上一篇,我們已經知道機器學習是將輸入(比如圖像)映射到目標(比如數字“4”)的過程。這一過程是通過觀察許多輸入和目標的示例來完成的。
我們還知道,深度神經網絡通過一系列簡單的數據變換(層)來實現這種輸入到目標的映射,這些數據變換都是通過觀察示例學習得到的。
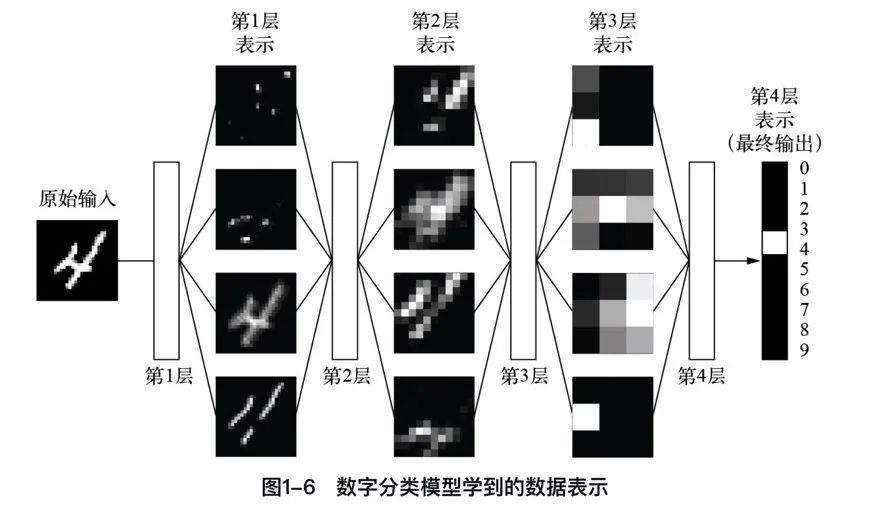
下面我們通過三張圖來具體看一下這種學習過程是如何發生的,即深度學習的工作原理是什么。
一、權重和參數
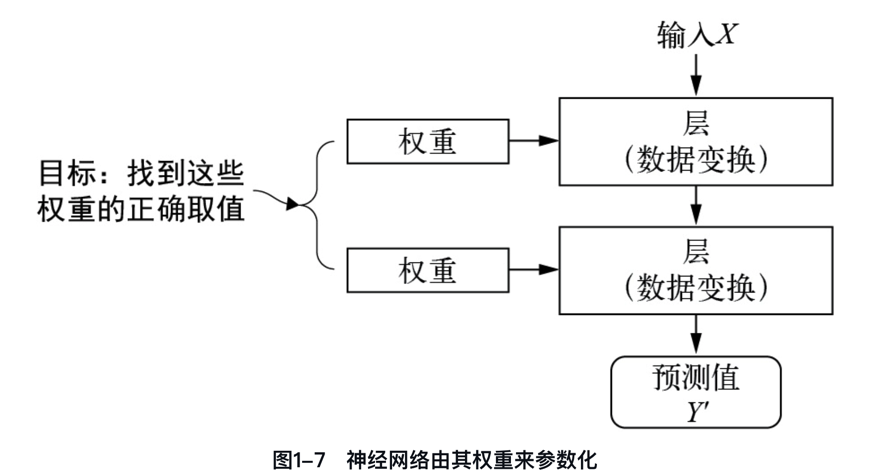
如何理解神經網絡由其權重來參數化?神經網絡由其權重參數化,意味著權重決定了網絡如何處理輸入數據并產生輸出,且這些權重通過訓練過程進行調整以優化網絡性能。
深度學習中的“學習”的意思就是為神經網絡的所有層找到一組權重值,使得該神經網絡能夠將每個示例的輸入與其目標正確地一一對應。
“一圖 + 一句話”徹底搞懂什么是權重和參數。
“在神經網絡中,每層對輸入數據所做的具體操作保存在該層的權重(weight)中,權重實質上就是一串數字。權重有時也被稱為該層的參數(parameter)。”
二、損失函數
如何使用損失函數尋找神經網絡的參數?一個深度神經網絡可能包含上千萬個參數(GPT-3參數有1750億),找到所有參數的正確取值似乎是一項非常艱巨的任務,特別是考慮到修改一個參數值將影響其他所有參數的行為。
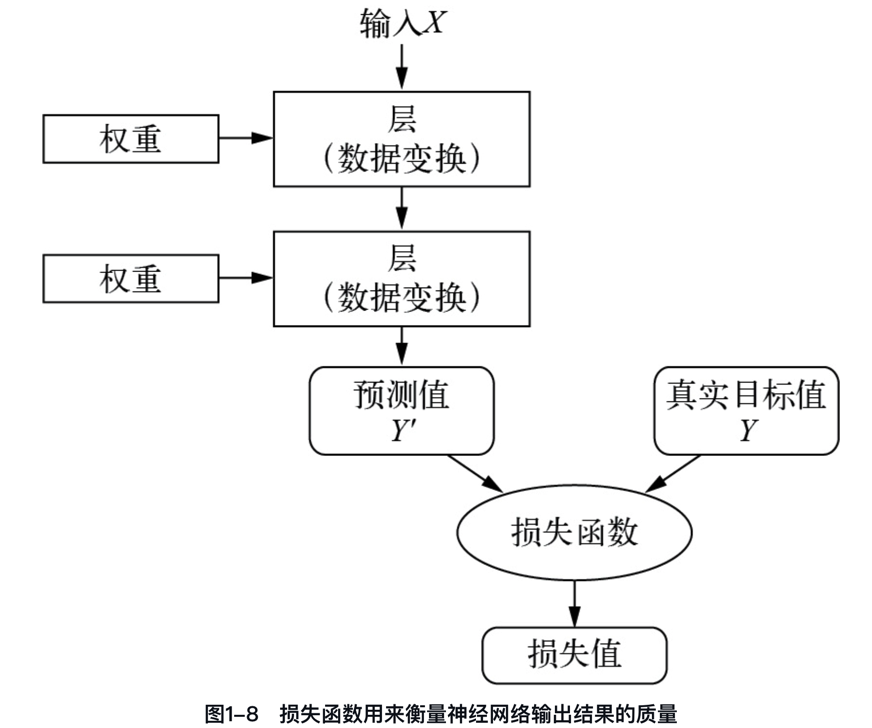
若要控制某個事物,首先需要能夠觀察它。若要控制神經網絡的輸出,需要能夠衡量該輸出與預期結果之間的距離。
損失函數如何衡量神經網絡輸出結果的質量?損失函數衡量神經網絡預測與真實目標之間的距離,用于評估網絡效果并指導控制輸出。
“一圖 + 一句話”徹底搞懂什么是損失函數。
“損失函數的輸入是神經網絡的預測值與真實目標值(你希望神經網絡輸出的結果),它的輸出是一個距離值,反映該神經網絡在這個示例上的效果好壞。”
三、優化器和反向傳播
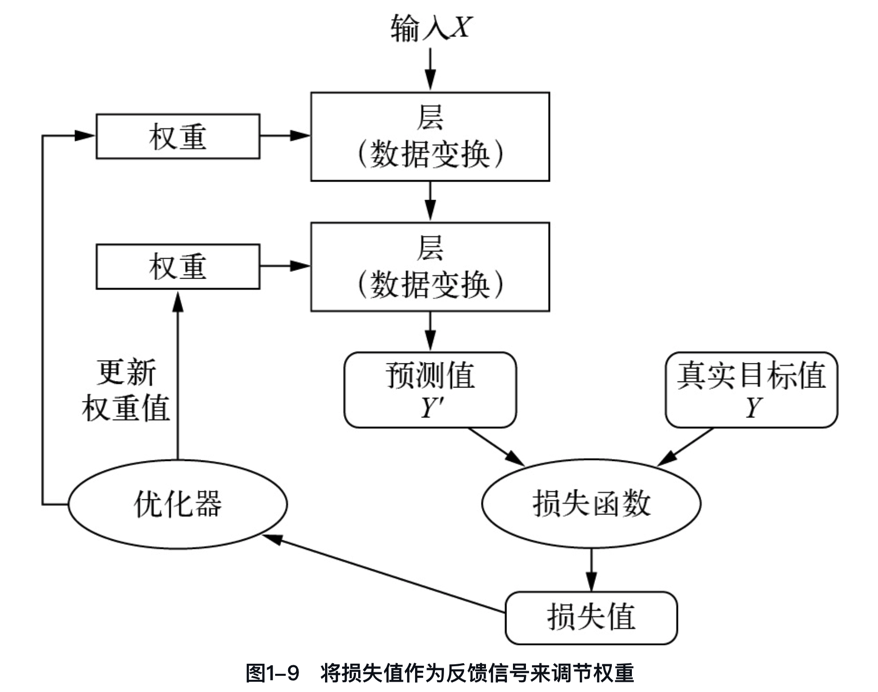
如何使用優化器和反向傳播將損失值作為反饋信號來調節權重?深度學習的核心技巧是利用損失值作為反饋,通過優化器和反向傳播算法微調權重,以降低損失并改進模型性能。
一開始神經網絡的權重是隨機賦值,因此神經網絡僅實現了一系列隨機變換,其輸出值自然與理想結果相去甚遠,相應地,損失值也很大。但是,神經網絡每處理一個示例,權重值都會向著正確的方向微調,損失值也相應減小。
“一圖 + 一句話”徹底搞懂什么是優化器和反向傳播。
“優化器和反向傳播通過迭代調整神經網絡權重,最小化損失函數,使輸出值接近目標值,實現網絡訓練。”
資料分享
為了方便大家學習,我整理了一份100G人工智能學習資料
包含數學與Python編程基礎、深度學習+機器學習入門到實戰,計算機視覺+自然語言處理+大模型資料合集,不僅有配套教程講義還有對應源碼數據集,更有零基礎入門學習路線,不論你處于什么階段,這份資料都能幫助你更好地入門到進階。
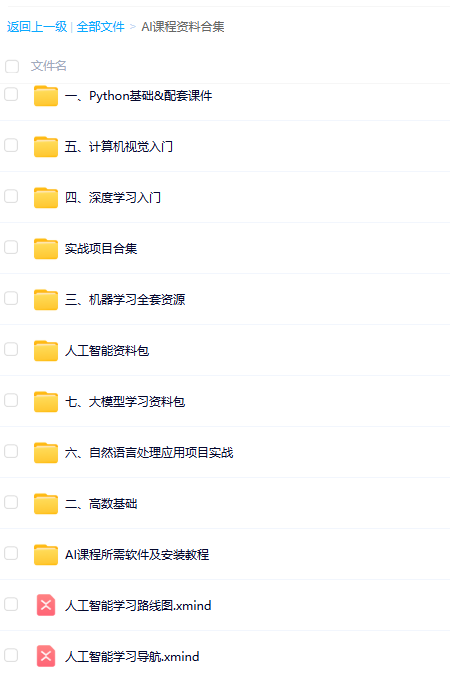
需要的兄弟可以按照這個圖的方式免費獲取







】)




Canvas基礎(萬字圖文講解))

)

)


