轉載:https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
在啟動 Manus (manus.im/app) 項目之初,我的團隊面臨一個關鍵抉擇:究竟是基于開源基礎模型訓練一個端到端的智能體模型,還是在前沿大模型的“上下文學習”(In-Context Learning)能力基礎之上構建智能體?
在我從事自然語言處理 (NLP) 的第一個十年里,我們沒有這樣“奢侈”的選擇。在久遠的 BERT (arxiv.org/abs/1810.04805) 時代(沒錯,已經七年了),模型必須經過微調和評估才能遷移到新的任務上。即使當時的模型比現在的大語言模型(LLM)小得多,這個過程每迭代一次也常常需要數周時間。對于快速發展的應用,尤其是在達到產品市場契合點 (PMF) 之前,如此緩慢的反饋周期是無法接受的。這是我上一家創業公司留下的痛苦教訓,當時我從零開始訓練模型以實現開放信息提取(Open Information Extraction)和語義搜索。后來,GPT-3 (arxiv.org/abs/2005.14165) 和 Flan-T5 (arxiv.org/abs/2210.11416) 橫空出世,我內部開發的模型一夜之間便失去了競爭力。諷刺的是,正是這些模型開啟了上下文學習(In-Context Learning)的新時代,也為我們指明了新的前進方向。
這次來之不易的教訓使我們明確了選擇:Manus 將側重“上下文工程”(Context Engineering)。這讓我們能夠將改進的交付時間從數周縮短到數小時,并使我們的產品與底層模型保持獨立:如果說模型進步是水漲船高,那么我們希望 Manus 成為那艘隨波而動的船,而不是深陷海底的柱子。
盡管如此,實踐證明上下文工程絕非易事。它是一門實驗性科學——我們已經四次重構了我們的智能體框架,每一次都是在發現了更好的上下文構建方法之后進行的。我們親切地將這種架構搜索、提示詞調整和經驗性猜測的手動過程稱為“隨機梯度下降法”(Stochastic Graduate Descent)。它雖然不夠優雅,但確實有效。
本文將分享我們通過這種“隨機梯度下降法”找到的局部最優解。如果你也在構建自己的 AI智能體,我希望這些原則能幫助你更快地收斂。
圍繞 KV-緩存(KV-Cache)進行設計
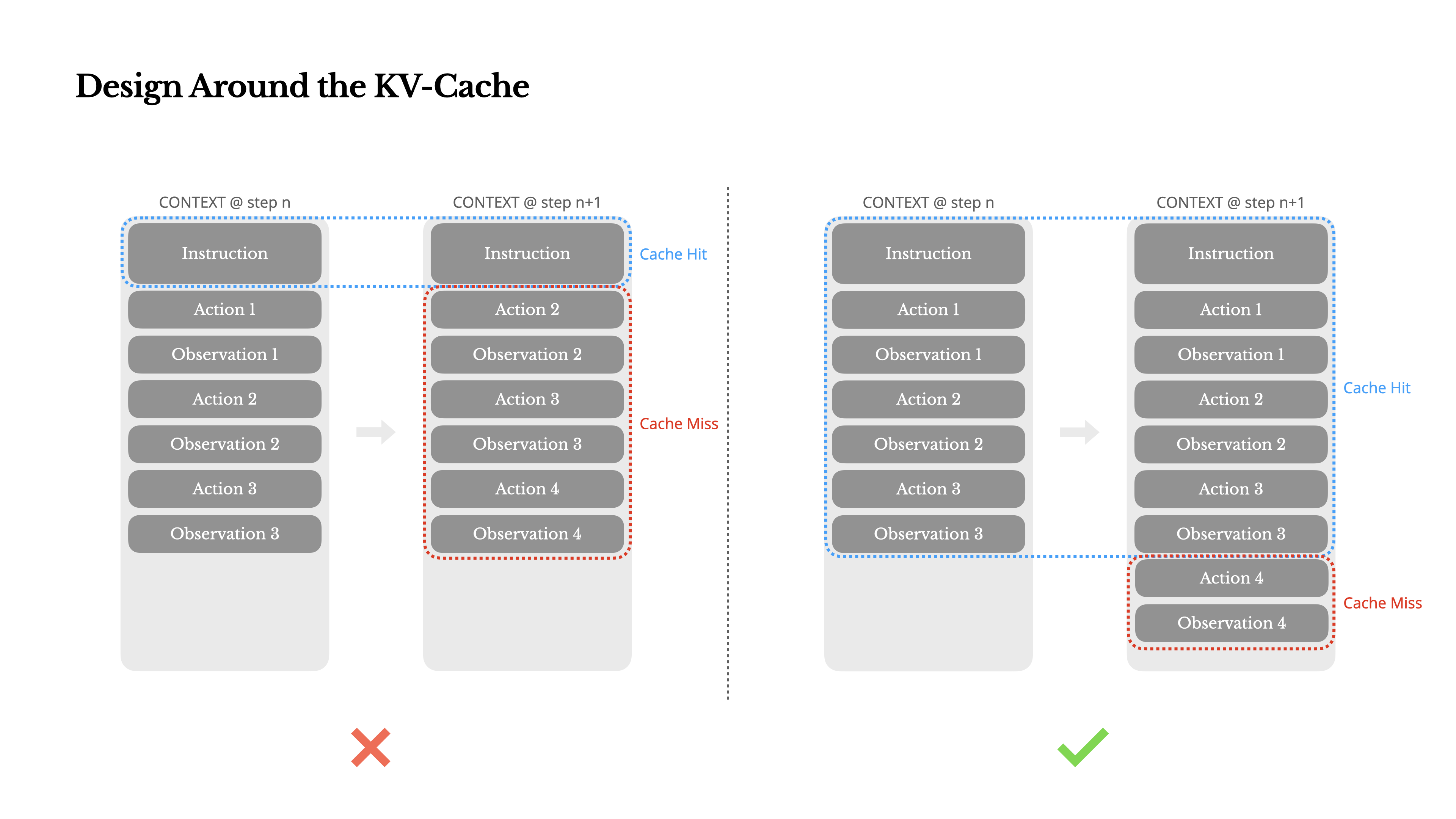
如果只能選擇一個指標,我會認為 KV-緩存命中率是生產階段 AI 智能體最重要的單一指標。它直接影響延遲和成本。為了理解原因,我們來看看一個典型智能體 (arxiv.org/abs/2210.03629) 的運行方式:
智能體接收到用戶輸入后,會通過一系列工具使用來完成任務。在每次迭代中,模型會根據當前上下文從預定義的操作空間中選擇一個動作。該動作隨后在環境中執行(例如,Manus 的虛擬機沙箱)以生成一個觀察結果。動作和觀察結果會被附加到上下文中,形成下一次迭代的輸入。這個循環持續進行,直到任務完成。
可以想象,上下文會隨著每一步的執行而增長,而輸出(通常是結構化的函數調用)則相對較短。這使得智能體中的預填充(prefilling)與解碼(decoding)之間的比例,與聊天機器人相比,呈現出高度傾斜。例如,在 Manus 中,平均輸入與輸出 token 的比例大約是 100:1。
幸運的是,具有相同前綴的上下文可以利用 KV-緩存(medium.com/@joaolages/kv-caching-explained-276520203249),這大大減少了首個 token 的生成時間(TTFT)和推理成本——無論你是使用自托管模型還是調用推理 API。而且我們談論的不是節省一小部分:以 Claude Sonnet 為例,緩存的輸入 token 成本為 0.30 美元/百萬 token,而未緩存的則需要 3 美元/百萬 token——相差 10 倍。
從上下文工程的角度來看,提高 KV-緩存命中率涉及以下幾個關鍵實踐:
-
保持提示詞前綴的穩定性。 由于大語言模型 (LLM) 的自回歸(autoregressive)特性,即使是單個 token 的差異,也可能導致從該 token 開始的緩存失效。一個常見錯誤是在系統提示詞的開頭包含時間戳——特別是精確到秒的時間戳。當然,這可以讓模型告訴你當前時間,但也會極大地降低你的緩存命中率。
-
確保上下文只追加不修改。 避免修改先前的操作或觀察結果。確保你的序列化是確定性的。許多編程語言和庫在序列化 JSON 對象時無法保證鍵的順序穩定,這可能會悄無聲息地破壞緩存。
-
在需要時明確標記緩存斷點。 某些模型提供商或推理框架不支持自動增量前綴緩存,而是需要在上下文中手動插入緩存斷點。在設置這些斷點時,請考慮潛在的緩存過期,并且至少要確保斷點包含系統提示詞的末尾。
此外,如果你使用像 vLLM (github.com/vllm-project/vllm) 這樣的框架來托管模型,請確保前綴/提示詞緩存(docs.vllm.ai/en/stable/design/v1/prefix_caching.html)已啟用,并且你正在使用會話 ID 等技術來確保請求在分布式工作節點之間保持一致地路由。
遮蔽,而非移除
隨著智能體功能變得越來越強大,其操作空間自然也變得更加復雜——簡單來說,就是工具的數量呈爆炸式增長。最近 MCP(modelcontextprotocol.io/introduction)的流行更是火上澆油。如果你允許用戶配置工具,相信我:總會有人將數百個神秘工具插入到你精心策劃的操作空間中。結果就是,模型更有可能選擇錯誤的操作,或者采取低效的路徑。簡而言之,你的“全副武裝”的智能體反而變得更笨了。
一個自然的反應是設計動態動作空間——也許使用類似 RAG (en.wikipedia.org/wiki/Retrieval-augmented_generation) 的方式按需加載工具。我們在 Manus 中也嘗試過。但我們的實驗表明了一個清晰的規則:除非絕對必要,否則避免在迭代過程中動態添加或移除工具。這主要有兩個原因:
-
在大多數大語言模型 (LLM) 中,工具定義在序列化后位于上下文的前部,通常在系統提示詞之前或之后。因此,任何更改都將使后續所有動作和觀察結果的 KV-緩存失效。
-
當之前的動作和觀察結果仍然引用當前上下文中未定義的工具時,模型會感到困惑。如果沒有約束解碼(constrained decoding),這通常會導致模式(schema)違規或幻想出的動作。
為了解決這個問題,同時仍然改進操作選擇,Manus 使用了一種上下文感知的狀態機(state machine)來管理工具的可用性。它不是移除工具,而是在解碼時遮蔽(mask)token 邏輯值,以根據當前上下文阻止(或強制)選擇某些操作。
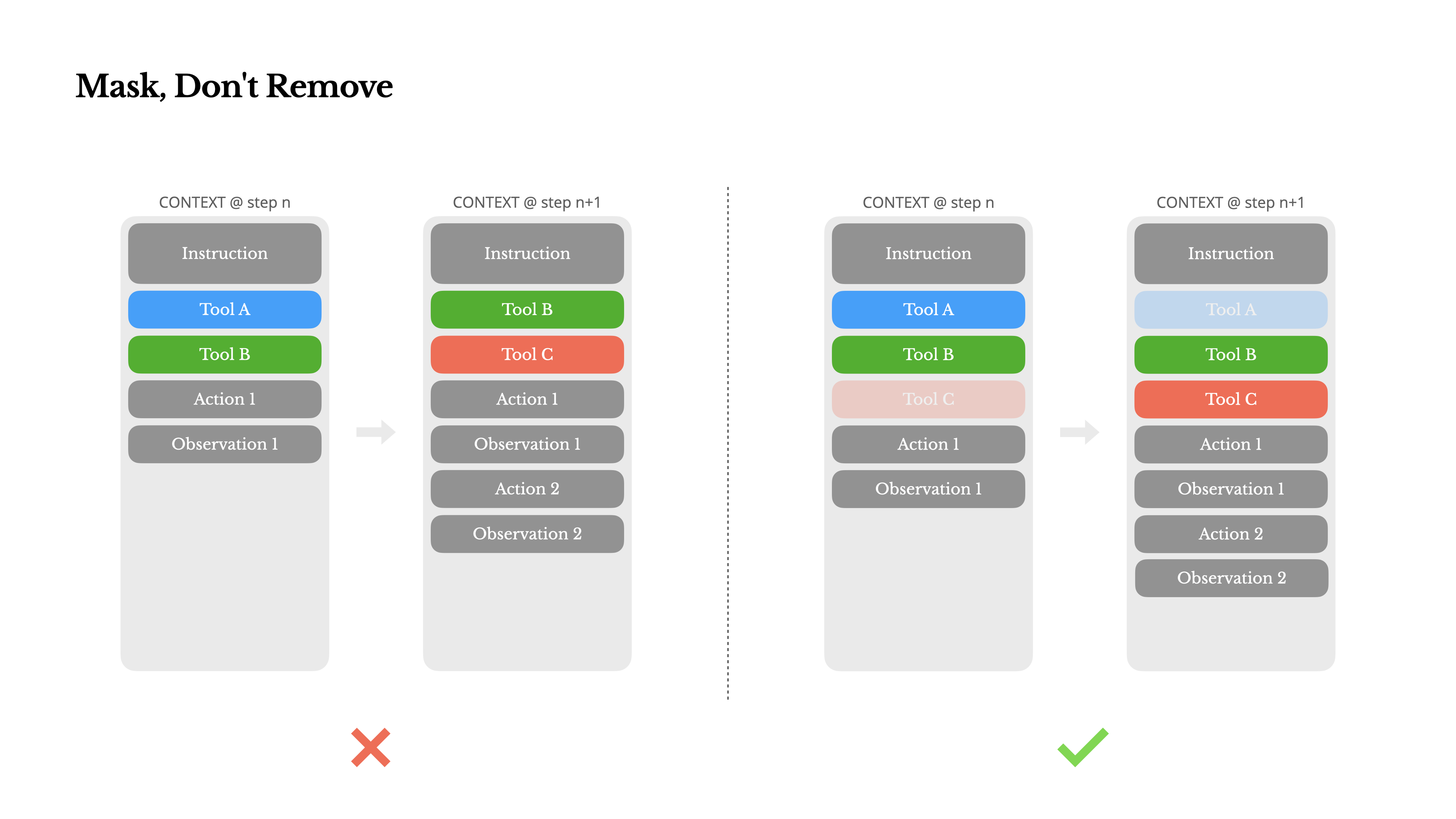
在實踐中,大多數模型提供商和推理框架都支持某種形式的響應預填充,這允許你在不修改工具定義的情況下約束操作空間。函數調用通常有三種模式(我們以 NousResearch 的 Hermes 格式 [github.com/NousResearch/Hermes-Function-Calling] 為例):
-
自動(Auto) – 模型可以選擇是否調用函數。通過僅預填充回復前綴來實現:
<|im_start|>assistant -
必需(Required) – 模型必須調用函數,但選擇不受限制。通過預填充到工具調用 token 來實現:
<|im_start|>assistant<tool_call> -
指定(Specified) –模型必須從特定子集中調用函數。通過預填充到函數名稱的開頭來實現:
<|im_start|>assistant<tool_call>{"name": “browser\_
通過這種方式,我們直接通過遮蔽 token邏輯值來約束操作選擇。例如,當用戶提供新輸入時,Manus 必須立即回復而不是執行操作。我們還特意設計了具有一致前綴的操作名稱——例如,所有與瀏覽器相關的工具都以 browser_ 開頭,命令行工具以 shell_ 開頭。這使我們能夠輕松地在給定狀態下強制智能體只能從特定工具組中選擇,而無需使用有狀態的邏輯值處理器。
這些設計有助于確保 Manus 智能體循環保持穩定——即使在模型驅動的架構下也是如此。
將文件系統用作上下文
如今前沿的大語言模型擁有 128K token 甚至更長的上下文窗口。但在實際的智能體應用場景中,這往往不夠,有時甚至會成為一個負擔。通常有三個痛點:
-
觀察結果可能非常龐大,尤其是當智能體與網頁或 PDF 等非結構化數據交互時,很容易超出上下文限制。
-
模型性能往往在超過一定上下文長度后下降,即使窗口技術上支持更長的上下文。
-
長輸入成本高昂,即使有前綴緩存。你仍然需要為傳輸和預填充每個 token 付費。
為了解決這個問題,許多智能體系統會實施上下文截斷或壓縮策略。但是,過度激進的壓縮不可避免地會導致信息丟失。這是一個根本性問題:智能體天生就需要根據所有先前的狀態來預測下一個動作——而你無法可靠地預測十步之后哪一個觀察結果可能變得至關重要。從邏輯角度來看,任何不可逆的壓縮都帶有風險。
這就是為什么在 Manus 中,我們將文件系統視為終極上下文:它大小無限、本質上是持久的,并且可以直接由智能體本身操作。模型學習按需寫入和讀取文件——將文件系統不僅用作存儲,還用作結構化的外部化內存。
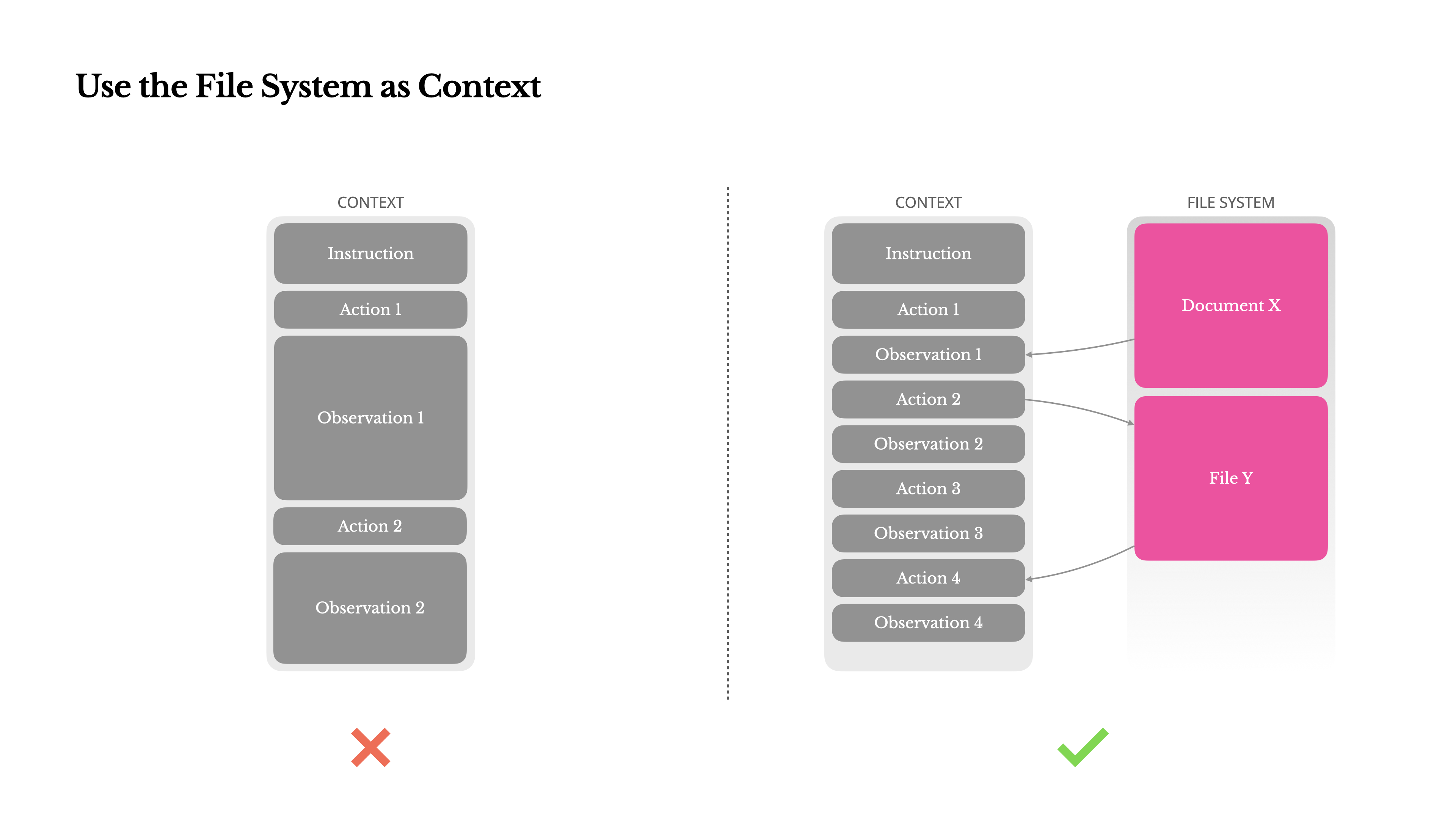
我們的壓縮策略總是被設計為可恢復的。例如,只要保留 URL,網頁內容就可以從上下文中刪除;如果文檔的路徑在沙箱中仍然可用,其內容就可以省略。這使得 Manus 可以在不永久丟失信息的情況下縮短上下文長度。
在開發此功能時,我發現自己一直在思考,如何才能讓狀態空間模型(SSM)在智能體環境中有效工作。與 Transformer 不同,SSM 缺乏完整的注意力機制,并且在處理長距離向后依賴方面存在困難。但如果它們能夠掌握基于文件的內存——將長期狀態外部化而不是將其保存在上下文中——那么它們的速度和效率可能會開辟一類新的智能體。智能體 SSM 可能成為神經圖靈機(Neural Turing Machines)的真正繼承者。
通過復述(Recitation)操控注意力
如果你使用過 Manus,你可能會注意到一個有趣的現象:在處理復雜任務時,它傾向于創建一個 todo.md 文件——并隨著任務的進展逐步更新,勾選已完成的項目。這不僅僅是“可愛”的行為,更是一種刻意為之的“注意力操控”機制。
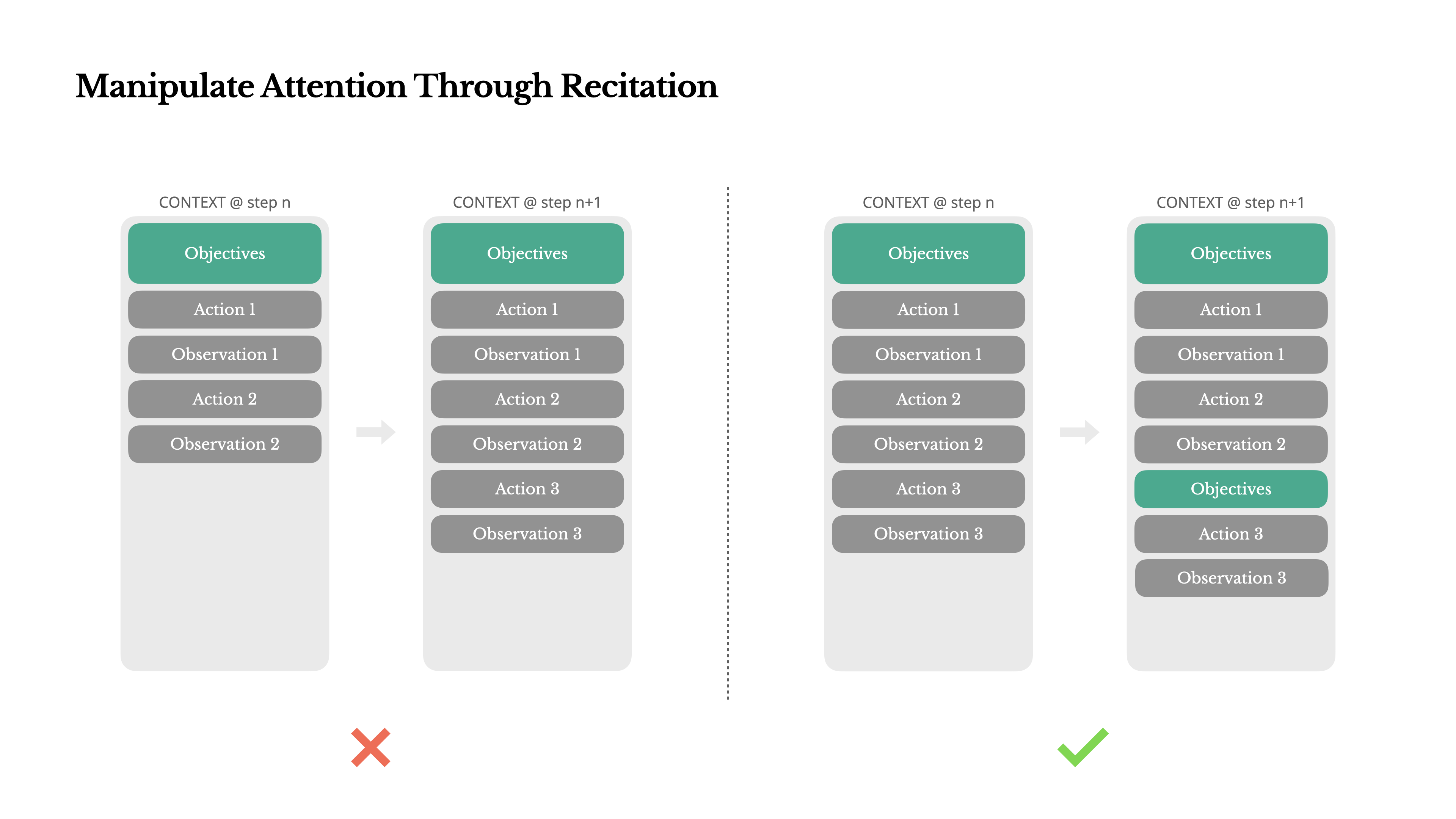
在 Manus 中,一個典型的任務平均需要大約 50 次工具調用。這是一個漫長的循環——由于 Manus 依賴于大語言模型(LLM)進行決策,它很容易偏離主題或忘記早期的目標,尤其是在長上下文或復雜任務中。
通過不斷重寫待辦事項列表,Manus 將其目標重復寫入上下文的末尾。這會將全局計劃推入模型的近期注意力范圍,從而避免“迷失在中間”的問題,并減少目標錯位。實際上,它正在使用自然語言來引導自己的注意力集中在任務目標上——而無需特殊的架構更改。
將“錯誤的數據”保留在上下文中
智能體(Agent)會犯錯。這不是 Bug,而是現實。語言模型會產生幻覺,環境會返回錯誤,外部工具會表現異常,意想不到的極端情況也時常出現。在多步驟任務中,失敗并非例外,而是循環的一部分。
然而,常見的本能是隱藏這些錯誤:清理軌跡、重試操作,或重置模型狀態并將其留給神奇的“溫度(temperature)”參數。這感覺更安全、更容易控制。但這會帶來代價:抹去失敗就等于消除了證據。而沒有證據,模型就無法適應。

根據我們的經驗,改進智能體行為最有效的方法之一出奇地簡單:將錯誤的路徑保留在上下文中。當模型看到失敗的操作以及由此產生的觀察結果或堆棧跟蹤時,它會隱式地更新其內部信念。這使得它不再傾向于類似的操作,從而減少重復相同錯誤的機會。
事實上,我們相信錯誤恢復是真正智能體行為最清楚的指標之一。然而,這在大多數學術研究和公共基準測試中仍然關注不足,這些研究和測試通常側重于理想條件下的任務成功率。
警惕少樣本提示(Few-ShotPrompting)的陷阱
少樣本提示(Few-Shot Prompting)是一種常見的提高大語言模型(LLM)輸出質量的技術。但在智能體系統中,它可能以微妙的方式適得其反。
語言模型是非常優秀的模仿者;它們會模仿上下文中行為模式。如果你的上下文中充滿了相似的過去“動作-觀察”對,模型就會傾向于遵循這種模式,即使它不再是最優的。
這在涉及重復決策或動作的任務中可能很危險。例如,當使用 Manus 協助審核一批 20 份簡歷時,智能體常常會陷入一種固定的節奏——重復執行類似的操作,僅僅因為它在上下文中看到了這些模式。這會導致偏離、過度泛化,有時甚至產生幻覺。
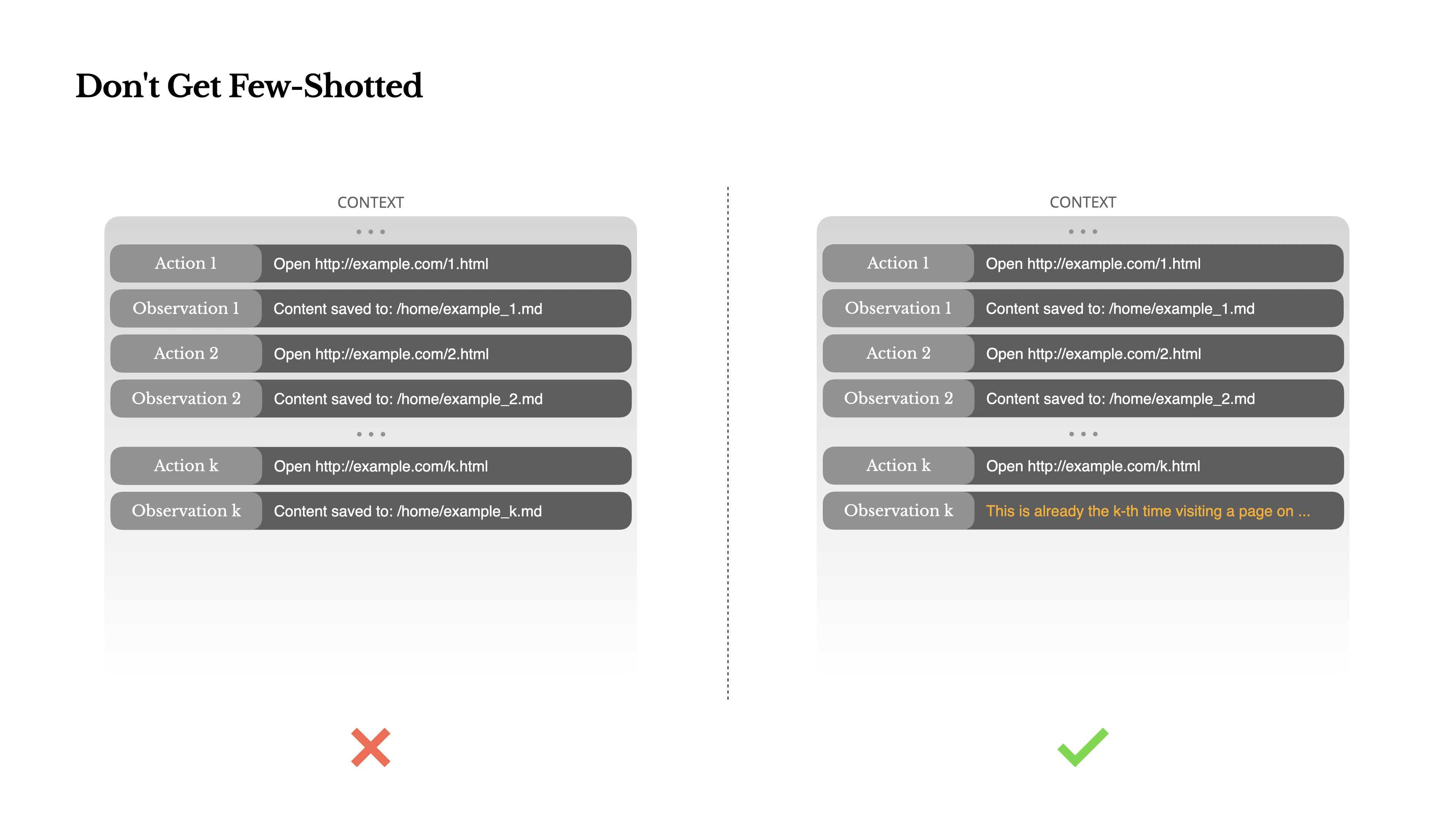
解決方案是增加多樣性。Manus 在動作和觀察中引入少量結構化變量——不同的序列化模板、替換措辭、在順序或格式上添加微小的噪聲。這種受控的隨機性有助于打破模式,并調整模型的注意力。
換句話說,不要讓少樣本提示將你引入困境。你的上下文越統一,你的智能體就越脆弱。
總結
上下文工程仍然是一門新興科學,但對于智能體系統而言,它已經至關重要。模型可能變得越來越強大、越來越快、越來越便宜,但再多的原始能力也無法取代對記憶、環境和反饋的需求。你如何塑造上下文,最終決定了你的智能體如何表現:它運行的速度、恢復的能力以及擴展的程度。
在 Manus,我們通過反復重寫、走入死胡同以及在數百萬用戶真實世界中的測試,汲取了這些經驗教訓。我們在此分享的并非普遍真理,但這些模式對我們來說是行之有效的。如果它們能幫助你避免哪怕一次痛苦的迭代,那么這篇文章就完成了它的使命。
智能體的未來將通過一次又一次地構建上下文來實現。請精心地進行這些工程。










庫、模擬京東app的底部導航欄)








)