一.Numpy(Numerical Python)
Numpy庫是Python用于科學計算的基礎包,也是大量Python數學和科學計算包的基礎。不少數據處理和分析包都是在Numpy的基礎上開發的,如后面介紹的Pandas包。
Numpy的核心基礎是ndarray(N-dimensional array ,n維數組),即由數據類型相同的元素組成N維數組。
1.創建數組
1.利用array函數創建
import numpy as np
d1 = [1,2,3,4,0.1,7]
d2 = (1,3,5,7,9)
d3 = [(1,2),(3,4),[5,6]]
n1 = np.array(d1)
n2 = np.array(d2)
n3 = np.array(d3)
print(n1)
print(n2)
print(n3)輸出:
[1. ?2. ?3. ?4. ?0.1 7. ]
[1 3 5 7 9]
[[1 2]
?[3 4]
?[5 6]]
print(n1.dtype)
print(n2.dtype)
print(n3.dtype)輸出:
float64
int64
int64
可以看出數組n1中的數據類型是浮點數,這是因為numpy會進行類型強制轉換,轉換規則為:str > float > int? ? ?只要原始數據中有一個類型“較高級”的數據,由這個原始數據創建的數組里面的元素就會開始強制轉換類型
float64是一種浮點數類型,表示雙精度浮點數,它占用64位(8字節)的存儲空間
int64是一種整數類型,表示64位有符號整數。用于存儲整數,能夠表示的整數的范圍為負2的63次方到正2的63次方減一,適用于需要處理較大范圍的整數場景
還有其他的類型可以上網查(感嘆現在的artifical intelligence)
另外有一個類型值得注意:object類型,稱為對象類型,可以存儲任何Python對象
2.利用內置函數創建數組
import numpy as np
z1 = np.zeros((3,4))
z2 = np.ones((2,3))
z3 = np.arange(1,10)
z4 = np.arange(1,10,2)
z5 = np.arange(10)輸出:(省略了print)
[[0. 0. 0. 0.]
?[0. 0. 0. 0.]
?[0. 0. 0. 0.]]
[[1. 1. 1.]
?[1. 1. 1.]]
[1 2 3 4 5 6 7 8 9]
[1 3 5 7 9]
[0 1 2 3 4 5 6 7 8 9]
2.數組的屬性
1. ndarray.shape
表示數組的維度大小(形狀),返回一個元組,其中每一個元素對應了一個維度的大小
import numpy as nparr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr.shape) 輸出:(2,3)
2.ndarray.ndim
用于獲取數組的維度(dimension)
3.ndarray.size
表示數組中元素總個數
4.ndarray.dtype
表示數組中的元素類型
5.ndarray,itemsiez
表示數組中每個元素所占的字節數
print(arr.itemsize)輸出:8
6.ndarray.nbytes
表示數組占用的字節總數
print(arr.nbytes)輸出:48
7.ndarray.T
表示數組的轉置(行變成列,列變成行)
8.ndarray.real
獲取數組中元素的實部
9.ndarray.imag
獲取數組中元素的虛部
10.ndarray.flags? ndarray.strides? ndarray.data
這三個屬性不常用,用到了再了解
3.數組的reshape函數
reshape本身就有重塑,改造的意思(shape 形狀,塑造)
reshape函數用于在不改變數組數據的情況下,重新調整數組的形狀,只要新形狀的總數據量和原來形狀的總數據量一致就行
在reshape方法中,-1參數可以讓Numpy自動計算維度的大小,即根據數組中元素的總個數和其他維度的大小自動推導出該維度的大小。注意:當使用reshape方法時,只有一個維度大小可以設置成-1
4.數組中的視圖(view)和副本(copy)
在Numpy中,視圖和副本是是兩種不同的數組操作方式,它們在數據存儲和內存管理上有顯著的區別
1.視圖(view)
視圖是原數組的一種“窗口”,它并不創建新的數據存儲,而是直接引用原數組的內存,對視圖的修改會直接影響原數組
1.視圖創建方式
使用切片操作[:]
使用reshape方法
使用transpose方法(轉置)
2.視圖的特點
不會占用額外的內存空間
修改視圖中的數據會影響到原數組中的數據
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6])
view = arr.reshape((2, 3)) # 創建視圖print("Original array:", arr)
print("View array:", view)# 修改視圖
view[0, 0] = 100print("Modified original array:", arr)
print("Modified view array:", view)輸出:
Original array: [1 2 3 4 5 6]
View array: [[1 2 3]
? ? ? ? ? ? ?[4 5 6]]
Modified original array: [100 ? 2 ? 3 ? 4 ? 5 ? 6]
Modified view array: [[100 ? 2 ? 3]
? ? ? ? ? ? ? ? ? ? ? [ ?4 ? 5 ? 6]]
2.副本(copy)
副本是原數組的一個完整拷貝,它在內存中創建了新的數據存儲。對副本的修改不會影響原數組
1.副本的創建方式
使用.copy()方法
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6])
copy = arr.reshape((2, 3)).copy() # 創建副本print("Original array:", arr)
print("Copy array:", copy)# 修改副本
copy[0, 0] = 100print("Modified original array:", arr)
print("Modified copy array:", copy)輸出:
Original array: [1 2 3 4 5 6]
Copy array: [[1 2 3]
? ? ? ? ? ? ?[4 5 6]]
Modified original array: [1 2 3 4 5 6]
Modified copy array: [[100 ? 2 ? 3]
? ? ? ? ? ? ? ? ? ? ? [ ?4 ? 5 ? 6]]
3.如何判斷一個數組是視圖還是副本
使用ndarray.flags屬性
如果OWNDATA=True 表示數組是副本,擁有自己的內存
如果OWNDATA=False 表示數組是視圖,引用了其他數組的內存
5.可以使用astype方法修改數組的數據類型
ndarray.astype(dtype)
其中dtype表示要轉換的數據類型
6.數組運算
基礎的加減乘除乘方就不說了
np.srqt(ndarray)
np.abs(ndarray)
np.cos(ndarray)
np.sin(ndarray)
np.exp(ndarray)
7.數組的切片
看前面的文章
8.數組的連接
1.numpy.concatenate()
參數axis=0表示垂直拼接,axis=1表示水平拼接
2.numpy.vstack()
Vertical 垂直的
3.numpy.hstack()
Horizontal 水平的
注意:水平連接要求數組之間行數一致,垂直連接要求數組之間列數一致
import numpy as npnp.random.seed(42) # 設置隨機數種子
n1 = np.random.randint(1,10,size=(2,3))
n2 = np.random.randint(2,20,size=(3,3))
n3 = np.random.randint(3,30,size=(2,4))print(np.concatenate((n1,n2),axis=0)) # 垂直拼接
print(np.concatenate((n1,n3),axis=1)) # 水平拼接輸出:
[[ 7 ?4 ?8]
?[ 5 ?7 ?3]
?[12 12 ?5]
?[ 9 ?4 ?3]
?[13 ?7 ?3]]
[[ 7 ?4 ?8 23 ?3 14 28]
?[ 5 ?7 ?3 24 14 27 19]]
print(np.vstack([n1,n2])) # 垂直拼接
print(np.hstack((n1,n3))) # 水平拼接輸出:
[[ 7 ?4 ?8]
?[ 5 ?7 ?3]
?[12 12 ?5]
?[ 9 ?4 ?3]
?[13 ?7 ?3]]
[[ 7 ?4 ?8 23 ?3 14 28]
?[ 5 ?7 ?3 24 14 27 19]]
9.數組形態的轉換
1.numpy.ravel()
將多維數組展平成一維數組
ravel_n1 = np.ravel(n1) # 展平
print(ravel_n1)輸出:
[7 4 8 5 7 3]
2.numpy.flatten()
將多維數組展平成一維數組
flatten_n2 = n2.flatten()
print(flaten_n2)輸出:
[12 12 ?5 ?9 ?4 ?3 13 ?7 ?3]
3.ndarray.reshape(-1)
reshape_n3 = n3.reshape(-1)
print(reshape_n3) # 展平,-1表示自動計算維度輸出:
[23 ?3 14 28 24 14 27 19]
二.Pandas
Pandas是基于Numpy開發的一個Python包。Pandas作為Python數據分析的核心包,提供了大量數據分析的函數,包括數據處理,數據抽取,數據集成,數據計算等基本數據分析手段。
Pandas核心數據結構包括序列和數據框。序列存儲一維數據,而數據框可以存儲更復雜的多維數據
1.數據框DataFrame的拼接
1.concat函數
import pandas as pd
import numpy as np
np.random.seed(42)
df1 = pd.DataFrame(data=np.random.randint(1,10,size=(3,2)))
df2 = pd.DataFrame(data=np.random.randint(1,10,size=(3,4)))
df3 = pd.DataFrame(data=np.random.randint(1,10,size=(4,2)))
print(df1)
print()
print(df2)
print()
print(df3)# 按列拼接,axis=1,即按列對齊,也就是列索引對齊,還可以理解為橫向拼接
print(pd.concat([df1,df2],axis=1))
print()
print(pd.concat([df1,df2],axis=1,ignore_index=True)) # 忽略索引,重新生成索引
print()
# 按行拼接,axis=0,即按行對齊,也就是行索引對齊,還可以理解為縱向拼接
print(pd.concat([df1,df3],axis=0))輸出:
? 0 ?1
0 ?7 ?4
1 ?8 ?5
2 ?7 ?3
? ?0 ?1 ?2 ?3
0 ?7 ?8 ?5 ?4
1 ?8 ?8 ?3 ?6
2 ?5 ?2 ?8 ?6
? ?0 ?1
0 ?2 ?5
1 ?1 ?6
2 ?9 ?1
3 ?3 ?7
? ?0 ?1 ?0 ?1 ?2 ?3
0 ?7 ?4 ?7 ?8 ?5 ?4
1 ?8 ?5 ?8 ?8 ?3 ?6
2 ?7 ?3 ?5 ?2 ?8 ?6
? ?0 ?1 ?2 ?3 ?4 ?5
0 ?7 ?4 ?7 ?8 ?5 ?4
1 ?8 ?5 ?8 ?8 ?3 ?6
2 ?7 ?3 ?5 ?2 ?8 ?6
? ?0 ?1
0 ?7 ?4
1 ?8 ?5
2 ?7 ?3
0 ?2 ?5
1 ?1 ?6
2 ?9 ?1
3 ?3 ?7
到現在,對一些函數的參數axis有了一點新的理解:
axsi=0,表示對行進行操作,比如使用concat函數時設置axis=0表示按行拼接,就是把數據一行一行接上去,即垂直連接
axis=1則表示對列進行操作,使用concat函數時設置axis=1表示按列拼接,就是把數據一列一列接上去,即水平連接
三.Matplotlib.pyplot
1.plt.pie()
import matplotlib.pyplot as plt
import numpy as npplt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10,10))sales_data = [100,102,140,149,120]
fruit_labels = ['西瓜','蘋果','香蕉','菠蘿','橘子']plt.subplot(2,3,1)
plt.pie(sales_data,labels=fruit_labels,autopct='%1.2f%%')
plt.title("水果銷售占比分析圖")plt.subplot(2,3,2)
plt.bar(fruit_labels,np.array(sales_data))
for x,y in enumerate(sales_data):plt.text(x-0.3,y+1,str(y),color='r')
plt.grid(alpha=0.5)
plt.title("水果銷售數量柱狀圖")
plt.xlabel('水果種類')
plt.ylabel('銷售數量')plt.subplot(2,3,3)
def my_autopct_func(percentage,all_values):absolute = round(percentage / 100 * sum(all_values))return f"{percentage:.1f}%\n({absolute}份)"
plt.pie(sales_data,autopct=lambda pct:my_autopct_func(pct,sales_data),labels=fruit_labels)
plt.title("水果銷售占比分析")plt.subplot(2,3,4)
plt.pie(sales_data,labels=fruit_labels,autopct='%1.2f%%',startangle=90,explode=(0,0.1,0.2,0.3,0.4))
plt.title("水果銷售占比分析")plt.subplot(2,3,5)
plt.pie(sales_data,labels=fruit_labels,autopct='%1.2f%%',startangle=180,explode=(0,0.01,0.05,0.1,0.15),shadow={'ox':-0.04,'oy':0.04,'edgecolor':'none','shade':0.5,'alpha':0.7})plt.tight_layout()
plt.show()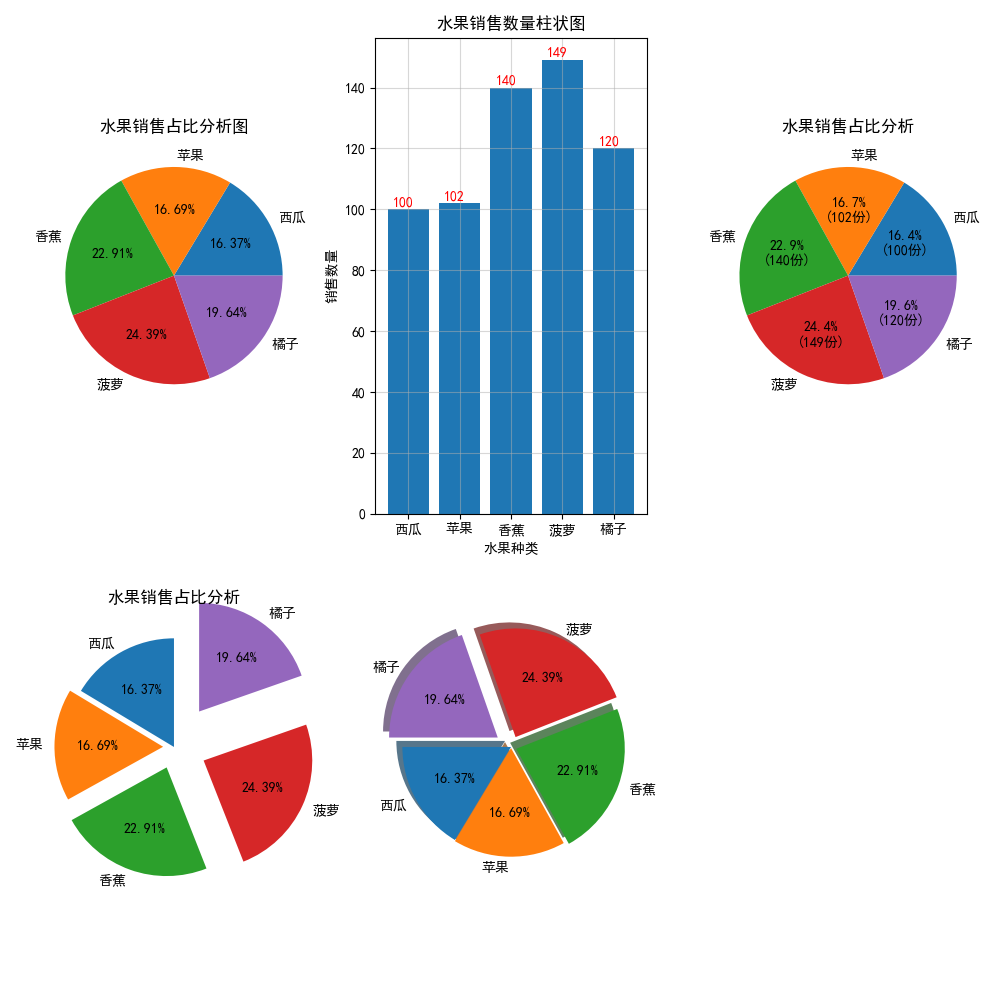


![[Java惡補day13] 53. 最大子數組和](http://pic.xiahunao.cn/[Java惡補day13] 53. 最大子數組和)




你好,三角形(Hello Triangle))





)


)


