
- 作者:Gobinda Chandra Sarker1^{1}1, AKM Azad2^{2}2, Sejuti Rahman1^{1}1, Md Mehedi Hasan1^{1}1
- 單位:1^{1}1達卡大學,2^{2}2伊瑪目穆罕默德·伊本·沙特伊斯蘭大學
- 論文標題:VLM-Nav: Mapless UAV-Navigation Using Monocular Vision Driven by Vision-Language Model
- 論文鏈接:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5231854
- 項目主頁:https://gcsarker.github.io/vlmnav/
- 代碼鏈接:https://github.com/gcsarker/vlm_nav
主要貢獻
- 提出了無人機自主導航系統 VLM-Nav ,該系統僅依賴單目視覺輸入,通過深度估計和視覺語言模型(VLM)實現高效避障和路徑規劃。
- 該系統無需預訓練地圖或外部人類指令,具有更好的泛化能力,能夠在未見過的環境中自主導航。
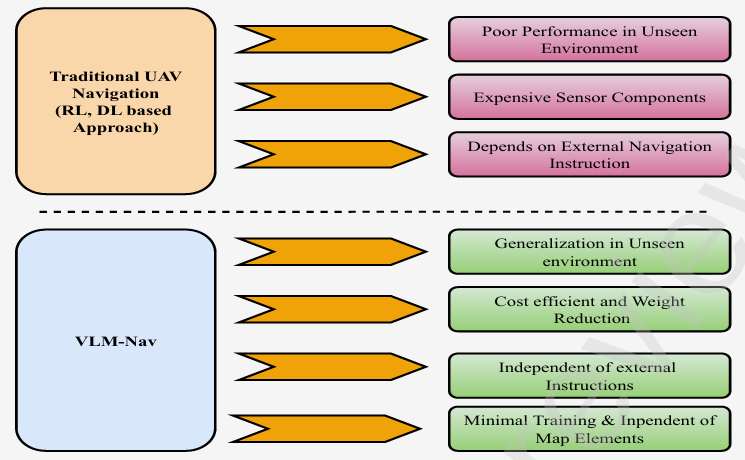
- 與傳統的基于強化學習(RL)或深度學習(DL)的無人機導航方法相比,VLM-Nav在未見環境中表現出更好的泛化能力,且對訓練數據的需求更少。
- 通過在 AirSim 模擬器中進行的實驗驗證了系統的有效性,VLM-Nav 在復雜環境中實現了接近完美的任務完成率。
研究背景
- 無人機(UAV)在包裹遞送、農業、監視和搜索救援等領域具有巨大的應用潛力,因此對安全、成本效益高且智能的導航系統的需求日益增長。
- 傳統的無人機導航方法主要依賴于激光雷達(LiDAR)等昂貴傳感器,且需要大量的訓練數據和復雜的路徑規劃算法。這些方法在動態或未知環境中表現不佳,且成本較高。
- 近年來,視覺語言模型(VLM)和大型語言模型(LLM)在圖像識別、目標檢測和語義分割等任務中取得了顯著進展,為無人機導航提供了新的思路。
導航任務
- 目標:VLM-Nav 系統的目標是引導多旋翼無人機(UAV)從初始位置 (xstart,ystart)(x_{\text{start}}, y_{\text{start}})(xstart?,ystart?) 自主飛行到目標位置 (xgoal,ygoal)(x_{\text{goal}}, y_{\text{goal}})(xgoal?,ygoal?)。
- 飛行條件:無人機以恒定速度 vvv 飛行,并保持初始高度 hhh,僅在需要避障時調整高度。
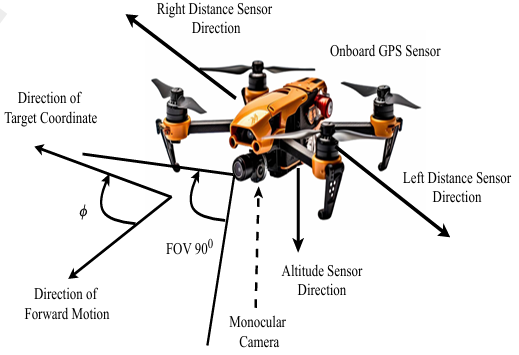
觀測空間
- 觀測空間定義:無人機需要從環境中獲取狀態信息以安全導航,即確定每個時間步應采取的動作。觀測空間 OOO 可以通過以下公式表示:
O={Irgb,Ddepth,dleft,dright,?} O = \{I_{\text{rgb}}, D_{\text{depth}}, d_{\text{left}}, d_{\text{right}}, \phi\} O={Irgb?,Ddepth?,dleft?,dright?,?}
其中:- IrgbI_{\text{rgb}}Irgb?:通過單目相機捕獲的 RGB 圖像。
- DdepthD_{\text{depth}}Ddepth?:通過深度估計模型從 RGB 圖像生成的深度圖。
- dleftd_{\text{left}}dleft? 和 drightd_{\text{right}}dright?:分別表示左側和右側距離傳感器測量的距離。
- ?\phi?:無人機前進方向與目標位置之間的夾角。
動作空間
- 動作定義:無人機在每個時間步觀察周圍環境后生成低級控制命令。動作空間包含以下五個離散動作:
- Forward:向前飛行 1 秒。
- Yaw Left:逆時針旋轉 25°。
- Yaw Right:順時針旋轉 25°。
- Up:向上飛行 1 秒。
- Down:向下飛行 1 秒。
模擬環境
- 環境選擇:為了測試和優化導航算法,研究者使用了 AirSim 模擬器,它提供了逼真的 3D 環境,允許在安全、可控的條件下進行實驗。

- 具體環境:
- 環境 A:簡單的單障礙環境,尺寸為 30 m × 30 m,障礙物的寬度和高度在每次導航軌跡中隨機縮放 0.5 到 5 倍。
- 環境 B:由 AirSim 提供的 Blocks 環境,包含多個不同形狀的障礙物,尺寸約為 220 m × 100 m。
- 環境 C:使用 Unreal Engine 市場中的 Downtown West 包創建的自定義環境,包含城市環境中的各種物體,如建筑、食品車、長椅、巖石、海報等。
研究方法
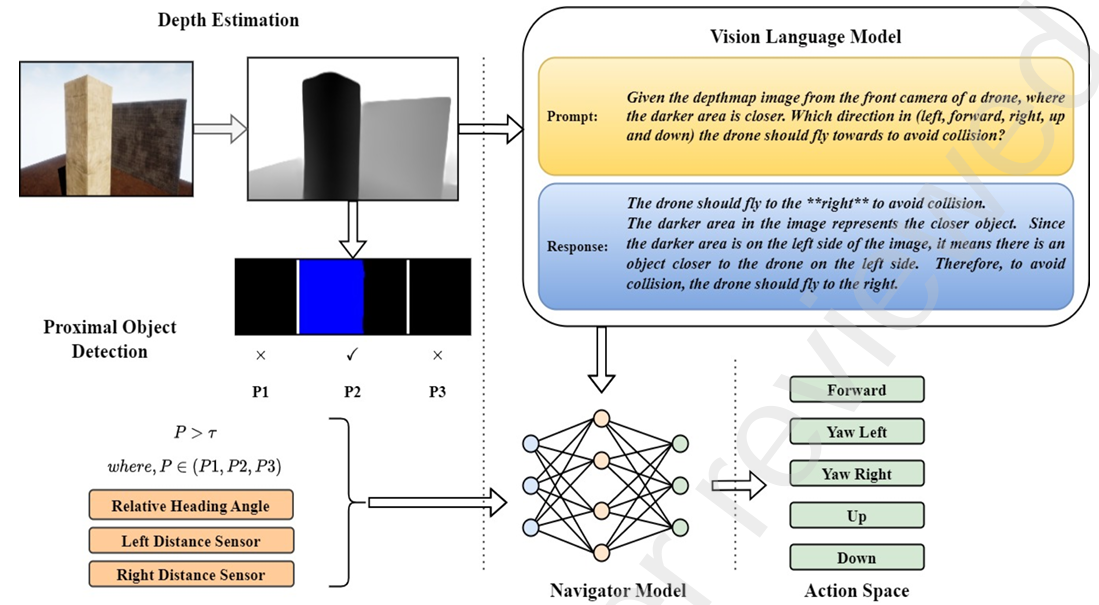
深度估計
- 背景:由于單目相機無法直接感知深度信息,因此需要使用深度估計模型將RGB圖像轉換為深度圖。
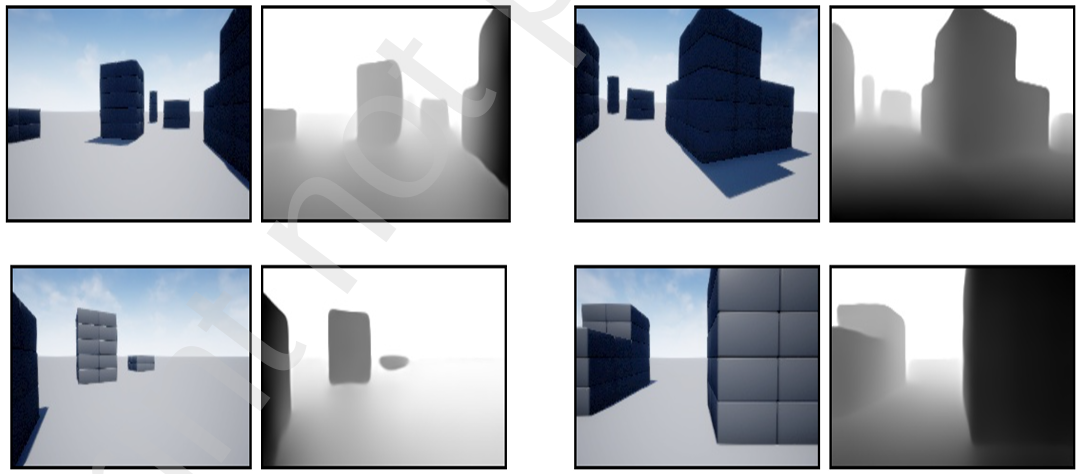
- 方法:研究中使用了 DepthAnything V2 模型,這是一個預訓練的零樣本深度估計模型,能夠處理各種場景并生成高質量的深度圖。
- 模型架構:DepthAnything V2 采用編碼器-解碼器結構,編碼器使用 Vision Transformer(ViT-L),解碼器使用 DPT。
- 訓練方法:該模型使用了6200萬張自動標注的無標簽圖像進行訓練,并通過偽標簽技術提升模型的泛化能力。
- 輸出處理:模型輸出的深度圖被縮放到 (0-255) 范圍內,并轉換為單通道圖像。為了適應VLM的輸入需求,深度圖被反轉,使得較近的物體具有較大的像素值。
- 性能優勢:DepthAnything V2 在深度估計的準確性和泛化能力上優于其他模型,如 MiDaS,且計算效率更高。
視覺語言模型
- 背景:VLM在圖像識別、目標檢測和語義分割等任務中表現出色,研究中利用VLM的視覺問答(VQA)能力來指導無人機避障。

- 模型選擇:研究中使用了兩種VLM模型:Gemini-1.5-flash 和 GPT-4o。
- Gemini-1.5-flash:由Google DeepMind開發,基于Transformer Decoder架構,能夠處理多模態數據(如圖像、文本和視頻),具備強大的推理和規劃能力。
- GPT-4o:由OpenAI開發,是GPT架構的一個變體,具有更大的上下文窗口和更快的處理速度,適用于圖像、文本和視頻任務。
- 工作流程:
- 將深度圖和預設的提示(prompt)發送給VLM模型。
- 提示內容是詢問VLM無人機應采取的方向以避開障礙物。
- VLM模型返回建議的方向,并附帶詳細的解釋。
- 通過關鍵詞搜索從VLM的輸出文本中提取方向(如左、右或任意方向)。
近物檢測
- 背景:為了評估前方是否存在障礙物,需要對深度圖進行分析。
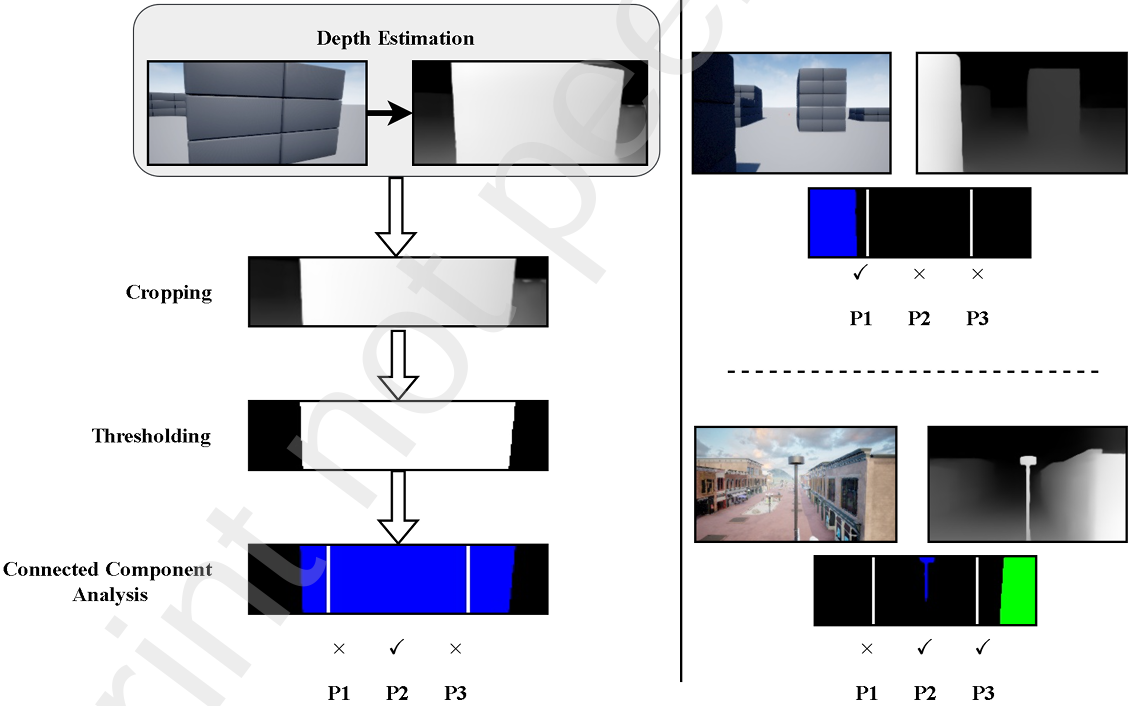
- 方法:
- 裁剪深度圖:將深度圖裁剪為 i×ji \times ji×j 的形狀,以排除地面并專注于前方障礙物。
- 二值化處理:使用閾值 σd\sigma_dσd? 對深度圖進行二值化處理,忽略超出一定距離的障礙物。
- 連通組件分析:使用“spaghetti”算法進行連通組件分析,識別深度圖中的障礙物。
- 區域劃分:將深度圖劃分為三個區域(P1、P2、P3),用于判斷障礙物的位置和方向。
- 作用:
- P1和P3區域幫助無人機判斷是否安全轉彎。
- P2區域用于檢測前方是否有障礙物,如果檢測到障礙物,則向VLM請求反饋。
導航模塊
- 背景:導航模塊是一個全連接網絡(FCN),用于綜合VLM的反饋、距離傳感器讀數、航向角等信息,生成最終的導航動作。
- 輸入參數:
- POD模塊的輸出(三個區域的障礙物檢測結果)。
- 左側和右側距離傳感器的讀數。
- 航向角 ?\phi?。
- VLM模塊的反饋(建議的動作方向)。
- 訓練方法:
- 在簡單的環境A中,由人類操作員手動飛行無人機,記錄飛行軌跡。
- 收集10,000步的飛行數據,包括輸入參數和人類操作員的動作。
- 使用這些數據訓練導航模塊,使其能夠模仿人類的飛行決策。
結果與討論
實驗設置
- 模擬環境:所有實驗均在 AirSim 模擬器中進行,該模擬器與 Unreal Engine 4.27 集成,提供了逼真的 3D 環境。
- 硬件配置:實驗使用了配備 Nvidia GeForce MX550 GPU 和 16 GB 內存的硬件平臺,確保了 3D 環境的流暢渲染和實時數據處理。
- 環境配置:
- 環境 A:簡單的單障礙環境,尺寸為 30 m × 30 m,障礙物的寬度和高度在每次導航軌跡中隨機縮放 0.5 到 5 倍。
- 環境 B:由 AirSim 提供的 Blocks 環境,包含多個不同形狀的障礙物,尺寸約為 220 m × 100 m。
- 環境 C:使用 Unreal Engine 市場中的 Downtown West 包創建的自定義環境,包含城市環境中的各種物體,如建筑、食品車、長椅、巖石、海報等。
定量分析
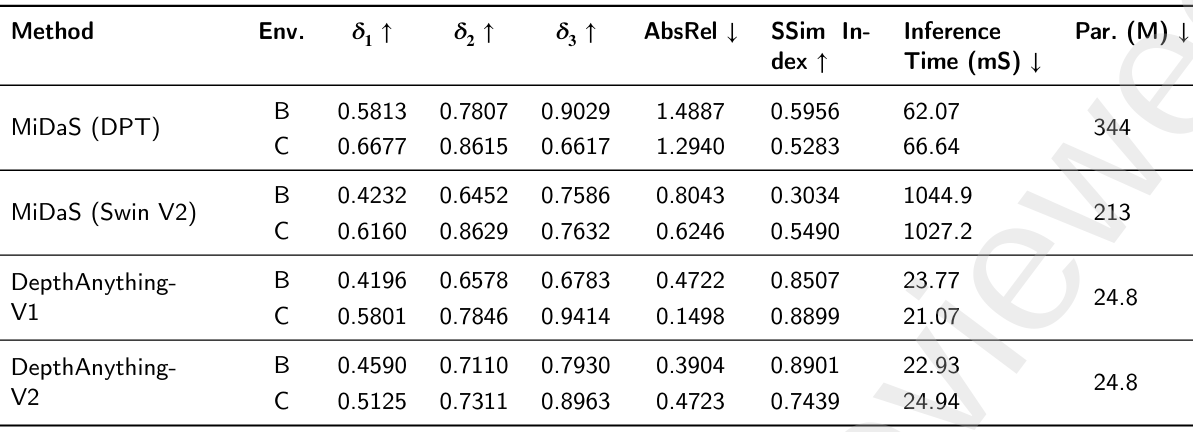
深度估計算法比較
- 方法:研究中比較了四種深度估計方法:MiDaS (DPT)、MiDaS (Swin V2)、DepthAnything V1 和 DepthAnything V2。
- 評估指標:
- Delta (𝛿):計算深度預測值在一定閾值內的比例,通常使用多個閾值(如 𝛿1 < 1.25, 𝛿2 < 1.252, 𝛿3 < 1.253)。
- 絕對相對誤差:計算預測深度值與真實深度值之間的絕對誤差,歸一化到真實深度值。
- 結構相似性指數:衡量預測深度圖與真實深度圖在結構、亮度和對比度上的相似性。
- 推理時間:計算從單張場景圖像生成深度圖所需的時間。
- 參數數量:模型訓練權重的數量,單位為百萬。
- 結果:
- DepthAnything V2 在所有指標上均優于其他方法,具有更高的 Delta 值、更低的 AbsRel 值和更高的 SSIM 值,同時計算效率更高。
- DepthAnything V1 和 DepthAnything V2 的性能接近,但 V2 在環境 B 和 C 中表現略好。
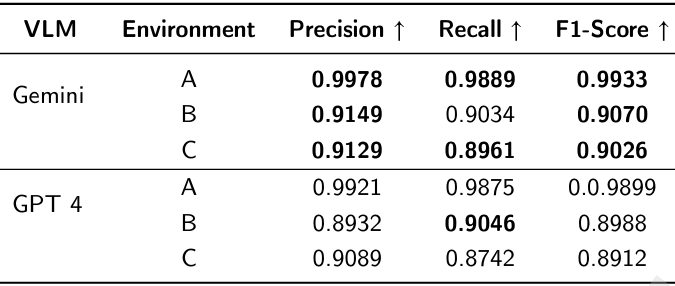
導航模塊性能
- 評估指標:
- 精確率:正確預測的動作數量與總預測數量的比值。
- 召回率:正確預測的動作數量與應預測為正確的總動作數量的比值。
- F1分數:精確率和召回率的調和平均值。
- 結果:
- Gemini 和 GPT-4o 模型在未見環境(環境 B 和 C)中均表現出高精度和高召回率,F1 分數接近 90%。
- Gemini 模型在導航新環境時表現略優于 GPT-4o。
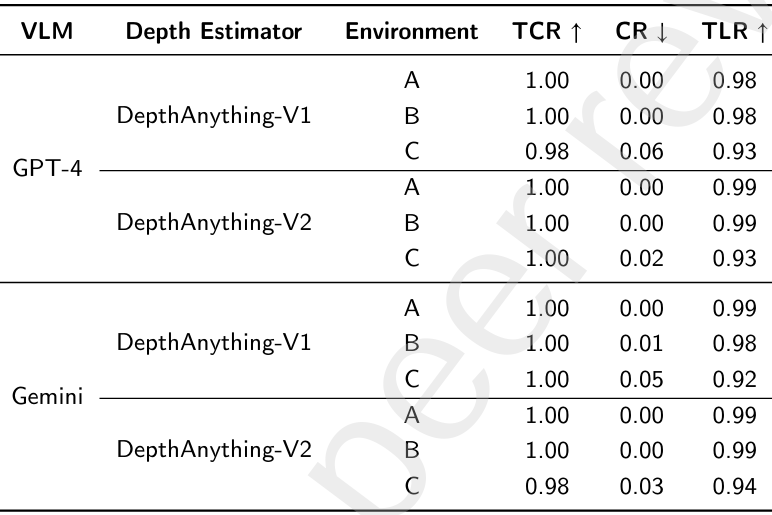
整體導航性能
- 評估指標:
- 任務完成率:無人機成功到達目標位置(距離目標小于 3 米)的軌跡百分比。
- 碰撞率:無人機與障礙物碰撞的次數占飛行總距離的百分比。
- 軌跡長度比:無人機飛行路徑長度與人類操作路徑長度的比值。
- 結果:
- VLM-Nav 在所有測試環境中均實現了接近完美的任務完成率(0.98),碰撞率極低,軌跡長度比接近 1。
- DepthAnything V2 的碰撞率低于 DepthAnything V1,表明其深度估計更準確。
定性分析
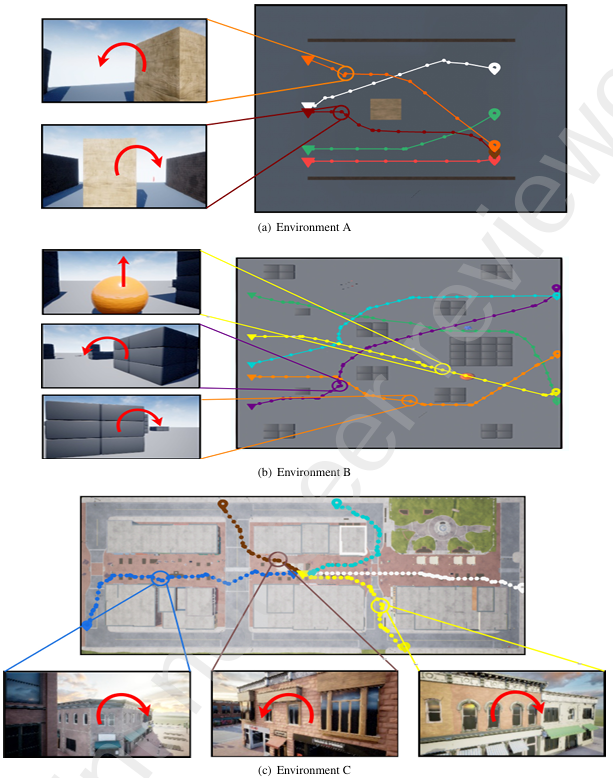
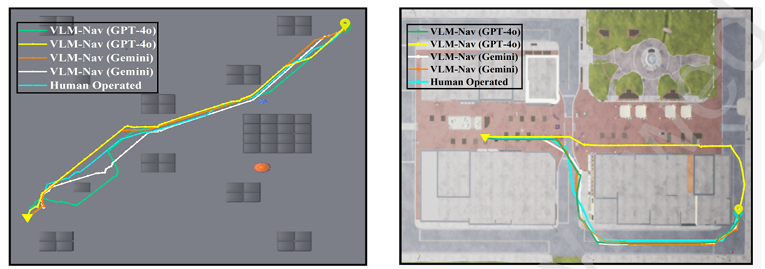
- 飛行路徑可視化:
- 環境 A、B 和 C:展示了在三個不同環境中生成的飛行路徑,無人機成功避開了所有障礙物并到達目標位置。
- 路徑比較:將 VLM-Nav 生成的飛行路徑與人類操作的飛行路徑進行比較,結果表明 VLM-Nav 生成的路徑與人類操作路徑非常接近。
- VLM 輸出的一致性:
- 復雜指令問題:當給 VLM 提供復雜指令時,其輸出可能不一致。研究中通過使用更簡單的提示來減少這種不一致性,確保更可靠的輸出。
消融研究
- 深度估計的重要性:深度估計模塊幫助 VLM 更好地理解場景中的障礙物距離,從而選擇最優動作。
- 近物檢測模塊的局限性:僅依賴 POD 模塊進行導航在某些情況下是不夠的,VLM 的全局分析能力在復雜場景中至關重要。
- VLM 輸出的一致性問題:復雜的指令可能導致 VLM 輸出不一致,簡單的提示和導航模塊的結合可以提高系統的可靠性和一致性。
結論與未來工作
- 結論:
- VLM-Nav 通過結合深度估計和視覺語言模型,實現了在復雜未知環境中的高效自主導航。
- 該方法具有成本低、泛化能力強、對訓練數據需求少等優點。
- 未來工作:
- 探索開發專門針對無人機導航的 VLM,使其能夠直接處理 RGB 圖像而無需深度估計。
- 研究動態障礙物的避障能力,例如通過時空圖神經網絡等方法預測障礙物的運動模式。
- 在實際場景中進行測試,驗證系統的魯棒性和實時性。

)
網絡層 IPv4、CIDR(使用子網掩碼進行網絡劃分)、NAT在私網劃分中的應用)


 視頻教程 - 基于wordcloud庫實現詞云圖)
)













