4、數據查詢
語法:
SELECT [ALL | DISTINCT] <目標列表達式> [,<目標列表達式>] …
FROM <表名或視圖名>[, <表名或視圖名> ] …
[ WHERE <條件表達式> ]
[ GROUP BY <列名1> [ HAVING <條件表達式> ] ]
[ ORDER BY <列名2> [ ASC | DESC ] ] ;
注:
? SELECT子句:指定要顯示的屬性列;
? FROM子句:指定查詢對象(基本表或視圖);
? WHERE子句:指定查詢條件;
? GROUP BY子句:對查詢結果按指定列的值分組,該屬性列值
相等的元組為一個組。通常會在每組中使用集函數;
? HAVING短語:篩選出只有滿足指定條件的組;
? ORDER BY子句:對查詢結果按指定列值升序或降序排序。
如果你用金倉數據庫,請設置好你自己的模式
金倉數據庫提示找不到數據表,一般都是模式路徑問題
SET search_path TO “S-T”;
SET search_path TO PUBLIC;
SET search_path TO “S-T”,PUBLIC;
注意:在金倉V8,設置搜索模式路徑之后,這個路徑(查找和插入)優先,如果需要刪除數據、刪除表格,最好加前綴
4.1單表查詢–只涉及到一個表的查詢
- SELECT+列名
[例1]查詢全體學生的學號與姓名。
SELECT Sno,Sname
FROM “S-T”.Student; //等價于 πsno,Sname (Student)–投影,但是投影會去重復,SELECT不會去重復
[例2] 查詢全體學生的詳細記錄。
SELECT * FROM “S-T”.Student;//表示將表中的列全部按序輸出
😎實戰
[步驟1] 設置默認搜索路徑
SET search_path TO “S-T”;
<無論是查找還是插入,都會默認到"S-T"模式下>
[步驟2] 在Student表插入一個記錄
INSERT INTO student (sno,sname,ssex,sage,sdept)
VALUES(‘231803001’,‘張三’,‘M’,18,‘網絡與信息安全學院’);
<在設置了默認搜索路徑后(要插入的表在默認搜索路徑所包含的模式中),插入記錄的時候就不用加前綴了>
[步驟3] 查看插入情況,執行單表查詢例子
SELECT Sno,Sname From Student;
SELECT * From Student ;
- SELECT+目標列表達式
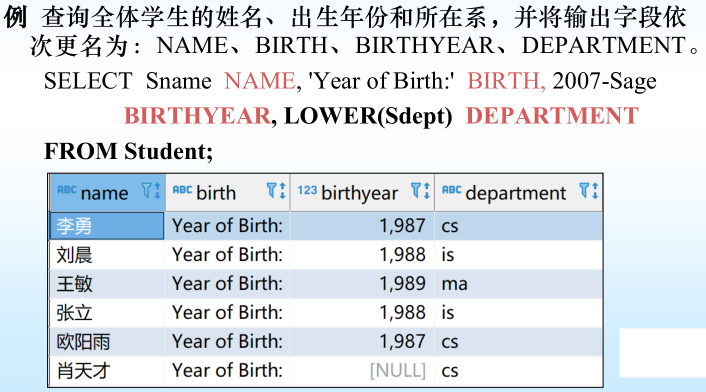
[例1] 查全體學生的姓名及其出生年份(假設這個表是2025年的)
SELECT Sname, 2025-Sage
FROM Student;
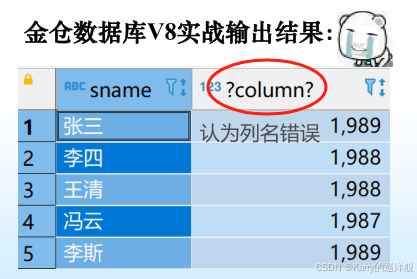
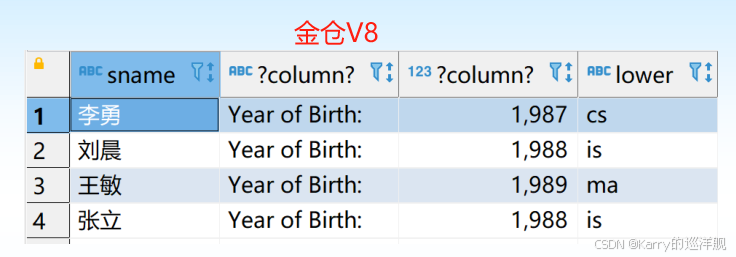
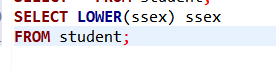
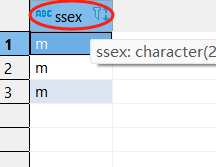
[例2]查詢全體學生的姓名、出生年份和所在系,要求用小寫字母表示所在系名。
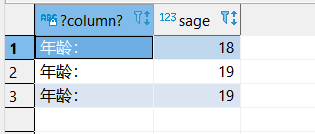
SELECT Sname, ‘Year of Birth:’, 2007-Sage, LOWER(Sdept)
FROM Student ;
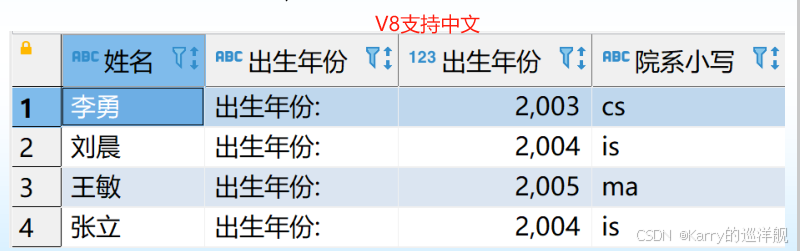
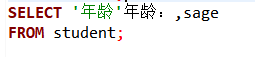
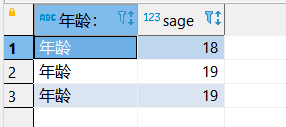
使用列別名改變查詢結果的列標題
;
SELECT Sname 姓名, ‘出生年份:’ 出生年份, 2025-Sage 出生年份, LOWER(Sdept) 院系小寫
FROM Student;
LOWER和UPPER的使用
原表中的數據并沒有改變
SELECT語句想顯示出一整列解釋語句,但原始表的內容并不變,只是執行本次SELECT才會顯示。
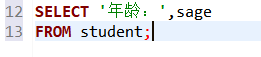
但是,如果這樣,列名會出錯:

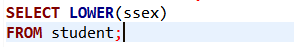

- 消除結果中取值重復的行--在SELECT子句中使用DISTINCT短語。
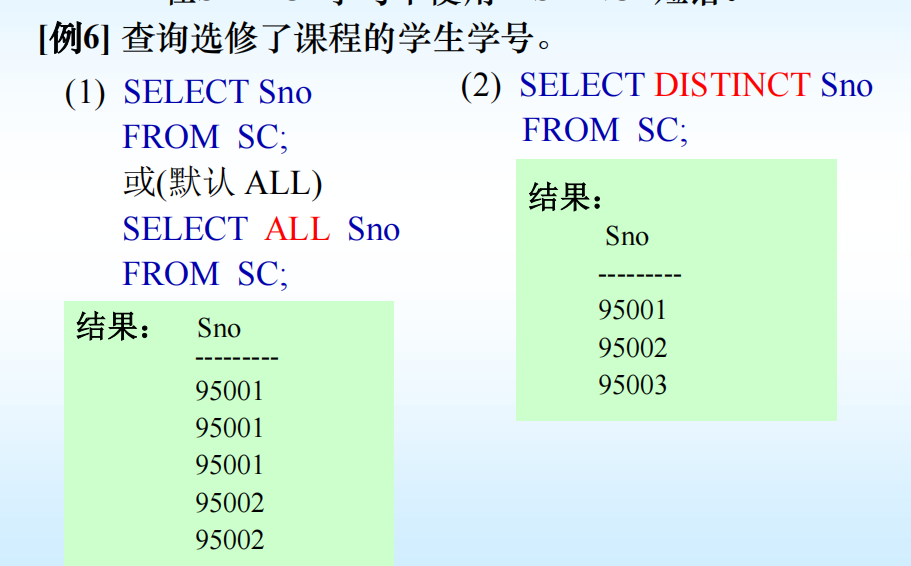
💥注意:DISTINCT短語的作用范圍是所 - 有目標列。返
回的所有目標列中必須有一個屬性不同。



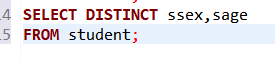



注:在關系代數投影(π)運算的定義中直接去掉了結果中的重復元組,在SQL中必須在SELECT子句中用DISTINCT明確指定才能去掉重復列。
4.2單表查詢–使用WHERE子句
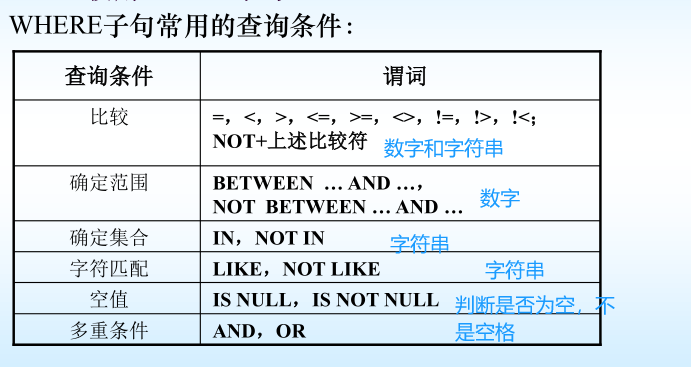
4.2.1比較

4.2.2確定范圍(BETWEEN AND)

4.2.3確定集合(IN、NOT IN)

4.2.4字符串匹配


💥注意:沒有模糊查詢的要求就不要使用LIKE,效率會低很多


4.2.5涉及空值的查詢


4.2.6多重條件的查詢(將上面五種查詢結合一下)
用邏輯運算符AND和OR來聯結多個查詢條件
? AND的優先級高于OR
? 可以用括號改變優先級


💜SQL代碼優化:
/如果建立了WHERE子句中的屬性列的索引/,[NOT]BETWEEN … AND … 和 [NOT] IN將不會利用索引提高查詢效率,應改為多重條件查詢,效率會提高,如上例。(比較的效率更高)
4.3單表查詢–對查詢結果排序輸出
使用ORDER BY子句
● 可以按一個或多個屬性列排序
? 升序:ASC;
? 降序:DESC;
? 缺省值為升序
● 當排序列含空值時
? ASC:排序列為空值的元組最后顯示
? DESC:排序列為空值的元組最先顯示
(將空值作為最大值來理解)


4.4單表查詢–集函數
5類主要集函數:(默認為ALL)
(1) 計數
COUNT ([DISTINCT|ALL] *)
COUNT ([DISTINCT|ALL] <列名>)
(2) 計算總和
SUM ([DISTINCT|ALL] <列名>)
(3) 計算平均值
AVG ([DISTINCT|ALL] <列名>)
(4) 求最大值
MAX ([DISTINCT|ALL] <列名>)
(5) 求最小值
MIN ([DISTINCT|ALL] <列名>)




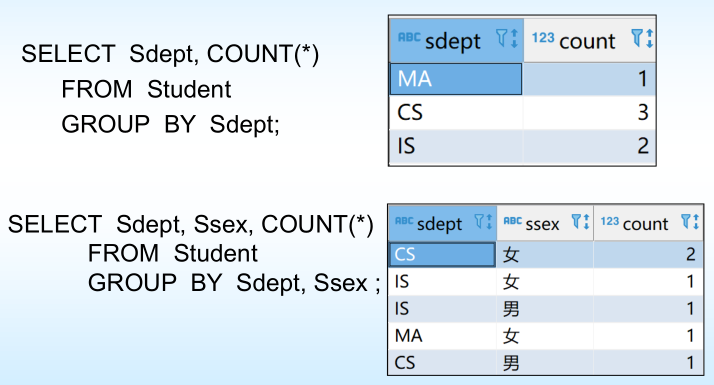
4.5單表查詢–對查詢結果分組輸出
使用GROUP BY子句分組
分組方法:按指定的一列或多列值分組 ,值相等的為一組;
執行順序:WHERE->GROUP BY->HAVING->SELECT
💥注意:使用GROUP BY子句后,SELECT子句的列名列表中只能出現分組屬性和集函數。



4.6連接查詢
? 連接查詢--將兩個(以上)表連接進行查詢
? 同時涉及多個表的查詢
? 連接查詢的意義等價于關系代數中的θ連接、等值連接和自然連接。

由于連接采用的是笛卡爾積,當數據非常大時,效率很低。
💥提高查詢效率的方法:
(1) 對表2按連接字段建立索引
(2) 對表1中的每個元組,依次根據其連接字段值查詢表2的索引,從中找到滿足條件的元組,找到后就將表1中的第一個元組與該元組拼接起來,形成結果表中一個元組。
4.6.1連接查詢–自身連接
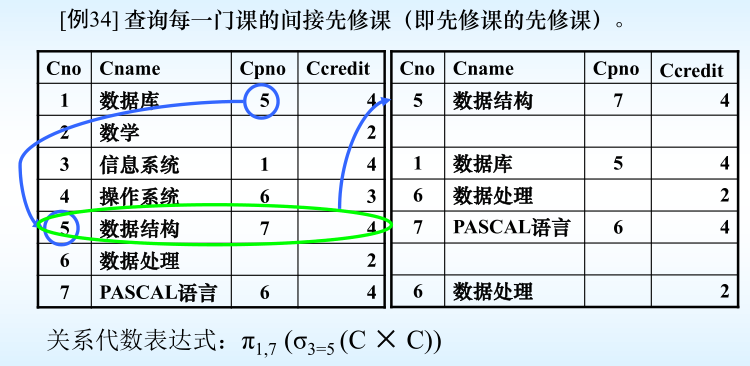

注:
(1) 一個表與其自己進行連接,稱為表的自身連接
(2) 需要給表起別名以示區別
(3) 由于所有屬性名都是同名屬性,因此必須使用別名前綴
?如何求一個課程的先修課的先修課的先修課?

4.6.2連續查詢–外連接
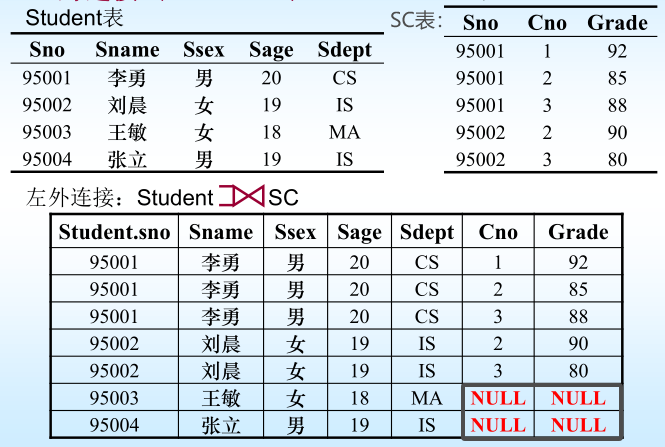

注:
(1)USING表示在兩個關系的某些同名列上進行連接
(2)右外連接:RIGHT OUTER JOIN
(3)全外連接:FULL OUTER JOIN
(4)內連接:INNER JOIN
4.6.3復合條件連接
WHERE子句中含多個連接條件


4.7嵌套查詢
4.7.1不相關子查詢
? 一個SELECT-FROM-WHERE語句稱為一個查詢塊;
? 將一個查詢塊嵌套在另一個查詢塊的WHERE子句或HAVING短語的條件中的查詢稱為嵌套查詢。

注:
? 子查詢的限制--不能使用ORDER BY子句,也沒有意義;
? 層層嵌套方式反映了SQL語言的結構化;
? 有些嵌套查詢可以用連接運算替代。

執行過程:
(1) 先執行子查詢,得到結果集{IS}
(2) 再執行父查詢WHERE Sdept IN {IS}
這種查詢稱為不相關子查詢,即子查詢的執行不依賴于父查詢的條件。

注意:內查詢是不相關子查詢
該查詢也可用連接來完成。
注:通常采用不相關子查詢的效率要優于連接查詢。

當能確切知道內層查詢返回單值時,可用比較運算符(>,<,=,>=,<=,!=或< >)。
注意:是不相關子查詢
注意:有些數據庫管理系統要求子查詢一定要跟在比較符之后!
4.7.2相關子查詢

此查詢的執行過程:
? (1)首先取外層查詢中表的第一個元組,將Sno值傳遞給內層查詢;
? (2)執行內層查詢,根據結果再執行外層查詢;
? (3)取外層表的下一個元組,重復這一過程,直至外層表全部檢查完為止。
這種查詢稱為相關子查詢,即子查詢的條件與父查詢當前值相關。
4.7.3帶有ANY或ALL謂詞的子查詢
謂詞語義:(1) ANY ( SOME ):某些值 (2) ALL:所有值
? > ANY
大于子查詢結果中的某個值
? > ALL
大于子查詢結果中的所有值
? < ANY
小于子查詢結果中的某個值
? < ALL
小于子查詢結果中的所有值
? >= ANY
大于等于子查詢結果中的某個值
? >= ALL
大于等于子查詢結果中的所有值
? <= ANY
小于等于子查詢結果中的某個值
? <= ALL
小于等于子查詢結果中的所有值
? = ANY
等于子查詢結果中的某個值
? =ALL
等于子查詢結果中的所有值(沒有實際意義)
? !=(或<>)ANY
不等于子查詢結果中的某個值
? !=(或<>)ALL
不等于子查詢結果中的任何一個值

執行過程
- 執行此查詢時,首先處理子查詢,找出IS系中所有學生的年齡,構成一個集合(19,18)
- 處理父查詢,找所有不是IS系且年齡小于19 或 18的學生
注意:是不相關子查詢


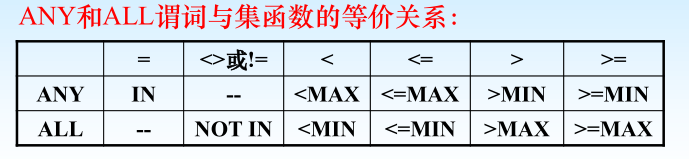
注:用集函數實現子查詢通常比直接用ANY或ALL查詢效率要高,因為前者通常能夠減少比較次數。
4.7.4帶有EXISTS謂詞的子查詢
? EXISTS謂詞的意義:
? 是存在量詞?在SQL中的應用;
? 帶有EXISTS謂詞的子查詢不返回任何數據,只產生邏輯真值“true”或邏輯假值“false”;
?若內層查詢結果非空,則返回真值
?若內層查詢結果為空,則返回假值
? 由EXISTS引出的子查詢,其目標列表達式通常都用* ,因為帶EXISTS的子查詢只返回真值或假值,給出列名無實際意義。


注: (1) 所有帶EXISTS或NOT EXISTS謂詞的子查詢能夠被其他形式的子查詢等價替換
(2)所有帶IN謂詞、比較運算符、ANY和ALL謂詞的子查詢都能用帶EXISTS謂詞的子查詢等價替換。
4.7.5用EXISTS/NOT EXISTS實現全稱量詞(難點)


💦上述詳細邏輯實現:
假設有張三和李四兩個學生,一共有ABC三門課,張三選了ABC,李四選了AC。
首先,從第一重查詢里選出張三,從第二重查詢里選擇A,在第三重查詢里判斷,第三重的WHERE返回true,進入第二重,經過NOT EXISTS,第二重的WHERE是false,接著,在第二重查詢里面選擇B,在第三重查詢里判斷,即判斷張三是否選擇了B,返回true,進入第二重,經過NOT EXISTS,第二重的WHERE是false,接著,在第二重查詢里面選擇C,在第三重查詢里判斷,返回true,進入第二重,經過NOT EXISTS,第二重的WHERE是false。現在,第二重的遍歷結束且WHERE語句全是false,故第二重返回false,經過第一重的NOT EXISTS ,第一重的WHERE語句是true,是true就立馬輸出,輸出張三的信息。
對于李四,從第一重查詢里選出李四,從第二重查詢里選擇A,在第三重查詢里判斷,第三重的WHERE返回true,進入第二重,經過NOT EXISTS,第二重的WHERE是false,接著,在第二重查詢里面選擇B,在第三重查詢里判斷,即判斷張三是否選擇了B,返回false,進入第二重,經過NOT EXISTS,第二重的EXISTS變成true,此時返回到第一重,經過NOT EXISTS變為false,不輸出李四,結束!!!
也就是說:當遇到true時會立即返回到上一重,到遇到false時,會接著在該重遍歷直到遇到true立馬返回或者遍歷結束全是false,返回false進行下一重的遍歷。
當遇到true,本重后面的遍歷就會結束掉,直接返回到上一重。



若95002選了ABC
張三:ABC
李四:AC
李五:D
上面的程序中,只要某個學生遍歷到和95002一樣的課就會結束(不輸出),只有李五輸出,即實現了輸出和與95002同學的課程沒有交集的的同學。

若95002選了ABC
張三:ABC
李四:AC
李五:D
上面的程序,實現了只要有一門與95002相同,就會輸出該學生。

若95002選了ABC
張三:ABC
李四:AC
李五:D
上面的程序,輸出李四和王五,實現了只要不選95002中的一門(只要不是ABC)就能輸出。
4.8集合查詢
💜 集合查詢--將兩個SELECT-FROM-WHERE查詢塊用集合操作語句聯結起來。
💜集合操作命令:
并操作(UNION)
交操作(INTERSECT)
差操作(EXCEPT)
💜語句形式:
<查詢塊>
操作
<查詢塊> ;
注:參加操作的各結果表的列數必須相同;對應項的數據類型也必須相同



4.9查詢注意事項
一、別名的使用
(1) 別名用于對輸出屬性列的重命名
(2) 別名用于自身連接查詢和對同一表的相關子查詢中,用于區別對同一表的不同引用

(3) 對不相關子查詢可以不使用別名

二、DISTINCT的使用
DISTINCT用于區分相同的記錄,將多條相同的記錄作為一條處理。

三、集函數的使用
集函數只能用于 SELECT子句和 HAVING短語之中,而絕對不能出現在 WHERE子句中。


四、GROUP BY的使用
使用了分組的查詢語句,其SELECT子句中只能出現分組屬性和集函數,而不能有在GROUP BY沒有出現的屬性。


五、ORDER BY子句在復合查詢中的應用
ORDER BY子句用于對查詢結果進行排序后再輸出,故只用于最外層的查詢,而子查詢中不應該出現ORDER BY子句。


六、輸出多個表的屬性的查詢
查詢的輸出只能取自最外層查詢所使用的表,對于子查詢中的屬性是不能作為最終的輸出的。如果輸出的屬性涉及多個表,則最外層查詢只能使用這些表的連接查詢。

5.數據更新
? 插入數據
? 修改數據
? 刪除數據
一、插入數據
(1) 插入單個元組--新元組插入指定表中。
語句格式:
INSERT
INTO <表名> [(<屬性列1>[,<屬性列2 >…)]
VALUES (<常量1> [,<常量2>] … ) ;
? INTO子句
? 指定要插入數據的表名及屬性列
? 屬性列的順序可與表定義中的順序不一致
? 沒有指定屬性列:表示要插入的是一條完整的元組,且屬性列屬
性與表定義中的順序一致
? 指定部分屬性列:插入的元組在其余屬性列上取空值
? VALUES子句
? 提供的值的個數和值的類型必須與INTO子句匹配
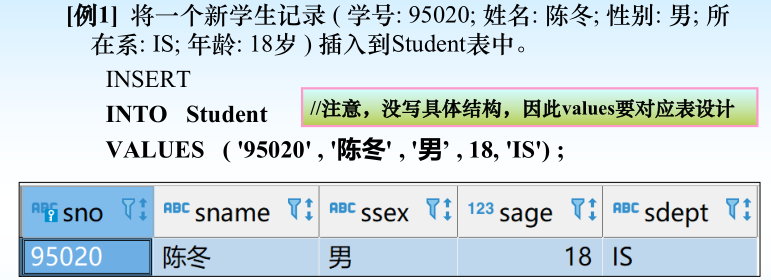

(2) 插入子查詢結果
語句格式:
INSERT
INTO <表名> [(<屬性列1> [,<屬性列2>… )]
子查詢;
注:
? INTO子句(與插入單條元組類似)
? 指定要插入數據的表名及屬性列
? 屬性列的順序可與表定義中的順序不一致
? 沒有指定屬性列:表示要插入的是一條完整的元組
? 指定部分屬性列:插入的元組在其余屬性列上取空值
? 子查詢
? SELECT子句目標列屬性的個數和類型必須與INTO子句匹配。

二、修改數據(用的比較少)
語句格式:
UPDATE <表名>
SET <列名>=<表達式>[, <列名>=<表達式>]…
[WHERE <條件>];
功能:
修改指定表中滿足WHERE子句條件的元組。
注:
? SET子句--指定修改方式,要修改的列和修改后取值
? WHERE子句
? 指定要修改的元組
? 缺省表示要修改表中的所有元組



三、刪除數據(較常用)
語句格式:
DELETE
FROM <表名>
[WHERE <條件>] ;
功能:
刪除指定表中滿足WHERE子句條件的元組
注:
WHERE子句
? 指定要刪除的元組
? 缺省表示要修改表中的所有元組





在執行插入、修改、刪除語句時會檢查是否會破壞表上已定義的完整性規則。如果破壞,系統會提示語句無效。
在建立表時,可以設置參照完整性:
? 不允許修改/刪除
? 級聯修改/刪除
定義SC的外碼Sno: //選課表記錄,受制于學生表
FOREIGN KEY (Sno) REFERENCES Student(Sno)
ON DELETE CASCADE ON UPDATE CASCADE;
6.空值
空值的產生:插入時不提供值、設為空值
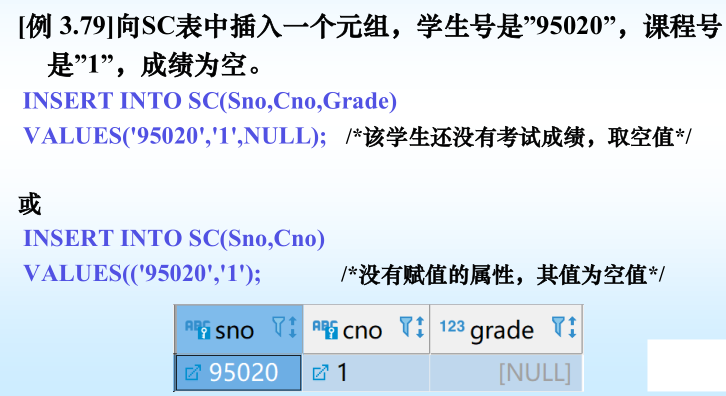

? 判斷一個屬性的值是否為空值,用IS NULL或IS NOT NULL來表示。

7.總結

8.視圖
8.1什么是視圖(View)?
😍視圖是從一個或幾個基本表(或視圖)導出的表,它與基本表不同,是一個虛表。
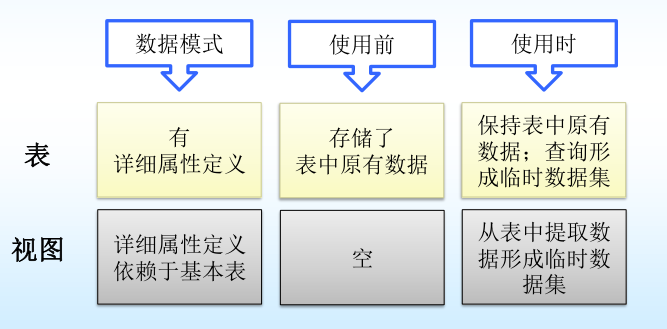
? 基表中的數據發生變化,從視圖中查詢出的數據也隨之改變。
? 視圖一經定義,就可以和基本表一樣被查詢和刪除,并且可以在視圖之上再定義新的視圖。
? 視圖的更新(增加、刪除、修改)操作會受到一定的限制。
? 視圖對應三級模式體系結構中的外模式。

8.2視圖定義
😴視圖定義語法:
CREATE VIEW <視圖名> [(<列名> [,<列名>]…)]
AS <子查詢>
[WITH CHECK OPTION];
😴CREATE VIEW 子句中的列名可以省略,此時視圖的屬性由子查詢中SELECT目標列中的諸字段組成。
😴子查詢中的屬性列不允許定義別名,不允許含有ORDER BY子句和DISTINCT短語。
😴執行CREATE VIEW語句時只是把視圖的定義存入數據字典,并不執行其中的SELECT語句。在對視圖進行查詢時,按視圖的定義從基本表中將數據查出(執行視圖定義中的SELECT語句)。
😴WITH CHECK OPTION表示對視圖進行更新操作的數據必須滿足視圖定義的謂詞條件(子查詢的條件表達式)。

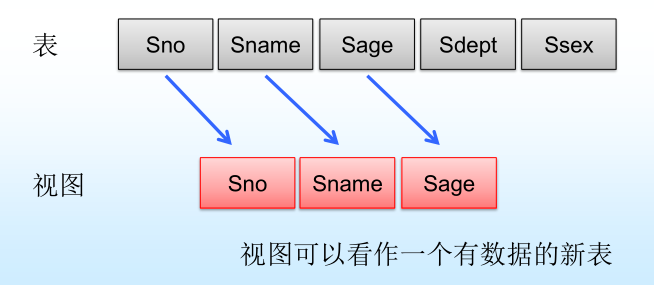

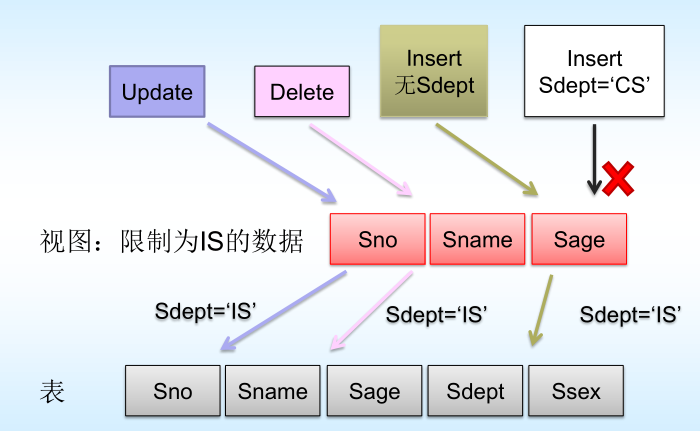
針對此視圖,當進行以下操作時,
? 修改操作:DBMS自動加上Sdept= 'IS’的條件
? 刪除操作:DBMS自動加上Sdept= ‘IS’的條件
? 插入操作:DBMS自動檢查Sdept屬性值是否為’IS’





8.3視圖的刪除
語法:
DROP VIEW <視圖名> [CASCADE] ;
注:
? 該語句從數據字典中刪除指定的視圖定義;
? 如果該視圖導出了其他視圖,則使用CASCADE級聯刪除,或者先顯式刪除導出的視圖,再刪除該視圖;

8.4視圖的查詢
此視圖查詢的方法:
(1) 視圖實體化法:
通過視圖定義建立視圖結構下的臨時表并對臨時表進行查詢,在查詢結束后刪除臨時表。
(2) 視圖消解法:
根據視圖定義將對視圖的查詢轉換為對基本表的查詢


8.5更新視圖
和基本表一樣,視圖定義之后也可以進行插入、刪除和修改操作。
(1) 用戶角度:更新視圖與更新基本表相同;
(2) 實現視圖更新的方法
? 視圖實體化法(View Materialization)
? 視圖消解法(View Resolution)
(3) 指定WITH CHECK OPTION子句后,在更新視圖時會進行檢查,防止用戶通過視圖對不屬于視圖范圍內的基本表數據進行更新。



一些視圖是不可更新的,因為對這些視圖的更新不能唯一地有意義地轉換成對相應基本表的更新(對兩類方法均如此)。
💜從理論上講,對其更新能夠唯一轉換為對應基本表更新的視圖是可更新的。

8.6視圖的作用–安全保護
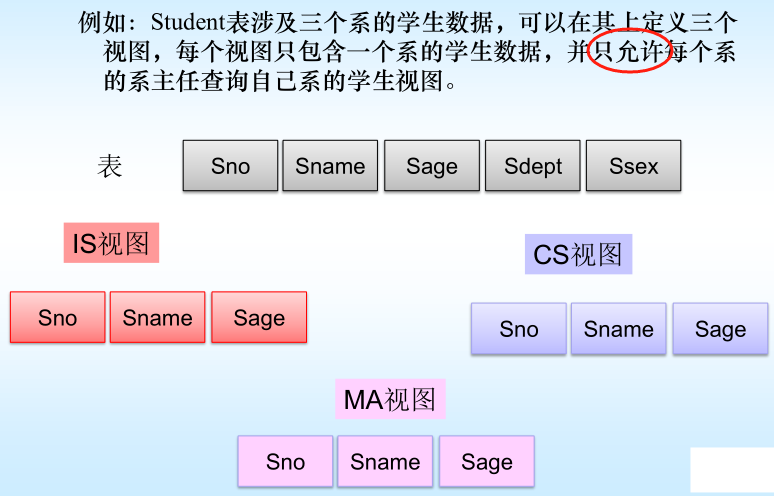










)








--Java版)