目錄
一 . HTTP 協議??
二 . 抓包?
三 . HTTP 請求 / 響應的基本格式?
(1)HTTP請求的基本格式?
(2)HTTP響應的基本格式?
四 . HTTP 方法?
GET 和 POST 的區別:
五 . 請求報頭和響應報頭?
(1)HOST?
(2)Content - Length 和?Content - Type?
(3)User - Agent(簡稱 UA )
(4)Referer?
(5)Cookie?
六 . 狀態碼(status code)
七 . HTTPS?
(1)密鑰?
(2)HTTPS 的基本工作流程?
1 . 引入對稱加密?
2 . 傳輸對稱密鑰給服務器?
3 . 引入非對稱加密?
4 . 中間人攻擊?
5 . 為了避免中間人攻擊,引入證書系統?
一 . HTTP 協議??
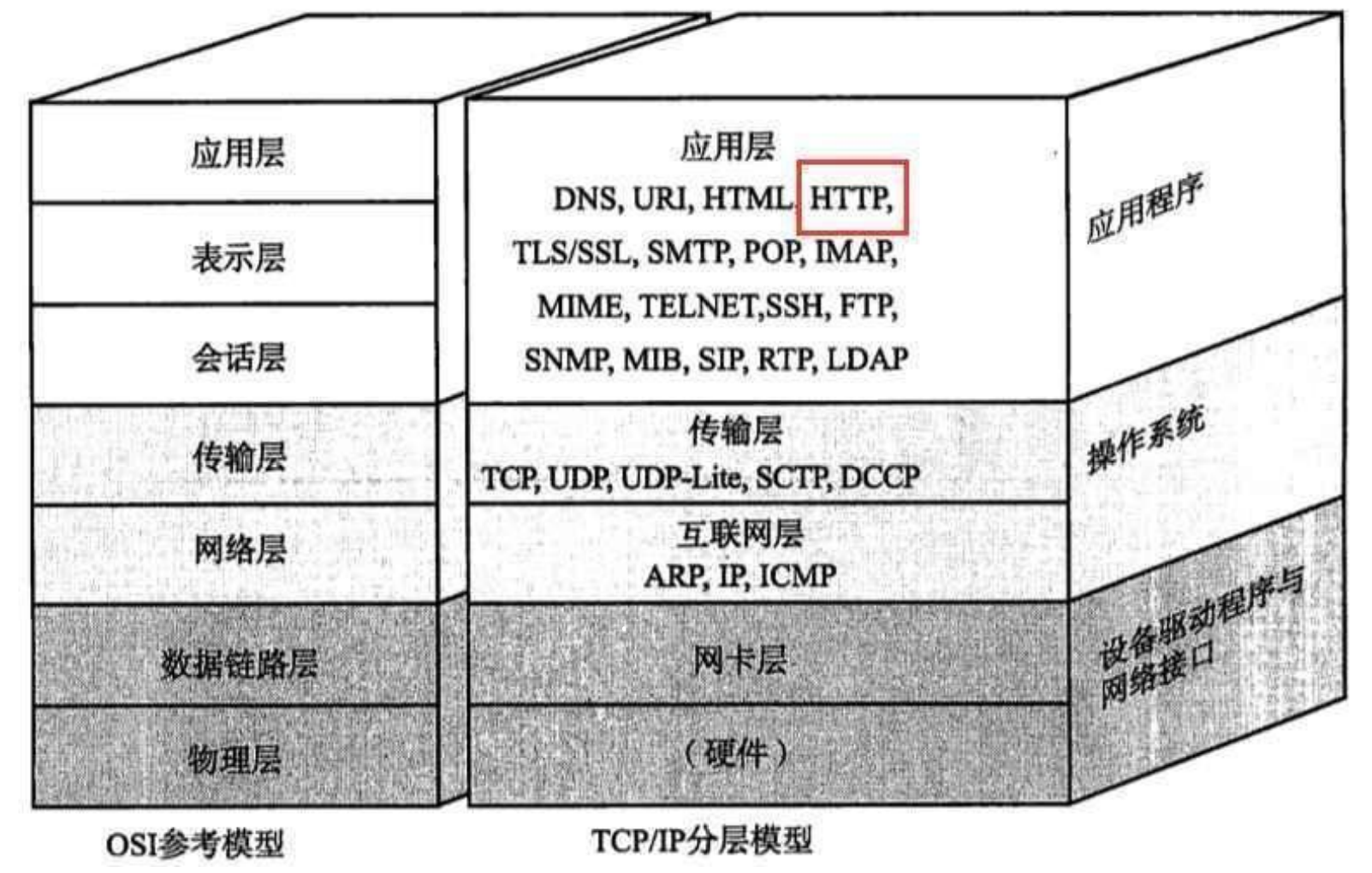
HTTP 全稱為超文本協議,是一種應用非常廣泛的應用層協議。HTTP 誕生于 1991 年,目前已經發展成為最主流的一種應用層協議。
為什么 HTTP 被稱為 “ 超文本?” 呢?這是因為 HTTP 不僅能傳輸文本,還能傳輸圖片、視頻、音頻文件以及其他各種數據。
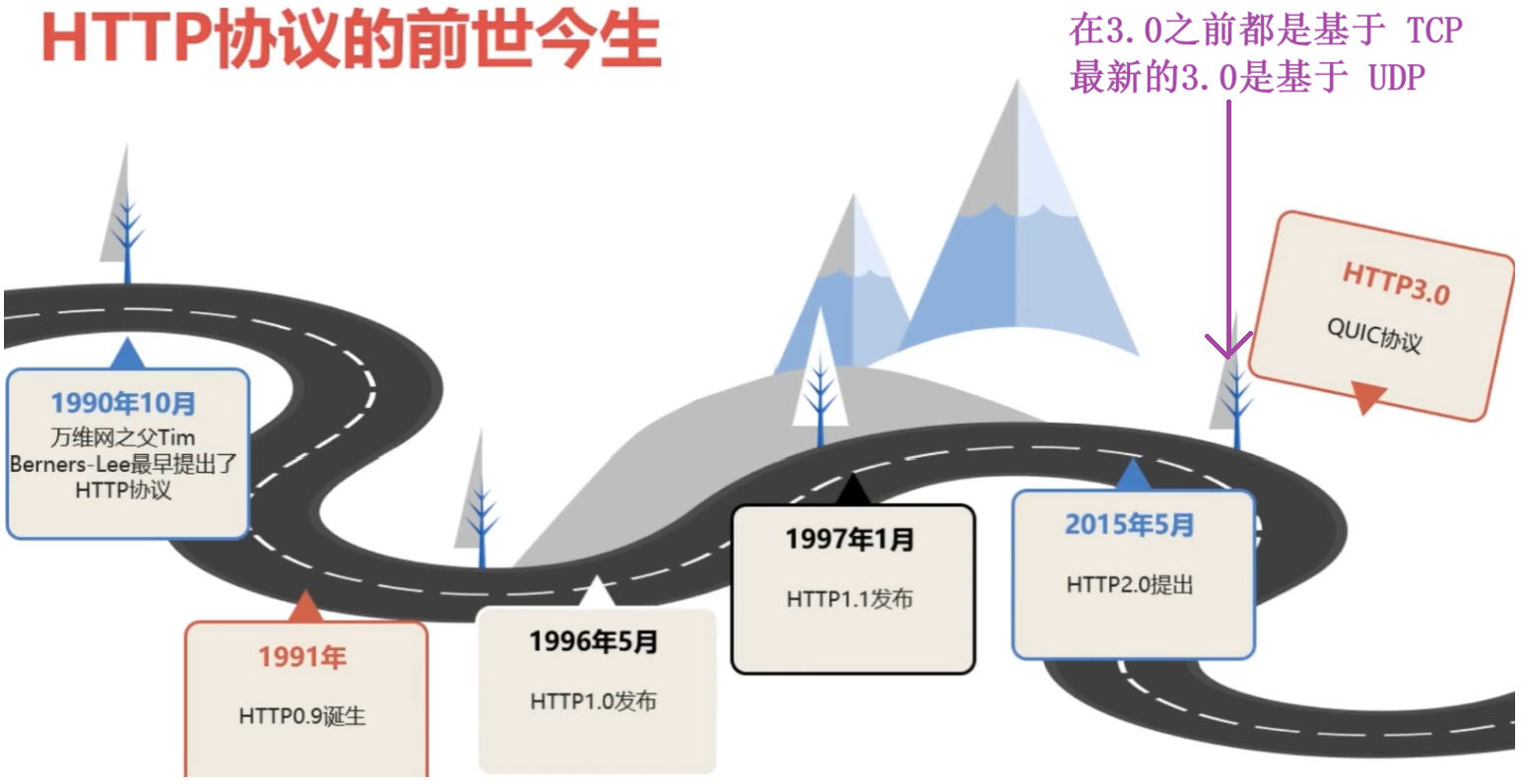
HTTP 協議,是一種典型的 “ 一問一答模型?” 協議。就是針對服務器與客戶端之間的,客戶端發一個請求,服務器返回一個響應。
二 . 抓包?
借助抓包工具,我們可以觀察到 HTTP 請求 / 響應的詳細情況。
抓包就是把通過網卡上的數據獲取到,并解析顯示出來。
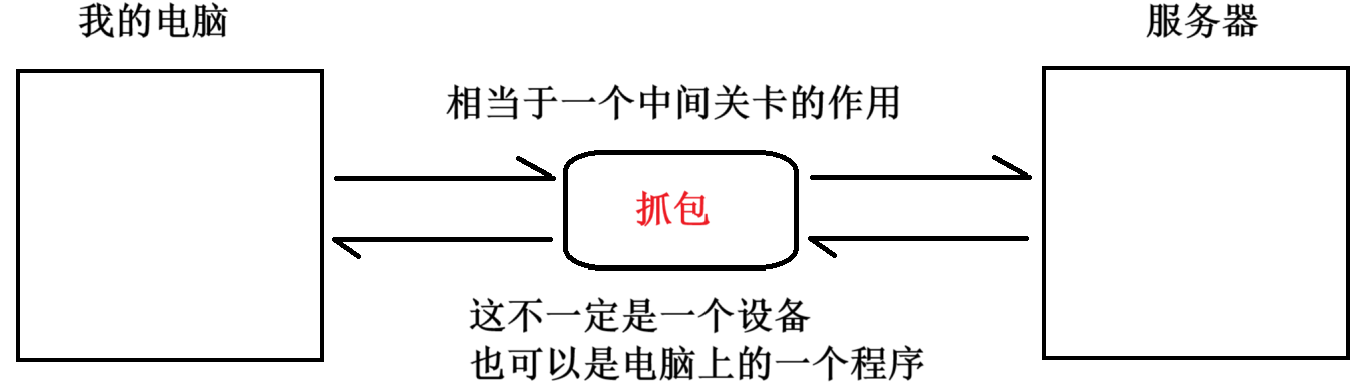
這一中間的抓包過程,也像個代理人一個,所以我們又將抓包程序這一過程稱之為 “ 代理 ” 。
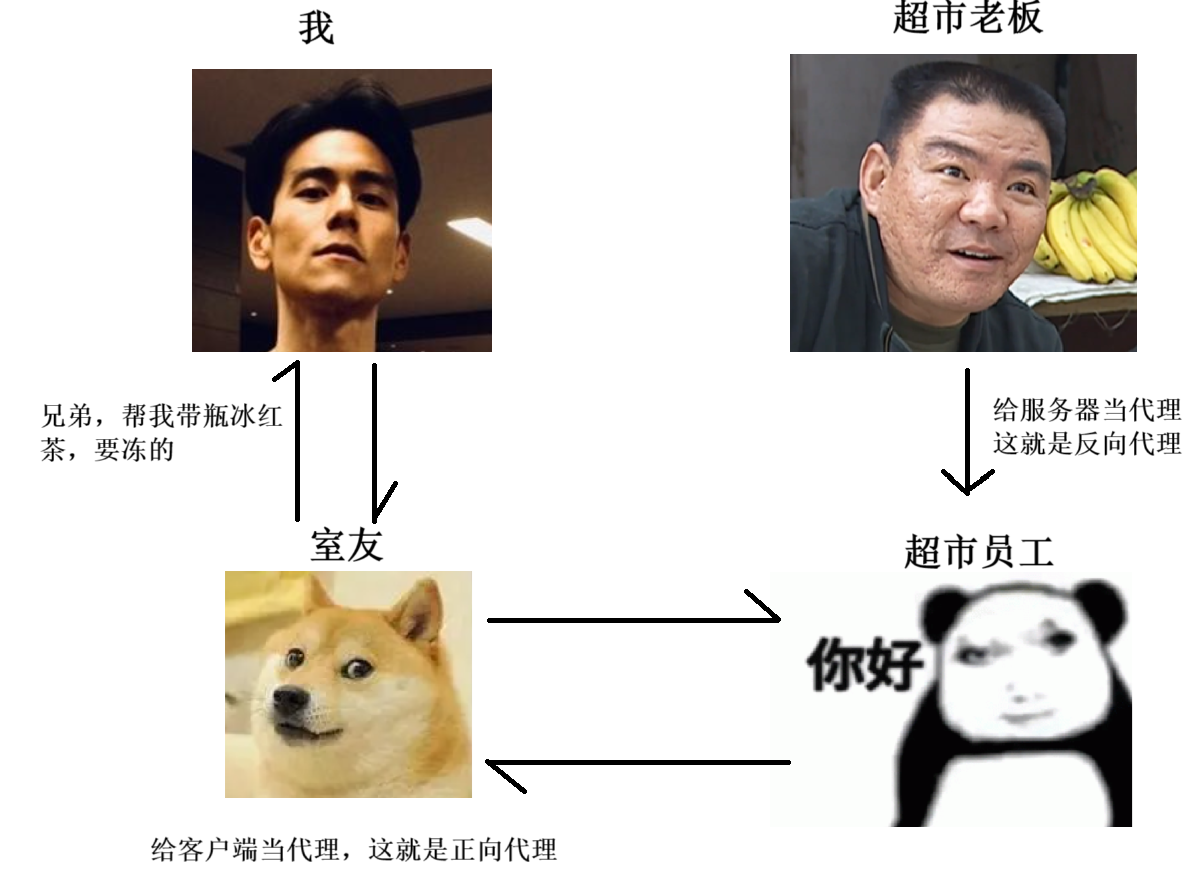
代理,又分為正向代理和反向代理:
三 . HTTP 請求 / 響應的基本格式?
(1)HTTP請求的基本格式?
1 . 首行

2 . 請求頭(header)
若干鍵值對,從第二行開始的若干行,一直到空行結束。
3 . 空行
作為請求頭的結束標記。
4 . 正文(body)
有的請求中有 body ,有的則沒有。body 中是一個個加密過的鍵值對,通過 “ :” 分隔開。
(2)HTTP響應的基本格式?
1 . 首行
首行的三個部分使用空格分隔,請求也是如此。
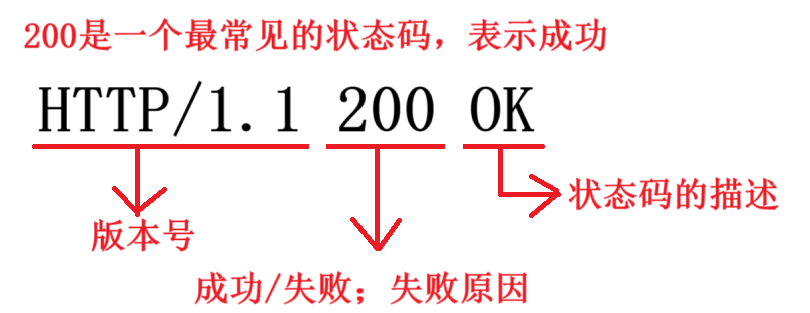
2 . 響應頭(header)
每一行是一個鍵值對,不確定幾行,以空行結尾,鍵和值之間使用 ;分隔。
鍵值對也是標準規定的,有的鍵值對只能出現在請求中,有的只能出現在響應中,有的則都可以。

3 . 空行
作為響應報頭的結束標記。
4 . 正文
對于響應來說,正文通常是 HTML、CSS、JS、JSON、圖片、音頻、字體等等,體現了服務器給瀏覽器返回的數據。
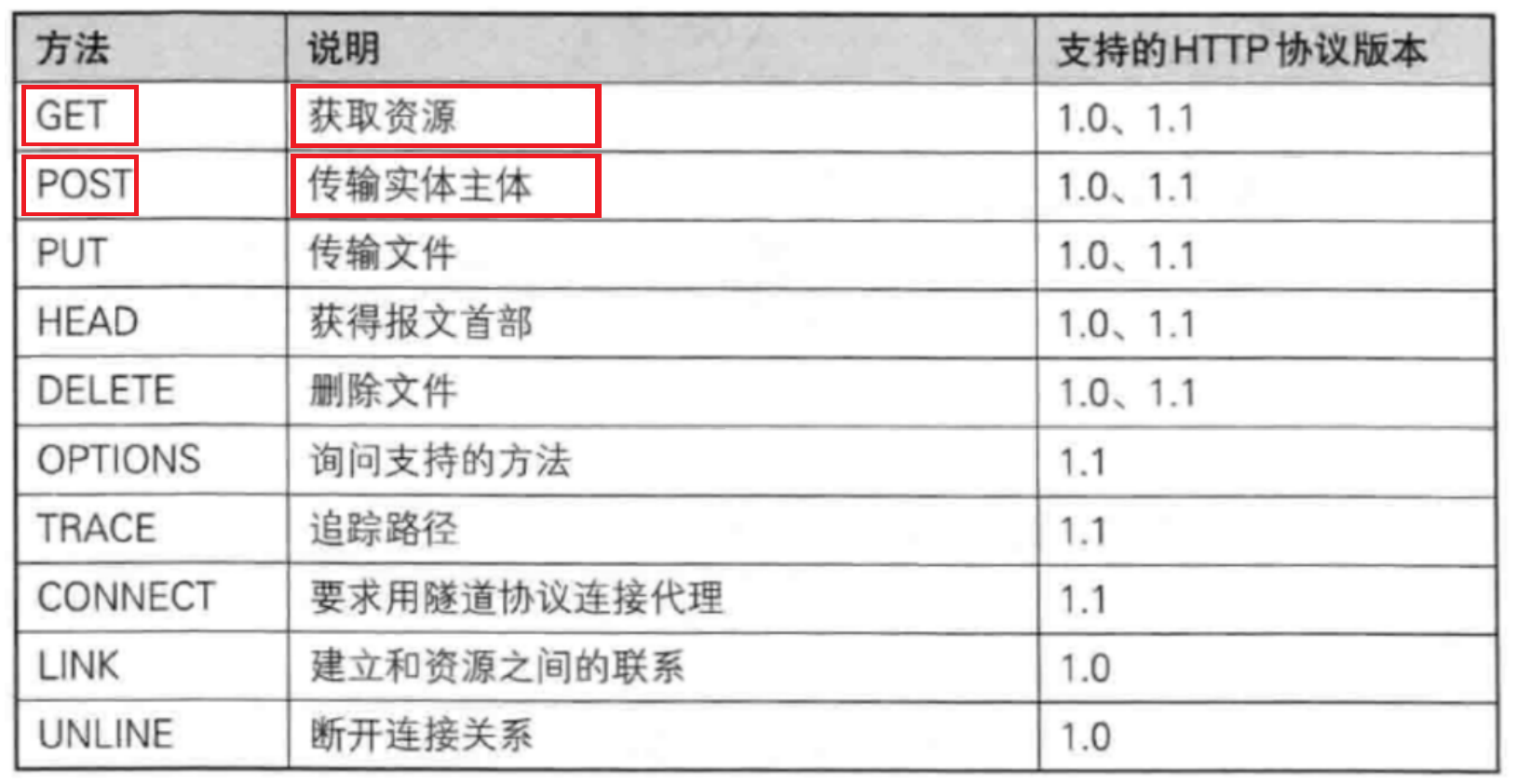
四 . HTTP 方法?
在我們HTTP中有很多很多方法,其中我們最最最常用的就是 “ GET ” 和 “ POST ” 。
大家小時候應該都學過一篇語文課文《世說新語》,其中有一篇寫謝安的文章,謝安有個很有名得的曾侄子 —— 謝靈運,謝靈運有句名言典故:才高八斗。他說,魏晉以來,天下文采共十斗,曹子建獨占八斗,我得一斗,自古至今其余人共分一斗。他這話其實吹牛了昂,看似夸曹植,實際夸自個呢,可能那天謝老爺子喝高了。
但這話放在我們的 HTTP 方法中就很恰當了,可以說,天下 HTTP 方法共十斗,GET 獨占八斗,POST 得一斗,其余方法各分一斗。
GET 請求也就是從服務器中拿到某個請求數據,POST 就是向服務器發送一個請求數據。
有很多場景都會涉及到 GET :
(1)直接在瀏覽器輸入一個 URL ,此時就會觸發 GET 請求。
(2)HTML 頁面中很多元素會進一步觸發 GET 請求。
(3)JS 代碼中也能夠觸發 GET 請求。
涉及到 POST 的場景:
(1)登錄 / 注冊的時候。
(2)上傳文件的時候。
GET 和 POST 的區別:
首先,明確拋出結論:這兩種方法,這兩種方法其實沒有本質區別(GET 能用的場景,換成 POST 也可以,同理,POST?能用的場景,換成 GET?也可以),但是有一定的區別:
(1)語義上的區別:GET 表示從服務器拿數據, POST 表示向服務器提交數據。(如果你想要使用 GET 提交數據,用 POST 拿數據也是可以的,但是這種做法不常見)
(2)傳遞數據的方式不同:GET 傳遞數據通常是通過 query string 把自定義數據提交給服務器。POST 在傳遞數據的時候,通常通過 body 把自定義數據提交給服務器。(同理,GET 也能加 body,給 POST 也能加 query string ,只是一般不這么做)
(3)GET 方法對應的請求,通常設計成 “ 冪等 ”的,POST 對應的請求對于 “ 冪等性 ” 則無要求。
(4)承接冪等性:GET 如果設計成冪等的,此時的 GET 的結果是可以被緩存的。POST 不設計成冪等性,POST 就不應該被緩存。
五 . 請求報頭和響應報頭?
請求報頭與響應報頭其實質就是鍵值對,我們挑幾個比較重要的來講一講。
(1)HOST?
表示服務器主機的地址和端口。
(2)Content - Length 和?Content - Type?
Content - Length 表示 body 中的數據長度,單位是字節。告訴我們,一個 HTTP 數據報到哪里就結束了( HTTP 基于 TCP ,TCP 面向字節流,存在粘包問題,如何解決粘包問題呢?在我上一期有講到過,常用的有兩種方法:指定分隔符,指定數據報長度)。
Content - Type 表示請求或響應的 body 中的數據格式。
如果一個請求 / 響應中沒有 body ,也就沒有這倆字段;如果有 body ,則必須要有這倆字段。Content - Length 和?Content - Type 在請求和響應中都可能存在。
(3)User - Agent(簡稱 UA )
在 UA 中主要包含兩個信息:1 . 操作系統信息(版本);2 .? 瀏覽器信息(版本),這兩種信息表明你在使用怎樣的設備上網。
UA 現在還有一個作用,用來做數據統計。這是我們日常開發的重要環節,因為很多方案的設計、執行并不是一個人一拍腦門就決定的,而是需要討論,更需要一定的數據支撐,而我們通過 UA 可以統計很多的業務指標,然后根據統計結果來進一步的迭代改進產品。( UA 的統計主要用于區分 PC 端和移動端)
(4)Referer?
Referer 就是描述了當前頁面是從哪個頁面跳轉過來的。大家注意,Referer 這個東西,并不一定真的有,當我們直接在地址欄輸入URL 或點擊收藏夾跳轉的網頁,咱們就抓不到 Referer 的包。
大家注意,Referer 跟瀏覽器網頁的回退操作并沒有關系,這兩者不相同。Referer 是在 HTTP 請求當中,發給服務器的,這個東西是給服務器使用的。而瀏覽器的回退,是瀏覽器自身的行為,與 HTTP 協議無關,瀏覽器給每個標簽頁都維護了一個 “ 棧 ” 這樣的數據結構,回退相當于 “ 出棧 ” 。
上面說的統計數據,Referer 在統計數據這一塊也有很大作用,例如我們同一個廣告主會在多個平臺通過多個渠道投放廣告,我們在百度上點擊會跳轉到廣告主的頁面,在搜狗上點擊,也會跳轉到廣告主頁面,廣告主在自己的網站這邊,是可以很容易統計出一段時間內有多少訪問量 / 點擊量的,Referer 的主要作用就是用來區分,這些點擊,哪些來自于百度,哪些來自于搜狗。因為廣告是按照點擊量進行付費嘛,為了以防有造假行為,百度會統計這個廣告有多少點擊量,而廣告主自己也會統計,只有這兩個統計的數據對上了,廣告主才會付費。
(5)Cookie?
Cookie 是瀏覽器本地持久化儲存數據的一種機制,它是按照鍵值對的形式進行存儲的,鍵值對之間用 “ ;” 進行分隔,鍵值對內用 “ = ” 進行分隔鍵和值。值得注意的是,這里面的鍵值對都是程序員自定義的,并且按照域名為維度分別進行儲存。(每個網站有自己的 Cookie ,相互不影響)
上述 Cookie 中的這種鍵值對,看似是從瀏覽器通過請求發送給服務器的,實際上這些數據最初都是從服務器返回給瀏覽器,此處看到的這些數據,都相當于是在瀏覽器本地儲存的。Cookie 是屬于瀏覽器給網站提供的一種 “ 客戶端儲存數據 ” 的機制。對于網站來說,主要的數據都是在服務器這邊儲存的,也有些數據需要在瀏覽器這邊存儲,例如上次訪問的時間,訪問的網址,用戶的基本身份信息等等。
為了安全,瀏覽器禁止網頁直接訪問用戶的硬盤,這一條是在文件系統中直接規定死的,大家想一想,咱們要是想在夜深人靜的時候,悄悄地打開一個學習網站學習學習,但是一打開,網頁直接訪問硬盤資料,將我們里面的數據刪的一干二凈,這是一件多么可怕的事情。但是瀏覽器并沒有把這條路封死,還是開了個小口子,允許網頁通過鍵值對的方式來儲存數據(這樣的數據其本質也是在硬盤上),具體這樣的鍵值對是怎樣存儲到硬盤上的呢?這件事是瀏覽器封裝好的,網頁本身無法干涉,這就是我們的 Cookie 機制。?
Cookie 從哪里來的呢?注意,首次訪問某個網站,可能是不帶 Cookie 的,在響應中就會有 Set - Cookie 字段(可能有多份,這是服務器這邊的程序員根據需要,編寫代碼生成的)這樣的 Header ,把一些鍵值對寫回到瀏覽器這邊,瀏覽器后續訪問這個網站就會帶有 Cookie 。
Cookie 要到哪里去呢?后續瀏覽器訪問同一個服務器的時候,就會把之前儲存的?Cookie 再帶上,從而發送到服務器這邊。這個時候有的小伙伴就可能會問了,既然是從服務器拿出來的,我們下次又放回服務器,這不是多此一舉嘛,我們干嘛不直接一直放著呢?大家上學都有放過假吧,咱們放假是不是會把一些書本作業都裝一些帶回家(其實我以前裝回去的書基本沒動過,特別是上大學以后,手動狗頭),咱們開學了又得帶回學校。通過這一例子就說明什么?說明一個服務器,可能同時會給多個客戶端提供服務,Cookie 中的數據,也是屬于可能在客戶端使用也可能在服務器使用。值得注意的是,Cookie 有一個充分的自定義空間,Cookie 的某個鍵值對,可能只是服務器用,可能只是客服端用,也可能兩邊都要用。
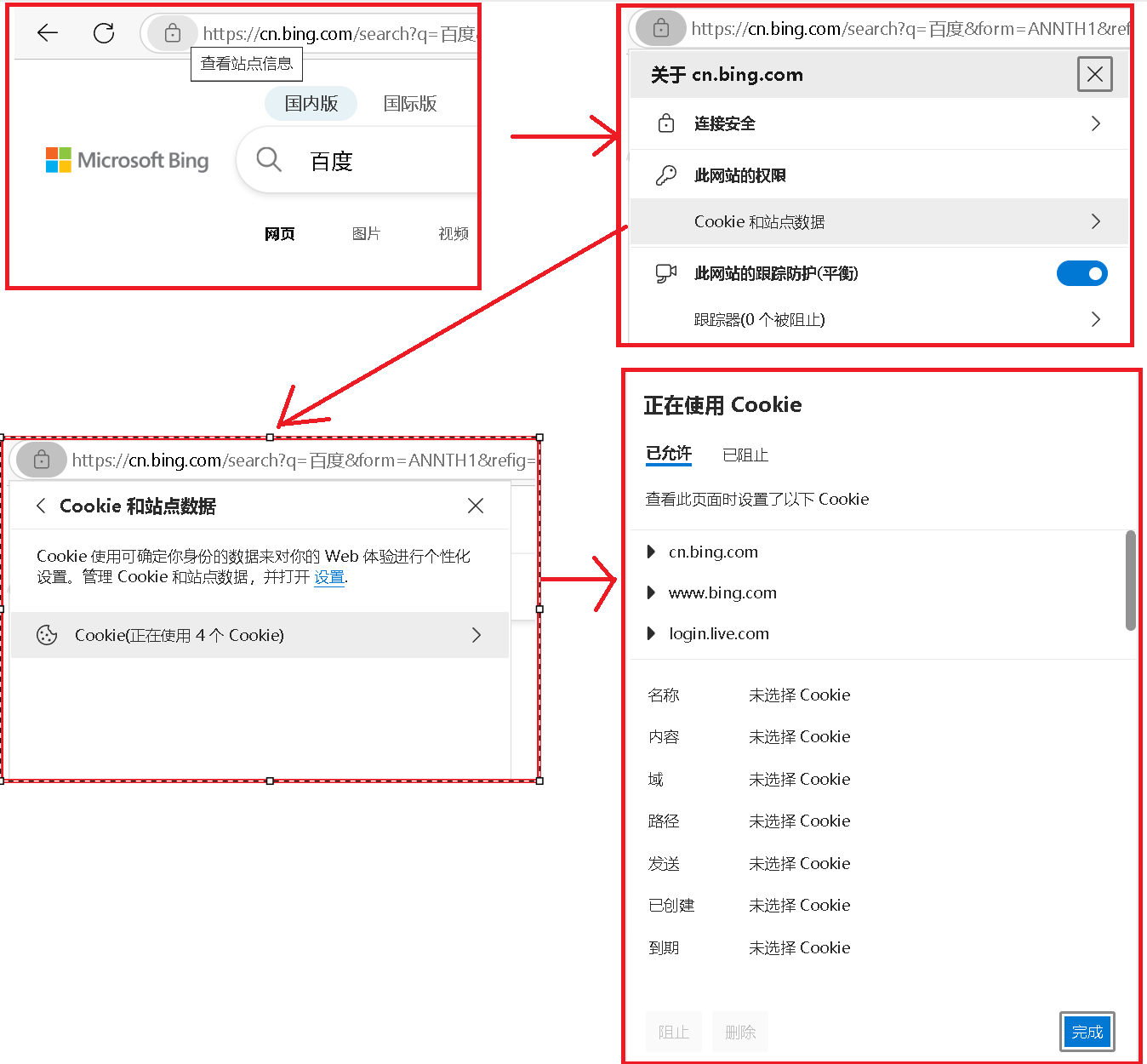
隨著我們時代的變遷,互聯網科技的發展,Cookie 也不是唯一一個能在瀏覽器這邊儲存數據的機制了,它可以說是最早的,但放在現在來說并不是唯一的。目前還有? Local storage(也是鍵值對)、Index db(類似于表這樣的結構) 這些更新型的機制,也可以通過這樣的機制來存儲會話 ID 。
登錄的信息驗證,也不一定都是基于 session 這樣的方式來存儲了,也有一些其他的方式,比如目前業界比較流行的 jwt(把用戶的信息就存儲在客戶端,但是會對其進行加密操作) 的這種方式。
六 . 狀態碼(status code)
HTTP 狀態碼主要分為五個大類,分別是:
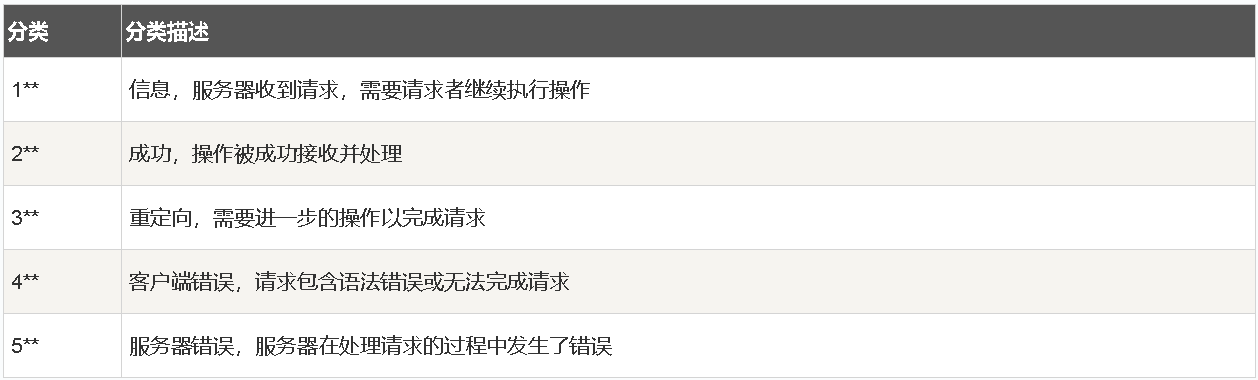
1XX(臨時響應,指示信息):表示臨時響應并且請求已接收需要請求者繼續執行操作的狀態碼:

2XX(響應成功): 表示動作被成功接收、理解和接受。
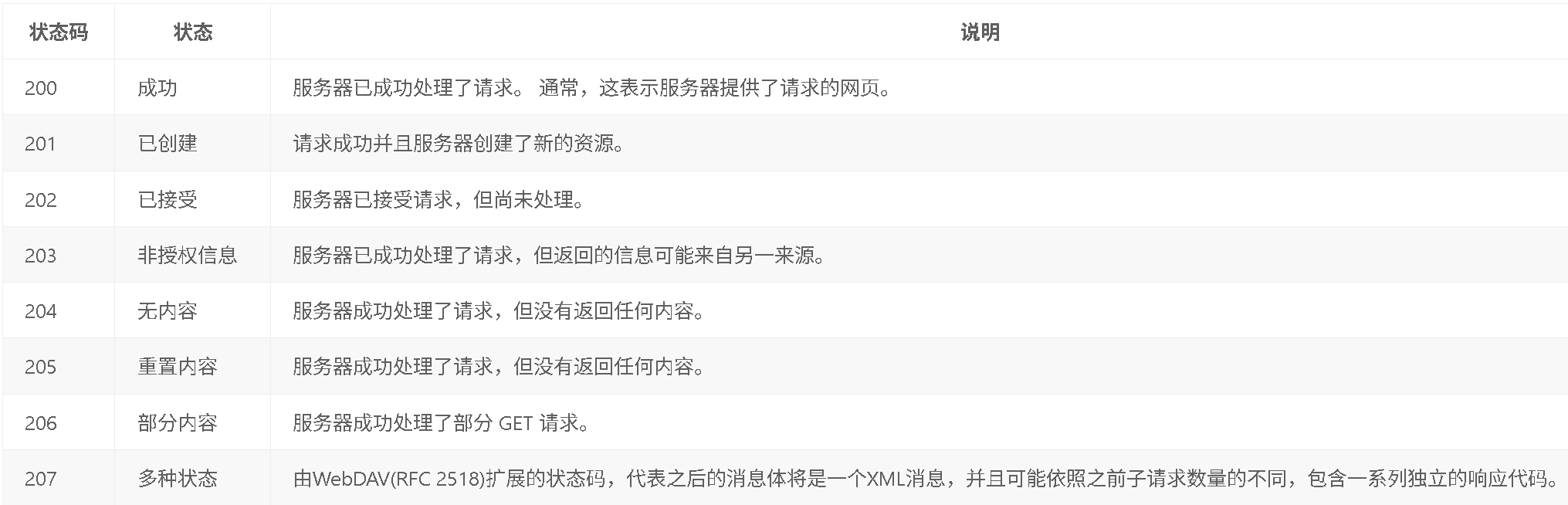
?3XX(重定向):為了完成指定的動作,必須接受進一步處理。

4XX(客戶端錯誤):請求包含錯誤語法或不能正確執行。



5XX(服務器錯誤):服務器不能正確執行一個正確的請求。

6XX狀態碼:

七 . HTTPS?
我們隨便打開一個網頁可以發現,當前的網址都是 “ https ” 形式,為什么不是我們的 “ http ” 呢?這個 https 跟 http 有什么區別呢?這就涉及到 “ 運營商劫持 ” 。
我們先來了解一下什么是運營商:
運營商指的就是提供寬帶服務的 ISP ,我國有三大運營商:中國電信、中國移動、中國聯通,還有一些小運營商,比如長城寬帶、歌華有線寬帶。運營商為我們提供了最基礎的網絡服務,掌握著通往用戶物理大門的鑰匙。
什么是運營商劫持呢?
在以前的年代,由于大家對互聯網知之甚少,一些運營商為了自己的利益,會給你的網頁頁面上加上各種頁面里本來沒有的元素,例如:廣告、彈框等。而當年對于互聯網的法律沒有那么完備,所以一度導致這種 “ 運營商劫持 ” 的現象很猖獗,在十年前,這一現象是很普遍的。
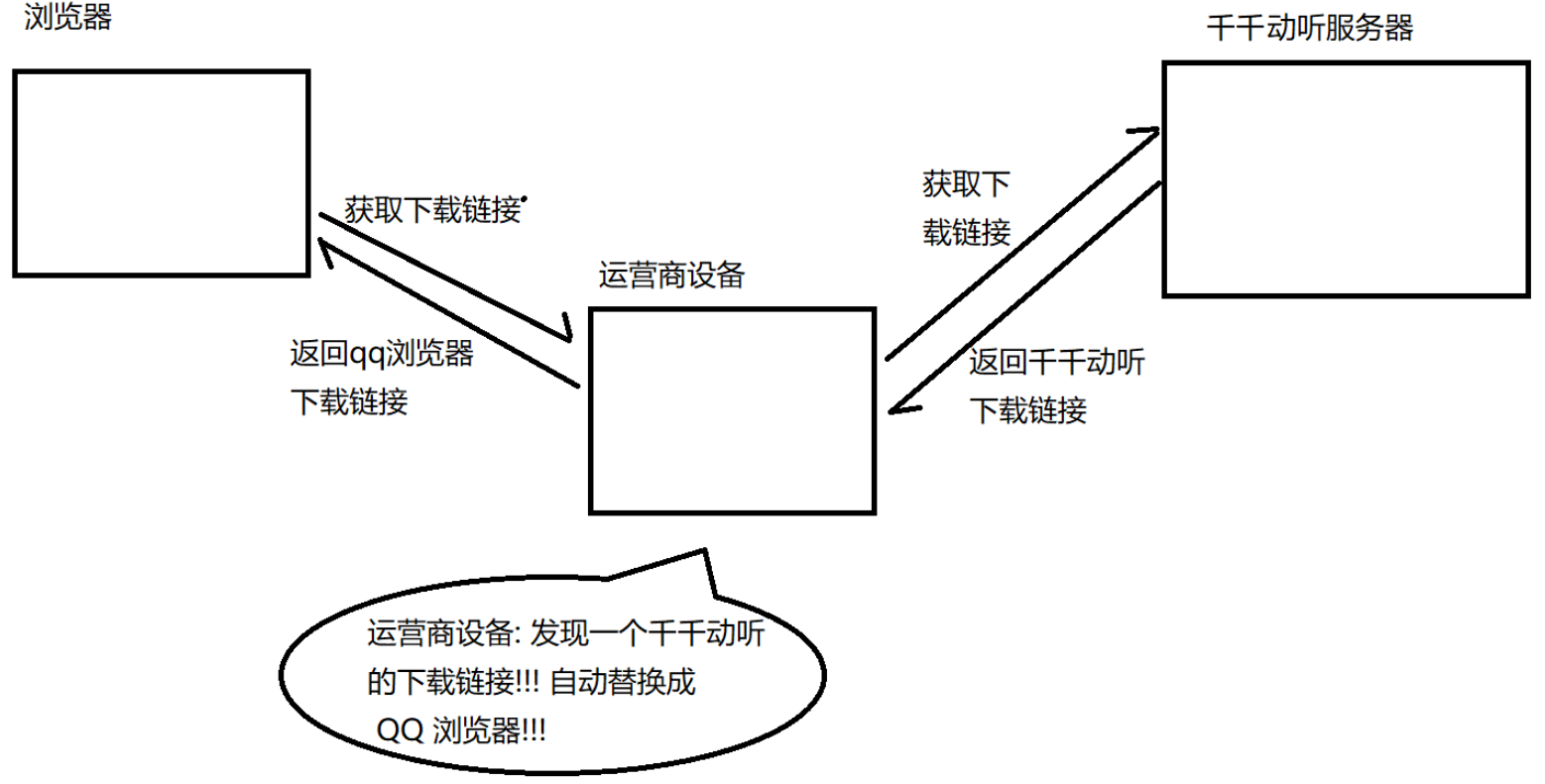
怎樣應對運營商劫持呢?
(1)全站 https ,能防一部分。
(2)加入防運營商劫持代碼,能防大部分注入型劫持。
(3)記錄 Log ,記錄證據,向工信部投訴。
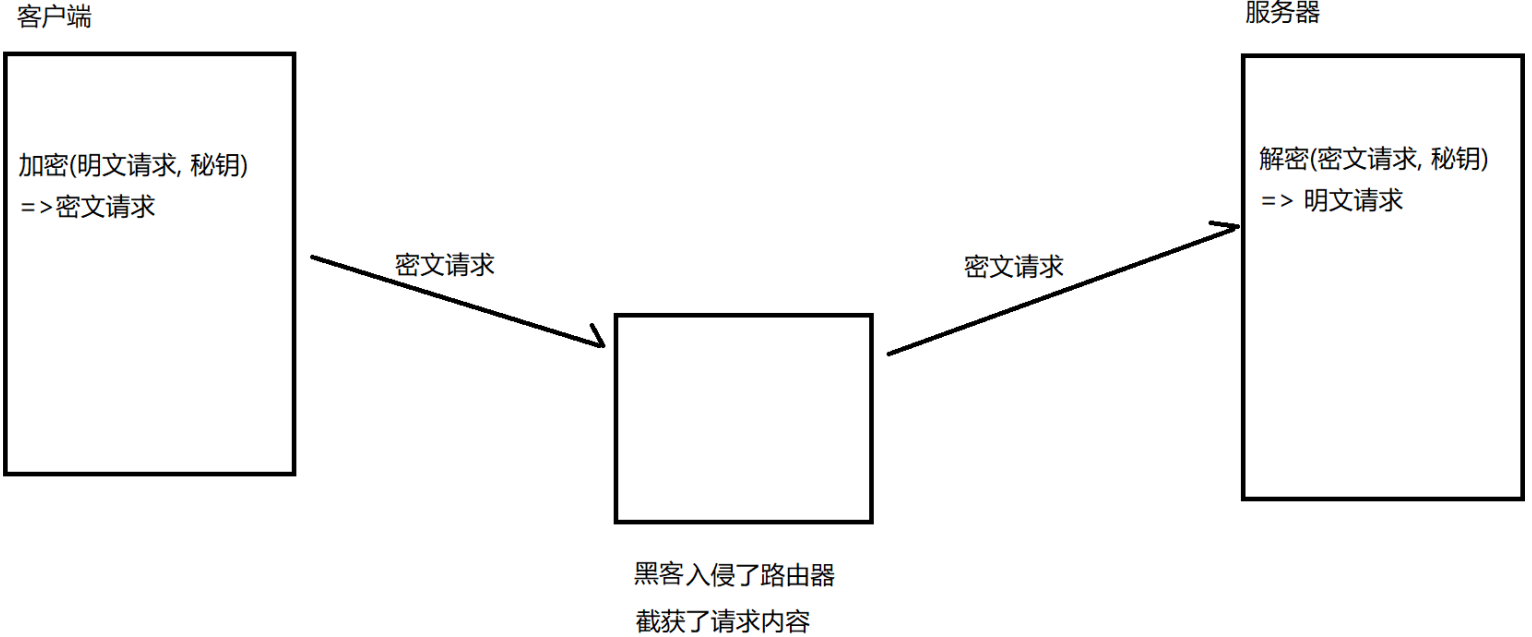
就算我們的網站不被運營商劫持,也有可能被黑客劫持,而被劫持的很大原因就是因為 HTTP 的明文傳輸,所以目前來說,解決這種被劫持最高效的方案就是:HTTPS 加密,進行密碼傳輸。
(1)密鑰?
明文:需要傳輸的原始數據。
密文:把明文進行加密之后得到一個讓別人不能理解的數據。
加密:明文 —> 密文。
解密:密文 —> 明文。
密鑰:進行加密和解密的重要數據 / 輔助工具。

如圖,該奏折中的文字就相當于密文,而挖了孔的封 面紙就相當于密鑰。
對稱加密:加密和解密共用一個密鑰。
非對稱加密:加密和解密分別用兩個密鑰,一個 “ 公鑰(公開出來的密鑰,誰都可以拿到)” ,一個 “?私鑰(私藏起來的密鑰)” 。這兩個沒有固定的加密解密,使用其中一把密鑰加密,就需要使用另一把進行解密。
(2)HTTPS 的基本工作流程?
HTTPS 只是在 HTTP 的基礎上引入了加密機制,其他部分完全一致。
1 . 引入對稱加密?
由于在客戶端與服務器的交互過程中,一個服務器往往對應著多個客戶端,所以我們的多個客戶端必須得使用不同的密鑰(要不然黑客只要自己創建一個客戶端不就也知道密鑰了嘛),因此我們就要求,讓每個客戶端在連上服務器的時候,自己生成一個隨機的對稱密鑰。
2 . 傳輸對稱密鑰給服務器?
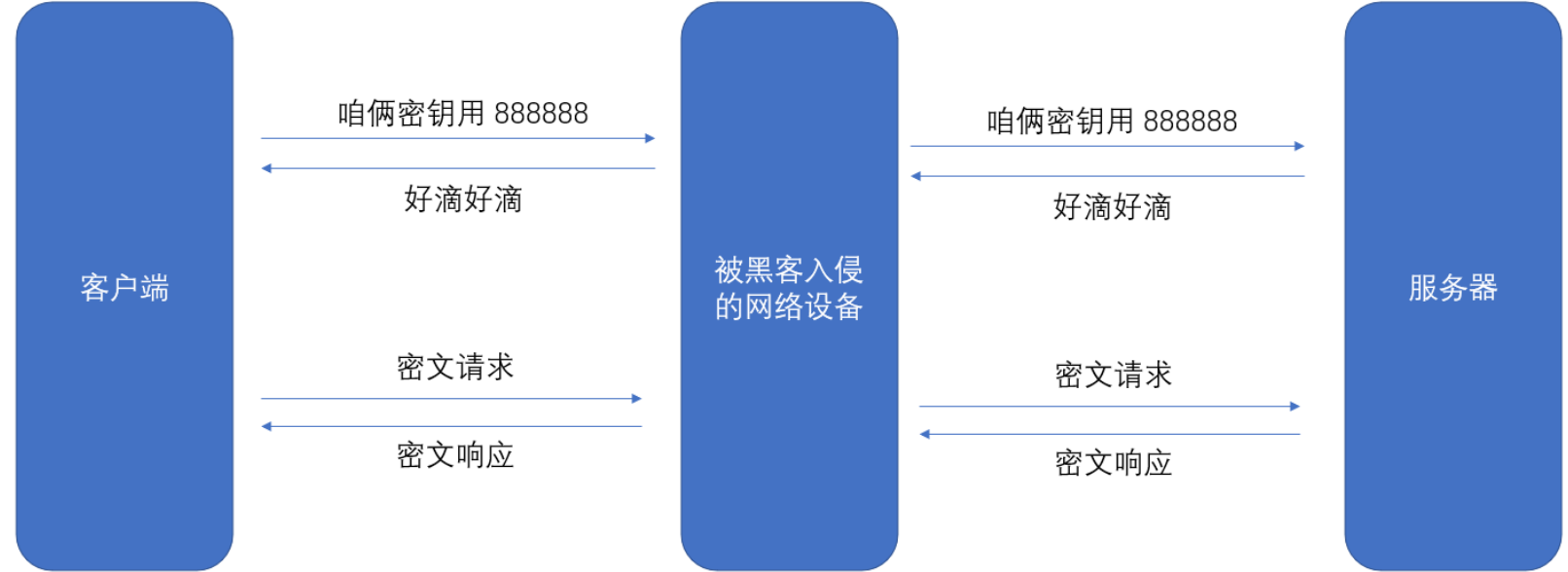
按照這樣的傳輸方式,看似可行,但是我們不管套多少層,依舊必須經過一次明文傳輸將密鑰傳給服務器,任然有可能被黑客截獲到這個密鑰。
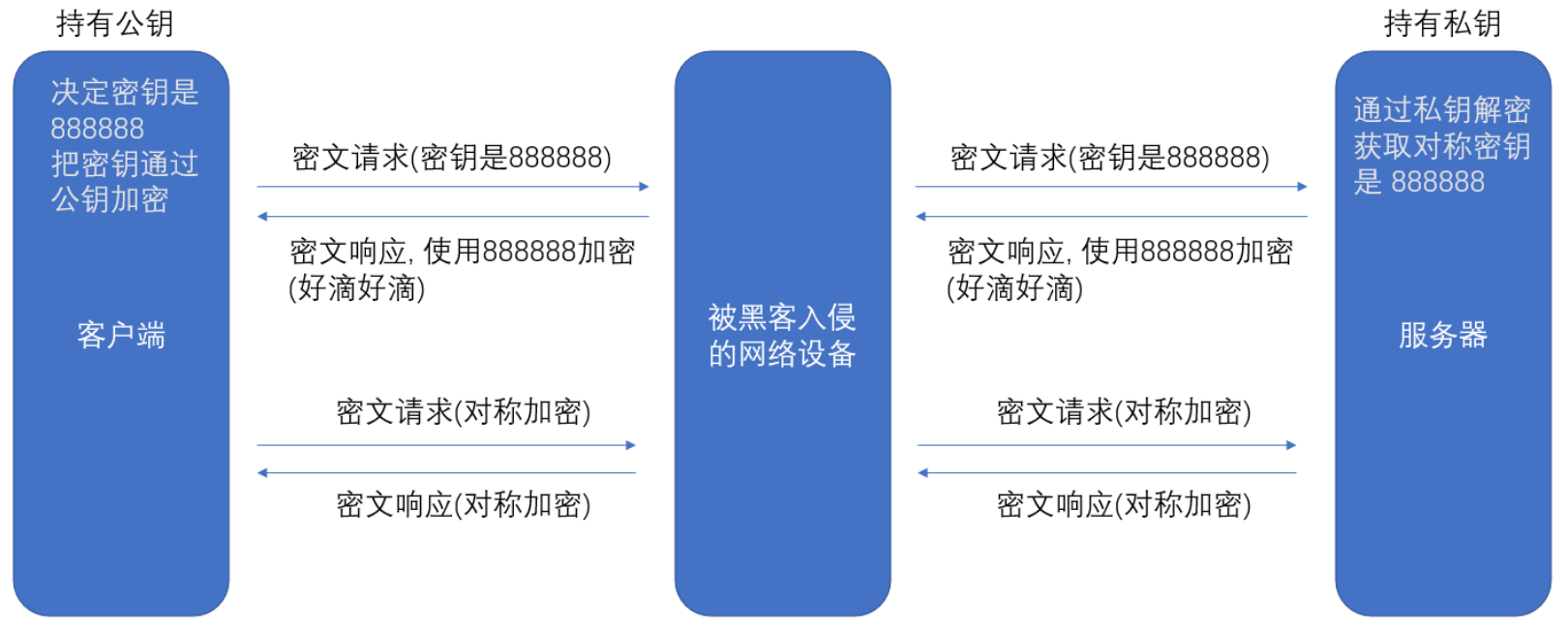
3 . 引入非對稱加密?
通過非對稱加密,對需要進行傳輸的對稱密鑰進行加密非對稱加密的存在目的并不是為了取代對稱加密,而是起到一小部分的 “ 輔助 ” 作用。主要的業務數據仍然是使用對稱加密,但是需要使用非對稱加密來加密傳輸的對稱密鑰。
為什么不完全使用非對稱加密來加密數據呢?這其中最主要的原因就是涉及成本的問題,非對稱加密的運算量開銷比較大,非常消耗計算機性能。
4 . 中間人攻擊?
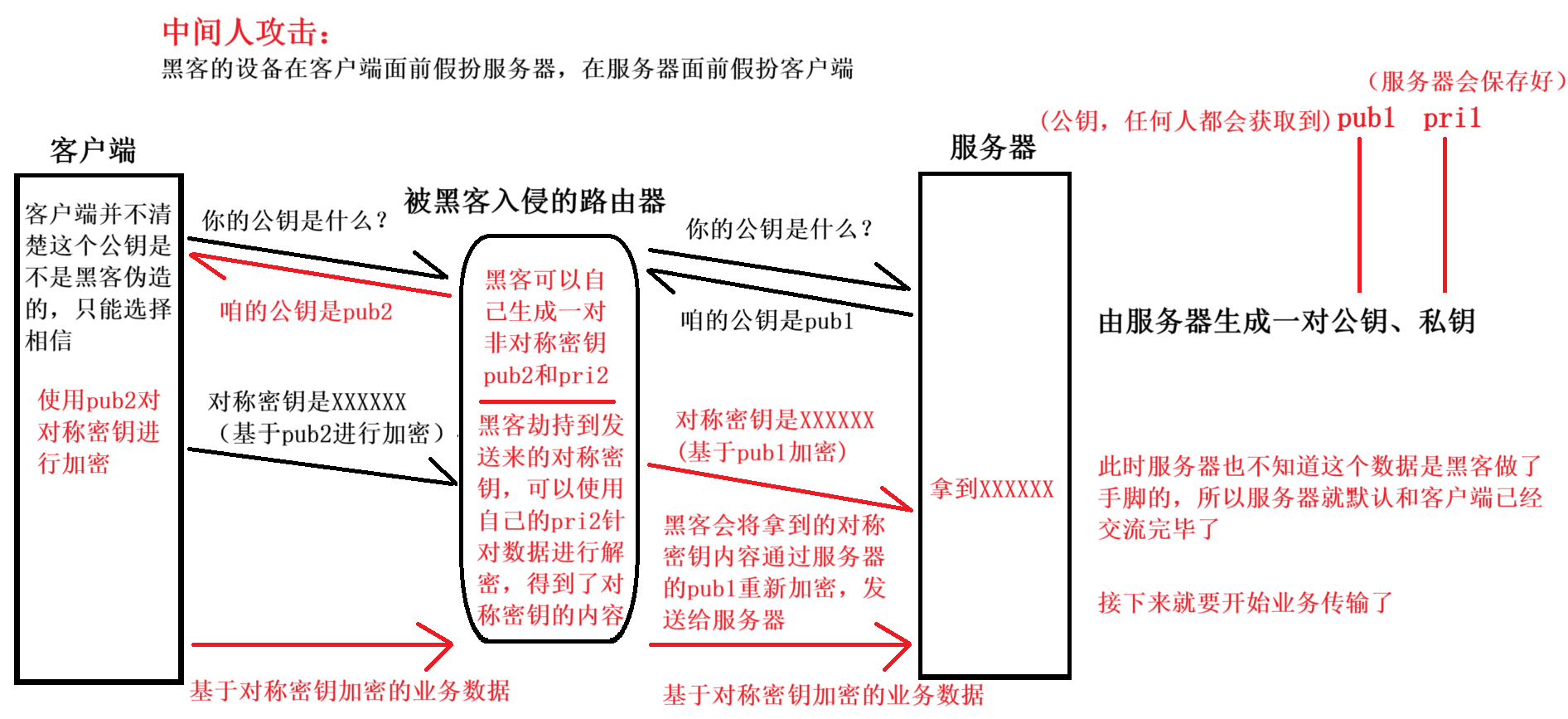
5 . 為了避免中間人攻擊,引入證書系統?
這個問題的關鍵是,能夠讓客戶端識別出拿到的公鑰是不是正確的,合理的,而不是偽造的公鑰。那么我們如何證明公鑰是合理的呢?此時就需要引入第三方證書機構。
如果你想搭建服務器,使用 HTTPS ,就需要在公證機構這里申請證書(電子的一串數據),申請的時候需要提交部分資料(如網站的域名,營業執照,備案號. . . . . )
然后公證機構就會生成一個 “ 電子證書 ” ,其內容主要包含如下幾個字段:證書發布機構,證書有效期,公鑰,證書所有者,簽名 . . . . . 其中最重要的就是 “ 簽名 ” ,它是保證證書合法的關鍵要點。
簽名就是:證書中的各個字段綜合在一起,計算校驗和(原始數據相同,計算得到的校驗和就相同,校驗和不同,說明原始數據就不同)。計算完校驗和之后,再對其進行非對稱加密的操作。
公證機構自己生成一對公鑰、私鑰,私鑰由公證機構自己保存,公鑰則會分發給各種客戶端。公證機構拿著自己的私鑰對剛才的校驗和進行加密,于是就得到了我們的數字簽名。
服務器申請到證書之后,后續客戶端從服務器拿公鑰,就不只是拿公鑰,而是拿整個證書。此時客戶端就可以憑借證書中的數字簽名,對證書的合法性進行驗證。
客戶端如何進行驗證簽名呢?
1 . 客戶端先將證書中的各個字段再算一次檢驗和,得到 checksum1。
2 . 客戶端使用公證機構的公鑰,對數字簽名進行解密,得到 checksum2。
3 . 對比 checksum1 ==?checksum2 ,如果相等,視為當前證書的每個字段就是和服務器這邊發出來的一模一樣,此時就可以認為其是合法證書。反之,若是不相等,就會被視為被不法分子篡改過了,此時瀏覽器網頁往往就會彈出警告標志,提示用戶,該網頁不安全(大家訪問一些學習網站的時候應該多多少少看見過哈,其實并不怎么樣,無視風險訪問哈哈哈)。
當客戶端手里拿著公證機構的公鑰,怎么驗證這個公鑰是不是正確的呢?它不是黑客偽造的呢?這個大可不必擔心,因為這個公鑰是操作系統內置的,并不是通過網絡能獲取的,一般的黑客,是幾乎沒有可能拿到這層信息的。
黑客可不可以在篡改數據之后,同時更改數字簽名,使得數字簽名解密過的 checksum2 和篡改過的?checksum1 一致呢?這種情況理論上也是不可行的!
當黑客篡改了數據之后,要想重新生成數字簽名,就需要使用公證機構的私鑰來加密,首先這個私鑰就不是一般黑客有能力拿得到的。
黑客如果自己生成一個私鑰呢?那么這個時候,客戶端拿著公證機構的公鑰,也解決不了,此時,客戶端解密出錯,也可能認為是證書的問題,也會彈出大大的窗口。
OKK,有關 HTTP 的相關知識點就說這么多了,這一期的知識點多且雜,大家還需要好好理解,就這樣吧,咱們下期再見,與諸君共勉!!!

)



詳解:SVM 中的關鍵損失函數)




 ? | ImageCarousel(圖片輪播組件))
)



)



