Kafka 介紹
想象一下你正在運營一個大型電商平臺,每秒都有成千上萬的用戶瀏覽商品、下單、支付,同時后臺系統還在記錄用戶行為、更新庫存、處理物流信息。這些海量、持續產生的數據就像奔騰不息的河流,你需要一個強大、可靠且實時的系統來接收、存儲并處理這些數據洪流,讓不同的業務部門(比如實時推薦、庫存管理、風險控制、用戶行為分析)都能及時獲取他們需要的信息。這就是Apache Kafka大展拳腳的舞臺。
本質上,Kafka是一個開源的、分布式的流處理平臺。它最核心的能力是作為一個高吞吐量、低延遲、可水平擴展且持久化的發布-訂閱消息系統。你可以把它想象成一個超級高效、永不丟失的“消息管道”或“數據中樞”。它的設計哲學就是處理源源不斷產生的實時數據流(Data Streams)。
我們看幾個具體的例子:
-
構建實時數據管道和流處理: 這是Kafka的看家本領。比如在金融行業,一家證券交易所需要實時處理每秒產生的巨量股票交易訂單數據。Kafka作為核心樞紐,可靠地接收來自各個交易終端發來的訂單消息,持久化存儲它們。然后,風控系統可以實時訂閱這些數據流,毫秒級地檢測異常交易模式防止欺詐;交易撮合引擎訂閱數據進行實時匹配;同時,另一個消費者可能將這些數據實時推送到數據倉庫或Hadoop集群,供分析師進行更深入的歷史趨勢研究。所有系統都通過Kafka這個統一、可靠的管道獲取實時數據,避免了復雜的點對點集成。
-
網站活動追蹤和日志聚合: 想象一下像滴滴這樣的大型應用。每當乘客打開APP、搜索地點、呼叫車輛、司機接單、車輛移動、行程結束、支付完成,每一步都會產生一條事件日志。這些日志數量巨大且分散在各個服務器上。Kafka提供了一個中心化的地方,讓所有服務器都可以輕松地將這些活動事件(比如“用戶A在時間T點擊了按鈕B”)作為消息發布到特定的主題(Topics)里。下游的各種系統可以按需訂閱:實時監控系統訂閱這些流來監控APP的實時健康狀態和用戶行為漏斗;用戶畫像系統訂閱來更新用戶的實時偏好和行為軌跡;安全團隊訂閱來實時檢測可疑活動(如異常頻繁的登錄嘗試)。同時,這些日志也可以被消費到像Elasticsearch這樣的系統中提供快速的搜索和可視化,或者到HDFS做長期存儲和離線分析。Kafka高效地統一了日志收集的入口。
-
物聯網數據集成: 在智能工廠或智慧城市項目中,成千上萬的傳感器(溫度、濕度、壓力、位置、攝像頭圖像元數據等)每時每刻都在產生數據。這些傳感器設備(或邊緣網關)將采集到的數據發送到Kafka。Kafka憑借其高吞吐量和分布式特性,輕松承接這些海量、高速的傳感器數據流。實時監控中心訂閱這些數據流,可以立刻在大屏上展示工廠設備的運行狀態或城市的交通流量;預測性維護系統分析設備傳感器數據流,實時判斷機器是否可能出現故障;數據湖則消費這些數據,存儲起來供后續訓練AI模型優化生產流程或城市規劃。
-
解耦微服務通信: 在一個由許多小型、獨立服務(微服務)構成的現代應用架構中,服務之間需要通信。Kafka可以作為它們之間的可靠“緩沖帶”或“通信總線”。例如,在一個電商系統中,“訂單服務”處理完一個新訂單后,它不需要直接調用“庫存服務”、“支付服務”和“物流服務”,而是簡單地將一條“新訂單創建”的消息發布到Kafka的一個主題里。各個相關的服務(庫存扣減、支付處理、物流調度)都獨立地訂閱這個主題。這樣,“訂單服務”只需要快速把消息發出去就完成任務了,不用等待或關心下游服務何時處理、是否成功(下游服務自己保證消費可靠性),大大提高了系統的整體響應速度、可擴展性和容錯性。即使某個下游服務(如物流服務)暫時宕機,消息也會安全地保存在Kafka中,等它恢復后繼續處理。
-
事件溯源和變更數據捕獲: 在一些需要精確記錄狀態變化歷史的系統中(如銀行核心系統、審計系統),Kafka可以用來存儲所有導致狀態變化的事件序列。例如,一個銀行賬戶的每次存款、取款、轉賬操作都被記錄為一個不可變的事件,發布到Kafka。通過重放這些事件流,可以精確地重建賬戶在任何歷史時刻的狀態,提供了強大的審計追蹤能力。同時,數據庫的變更(CDC - Change Data Capture)也可以通過工具捕獲(如讀取數據庫的binlog),轉換成事件流發布到Kafka,讓其他系統能夠近乎實時地感知到數據庫的變動。
總結來說,Kafka的核心價值在于它能夠:
-
可靠地處理海量實時數據流:像一個永不堵塞的高速公路。
-
持久化存儲數據流:數據可以保留很長時間(幾天、幾周甚至幾個月),允許不同的消費者按自己的節奏重放歷史數據。
-
連接不同的系統和應用:作為統一、可靠的數據中樞,簡化系統架構,實現松耦合。
-
支撐實時處理和分析:為需要即時響應的業務場景(監控、風控、推薦、告警)提供實時數據源。
Kafka角色和流程
Kafka角色
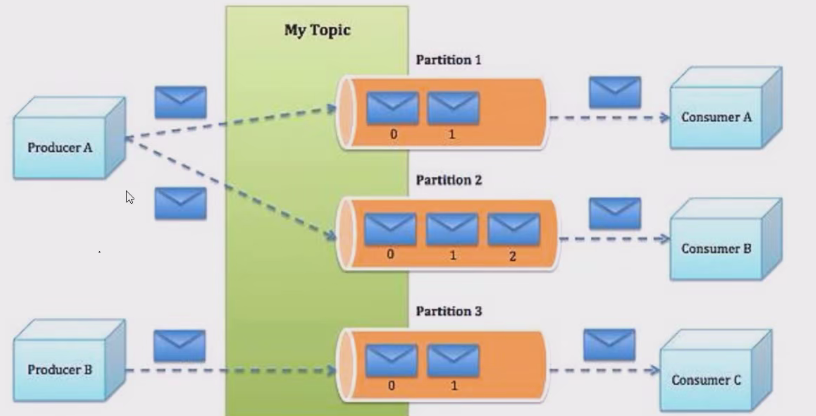
-
Producer: Producer即生產者,消息的產生者,是消息的入口。負責發布消息到Kafka broker。
-
Consumer: 消費者,用于消費消息,即處理消息
-
Broker:Broker是kafka實例,每個服務器上可以有一個或多個kafka的實例,假設每個broker對應一臺服務器,每個kafka集群內的broker都有一個不重復的編號,如: broker-0, broker-1等……
-
Topic: 消息的主題,可以理解為消息的分類,相當于Redis的Key和ES中的索引,kafka的數據就保存在Topic,在每個broker上都可以創建多個Topic,物理上不同 topic 的消息分開存儲在不同的文件夾,邏輯上一個 topic的消息雖然保存于一個或多個broker 上,但用戶只需指定消息的Topic即可生成聲明數據而不必關心數據存于何處。Topic 在邏輯上對record記錄、日志進行分組保存,消費者需要訂閱相應的Topic才能滿足Topic中的消息。
-
Consumer group: 每個consumer 屬于一個特定的consumer group(可為每個consumer 指定 group name,若不指定 group name 則屬于默認的group),同一topic的一條消息只能被同一個consumer group 內的一個consumer 請求,類似于一對一的單播機制,但多個consumer group 可同時請求這一消息,類似于一對多的多播機制
-
Partition:是物理上的概念,每個topic 分別為一個或多個partition,即一個topic劃分為多份創建 topic的可指定 partition 數量。partition的表現形式就是一個一個的文件夾,該文件夾下存儲該partition的數據和索引文件,分區的作用還可以實現負載均衡,提高kafka的吞吐量。同一個topic在不同的分區的數據是不重復的,一般Partition數不要超過節點數。注意同一個partition數據是有順序的,但不同partition則是無序的。
-
Replication: 同樣數據的副本,包括leader和follower的副本數基本于數據安全,建議至少2個,是Kafka的高可靠性的保障。和ES的副本有所不同,Kafka中的副本數包括主分片數,而ES中的副本數不包括主分片數
-
AR:Assigned Replicas,分區中的所有副本的統稱,包括leader和 follower。AR= ISR+ OSR
-
ISR:In Sync Replicas,所有與leader副本保持同步的副本 follower和leader本身組成的集合,包括leader和 follower,是AR的子集
-
OSR:out-of-Sync Replied,所有與leader副本同步不能同步的 follower的集合,是AR的子集
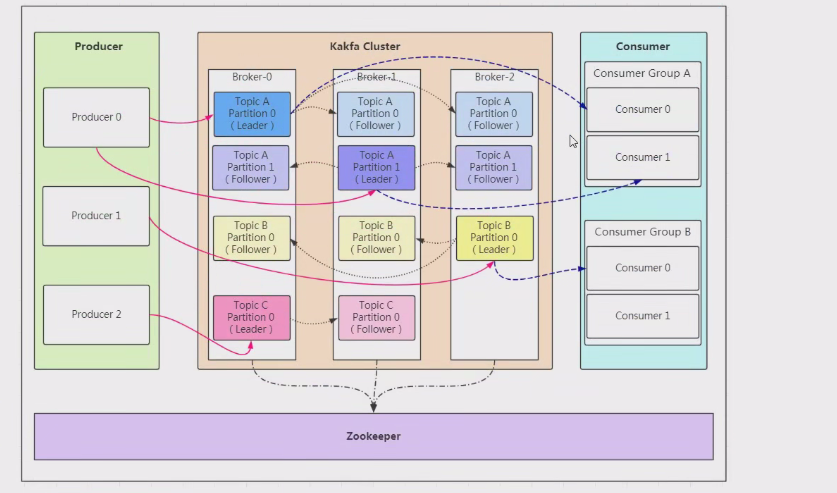
Kafka寫入消息流程
Kafka 配置文件說明
配置文件說明#?配置文件?./conf/server.properties?內部說明********?Server?Basics?********#?broker?的?id,值為整數,且必須唯一,在一個集群中不能重復
broker.id=1********?Socket?Server?Settings?********#?kafka?監聽端口,默認?9092
listeners=PLAINTEXT://10.0.0.101:9092#?處理網絡請求的線程數量,默認為?3?個
num.network.threads=3#?執行磁盤?IO?操作的線程數量,默認為?8?個
num.io.threads=8#?socket?服務發送數據的緩沖區大小,默認?100kB
socket.send.buffer.bytes=102400#?socket?服務接受數據的緩沖區大小,默認?100kB
socket.receive.buffer.bytes=102400#?socket?服務所能接受的一個請求的最大大小,默認為?100M
socket.request.max.bytes=104857600********?Log?Basics?********#?kafka?存儲消息數據的目錄
log.dirs=../data#?每個?topic?的默認?partition?數量
num.partitions=1#?設置默認副本數量為?3。如果?Leader?副本故障,會進行故障自動轉移。
default.replication.factor=3#?在啟動時恢復數據和關閉時刷數據前,每個數據目錄使用的線程數量
num.recovery.threads.per.data.dir=1********?Log?Flush?Policy?********#?消息刷新到磁盤中的消息條數閾值
log.flush.interval.messages=10000#?消息刷新到磁盤中的最大時間間隔,?1s
log.flush.interval.ms=1000*******************************************************?Log?Retention?Policy?*******************************************************#?日志保留時間,超時會自動刪除,默認為?7?天?(168?小時)
log.retention.hours=168#?日志保留大小,超出大小會自動刪除,默認為?1GB
log.retention.bytes=1073741824#?單個日志段文件的大小限制,最大為?1GB,超出后則創建一個新的日志段文件
log.segment.bytes=1073741824#?每隔多長時間檢測數據是否達到刪除條件,?300s?(5?分鐘)
log.retention.check.interval.ms=300000********?Zookeeper?********#?Zookeeper?連接信息,如果是?Zookeeper?集群,則以逗號隔開
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181#?連接?Zookeeper?的超時時間,?6s
zookeeper.connection.timeout.ms=6000#?是否允許刪除?topic,默認為?false(topic?只會被標記為待刪除)。設置為?true?則允許物理刪除。
delete.topic.enable=true
Kafka 集群部署
| version | IP | |
|---|---|---|
| Zookeeper | 3.8.4 | 192.168.80.11-80.33 |
| Kafka | 3.8.0 | 192.168.80.11-80.33 |
一鍵安裝腳本
每個節點分別執行
#!/bin/bash
KAFKA_VERSION=3.8.0
SCALA_VERSION=2.13
KAFKA_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/${KAFKA_VERSION}/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz"
ZK_VERSION=3.8.4ZK_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-${ZK_VERSION}/apache-zookeeper-${ZK_VERSION}-bin.tar.gz"ZK_INSTALL_DIR=/usr/local/zookeeper
KAFKA_INSTALL_DIR=/usr/local/kafkaNODE1=192.168.80.11
NODE2=192.168.80.12
NODE3=192.168.80.13HOST=$(hostname?-I?|?awk?'{print?$1}')
.?/etc/os-releaseprint_status()?{local?msg=$1local?status=$2local?GREEN='\033[0;32m'local?RED='\033[0;31m'local?YELLOW='\033[0;33m'local?NC='\033[0m'case?$status?insuccess)color=$GREENsymbol="[??OK??]";;failure)color=$REDsymbol="[FAILED]";;warning)color=$YELLOWsymbol="[WARNING]";;esacprintf?"%-50s?${color}%s${NC}\n"?"$msg"?"$symbol"
}detect_node_id()?{if?[[?$HOST?==?$NODE1?]];?thenMYID=1elif?[[?$HOST?==?$NODE2?]];?thenMYID=2elif?[[?$HOST?==?$NODE3?]];?thenMYID=3elsewhile?true;?doread?-p?"輸入節點編號?(1-3):?"?MYIDif?[[?$MYID?=~?^[1-3]$?]];?thenbreakelseprint_status?"無效的節點編號"?warningfidonefiprint_status?"節點ID:?$MYID"?success
}install_java()?{if?[[?$ID?==?'centos'?||?$ID?==?'rocky'?]];?thenyum?-y?install?java-1.8.0-openjdk-develelseapt?updateapt?install?-y?openjdk-8-jdkfiif?java?-version?&>/dev/null;?thenprint_status?"Java安裝成功"?successelseprint_status?"Java安裝失敗"?failureexit?1fi
}setup_zookeeper()?{local?src_dir="/usr/local/src"local?pkg_name=$(basename?$ZK_URL)if?[[?!?-f?"$src_dir/$pkg_name"?]];?thenwget?-P?$src_dir?$ZK_URL?||?{print_status?"ZooKeeper下載失敗"?failureexit?1}fitar?xf?"$src_dir/$pkg_name"?-C?/usr/local?||?{print_status?"解壓失敗"?failureexit?1}ln?-sf?/usr/local/apache-zookeeper-*-bin?$ZK_INSTALL_DIRecho?"PATH=$ZK_INSTALL_DIR/bin:\$PATH"?>?/etc/profile.d/zookeeper.shsource?/etc/profile.d/zookeeper.shmkdir?-p?$ZK_INSTALL_DIR/dataecho?$MYID?>?$ZK_INSTALL_DIR/data/myidcat?>?$ZK_INSTALL_DIR/conf/zoo.cfg?<<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=$ZK_INSTALL_DIR/data
clientPort=2181
maxClientCnxns=128
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
server.1=$NODE1:2888:3888
server.2=$NODE2:2888:3888
server.3=$NODE3:2888:3888
EOFcat?>?/etc/systemd/system/zookeeper.service?<<EOF
[Unit]
Description=ZooKeeper?Service
After=network.target[Service]
Type=forking
Environment="JAVA_HOME=$(dirname?$(dirname?$(readlink?-f?$(which?java))))"
ExecStart=$ZK_INSTALL_DIR/bin/zkServer.sh?start
ExecStop=$ZK_INSTALL_DIR/bin/zkServer.sh?stop
ExecReload=$ZK_INSTALL_DIR/bin/zkServer.sh?restart
User=root
Group=root
Restart=on-failure
RestartSec=10[Install]
WantedBy=multi-user.target
EOFsystemctl?daemon-reloadsystemctl?enable?--now?zookeeper.serviceif?systemctl?is-active?--quiet?zookeeper.service;?thenprint_status?"ZooKeeper啟動成功"?successelseprint_status?"ZooKeeper啟動失敗"?failureexit?1fi
}setup_kafka()?{local?src_dir="/usr/local/src"local?pkg_name=$(basename?$KAFKA_URL)if?[[?!?-f?"$src_dir/$pkg_name"?]];?thenwget?-P?$src_dir?$KAFKA_URL?||?{print_status?"Kafka下載失敗"?failureexit?1}fitar?xf?"$src_dir/$pkg_name"?-C?/usr/local?||?{print_status?"解壓失敗"?failureexit?1}ln?-sf?/usr/local/kafka_*?$KAFKA_INSTALL_DIRecho?"PATH=$KAFKA_INSTALL_DIR/bin:\$PATH"?>?/etc/profile.d/kafka.shsource?/etc/profile.d/kafka.shmkdir?-p?$KAFKA_INSTALL_DIR/datacat?>?$KAFKA_INSTALL_DIR/config/server.properties?<<EOF
broker.id=$MYID
listeners=PLAINTEXT://$HOST:9092
log.dirs=$KAFKA_INSTALL_DIR/data
num.partitions=1
log.retention.hours=168
zookeeper.connect=$NODE1:2181,$NODE2:2181,$NODE3:2181
zookeeper.connection.timeout.ms=6000
EOFcat?>?/etc/systemd/system/kafka.service?<<EOF
[Unit]
Description=Apache?Kafka
After=network.target?zookeeper.service[Service]
Type=simple
Environment="JAVA_HOME=$(dirname?$(dirname?$(readlink?-f?$(which?java))))"
ExecStart=$KAFKA_INSTALL_DIR/bin/kafka-server-start.sh?$KAFKA_INSTALL_DIR/config/server.properties
ExecStop=/bin/kill?-TERM?\$MAINPID
Restart=on-failure
RestartSec=20[Install]
WantedBy=multi-user.target
EOFsystemctl?daemon-reloadsystemctl?enable?--now?kafka.serviceif?systemctl?is-active?--quiet?kafka.service;?thenprint_status?"Kafka啟動成功"?successelseprint_status?"Kafka啟動失敗"?failureexit?1fi
}detect_node_id
install_java
setup_zookeeper
setup_kafka
print_status?"安裝完成"?success
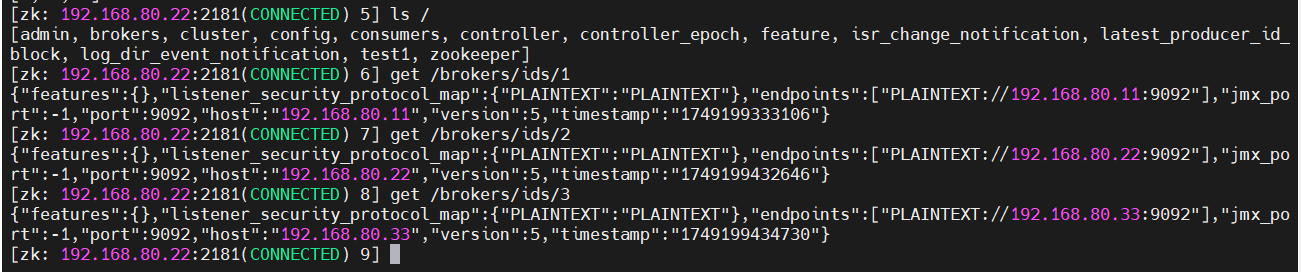
查看Kafka注冊情況
創建Topic
/usr/local/kafka/bin/kafka-topics.sh?--create?--topic?DBA?--bootstrap-server?192.168.80.11:9092?--partitions?3?--replication-factor?2

獲取所有 Topic
/usr/local/kafka/bin/kafka-topics.sh?--list?--bootstrap-server?192.168.80.11:9092

獲取Topic副詳情
/usr/local/kafka/bin/kafka-topics.sh?--describe?--bootstrap-server?192.168.80.11:9092

Kafka 生產者產出數據
/usr/local/zookeeper/bin#?/usr/local/kafka/bin/kafka-console-producer.sh?--broker-list?192.168.80.11:9092?--topic?DBA

Kafka 消費者消費數據
/usr/local/kafka/bin/kafka-console-consumer.sh?--topic?DBA?--bootstrap-server?192.168.80.22:9092?--from-beginning

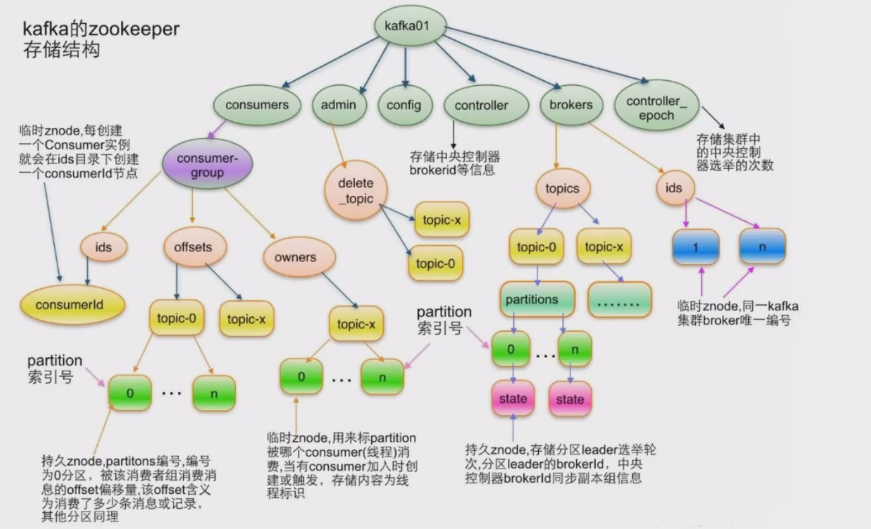
Kafka在Zookeeper中存儲結構



對沖基金模擬系統:模范巴菲特、凱西·伍德的投資策略)



![[Java惡補day13] 53. 最大子數組和](http://pic.xiahunao.cn/[Java惡補day13] 53. 最大子數組和)




你好,三角形(Hello Triangle))





)
