目錄
1.深拷貝和淺拷貝
1.1.區別
定義
定義
1.2.實現深拷貝的方式
2.泛型
2.1.定義
2.2.作用
?3.對象
3.1.創建對象的方式
3.2.對象回收
3.3. 獲取私有成員
4.反射
4.1.定義
4.2.特性
4.3.原理
5.異常
5.1.異常的種類
5.2.處理異常的方法
6.Object
6.1.等于與equals()區別
6.2.hashcode()與equals()關系
6.3String、StringBuffer、StringBuilder的區別
?7.序列化
7.1.JVM之間的傳遞對象
?8.設計模式
9.I/O
9.1.實現網絡IO高并發編程
9.2.BIO、NIO、AIO區別
1.深拷貝和淺拷貝
1.1.區別
例子:你需要將一個對象拷貝到一個新的對象里(類型相同),你選擇淺拷貝,那么它就是將對原先的對象原封不動的拷貝過去(引用類型共享內存地址),而深拷貝就是基本類型復制,引用類型是先創建一個新的對象再將值復制過來
區別:引用類型拷貝區別:淺拷貝將地址拷過來(地址復用),深拷貝將值拷過來(創建一個新的對象,地址不復用)
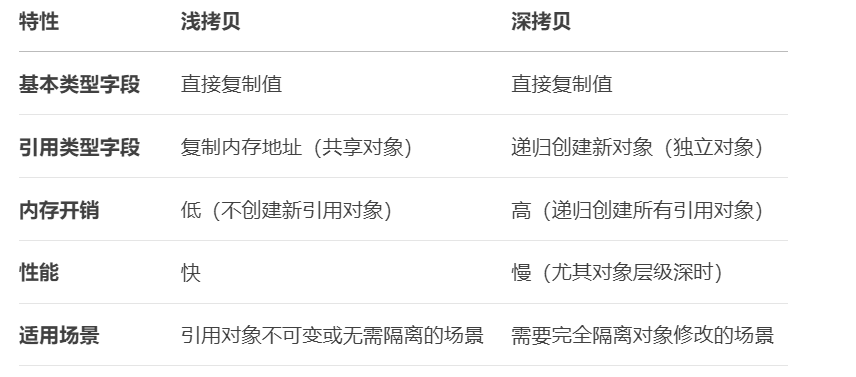
淺拷貝
定義
-
基本類型字段:直接復制值。
-
引用類型字段:僅復制內存地址(新舊對象共享同一引用對象)。
-
特點:修改原對象或拷貝對象中的引用字段時,另一方會同步變化。
深拷貝
定義
-
基本類型字段:直接復制值。
-
引用類型字段:遞歸創建新對象并復制所有層級數據(新舊對象引用獨立對象)。
-
特點:修改原對象或拷貝對象中的引用字段時,另一方不受影響。
1.2.實現深拷貝的方式
- 實現?Cloneable 接口并重寫 clone() 方法
class Person implements Cloneable {String name;Address address;@Overridepublic Person clone() {try {Person cloned = (Person) super.clone();// 深拷貝:遞歸克隆引用字段cloned.address = this.address.clone();return cloned;} catch (CloneNotSupportedException e) {throw new AssertionError(); // 不會發生}}
}class Address implements Cloneable {String city;@Overridepublic Address clone() {try {return (Address) super.clone();} catch (CloneNotSupportedException e) {throw new AssertionError();}}
}class Person implements Cloneable {String name;Address address;@Overridepublic Person clone() {try {Person cloned = (Person) super.clone();// 深拷貝:遞歸克隆引用字段cloned.address = this.address.clone();return cloned;} catch (CloneNotSupportedException e) {throw new AssertionError(); // 不會發生}}
}class Address implements Cloneable {String city;@Overridepublic Address clone() {try {return (Address) super.clone();} catch (CloneNotSupportedException e) {throw new AssertionError();}}
}- 使用序列化和反序列化
import java.io.*;class Person implements Serializable {String name;Address address; // Address 也需實現 Serializable
}public class DeepCopyUtils {public static <T extends Serializable> T deepCopy(T obj) {try (ByteArrayOutputStream bos = new ByteArrayOutputStream();ObjectOutputStream oos = new ObjectOutputStream(bos)) {oos.writeObject(obj);try (ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());ObjectInputStream ois = new ObjectInputStream(bis)) {return (T) ois.readObject();}} catch (IOException | ClassNotFoundException e) {throw new RuntimeException("Deep copy failed", e);}}
}// 使用示例
Person original = new Person();
Person deepCopy = DeepCopyUtils.deepCopy(original);- 手動遞歸復制
class Person {String name;Address address;public Person deepCopy() {Person copy = new Person();copy.name = this.name;copy.address = this.address.deepCopy(); // 手動遞歸復制return copy;}
}class Address {String city;public Address deepCopy() {Address copy = new Address();copy.city = this.city;return copy;}
}// 使用示例
Person original = new Person();
Person deepCopy = original.deepCopy();對比總結
| 方法 | 性能 | 代碼復雜度 | 適用場景 | 限制條件 |
|---|---|---|---|---|
| Cloneable 接口 | 高 | 中等 | 簡單對象、可控的深拷貝 | 需遞歸處理引用字段 |
| 序列化/反序列化 | 低 | 低 | 復雜對象圖、完全深拷貝 | 必須實現?Serializable |
| 手動遞歸復制 | 高 | 高 | 精細控制拷貝邏輯、排除特定字段 | 代碼維護成本高 |
2.泛型
2.1.定義
泛型是java中的一個特性,它允許在定義類和方法和接口時只需要指定一個或者多個類型參數(泛型符號)就行,在使用時再指定具體的類型
2.2.作用
當多個類需要共享相同代碼邏輯時,可以通過定義泛型來實現。泛型允許在使用時指定具體類型,使不同類都能復用相同的代碼邏輯。
--------
由于泛型在定義時使用類型參數而非具體類型,它可以接收任何類型參數而無需強制類型轉換,從而避免了類型安全問題
?3.對象
3.1.創建對象的方式
- 通過new關鍵字創建對象
- 通過克隆創建對象
- 通過反射創建對象
- 通過反序列化創建對象
3.2.對象回收
對象是由垃圾回收器回收,垃圾回收器會在程序運行時自動運行,周期性去檢查對象是否被引用,沒有就直接回收,釋放內存
垃圾回收器實現的主要的機制:
----
1.引用計數法:它會根據該對象的引用計數,如果為0,代表沒有被引用直接回收釋放
---
2.可達性分析算法:它會從根對象出發,根據根對象的屬性和方法的引用鏈來判斷,如果這個對象沒有一個引用鏈那么代表沒有被引用,直接回收釋放內存
---
3.終結器:在對象里面你可以重寫finalize()方法,如果重寫了該方法,那么垃圾回收器在回收該對象之前會先執行該方法,但是會出現一個問題,你清楚你的這個對象什么時候被回收嗎?不確定時間,那么該方法執行的時間也不確定,因此會出現一些可能會出現的問題(?可能導致性能問題、死鎖和資源爭用),就比如性能問題,如果你在finalize()方法中釋放了某些資源,但是由于不確定時間釋放,就會導致一些性能問題(可能都不會釋放)
3.3. 獲取私有成員
由于定義的私有成員,那么只能該類內部訪問,如果外部需要訪問
- 你對外提供方法來訪問(比getter方法)
- 你通過反射直接獲取該成員
4.反射
4.1.定義
反射就是可以獲取任何一個類里面的全部信息(父類,實現的接口都可以),并且反射可以調用任何一個類里面的成員
4.2.特性
| 運行時類信息全知 | 只要程序運行,那么通過反射就可以知道類里面全部信息 |
| 動態的創建對象 | 由于你知道信息,那么你通過反射也可以創建對象 |
| 動態的調用方法 | 也是因為知道全部信息,因此可以調用 |
| 訪問和修改字段值 | 一樣 |
4.3.原理
編譯器會將源代碼先編譯成字節碼,然后JVM根據字節碼翻譯成機器碼,而反射就是通過字節碼從而知道類的全部信息
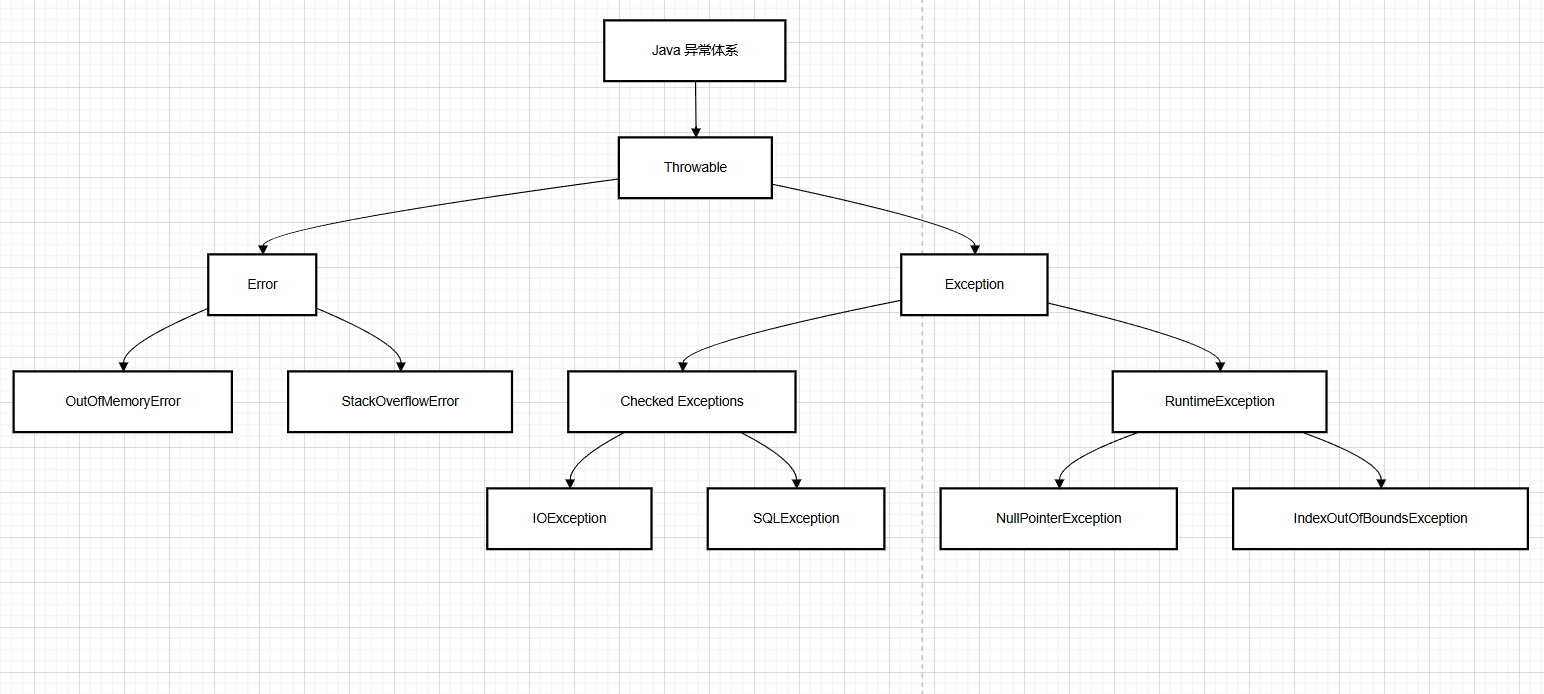
5.異常
5.1.異常的種類
5.2.處理異常的方法
-
使用try-catch-fianlly(包裹可能會出現異常的代碼)
-
手動拋出異常(throw)
-
方法或類拋出異常(throws)
如果你使用try-catch-fianlly那么你需要注意:
當 try 代碼塊中的語句發生異常時,后續代碼將不會執行,異常會立即傳遞給 catch 塊。如果 catch 塊未能捕獲對應類型的異常,該異常會繼續向上層拋出(例如方法b拋出的異常可被調用它的方法a捕獲)。
----
catch接收到異常那么就會執行catch里面的對應代碼
----
如果定義了fianlly,不管有沒有異常,fianlly都會執行(常用于釋放鎖)
----
執行順序規則(fianlly,如果return在前,fianlly在后)
return?語句計算返回值:先將返回值存儲到臨時變量中。執行?
finally?塊:無論是否有?return?或異常,finally?都會執行。方法返回臨時變量中的值:如果?
finally?中沒有新的?return,則返回最初的值;如果?finally?中有?return,則會覆蓋原值。
6.Object
6.1.等于與equals()區別
等于就是:比較基本類型比值,比較引用類型比地址(比表面的)
而equals():你如果重寫了該方法,那么比較引用類型時比較里面的屬性值,沒有重寫與等于一樣
6.2.hashcode()與equals()關系
前提:你如果要重寫這其中的一個方法,那么另外一個也需要重寫(約定)
一致性:當equals()比較對象相等時,那么hashcode也一定相等(本質就是根據內部值計算出哈希值,而內部值都相等了,你的哈希值肯定相等)
不一致性:當hasjcode相等時,equals()不一定相等,因為你不同的對象計算出來的哈希值可能相同(哈希沖突)
6.3String、StringBuffer、StringBuilder的區別
1.可變性
-----
解釋:在Java中,String對象一旦創建就不可修改,具有不可變性。每次對String進行修改時,實際上都會創建一個新的String對象(數組也有類似特性)。
而StringBuffer、StringBuilder可變
2.線程安全性
---
解釋:由于String不可變,因此天然的線程安全,?而StringBuilder是線程不安全的(單線程來訪問最好),StringBuffer是線程安全的,其內部方法(在StringBuilder方法上)實現了悲觀鎖
synchronized
3.性能
----
解釋:由于String每次修改就需要創建一個新的對象,因此性能低,?StringBuffer由于內部方法實現了鎖(而鎖本身就會影響性能),因此性能一般,StringBuilder性能最好
?7.序列化
7.1.JVM之間的傳遞對象
1.使用序列化和反序列化
---
解釋:你先通過序列化將對象序列化成字節流存入文件中,再將文件傳輸,接收到文件后再將文件反序列化成對象即可
2.使用消息隊列
---
解釋:使用消息隊列(?RabbitMQ、Kafka)來傳遞消息,另一邊接收消息即可?
3.使用遠程方法(RPC)
4.使用數據庫(MYSQL)或緩存(Redis)
---
解釋:比如將對象之間存入數據庫或緩存中,直接訪問數據即可?
?8.設計模式
代理模式:
- 目的:控制對象的訪問或增加一些新的方法
- 內容:抽象主題,真實主題,代理三個角色
適配器模式:
- 目的:轉換接口,是不兼容的類可以并行執行
- 內容:目標接口,適配器,被適配對象
9.I/O
9.1.實現網絡IO高并發編程
使用NIO,NIO是同步非阻塞執行的,NIO 是基于I/O多路復用實現的,它可以只用一個線程處理多個客戶端I/O,如果你需要同時管理成千上萬的連接,但是每個連接只發送少量數據,例如一個聊天服務器,用NIO實現會更好一些。
9.2.BIO、NIO、AIO區別
| BIO | 同步阻塞式執行 |
| NIO | 同步非阻塞執行 |
| AIO | 異步非阻塞執行 |
解釋:
- 同步阻塞式執行:就是說你發完一個消息后,你會一直等待別人回你消息,并且在等待的過程中不會干任何事情
- 同步非阻塞執行:就是說你發完一個消息后,你會一直等待別人回你消息,但是在等待的過程中你可以做一些自己的事情
- 異步非阻塞執行:就是說你發完一個消息后,你不會等待別人回你消息




對沖基金模擬系統:模范巴菲特、凱西·伍德的投資策略)



![[Java惡補day13] 53. 最大子數組和](http://pic.xiahunao.cn/[Java惡補day13] 53. 最大子數組和)




你好,三角形(Hello Triangle))





)