目錄
一 虛擬地址到物理地址的轉換
1. 操作系統如何管理物理內存:
2. 下面來談談虛擬地址如何轉換到物理地址:
3. 補充字段:
二 Linux中的線程
1. 先來說說進程:
2. 線程:
3. 線程相比較于進程的優缺點:
4. 線程獨有的字段:
5. pthread庫:
一 虛擬地址到物理地址的轉換
1. 操作系統如何管理物理內存:
假設物理內存是4GB,管理物理內存基本單位是1字節嗎?不是,一般是以4KB為一個基本單位,稱為頁框(頁楨),正好操作系統與磁盤交互也是以4KB為基本單位,即讀取8個扇區,既然4KB為單位,4GB有很多個4KB,勢必也要進行管理吧,這里簡單一點當成數組進行管理,實際是伙伴系統/slab....機制。
4GB / 4KB = 1,039,386個4KB,忽略其他字段:頁框的使用情況...等。
也就是說數組大小為100w,假設地址從 0 ~ 4GB 編制,第0~1023字節,也就是對應的第0號下標,1024?~ 2*4KB,對應第二個下標,取模,余數丟掉,所以只要拿著任意的地址都能索引到這個數組的任意下標,反向也能轉回到頁框的起始地址,當然,這個數組肯定也要在內存中開辟空間,100w * 4 = 400w 字節 -> 4k,每個下標存放頁框的起始地址,這個不考慮。
2. 下面來談談虛擬地址如何轉換到物理地址:
32位平臺下:
虛擬地址主要是通過頁表轉換到物理地址,虛擬地址是 0 ~ 4G,如果按一對一進行映射,頁表存放虛擬地址和物理地址的指針,一共4G,也就是4G * 8 = 32G的內存大小,顯然是不現實的。
上面是把虛擬地址整體使用了,下面來看看另一個方案。
指針大小也就是 0 ~ 2^32次方,那能不能從這個虛擬地址的bit位入手?
實際上不僅僅只有一個頁表,會有一個頁目錄,和頁表。
頁目錄:存放指針高位前10bit位,也就是 2^10次方,1024,頁目錄一共1024個項,里面每一項存放的是頁表的起始地址。
頁表:頁目錄能索引到頁表,頁表大小是多少呢?也是1024項,取指針中間的10個bit位,每一項存放的是頁框的起始地址,所以頁表主要是用來建立頁框的起始地址,也就是映射。
還有12bit位干嘛的?
頁框是4KB,2^12次方剛好也是4KB,所以后面剩余的12bit是用來在頁框中偏移的,頁表以及存放的是頁框的起始地址了,在進行頁內偏移,最終拿到頁框中某一個字節。
所以上述方案是利用了指針大小的bit位來進行轉換劃分的,而不是當整塊使用暴力映射。
不同的進程虛擬地址完全一樣,索引路徑也一樣,但最終頁表存放的物理地址不一樣,也側面證明了進程是相互獨立的,父子進程除外。
最后再來算一算頁表和頁目錄占用內存的大小:
頁目錄:1024項 + 存放頁表的地址:1024 * 4 = 4KB
頁表:1024個頁目錄 + 每個頁目錄對應的頁表也是1024項 + 頁表每一項和物理地址的映射也就是存放頁框的起始地址 = 1024 * 1024 * 4 = 4M
最終占總大小:4M + 4KB,這是最壞的情況,所有的虛擬地址全用上了,實際可能只會用一點點。
3. 補充字段:
1. 誰拿頁表進行尋址呢?
OS?不是,CPU內部集成了一個硬件MMU,作用是用來進行頁表轉換的,怎么拿到頁表?CPU內又有一個寄存器CR3,記錄頁表的起始地址在交給MMU,自此從MMU出來的就是實際的物理地址。
2. 如果在程序某個地方打了個死循環,MMU每次都要查相同的虛擬地址,是不是沒必要啊?所以在CPU內部還有個寄存器TLB,主要用來緩存MMU之前查過的虛擬地址,以便后續省了查表的過程,變相提高了虛擬到物理的轉換了。
3. 頁表下標存放頁框的地址,也就是指針4字節整數(2^32),直接用來索引頁框嗎?上面說的頁框有100w個,2^20次方就是100w,剩下的12位浪費了嗎?不是,頁表不僅僅只有映射,還有比如該地址對應的對象的讀寫權限位,用戶/內核態標記等字段,所以也就利用了這些剩余的bit位來標記比如虛擬地址是否合法,是否命中物理內存(否則缺頁中斷)等標記位。
二 Linux中的線程
1. 先來說說進程:
當創建一個進程,加載可執行文件代碼和數據,創建內核數據結構:PCB,mm_struct,文件描述符表....等對象,都需要在內存中申請空間,被CPU調度,切換保護進程上下文數據,重新填充pc指針,MMU,TLB,CR3,等一系列的寄存器,每個進程新創建/被切換,帶來的開銷勢必是很大的,這也就是為什么進程是資源分配的基本單位,要什么資源直接給進程分配物理內存。
2. 線程:
上面說的進程,不管是創建,調度等策略,線程是否也需要構建和進程一樣的策略呢?如果采用,編碼方面肯定復雜,其次比如調度和進程不一樣,CPU是不是還要識別是進程還是線程?
所以在Linux中,線程沒有單獨制定個進程類似的策略,直接共享進程大部分屬性,比如:調度算法,CPU一視同仁,不過線程也要有自己的一些其他字段。
既然線程能共享進程內的大部分資源,那么如何理解線程是CPU調度的基本單位?
進程也能被調度,線程也能:
進程調度,當時間片到了切換到下一個進程時,保存上下文更新,CR2指向的頁表,TLB緩存內容,全部都失效重新加載新的進程,重新進行TLB緩存預熱。
不僅僅是TLB緩存虛擬地址和物理地址的映射,CPU內部還有cache緩存,緩存代碼塊和數據,比如:訪問第10行代碼,把第10行代碼周邊的數據按4KB為基本單位緩存到cache緩存中,下次也能直接讀取,不用間接尋址,遵循局部性原理規則,雖然不一定訪問到,但極大概率訪問到。
最重要的就是TLB,cache緩存,TLB存放高頻訪問的虛擬地址直接失效,cache緩存存放高頻的數據塊和代碼塊,進程會更新導致失效并重新進行尋址加載,而線程共享這些屬性,無需更改,直接查,效率要高得多。
在Linux中沒有真正的線程,只有輕量級進程(LWP),不管是單進程里面的一個執行流,也是輕量級進程,創建多個線程也是輕量級進程,而輕量級進程就是模擬進程的策略而誕生出來的。
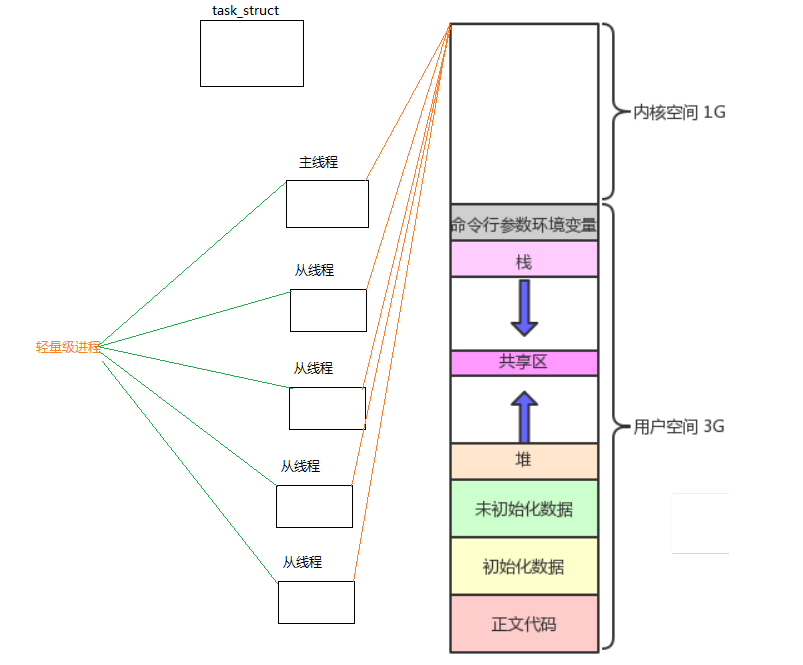
3. 線程相比較于進程的優缺點:
優點:
- 線程占用的資源比進程少,共享進程大部分資源,進程需要重新分配資源
- 線程創建成本小,共享進程大部分資源
- 線程共享進程虛擬地址空間,切換無需更改,進程則需要
- 進程切換會更新TLB快表,cache緩存,導致熱數據直接失效,重新訪問內存填充
- 線程共享數據容易,進程需要通信機制:fork(),管道,system v,posix通信機制提供的系統調用
缺點:
- 線程共享大部分資源,會導致資源競爭導致數據不一致,靜態條件等問題
- 線程創建越多不會導致效率更高,主要以CPU的個數 * CPU的核心數來創建線程對象
- 進程獨立不會影響另一個進程,某一個線程異常,其他同級線程也會異常,線程異常代表進程異常,因為線程共享進程大部分屬性,OS直接把這個線程有關聯的數據全部釋放,其他線程也就沒意義了
4. 線程獨有的字段:
線程ID:多個線程也要有ID區分輕量級進程,總不能這些線程沒有編號吧
優先級:調度優先級肯定也會不一樣,如果一樣先調度誰?
棧:線程執行函數,調用函數就會建立棧幀,如果共享,線程是并發執行的,入棧,彈棧順? ? ? ? ?序就亂了
寄存器:不同的線程被切換也要將該線程當前的上下文數據保存起來,下次進行恢復
信號block表:線程共享handler表,block可以自行屏蔽,比如給進程發信號,所有的線程都要執行這個信號,某個線程可以單獨屏蔽他不執行。
5. pthread庫:
上面說Linux中沒有真正的線程,只有LWP,即輕量級進程,所以為了保證操作系統學科的線程的概念,向上封裝了一層軟件層,pthread庫,也就是對輕量級進程接口進行了封裝,屬于第三方庫,使用必須 -lpthread 指定庫名,具體pthread庫如何管理這些線程,請看下章。






下)










)

