力:
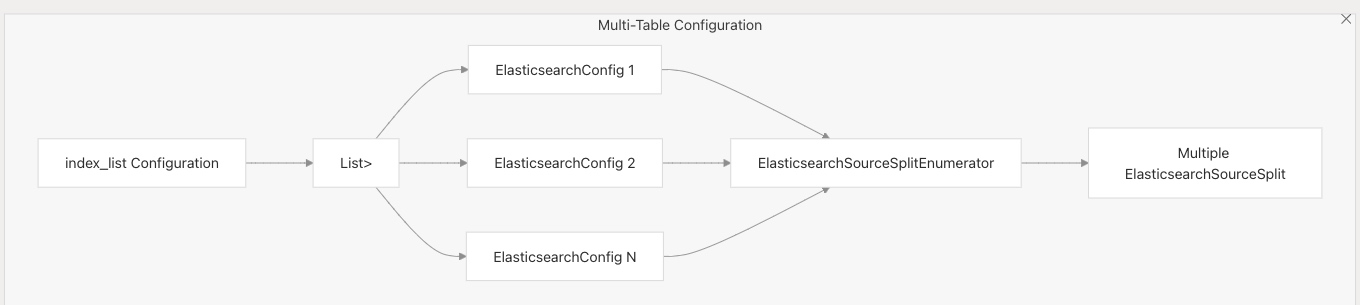
該模式支持在一個作業中同步多個索引的數據。
原文鏈接:Cloud Data Warehouse Connectors | apache/seatunnel | DeepWiki



)





)



詳解:SVM 中的關鍵損失函數)




 ? | ImageCarousel(圖片輪播組件))
)