
【導讀】
應對氣候變化對非洲象的生存威脅,本研究創新采用無人機航拍結合AI姿態分析技術,突破傳統觀測局限。團隊在肯尼亞桑布魯保護區對比測試DeepLabCut與YOLO-NAS-Pose兩種模型,首次將后者引入野生動物研究。通過檢測象群頭部、脊柱等關鍵點(50像素分辨率),YOLO-NAS-Pose在RMSE、PCK、OKS等指標上全面超越實驗室常用工具,實現多目標行為動態解析。該技術突破為裂變-融合社會結構的大象群體行為研究提供高精度自動化解決方案,推動無人機生態監測在保護生物學中的應用進程。>>更多資訊可加入CV技術群獲取了解哦~

論文題目:
Whole-Herd Elephant Pose Estimation from Drone Data for Collective Behavior Analysis
論文鏈接:
https://arxiv.org/pdf/2411.00196
目錄
一、方法
數據集
千款模型+海量數據,開箱即用!
DeepLabCut工作流程
YOLO-NAS-Pose工作流程
性能評估
無需代碼,訓練結果即時可見!
從實驗到落地,全程高速零代碼!
二、實驗結果
三、討論
四、結論
一、方法
-
數據集
本研究采用配備廣角攝像頭的無人機技術觀測象群,確保單幀畫面可呈現整個群體。無人機數據采集帶來特定挑戰。"拯救大象"野外團隊在保證數據質量最大化的同時,盡可能減少對大象的干擾以捕捉真實行為。此前研究表明無人機會引發大象不同程度的反應。雖然更高分辨率數據更具優勢,但使用多架無人機可能改變大象自然行為。為此,無人機在肯尼亞允許的最高飛行高度(400英尺)進行操作,通過穩定云臺平臺以29幀/秒、3840×2160分辨率拍攝視頻。研究期間無人機固定于設定高度進行俯拍,確保視角統一。在該飛行高度下,視頻中幼象從鼻到尾約占8像素,成年象最多占70像素。圖1展示了無人機視頻的示例幀。

研究重點識別與社交行為相關的關鍵點,如頭部朝向和耳朵扇動等。因此選擇圖2所示的8個關鍵點作為姿態估計目標。
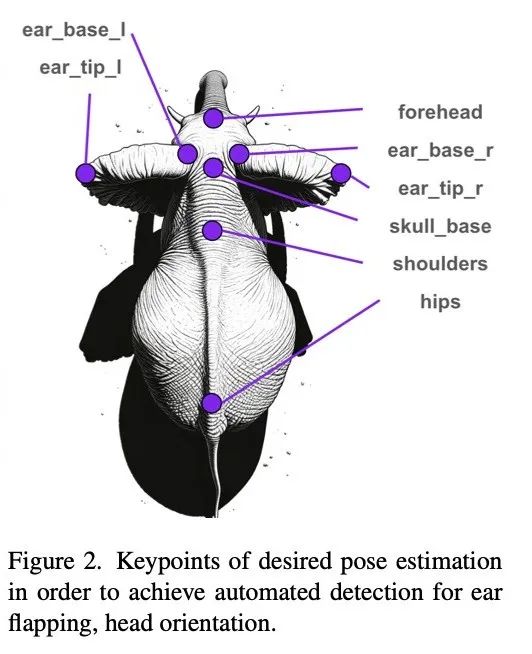
數據集包含23段視頻,每段約5分鐘時長。從中選取俯拍幀,最終得到包含1308頭大象的133幀圖像。基于這些幀創建了人工標注的訓練數據集,包括邊界框和圖2定義的關鍵點。標注時,對特別幼小的象崽若無法辨別耳朵,則僅標注脊柱關鍵點,耳朵標記為"遮擋"。
標注數據集按90-10-10比例劃分為訓練集-驗證集-測試集。測試集來自完全獨立的四段視頻,確保與訓練集和驗證集無視頻來源重疊。
-
千款模型+海量數據,開箱即用!
平臺匯聚國內外開源社區超1000+熱門模型,覆蓋YOLO系列、Transformer、ResNet等主流視覺算法。同時集成300+公開數據集,涵蓋圖像分類、目標檢測、語義分割等場景,一鍵下載即可投入訓練,徹底告別“找模型、配環境、改代碼”的繁瑣流程!

-
預處理
在進入任一工作流程之前,都要對數據進行預處理,以滿足 YOLOv5 模型對對象尺寸的要求。標記的視頻幀被平鋪為 800x800 像素,窗口間距有 33% 的重疊,以確保幀內大象有合適的對象尺寸。然后使用以下兩個工作流程對數據進行姿態估計。
-
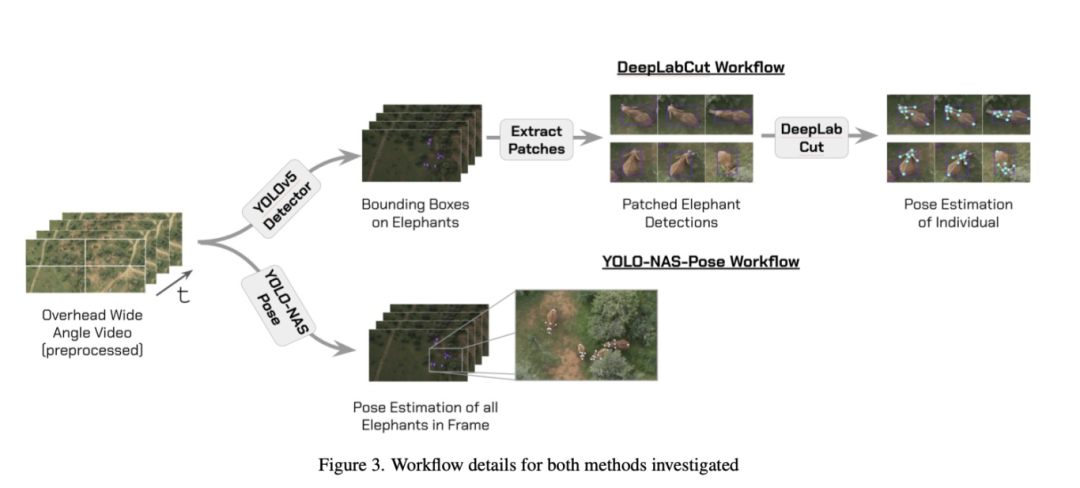
DeepLabCut工作流程
-
大象檢測器
首先采用YOLOv5模型和MegaDetector預訓練模型對前文定義的數據集進行微調。這些模型被訓練用于生成畫面中大象的邊界框。
當預測出邊界框后,以檢測框為中心截取正方形圖像,其邊長取邊界框最大尺寸增加20%余量。這些圖像塊隨后被調整為100×100像素。該格式用于訓練DeepLabCut,通過提供居中放大的動物圖像來消除背景不一致帶來的干擾。
-
DeepLabCut
使用姿態數據集訓練DeepLabCut模型。數據被轉換為DLC訓練格式,模型訓練80萬次迭代直至損失收斂。
-
YOLO-NAS-Pose工作流程
為了訓練 YOLO-NAS-Pose 網絡,使用了與訓練檢測器和 DeepLabCut 工作流程相同的數據集,并添加了手動注釋的姿勢。然后對模型進行訓練,以提供整個圖像的邊界框和姿勢。
-
性能評估
采用獨立測試集評估兩種工作流程。YOLOv5檢測器與YOLO-NAS-Pose的邊界框準確性通過平均精度均值(mAP)評估。兩種工作流程的姿態估計均采用均方根誤差(RMSE)、正確關鍵點百分比(PCK)和物體關鍵點相似度(OKS)進行評估。為保證公平比較,由于DeepLabCut僅能在提取的邊界框上進行姿態估計,評估時僅選取YOLO-NAS-Pose工作流程中正確檢測的邊界框。
為識別正確檢測目標,YOLO-NAS-Pose輸出的邊界框經非極大值抑制(NMS)處理,最大重疊閾值設為0.5。經過去重的邊界框按置信度排序后與真實標注計算交并比(IoU)。當預測框與真實標注框IoU≥0.5時視為候選匹配,若多個預測框對應同一真實框,則選取置信度最高者。
-
可視化視頻追蹤
雖然連續視頻并非訓練或定量評估的必要條件,但個體連續影像對定性評估大有助益。通過DeepSORT算法對每幀檢測個體生成追蹤視頻片段。該方法通過比較圖像塊位置、嵌入特征和物體運動動量來識別視頻中的連續目標。由于部分個體分辨率過低,本研究排除邊界框小于50像素的幼象,重點分析成年象行為。最終從訓練集、驗證集和測試集的原始視頻中提取25段視頻用于姿態估計評估。
如果你也想要使用模型進行訓練或改進,Coovally——新一代AI開發平臺,為研究者和產業開發者提供極簡高效的AI訓練與優化體驗!Coovally支持計算機視覺全任務類型,包括目標檢測、文字識別、實例分割、并且即將推出關鍵點檢測、多模態3D檢測、目標追蹤等全新任務類型。
-
無需代碼,訓練結果即時可見!
在Coovally平臺上,上傳數據集、選擇模型、啟動訓練無需代碼操作,訓練結果實時可視化,準確率、損失曲線、預測效果一目了然。無需等待,結果即訓即看,助你快速驗證算法性能!
-
從實驗到落地,全程高速零代碼!
無論是學術研究還是工業級應用,Coovally均提供云端一體化服務:
-
免環境配置:直接調用預置框架(PyTorch、TensorFlow等);
-
免復雜參數調整:內置自動化訓練流程,小白也能輕松上手;
-
高性能算力支持:分布式訓練加速,快速產出可用模型;
-
無縫部署:訓練完成的模型可直接導出,或通過API接入業務系統。
!!點擊下方鏈接,立即體驗Coovally!!
平臺鏈接:https://www.coovally.com
無論你是算法新手還是資深工程師,Coovally以極簡操作與強大生態,助你跳過技術鴻溝,專注創新與落地。訪問官網,開啟你的零代碼AI開發之旅!
二、實驗結果
在初始工作流程中發現,采用YOLOv5標準預訓練權重的檢測效果優于megadetector權重。邊界框檢測器的mAP指標如表1所示。

測試集的各項評估指標結果(包括各關鍵點及整體平均值)展示在表2。
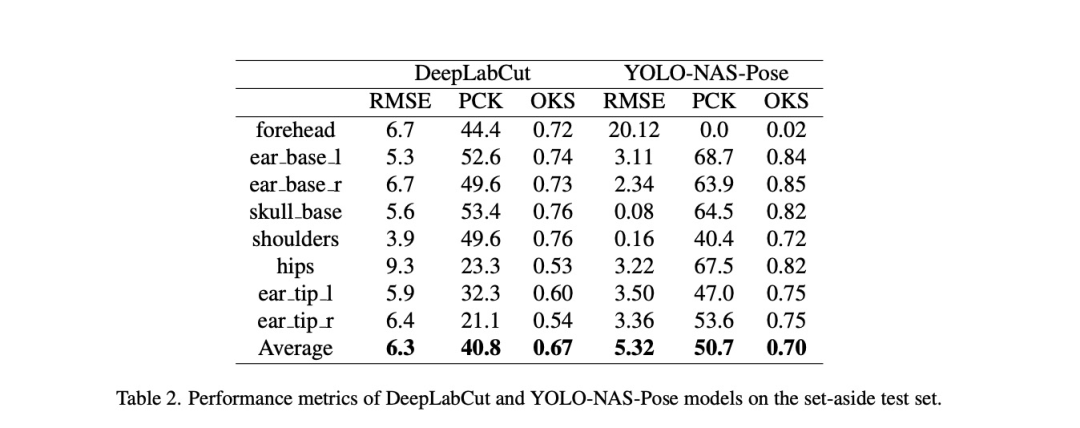
圖4展示了DeepLabCut在提取圖像塊上的應用效果。補充材料包含帶有姿態估計疊加的訓練驗證集追蹤視頻,既有效果良好的案例,也存在耳部檢測不準的情況——雖然脊柱對齊效果穩定,但在快速運動或非常規姿態時耳尖檢測容易出現偏差。

圖5展示了YOLO-NAS-Pose在單幀視頻中的定性結果。整體關鍵點標注準確,僅漏檢一只幼象,但"前額"關鍵點持續偏置于頭部后方。

三、討論
本研究開創了無人機視頻數據自動姿態估計在野生動物研究中的應用。實驗結果對野生動物行為監測的改進提供了重要啟示。
從表2指標可見,兩種模型在測試集均表現合理。YOLO-NAS-Pose在所有指標上均表現良好(雖未達完美),證明其作為野生動物行為研究工具的潛力。但當前精度尚未達到全自動化流程要求,仍需進一步優化。
需注意關鍵點準確度差異:DeepLabCut耳尖檢測精度較低(因其運動范圍大且標注置信度最低),但髖部成為最差關鍵點(可能因缺乏相鄰參考點)。這與YOLO-NAS-Pose形成反差——后者髖部表現最佳卻在前額關鍵點遇到困難(可能因象鼻伸展時難以定位面部)。未來將探究這些差異成因。
定性分析顯示,DeepLabCut整體表現良好,但存在耳部追蹤失敗(尤其在幼象上表現為默認"中立"耳姿)。值得注意的是,全幀多象姿態估計與個體圖像塊估計各有優勢:前者簡化工作流程利于自動化,后者通過篩選成年象可避免低分辨率幼象的干擾,且能平衡訓練集姿態分布。
雖然DeepLabCut未超越YOLO-NAS-Pose,但在小樣本場景(約100幀)仍具價值。這對標注數據有限但需快速獲取全視頻姿態的研究尤為重要。
展望未來,針對低分辨率姿態估計,通過分析視頻序列變化檢測復雜關鍵點是重要方向。單幀耳部定位的困難凸顯了當前逐幀估計的局限,后續可探索光流或循環神經網絡等跨幀分析方法來提升運動連續性檢測精度。
四、結論
這項研究通過比較不同的姿態估計技術,在將自動行為分析方法納入野生動物研究方面取得了重大進展。它為在自然棲息地對野生動物行為進行更復雜的研究鋪平了道路,這些研究涉及大范圍場景中的多個個體。研究結果表明,YOLO-NAS-Pose 是一種可行且有吸引力的姿態估計方法,它提供了簡單明了的工作流程和卓越的性能指標。不過,還需要進一步的開發和改進。這項工作的意義超出了對大象行為的研究,它為未來基于無人機的野生動物行為研究在不同物種和生態環境中的發展提供了寶貴的見解。









)








--Java版)
)