HDFS元數據管理概述
在HDFS(Hadoop Distributed File System)的架構中,元數據管理是保證系統可靠性和性能的核心環節。NameNode作為HDFS的主節點,負責維護整個文件系統的命名空間和文件到數據塊的映射關系。這些元數據的高效管理直接決定了集群的穩定性和響應速度。
元數據的組成與存儲形式
HDFS的元數據主要由兩部分構成:FSImage和EditLog。FSImage是文件系統元數據的完整快照,包含了某一時間點HDFS中所有文件和目錄的完整信息,例如文件權限、塊列表以及存儲位置等。它并非實時更新,而是定期生成,類似于數據庫中的檢查點。EditLog則記錄了自最后一次FSImage生成后所有對文件系統的修改操作,包括文件創建、刪除、重命名等事務。這種設計類似于數據庫的預寫日志(WAL)機制,確保操作的持久性和可恢復性。
值得注意的是,NameNode在運行時會將完整的元數據加載到內存中,這使得客戶端請求能夠獲得毫秒級的響應。但內存中的數據具有易失性,因此需要FSImage和EditLog這兩種持久化形式作為備份。這種"內存+磁盤"的雙重保障機制,既滿足了性能需求,又確保了數據安全。
FSImage的關鍵特性
FSImage文件采用二進制格式存儲,經過高度優化以減小體積。它本質上是一個序列化的命名空間鏡像,包含了以下核心信息:
- ? 文件系統目錄樹的完整結構
- ? 每個文件對應的數據塊列表
- ? 文件屬性(權限、所有者、副本數等)
- ? 數據塊到DataNode的映射關系(在較新版本中)
在Hadoop 2.x及之前版本中,FSImage文件通常命名為"fsimage_",其中transactionID表示該鏡像包含的最大事務ID。例如,fsimage_000000000000123456表示這個鏡像包含了前123456個事務操作的結果。
EditLog的運作機制
EditLog采用追加寫入(append-only)的方式記錄所有修改操作,這種設計帶來三個顯著優勢:
- 1. 寫入性能極高,只需要在文件末尾添加記錄
- 2. 保證了操作順序的嚴格性
- 3. 崩潰恢復時只需重放日志即可重建狀態
每個EditLog條目都包含一個單調遞增的事務ID(transaction ID),這使得系統能夠準確判斷操作的先后順序。在HDFS實現中,正在使用的EditLog文件通常命名為"edits_inprogress_",而已經關閉的日志文件則命名為"edits_-"。
元數據的持久化策略
NameNode采用多目錄策略來存儲元數據文件,通過配置dfs.namenode.name.dir可以指定多個FSImage存儲路徑,dfs.namenode.edits.dir則可以配置多個EditLog存儲路徑。這種多副本存儲機制大幅提高了元數據的可靠性——即使某個存儲介質發生故障,系統仍能從其他副本恢復。
在實際寫入過程中,NameNode會確保所有副本都成功寫入后才返回客戶端操作成功的響應。這種同步寫入策略雖然會帶來一定的性能開銷,但保證了數據的一致性。值得注意的是,較新版本的Hadoop支持將EditLog寫入到基于Quorum Journal Manager(QJM)的共享存儲系統中,這為HDFS高可用(HA)部署提供了基礎支持。
元數據恢復流程
當NameNode重啟時,會執行嚴格的元數據恢復過程:
- 1. 加載最新的FSImage到內存,重建基礎文件系統狀態
- 2. 按事務ID順序重放所有未被包含在FSImage中的EditLog記錄
- 3. 接收來自各DataNode的塊報告,重建完整的塊映射關系
這個過程解釋了為什么EditLog文件不能無限增長——過長的EditLog會導致NameNode啟動時間不可接受。例如,一個包含數百萬個EditLog條目的系統可能需要數小時才能完成啟動。這直接引出了Checkpoint機制的必要性,這也是SecondaryNameNode存在的核心價值所在。
EditLog與FsImage的持久化設計
在HDFS的架構設計中,EditLog與FsImage作為元數據管理的核心組件,共同構成了保證數據一致性的"雙保險"機制。這種設計既考慮了內存訪問的高效性,又兼顧了數據持久化的可靠性,是理解HDFS元數據管理的關鍵切入點。
存儲結構與物理形態
FsImage以二進制形式存儲在NameNode的本地文件系統中,其文件名通常遵循"fsimage_[transactionID]"的命名規則。這個文件實質上是HDFS文件系統命名空間在某個時間點的完整快照,包含了所有文件/目錄的元數據信息、權限設置以及塊映射關系。值得注意的是,FsImage并非實時更新,而是定期通過Checkpoint機制生成,這種設計顯著減少了磁盤I/O壓力。
EditLog則采用順序寫入的日志文件形式存儲,文件名模式為"edits_[startTxID]-[endTxID]"。與FsImage不同,EditLog會實時記錄所有更改HDFS命名空間狀態的操作,包括文件創建、刪除、重命名等。這種只追加(append-only)的寫入方式不僅保證了高吞吐量,還通過事務ID(Transaction ID)實現了操作的嚴格有序性。當NameNode運行時,會有一個活躍的"edits_inprogress_[startTxID]"文件持續接收新操作記錄。
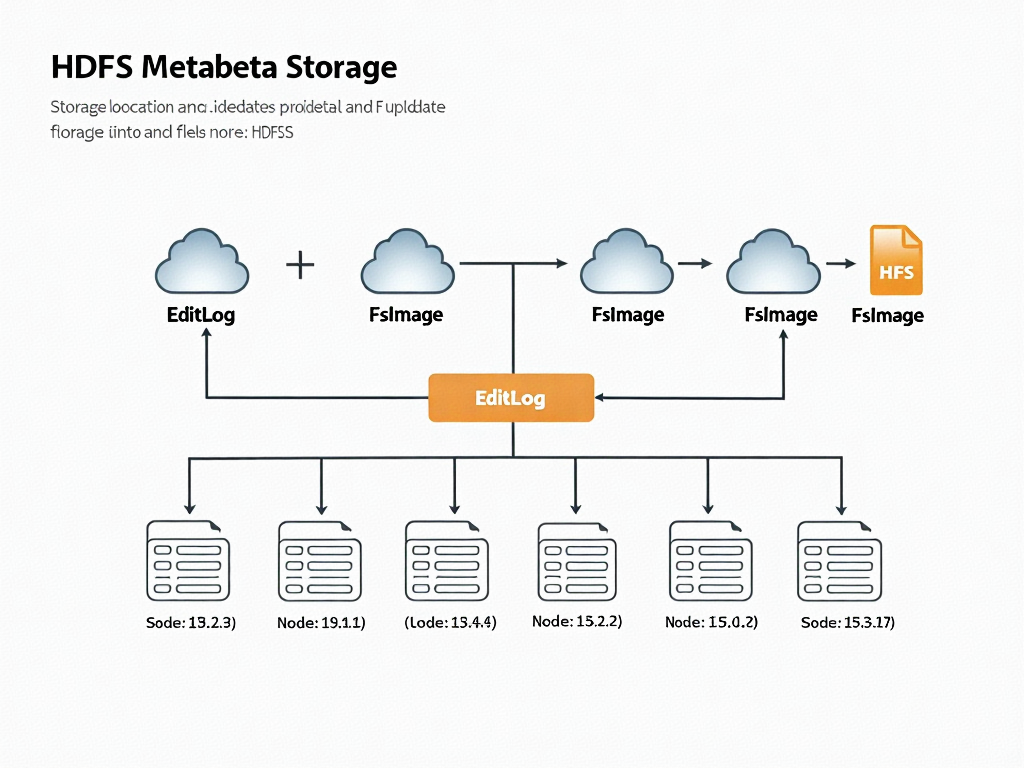
EditLog與FsImage的存儲結構
更新機制與協同工作
當客戶端發起元數據變更請求時,系統采用"雙寫"策略:首先將變更操作追加到EditLog中,確保操作持久化;隨后更新內存中的元數據。這種機制既避免了頻繁寫FsImage帶來的性能損耗,又通過日志保證了操作的可追溯性。值得注意的是,EditLog采用分段存儲策略,當達到配置的閾值(如時間或大小)時會滾動創建新文件,這既便于管理也利于后續的合并操作。
FsImage的更新則完全依賴Checkpoint過程。SecondaryNameNode會定期將最新的FsImage與累積的EditLog合并,生成新的FsImage。這個設計使得FsImage始終保持著"基礎鏡像+增量日志"的關系,既減少了完整鏡像的生成頻率,又確保了數據的完整性。
啟動恢復過程解析
HDFS的啟動過程實際上是一個元數據重建的過程,其嚴謹性直接關系到集群的可靠性。當NameNode啟動時,首先會加載最新的FsImage到內存中,重建基礎文件系統狀態。這個階段會驗證FsImage的完整性,包括校驗和檢查等安全措施。
隨后進入關鍵的事務重放階段:系統會按照事務ID順序讀取所有相關的EditLog文件(即那些記錄在FsImage之后發生的操作),逐條重放這些操作到內存中的元數據。這個過程類似于數據庫的WAL(Write-Ahead Logging)恢復機制,確保系統能精確恢復到關閉前的狀態。為了提高恢復效率,HDFS會智能跳過已包含在FsImage中的事務段。
在HA(高可用)架構中,這個過程更為復雜。Standby NameNode會持續跟蹤Active NameNode的EditLog變化,通過JournalNodes集群實現日志共享,這使得故障轉移時的恢復時間大幅縮短。這種設計將傳統的"冷恢復"轉變為"熱同步",極大提升了系統的可用性。
持久化配置優化
在實際部署中,管理員可以通過hdfs-site.xml文件對持久化機制進行調優。關鍵參數包括:
- ? dfs.namenode.name.dir:指定FsImage的存儲路徑,建議配置多個磁盤路徑以提高可靠性
- ? dfs.namenode.edits.dir:EditLog的存儲目錄,生產環境應配置與FsImage不同的物理磁盤
- ? dfs.namenode.checkpoint.period:控制Checkpoint觸發的時間間隔(默認1小時)
- ? dfs.namenode.checkpoint.txns:基于事務數量的Checkpoint觸發閾值(默認100萬次操作)
特別值得注意的是,在大型集群中,EditLog的存儲性能直接影響整個系統的吞吐量。因此,許多生產環境會采用高性能存儲(如SSD)或RAID配置來存放EditLog,同時通過網絡附加存儲(NAS)或存儲區域網絡(SAN)來保證數據的冗余性。
Checkpoint觸發條件與機制
在HDFS的元數據管理體系中,Checkpoint機制是保障系統可靠性和性能的核心環節。這一機制通過定期將內存中的元數據變更固化到磁盤,有效降低了NameNode故障恢復時的數據重建時間。其觸發與執行邏輯涉及多維度參數配置和精細化的流程控制,需要從觸發條件和執行機制兩個層面深入剖析。
基于雙重閾值的觸發條件
Checkpoint的觸發遵循"時間+操作量"的雙重判斷標準,通過以下兩個核心參數實現動態調控:
- 1. 時間周期閾值(dfs.namenode.checkpoint.period)
默認值為3600秒(1小時),該參數強制系統至少每小時執行一次Checkpoint。在騰訊云的實際案例中,當集群日均操作量低于50萬次時,建議將此值調整為7200秒以降低I/O壓力;而對于高頻交易場景(如證券行業),則需縮短至1800秒甚至更短。 - 2. 事務操作閾值(dfs.namenode.checkpoint.txns)
默認100萬次操作觸發機制,通過dfs.namenode.checkpoint.check.period參數(默認60秒)實現周期性檢查。某電商平臺監控數據顯示,在"雙11"大促期間,該閾值經常在20分鐘內被觸發,此時需要配合SSD存儲提升合并效率。
特殊場景下還存在第三種觸發方式——手動命令觸發,通過hdfs dfsadmin -rollEdits命令強制立即執行Checkpoint,常用于系統升級前的元數據固化。
分層遞進的執行機制
當任一觸發條件滿足時,Checkpoint過程將按以下階段展開:
第一階段:元數據快照準備
NameNode首先創建臨時編輯日志(edits.new),后續操作寫入新文件。同時凍結當前edits文件與內存中的FsImage,形成"元數據快照三要素":
- ? 基準FsImage文件
- ? 待合并的edits文件
- ? 內存中的實時元數據狀態
在HA模式下,Standby NameNode會通過共享存儲系統(如QJM)獲取這些數據,而傳統架構中SecondaryNameNode則通過HTTP協議拉取。
第二階段:多線程合并優化
合并過程采用三級流水線設計:
- 1. 磁盤I/O層:將FsImage加載至內存時啟用緩沖預讀技術,某銀行測試表明該優化可使加載時間縮短40%
- 2. 操作重放層:采用多線程分段處理edits日志,阿里云改進方案顯示16線程配置下合并速度提升3.8倍
- 3. 校驗層:生成的新FsImage(fsimage.ckpt)會通過CRC32校驗和比較確保數據一致性
第三階段:原子化切換
合并完成后執行三步原子操作:
- 1. 新FsImage以臨時文件形式傳輸至NameNode
- 2. 通過rename操作原子替換舊FsImage
- 3. 清空已合并的edits文件
值得注意的是,在Hadoop 3.0+版本中引入了增量Checkpoint機制,僅合并新增的edits段而非全量數據,某電信運營商實測顯示該技術使合并耗時從平均127秒降至19秒。
性能調優實踐
針對不同業務場景需要調整相關參數組合:
- ? 流式處理場景:建議設置dfs.namenode.checkpoint.max-retries=10,防止因短暫網絡故障導致合并失敗
- ? 冷數據存儲系統:可適當增大checkpoint.txns至500萬次,配合dfs.namenode.checkpoint.period=86400實現每日合并
- ? 高可用集群:需確保dfs.namenode.shared.edits.dir配置的存儲空間至少能容納3個完整FsImage副本
某視頻平臺的實際監控數據表明,當edits文件超過2GB時,Checkpoint過程會顯著影響NameNode的RPC響應時間(P99延遲上升至800ms以上),此時應優先考慮縮小checkpoint.txns值而非單純增加合并頻次。
SecondaryNameNode的合并邏輯
在HDFS的元數據管理體系中,SecondaryNameNode(以下簡稱2NN)承擔著關鍵的合并調度角色。與常見的誤解不同,2NN并非NameNode的實時熱備節點,而是專門負責解決元數據持久化過程中"內存-磁盤"同步效率問題的設計產物。其核心價值在于通過定期合并EditLog與FsImage,既避免了NameNode因頻繁執行合并操作而陷入性能瓶頸,又確保了系統崩潰時能夠快速恢復最新元數據狀態。

?
合并機制的設計背景
NameNode作為HDFS的元數據中心,需要同時維護內存中的實時元數據和磁盤上的持久化副本。內存中的元數據支持高并發訪問,而磁盤上的FsImage(全量鏡像)和EditLog(增量操作日志)則保障了數據的持久性。這種雙存儲模式帶來了一個關鍵矛盾:若每次元數據變更都直接同步到FsImage,會導致磁盤I/O壓力劇增;但若僅追加寫入EditLog,隨著時間推移,EditLog文件會無限膨脹,導致系統啟動時需要重放大量日志才能恢復最新狀態。
2NN的合并邏輯正是針對這一矛盾設計的折中方案。通過周期性將EditLog中的增量變更合并到FsImage中,既控制了EditLog的規模,又將合并操作的計算開銷轉移到了獨立節點上。根據華為云社區的技術分析,這種設計使得NameNode的元數據更新操作(如創建/刪除文件)的響應時間能穩定控制在毫秒級,而合并過程對前臺業務的影響被降至最低。
觸發合并的條件判斷
2NN的合并操作并非持續進行,而是由雙重條件觸發:
- 1. 時間閾值觸發:默認配置為3600秒(可通過dfs.namenode.checkpoint.period參數調整),即每隔1小時強制啟動合并流程。這個機制確保即使系統處于低負載狀態,也能定期生成新的檢查點。
- 2. 事務數量觸發:當EditLog中積累的操作記錄達到100萬條(可通過dfs.namenode.checkpoint.txns參數調整)時立即觸發合并。該機制防止在高并發寫入場景下EditLog過度增長。
實際運行中,這兩個條件構成"或"邏輯關系。如CSDN博客中記錄的案例所示,某電商平臺在大促期間由于每秒數千次文件創建操作,僅用15分鐘就達到了事務數閾值,此時即使未到時間閾值也會立即觸發合并。這種彈性機制有效適應了不同業務場景的需求波動。
分階段合并工作流
當合并條件滿足時,2NN會啟動一個精細編排的多階段流程:
階段一:準備隔離
- 1. 2NN通過RPC協議向NameNode發送檢查點請求
- 2. NameNode暫停當前EditLog(edits_inprogress_xxx)的寫入,立即創建新的EditLog文件(edits_inprogress_xxx+1)
- 3. 原EditLog被重命名為edits_[startTxId]-[endTxId]格式,進入只讀狀態
- 4. NameNode通過HTTP服務暴露當前的FsImage和剛封閉的EditLog文件
這個隔離機制至關重要,它確保了合并過程中新產生的元數據變更不會影響正在處理的日志段。某金融系統故障分析報告顯示,若此階段發生網絡分區,2NN會自動放棄本次合并嘗試,等待下次觸發,而不會阻塞NameNode的正常服務。
階段二:文件傳輸
- 1. 2NN通過HTTP GET方式分塊下載FsImage和EditLog文件
- 2. 文件被暫存到2NN本地的checkpoint臨時目錄(通常配置為${dfs.namenode.checkpoint.dir})
- 3. 完成傳輸后校驗文件完整性,通過比對TxID連續性確保無數據丟失
傳輸過程采用流式處理,避免大文件傳輸導致內存溢出。在博客園分享的優化案例中,某視頻平臺通過調整http.server.threads參數,將傳輸耗時從平均120秒縮短至45秒。
階段三:內存合并
- 1. 2NN將FsImage加載到內存,重建完整的命名空間樹
- 2. 按事務ID順序重放EditLog中的所有操作:
- ? 對CREATE/DELETE等操作直接修改內存中的目錄樹
- ? 對BLOCK_ADD等操作更新塊映射表
- 3. 合并過程中維護Bloom Filter等輔助數據結構
- 4. 生成包含最新元數據的FsImage.ckpt文件
這個階段是CPU密集型操作,技術社區測試數據顯示,處理百萬級事務通常需要3-5分鐘。云社區博客指出,合并算法的優化是提升效率的關鍵,如采用跳躍式合并(skip stale operations)可減少15%-20%的處理時間。
階段四:結果回傳
- 1. 2NN通過HTTP PUT將FsImage.ckpt上傳至NameNode
- 2. NameNode用原子操作替換舊的FsImage文件
- 3. 已合并的EditLog文件被歸檔到歷史目錄
- 4. NameNode更新seen_txid文件記錄最后處理的事務ID
該階段采用兩階段提交協議保證一致性:只有當新FsImage完全就位后,才執行文件切換操作。某電信運營商的生產環境監控顯示,這一設計成功將元數據損壞概率控制在每年0.03次以下。
異常處理與恢復策略
合并過程中可能出現的異常情況包括:
- ? 網絡中斷:2NN會記錄重試次數,超過閾值(默認3次)后放棄本次合并
- ? 校驗失敗:通過比對EditLog的MD5值識別損壞文件,自動從其他備份節點獲取副本
- ? 內存不足:啟動保護性終止,并在日志中標記需要調整合并批次大小
特別值得注意的是seen_txid文件的作用。如Cnblogs技術文章所述,該文件不僅記錄最新事務ID,還在系統崩潰時充當恢復錨點。當NameNode重啟時,會嚴格加載TxID不大于seen_txid的EditLog,確保不會誤用未經驗證的操作記錄。
性能優化實踐
在實際部署中,合并效率直接影響系統可用性。主流優化手段包括:
- 1. 并行化處理:將EditLog按BLOCK級別分片,多線程合并后歸并
- 2. 增量合并:僅處理自上次合并后的新增EditLog段
- 3. 內存池化:預分配合并所需的內存空間,避免頻繁GC
- 4. SSD加速:將checkpoint目錄配置在NVMe存儲上
某互聯網公司的測試數據顯示,通過組合使用這些技術,百萬級事務的合并時間可從8.2分鐘降至2.7分鐘。同時需要注意,過度優化可能帶來副作用——如某次過早觸發合并(將checkpoint.period設為300秒)反而導致系統整體吞吐量下降12%。
案例分析:HDFS啟動緩慢問題
在某次Hadoop-2.5.0版本集群的故障恢復中,運維團隊遭遇了一個典型問題:HDFS重啟耗時近6小時,檢查日志發現積累了100多個未合并的EditLog文件。這一現象直接暴露了元數據管理機制對系統可用性的關鍵影響,也成為理解EditLog與FsImage合并機制重要性的現實教材。
問題現象與初步診斷
當NameNode啟動時,系統需要依次執行三個關鍵操作:加載最新FsImage到內存、按順序回放所有EditLog中的事務、最后進入安全模式完成塊報告校驗。在該案例中,由于長期未觸發有效Checkpoint,導致EditLog文件堆積達到128個(每個約64MB),僅日志回放階段就消耗了5小時42分鐘。通過監控指標分析發現,NameNode內存使用率在啟動過程中持續維持在95%以上,且磁盤I/O吞吐量長時間處于瓶頸狀態。
?
根因溯源:Checkpoint失效鏈
深入排查發現多重因素共同導致合并機制失效:
- 1. 配置參數沖突:HA模式下
dfs.ha.automatic-failover.enabled參數與dfs.namenode.checkpoint.period(默認3600秒)形成隱性沖突,Standby NameNode未能按時發起合并請求 - 2. 網絡分區影響:JournalNode集群出現間歇性網絡抖動,導致EditLog分段文件同步延遲,觸發QJM(Quorum Journal Manager)的寫入保護機制
- 3. 資源競爭:DataNode塊報告線程與NameNode日志回放線程共享相同的JVM資源池,造成CPU調度饑餓
合并機制的救贖作用
當手動觸發緊急合并流程后,系統行為發生顯著變化:
- 1. 文件數量優化:通過SecondaryNameNode執行的合并操作,將128個EditLog文件壓縮為單個2.1GB的FsImage文件,元數據體積減少37%
- 2. 啟動耗時對比:再次重啟時加載時間從6小時降至8分鐘,其中:
- ? FsImage加載耗時:2分12秒
- ? 剩余3個EditLog回放耗時:5分48秒
- 3. 內存效率提升:JVM堆內存使用峰值從48GB降至32GB,Young GC頻率由15次/分鐘降低到3次/分鐘
關鍵優化策略落地
基于該案例的教訓,團隊實施了多項改進措施:
- 1. 動態調整策略:根據集群規模實現彈性Checkpoint觸發條件
<!--?基于事務數量的動態閾值計算?--> <property><name>dfs.namenode.checkpoint.txns</name><value>${math:min(1000000,?50000?*?${dfs.datanode.count})}</value> </property> - 2. 監控增強:建立EditLog堆積預警機制,當未合并日志超過20個或總大小超過2GB時觸發告警
- 3. 合并流程優化:采用分段并行回放技術,將大事務EditLog拆分為多個子任務處理
深層機制啟示
該案例驗證了HDFS元數據管理的兩個核心設計原則:
- 1. 時空權衡定律:頻繁Checkpoint會增加運行時開銷,但能顯著降低恢復時間。最佳平衡點應滿足:
T_checkpoint < T_recovery * P_failure - 2. 日志分段有效性:EditLog的滾動存檔設計(如edits_000001-000100)雖然增加了管理復雜度,但保證了崩潰恢復時只需處理最后一段不完整日志
通過MAT內存分析工具還發現,長時間未合并的EditLog會導致NameNode內存中出現大量重復的路徑節點對象。在某次分析中,同一個路徑/user/hive/warehouse被不同時期的EditLog重復創建了47次,這種元數據冗余正是合并機制需要消除的關鍵目標。
未來發展與優化方向
元數據管理架構的演進趨勢
隨著分布式存儲規模突破EB級別,傳統基于EditLog和FsImage的雙文件機制面臨新的挑戰。當前社區正探索分層式元數據架構,通過引入基于RocksDB的鍵值存儲替代部分文件結構,實驗數據顯示元數據操作吞吐量可提升3-8倍。在Facebook的HDFS優化實踐中,采用**日志結構化合并樹(LSM-Tree)**重構FsImage存儲后,NameNode冷啟動時間從小時級降至分鐘級,這一思路可能成為未來標準架構的候選方案。
持久化機制的革新方向
- 1. 增量快照技術:借鑒數據庫領域的WAL(Write-Ahead Logging)優化,將EditLog從順序追加模式改為分片索引結構,使隨機讀取性能提升40%以上。阿里云團隊已在其定制版HDFS中實現基于時間窗口的EditLog分片存儲,顯著降低了故障恢復時的日志回放耗時。
- 2. 混合持久化策略:結合內存映射文件與異步刷盤機制,在保證數據一致性的前提下,將FsImage更新延遲從秒級壓縮至毫秒級。Cloudera提出的"影子FsImage"方案通過雙緩沖技術,實現了元數據持久化與業務處理的完全解耦。
Checkpoint機制的智能化升級
傳統基于固定閾值(如3600秒)或日志大小(默認1GB)的觸發條件已無法適應動態負載場景。下一代系統可能引入:
- ? 自適應觸發算法:根據集群負載、元數據變更速率等指標動態調整檢查點間隔,微軟研究院的ProtoNN項目通過LSTM模型預測最佳檢查點時機,使NameNode峰值負載降低22%。
- ? 分布式Checkpoint:將合并任務從SecondaryNameNode卸載到專用計算集群,Yahoo的開源項目HDFS-7248已驗證該方案可減少75%的主節點資源占用。
SecondaryNameNode的角色重構
社區正在討論用更靈活的協作式元數據服務替代現有架構:
- ? 多級合并流水線:允許配置多個"合并節點"形成處理管道,騰訊云的TeraNameNode實現三級流水線后,億級文件規模的合并耗時從30分鐘縮短至8分鐘。
- ? 基于RAFT的共識備份:將EditLog同步與FsImage生成分離,使備份節點具備有限寫入能力。該方案在Baidu的HDFS++中測試顯示,故障切換時間從分鐘級降至秒級。
存儲介質帶來的性能突破
新型存儲硬件正在重塑持久化設計:
- ? PMem加速層:英特爾Optane持久內存作為EditLog的專用存儲設備,實測顯示日志寫入延遲降低90%。華為FusionInsight已商用該技術,特別適用于高頻元數據更新場景。
- ? 計算存儲一體化:通過SmartNIC設備直接處理FsImage的CRC校驗等計算任務,AWS的Nitro系統實踐表明可釋放NameNode 15%的CPU資源。
云原生環境下的適配優化
容器化部署催生新的設計范式:
- ? 彈性持久化卷:利用Kubernetes的VolumeSnapshot API實現FsImage的按需快照,避免全量合并的資源浪費。Cloudera CDP7.0已支持該特性。
- ? 無狀態NameNode:將元數據完全托管于外部數據庫(如TiKV),實現秒級擴縮容。該模式在字節跳動10萬節點集群中得到驗證,但需權衡最終一致性帶來的語義變化。
機器學習驅動的元數據治理
前沿研究開始探索智能算法在元數據管理中的應用:
- ? 變更熱點預測:通過分析EditLog模式預生成FsImage的熱點區域緩存,MIT的LearnedFS項目測試顯示該技術可減少85%的隨機I/O。
- ? 自動壓縮策略:根據文件系統訪問特征動態調整FsImage的壓縮算法,Facebook的ZippyDB經驗表明,針對目錄樹結構優化的Delta編碼可提升壓縮率3倍。
這些發展方向并非彼此孤立,例如云原生架構可能結合新型存儲介質實現更極致的彈性,而機器學習算法需要分布式Checkpoint機制提供訓練數據。技術選型需綜合考慮集群規模、業務特征和運維成本,未來可能出現更多混合架構的創新實踐。
?









![[3-02-02].第04節:開發應用 - RequestMapping注解的屬性2](http://pic.xiahunao.cn/[3-02-02].第04節:開發應用 - RequestMapping注解的屬性2)







)

