
TinyLUT: Tiny Look-Up Table for Efficient Image Restoration at the Edge(2024 NeurIPS)
- 專題介紹
- 一、研究背景
- 二、TinyLUT方法
- 2.1 Separable Mapping Strategy
- 2.2 Dynamic Discretization Mechanism
- 三、實驗結果
- 四、總結
本文將從頭開始對TinyLUT: Tiny Look-Up Table for Efficient Image Restoration at the Edge,這篇極致輕量化的LUT算法進行講解,這篇主要的亮點在于作者利用LUT去替代計算從而大幅減小了LUT的尺寸,在更小的尺寸下達到了更好的效果。參考資料如下:
[1]. TinyLUT論文地址
[2]. TinyLUT代碼地址
專題介紹
Look-Up Table(查找表,LUT)是一種數據結構(也可以理解為字典),通過輸入的key來查找到對應的value。其優勢在于無需計算過程,不依賴于GPU、NPU等特殊硬件,本質就是一種內存換算力的思想。LUT在圖像處理中是比較常見的操作,如Gamma映射,3D CLUT等。
近些年,LUT技術已被用于深度學習領域,由SR-LUT啟發性地提出了模型訓練+LUT推理的新范式。
本專題旨在跟進和解讀LUT技術的發展趨勢,為讀者分享最全最新的LUT方法,歡迎一起探討交流,對該專題感興趣的讀者可以訂閱本專欄第一時間看到更新。
系列文章如下:
【1】SR-LUT
【2】Mu-LUT
【3】SP-LUT
【4】RC-LUT
【5】EC-LUT
【6】SPF-LUT
【7】Dn-LUT
一、研究背景
TinyLUT從名字就可以看到,作者是做了一個極小尺寸的LUT算法,可以看下圖,作者畫出了TinyLUT與其他算法的尺寸效果對比圖。

圖中可以發現很多熟悉的面孔,包含專欄前面講到過的SRLUT、RCLUT、MuLUT、SPLUT以及SPFLUT,TinyLUT-S尺寸的優勢非常明顯,且效果是優于SRLUT以及SPLUT-S的,足以證明其策略對于尺寸壓縮的優勢,TinyLUT-F更是占據了最好的效果的同時,尺寸也是最小的。那么作者是如何做到這個效果的,主要是以下2個策略:
- 提出了Separable Mapping Strategy(分離映射策略)來解決因為LUT維度過大導致的尺寸爆炸問題。
- 設計了一種Dynamic Discretization Mechanism(動態離散化機制)來分解激活并壓縮相應的量化尺度,在不造成較大精度損失的情況下進一步縮小存儲需求。
作者通過很多實驗證明了這兩個策略訓練后的TinyLUT可以在最小存儲量的同時,比其他LUT方法的效果還要更好,展示了LUT-Based方法的潛力。
二、TinyLUT方法
TinyLUT網絡結構如下圖所示:

有以下2個重點:
- 輸入分為MSBs和LSBs,分別經過一樣的分支進行處理,這里可以發現整體結構跟專欄前面講到過的SPLUT是很相像的,當然作者會在這基礎上做了進一步的優化,后續會提到。
- 每一個支路由以下基礎模塊,3x3 Conv、PwBlock以及3x3 DwConv組合而成,最后將MSB和LSB進行一個相加并經過pixelshuffle層進行一個超分輸出。
前面提到的兩個策略會在這幾個模塊中體現出來,接下來會進行具體闡述。
2.1 Separable Mapping Strategy
一個老生常談的問題,以前的LUT方法例如SRLUT,感受野越大,尺寸會爆炸性增長,這個策略就是為了解決這個問題,如下表所示。

可以看到,一個2x2 pixels的RF,需要4D的LUT,如果采用Full size來存儲計算就是64GB=256 * 256 * 256 * 256 * 16 / 1024 / 1024 / 1024,而使用SRLUT的均勻采樣后也需要1.27MB=17 * 17 *17 * 17 * 16 / 1024 / 1024。若采用本文的SMS策略,則可以減到16KB。再加上DDM后會更小。
SMS策略包含兩個部分,分別是空間和通道的。
- 空間的SMS策略,如下圖所示:
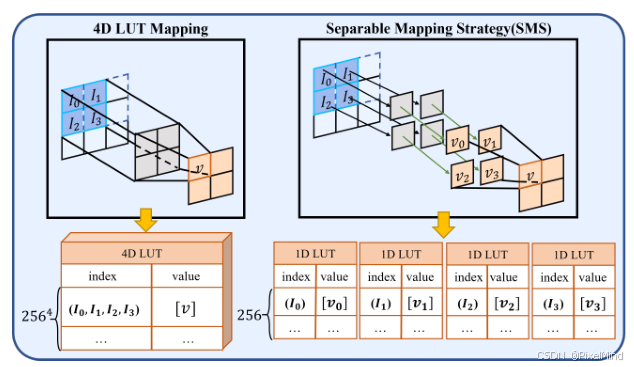
可以看到以前查詢一個窗口時通過直接查詢 I0 - I3 這4個點得到一個結果,這使得LUT維度太大,尺寸爆炸性增長(256^4),那作者就想換一個方式,先利用4個1D LUT查詢每個點對應的結果,然后再將這些結果進行相加,這樣我們發現就可以將LUT尺寸減小為(256*4)。博主認為,大家可以將SMS這個操作認為是將以前卷積計算的過程修改為一個LUT查找的過程,即用一次查找替換了一次乘法,以前LUT方法當然也是在用LUT替換計算,但其因為替換了更多的乘法和加法,因此需要更多的維度,也導致了尺寸爆炸增長。作者將這個過程用公式表示:
F ^ out? = 1 n 2 ∑ i = 0 n ? 1 ∑ j = 0 n ? 1 L U T ( i , j ) [ x ( i , j ) ] \hat{F}_{\text {out }}=\frac{1}{n^{2}} \sum_{i=0}^{n-1} \sum_{j=0}^{n-1} L U T_{(i, j)}\left[x_{(i, j)}\right] F^out??=n21?i=0∑n?1?j=0∑n?1?LUT(i,j)?[x(i,j)?]
這里的n代表窗口的尺寸,例如SRLUT就是n=2,可以發現SMS空間的策略是一個Depthwise Conv,只在空間維度上操作。
- 通道的SMS策略,作者設計了一個模塊叫PwBlock,如下圖所示。

通道的交互,原理跟空間上的是一樣的,在通道上我們仍然可以將查詢維度變成1D,然后再加起來模擬正常的點卷積。圖中可以看到有多個PwConv和ReLU串聯,那因為最后這個PwBlock要變成一堆1D LUT,那么我們就需要確保每次只處理一個輸入通道,相當于普通卷積設置groups參數為cin,如果此時cout=cin的話,就變成了我們熟悉的通道可分離卷積,最后的LUT查找過程跟空間上是大同小異的,公式如下所示:
F ^ out? = 1 C in? 2 ∑ c = 0 C in? L U T c [ x c ] \hat{F}_{\text {out }}=\frac{1}{C_{\text {in }}^{2}} \sum_{c=0}^{C_{\text {in }}} L U T_{c}\left[x_{c}\right] F^out??=Cin?2?1?c=0∑Cin???LUTc?[xc?]
可以看到一個輸出通道是由Cin個LUT相加得來,尺寸也從(256 ^ Cin * Cout * 8bit)變成了(256 * Cin * Cout * 8bit)。
2.2 Dynamic Discretization Mechanism
前面提到TinyLUT會做MSB和LSB的分離,這個策略就是針對這個地方進行更深度的優化。因為數據是8bit,范圍是[-128,127],當我們分成MSB和LSB時,MSB的范圍是[-m,m-1],LSB的范圍是[0,k](LSB是無符號的原因是MSB拿到了符號位),那我們可以根據MSB和LSB來推理出此時LUT的尺寸。
S i z e ( M S B ) = ( 2 ? m ) ? n 2 ? r 2 Size(MSB)=(2*m)*n^{2}*r^{2} Size(MSB)=(2?m)?n2?r2 S i z e ( L S B ) = ( k + 1 ) ? n 2 ? r 2 Size(LSB)=(k+1)*n^{2}*r^{2} Size(LSB)=(k+1)?n2?r2
自然,尺寸這么計算的原因是因為MSB和LSB范圍分別是2*m和k+1,然后我們再乘以kernel_size(n)和放大倍數(r)。這么一分析我們也能明白,分離能夠將LUT尺寸減小的原因在于輸入索引的范圍減小了,為進一步優化,作者引入可學習裁剪參數 α \alpha α 以縮小范圍為了進一步對其進行優化,公式如下所示:
F q = r o u n d ( F ? α y ) F_q=round(F*\alpha_{y}) Fq?=round(F?αy?),其中 α y \alpha_{y} αy?是一個放縮的系數,當我們減小F(MSB或LSB)時,自然可以進一步減小尺寸,尺寸可以減小至下列公式所示大小: S i z e = ( m a x ( F q ) ? m i n ( F q ) ) ? n 2 ? r 2 Size=(max(F_q)-min(F_q))*n^2*r^2 Size=(max(Fq?)?min(Fq?))?n2?r2計算邏輯跟上面一致,作者還用了一個圖來描述這個過程。

可以看到MSB開始是6bit,使用 α m \alpha_m αm?之后可以被壓縮,因為壓縮了,自然LUT的尺寸就減小了,多個index對應的其實是一個value,且這個過程是單調的,可以作為一個LUT的index保存。作者提到這個優化手段會使用 α \alpha α為0.8的初值,且在后期的優化過程中,使用L2正則去控制它的大小,自然越小會有更強的壓縮比。
博主這里的想法:使用這種壓縮方法會不會使得查詢過程引入更多的計算,因為 α \alpha α的存在雖然儲存量增加微乎其微,但需要去對原始index做一個放縮從而找到放縮后的index,這個地方可能會引入多余的計算,在代碼講解的地方可以驗證。
三、實驗結果
定量的實驗結果顯示:TinyLUT在LUT方法中效果是最具有性價比的,無論是效果上還是耗時和內存占用上。
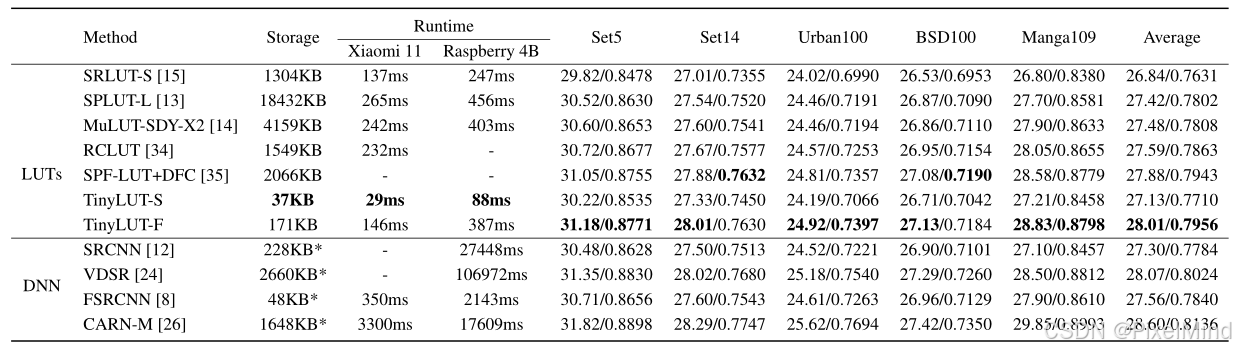
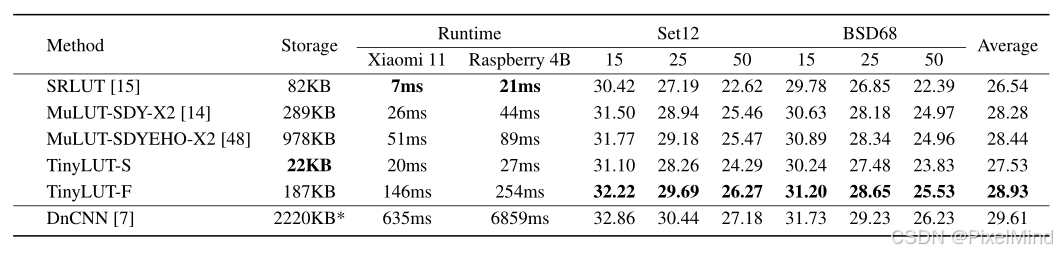
定性的實驗結果顯示,結論是一致的,強于FSRCNN,在LUT中是最具有性價比的。

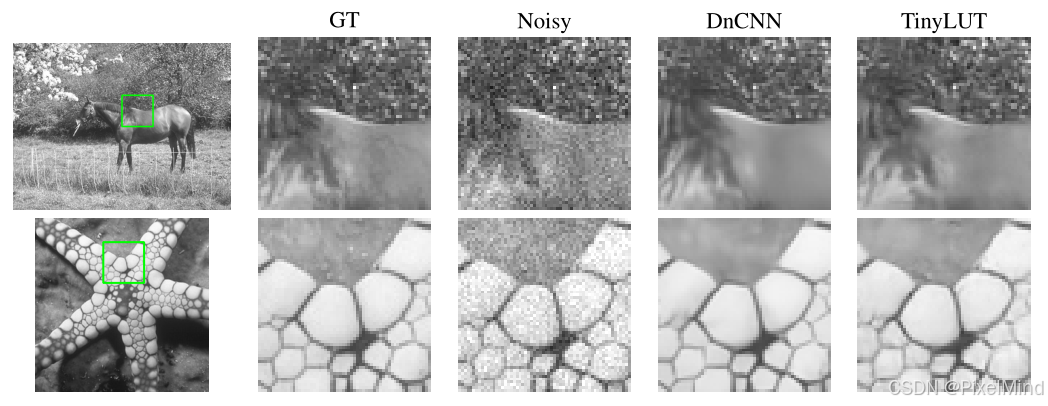
接下來作者進行了消融實驗:
1)SMS的消融實驗:

SMS策略的有效性證明,作者對比了SMS與不壓縮和均勻壓縮的效果,顯然優勢很明顯,效果逼近不壓縮的結果,但是LUT Size是最小的。
2)DDM的消融實驗:

作者對比了使用前后的指標,基本沒變化,但是LUT size進一步減小了,所以是非常有效的。進一步的,作者使用了一個圖來說明DDM的優勢。

圖中,紅線顯示的MSB 6bit的范圍,自然是64,TinyLUT-S- α \alpha α是學習的范圍,TinyLUT-S-E是實際數據所在的范圍,可以基本學習到的可以包圍數據的范圍,說明學習到的 α \alpha α對激活數據的精度進行了自適應的調整,減小了輸入數據的范圍,自然就減小了LUT的大小,做到了物盡其用,空間沒有浪費,因此可以做到無損的減小LUT尺寸。
四、總結
TinyLUT的方法相當于做了LUT實現的卷積網絡,配合上原有的一些量化知識和技巧對其繼續做了容量的削減,整體做了深度的優化,從指標上也能看到優勢是非常明顯的,可以期待下作者后續是否可以繼續擴大尺寸或者擴展到其他新型結構上(transformer或mamba),這點在文章的limitations一節也有提到。
代碼部分將會單起一篇進行解讀。(未完待續)
感謝閱讀,歡迎留言或私信,一起探討和交流,如果對你有幫助的話,也希望可以給博主點一個關注,謝謝。






ModalAI VOXL)









】)


