Kafka:Java開發的消息神器,你真的懂了嗎?
一、Kafka 是什么鬼?
想象一下,你在網上瘋狂剁手后,滿心期待著快遞包裹的到來。這時候,快遞站就像是 Kafka,而你的包裹就是消息。快遞站接收來自不同商家(生產者)的包裹,然后等待你(消費者)去取。Kafka 和快遞站類似,它是一個分布式消息系統,負責接收、存儲和轉發消息,在不同的應用程序之間傳遞數據。
Kafka 是由 Apache 軟件基金會開發的一個開源的分布式流處理平臺 ,最初是由 LinkedIn 公司開發,后來捐贈給了 Apache。它的誕生,解決了大數據時代數據傳輸和處理的難題,就像給數據世界搭建了一條超級高速公路,讓數據能夠快速、高效地流通。
在大數據的世界里,數據就像洶涌的潮水,源源不斷地產生。網站的訪問日志、用戶的操作記錄、傳感器采集的數據…… 這些數據需要被收集、傳輸和處理。Kafka 就像是一個超級數據管道,能夠高效地處理海量數據的傳輸和分發,在大數據處理、日志收集、實時數據處理、消息隊列等場景中發揮著重要作用。
二、Kafka 的特性,為啥這么牛?
(一)高吞吐量,海量消息輕松應對
Kafka 的高吞吐量就像是一個超級大胃王,能夠輕松吃下海量的消息。它每秒可以處理幾十萬條消息,這得益于它的分布式架構和獨特的設計。比如在電商大促期間,大量的訂單消息、用戶行為消息如潮水般涌來,Kafka 就像一個不知疲倦的搬運工,能夠快速地將這些消息接收并存儲起來,為后續的處理提供保障。
Kafka 的生產者在發送消息時,并不是一條一條地發送,而是將多條消息收集起來組成一個批次(batch)一起發送,這樣就減少了網絡開銷,大大提高了發送效率 。就好比你去超市買東西,如果每次只買一件商品,那來回跑的次數就多,效率也低;但如果把需要的東西一次性都買齊,裝在一個大袋子里帶回去,就能節省很多時間和精力。Kafka 的批量發送就類似這個道理。
另外,Kafka 使用磁盤順序讀寫來提升性能 。傳統的磁盤隨機讀寫就像是在一個大圖書館里隨機找一本書,需要花費很多時間在書架間穿梭尋找;而順序讀寫則像是按照書架編號依次取書,速度就快多了。Kafka 的消息是不斷追加到本地磁盤文件末尾的,這種順序寫入方式極大地提高了寫入吞吐量。再加上 Kafka 使用了頁緩存(pageCache),它把盡可能多的空閑內存當作磁盤緩存使用,進一步提高了 I/O 效率。生產者把消息發到 broker 后,數據先進入 PageCache,然后再由內核中的處理線程采用同步或異步的方式定期刷盤至磁盤 。消費者消費消息時,也會先從 PageCache 獲取消息,獲取不到才會去磁盤讀取,并且還會預讀出一些相鄰的塊放入 PageCache,方便下一次讀取。如果 Kafka producer 的生產速率與 consumer 的消費速率相差不大,那么幾乎只靠對 broker PageCache 的讀寫就能完成整個生產和消費過程,磁盤訪問非常少,這就大大提高了吞吐量。
對比其他消息系統,比如 ActiveMQ,它在處理高并發消息時,吞吐量就遠不如 Kafka。ActiveMQ 主要側重于傳統的消息隊列應用場景,在設計上沒有像 Kafka 那樣針對高吞吐量進行優化,所以當面對海量消息時,就容易出現性能瓶頸。而 Kafka 憑借其出色的設計,在高并發場景下表現得游刃有余,成為了大數據處理領域的寵兒。
(二)低延遲,消息傳輸快如閃電
Kafka 的低延遲特性就像是閃電俠,能夠以極快的速度傳輸消息。它的消息傳遞延遲極低,通常在毫秒級別,這使得它能夠滿足實時性要求較高的業務場景,比如股票交易、實時監控等。
Kafka 實現低延遲的原理主要有以下幾點:首先,前面提到的順序讀寫和頁緩存機制不僅提高了吞吐量,也對降低延遲起到了重要作用。因為順序讀寫和利用頁緩存可以快速地讀取和寫入消息,減少了 I/O 等待時間 。其次,Kafka 采用了零拷貝技術。在傳統的數據傳輸過程中,數據通常需要在用戶空間和內核空間之間多次拷貝,這就像在不同的房間之間來回搬運東西,會消耗大量的時間和精力。而零拷貝技術通過優化數據傳輸路徑,減少了數據在用戶空間和內核空間之間的多次拷貝,直接在內核空間完成數據的傳輸,大大提高了數據傳輸的速度,降低了延遲。
以股票交易系統為例,股票價格的變化瞬息萬變,每一秒的價格波動都可能影響投資者的決策。在這樣的場景下,Kafka 可以快速地將股票交易數據從數據源傳輸到各個交易終端和分析系統,讓投資者能夠及時獲取最新的股票價格信息,做出準確的交易決策。如果消息傳輸延遲過高,投資者可能會因為無法及時獲取價格信息而錯過最佳的交易時機,造成經濟損失。而 Kafka 的低延遲特性就為股票交易系統提供了可靠的保障,確保了交易的及時性和準確性。
(三)持久化,數據安全有保障
Kafka 就像是一個可靠的保險柜,會將消息持久化到磁盤上,確保數據的安全,即使在系統故障時也能恢復數據。這對于很多對數據可靠性要求極高的場景來說,是非常重要的。
Kafka 將消息存儲在分區(Partition)中,每個分區是一個有序的、不可變的消息序列 。分區可以分布在不同的服務器上,實現數據的分布式存儲和負載均衡。每個分區都有一個對應的日志文件,消息以追加的方式順序寫入日志文件 。這種順序寫入的方式不僅提高了寫入性能,也保證了消息的順序性。
為了進一步確保數據的可靠性,Kafka 采用了副本機制 。每個分區可以有多個副本,其中一個副本為主副本(Leader),其他副本為從副本(Follower)。主副本負責接收和處理生產者發送的消息,并將消息同步到從副本。從副本會定期從主副本拉取消息,以保持與主副本的同步。如果主副本出現故障,Kafka 會自動從從副本中選舉一個新的主副本,保證系統的高可用性和數據不丟失。
例如,在一個電商的訂單系統中,訂單數據是非常重要的業務數據,不能有任何丟失。Kafka 作為消息隊列,將訂單消息持久化存儲,即使在某個服務器出現硬件故障或者軟件異常的情況下,通過副本機制,其他副本服務器上仍然保存著完整的訂單消息。當故障恢復后,系統可以從這些副本中恢復數據,保證訂單處理的完整性,不會因為系統故障而導致訂單丟失或數據不一致的情況發生。
(四)可擴展性,隨時應對業務增長
Kafka 的可擴展性就像是一個可以無限拼接的積木城堡,能夠隨時根據業務的增長進行擴展。它的集群可以通過添加節點實現水平擴展,輕松應對不斷增長的業務量。
Kafka 采用分布式架構,由多個 Broker 組成集群 。每個 Broker 負責存儲一部分 Topic 的 Partition 數據,并處理來自 Producer 和 Consumer 的請求。當業務量增加,現有的集群處理能力不足時,只需要簡單地添加新的 Broker 節點,就可以增加集群的處理能力和存儲容量。Kafka 會自動將新的分區分配到新添加的節點上,實現負載均衡。
比如一個短視頻平臺,隨著用戶數量的快速增長,每天產生的視頻上傳、點贊、評論等消息量也呈爆發式增長。如果一開始使用的 Kafka 集群規模較小,當消息量超出集群的處理能力時,就可以通過添加新的 Broker 節點來擴展集群。新添加的節點會自動參與到消息的存儲和處理中,與原有的節點一起協同工作,共同應對大量的消息處理需求。這樣,短視頻平臺就可以在不影響用戶體驗的前提下,輕松應對業務增長帶來的挑戰,保證系統的穩定運行。
三、Kafka 架構大揭秘
(一)核心組件介紹
1. Producer:消息的源頭
Producer 就像是一個勤勞的快遞員,負責生產消息并將它們發送到 Kafka 集群中。在實際應用中,Producer 可以是各種產生數據的應用程序,比如電商系統中的訂單生成模塊,每產生一個新訂單,就會作為一條消息由 Producer 發送到 Kafka 集群。
在 Java 中使用 Kafka Producer 發送消息,首先需要引入 Kafka 的客戶端依賴。如果使用 Maven 項目,可以在pom.xml文件中添加如下依賴:
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.5.1</version>
</dependency>
然后編寫發送消息的代碼:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {// Kafka集群地址String bootstrapServers = "localhost:9092";// 創建KafkaProducer配置Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);// 鍵的序列化器props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 值的序列化器props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 創建KafkaProducer實例KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 要發送的消息String topic = "my-topic";String key = "key1";String value = "Hello, Kafka!";// 創建ProducerRecord對象ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);// 發送消息,這里使用異步發送,并添加回調函數處理結果producer.send(record, (metadata, exception) -> {if (exception == null) {System.out.printf("Message sent to topic %s partition %d offset %d%n",metadata.topic(), metadata.partition(), metadata.offset());} else {System.out.println("Failed to send message: " + exception.getMessage());}});// 關閉生產者producer.close();}
}
在這段代碼中,首先配置了 Kafka 集群的地址以及消息鍵和值的序列化器 。然后創建了KafkaProducer實例,并構建了一個ProducerRecord對象,包含要發送到的主題、消息的鍵和值。最后使用producer.send方法異步發送消息,并通過回調函數處理消息發送的結果。如果發送成功,會打印出消息發送到的主題、分區和偏移量;如果發送失敗,則會打印出錯誤信息。
2. Consumer:消息的接收者
Consumer 就像是等待收快遞的你,從 Kafka 集群中拉取消息進行消費處理。在實際場景中,Consumer 可以是數據分析系統,從 Kafka 集群中獲取用戶行為數據進行分析;也可以是訂單處理系統,獲取訂單消息進行后續的訂單處理流程。
在 Kafka 中,消費者是以消費組(Consumer Group)的形式工作的 。每個消費組會消費一個或多個主題的消息,并且 Kafka 會確保同一個消費組內,來自同一分區的消息只會被組內的一個消費者消費 。這樣就實現了負載均衡和高并發處理。比如有一個電商的訂單處理系統,有多個訂單處理模塊作為消費者組成一個消費組,Kafka 會將訂單消息分區后,分配給消費組內的不同消費者進行處理,提高訂單處理的效率。
下面是使用 Java 實現 Kafka Consumer 的代碼示例:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class KafkaConsumerExample {public static void main(String[] args) {// Kafka集群地址String bootstrapServers = "localhost:9092";// 消費組IDString groupId = "my-group";// 創建KafkaConsumer配置Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);// 鍵的反序列化器props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 值的反序列化器props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 當沒有初始偏移量或當前偏移量無效時,從最早的消息開始消費props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");// 創建KafkaConsumer實例KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 訂閱主題String topic = "my-topic";consumer.subscribe(Collections.singletonList(topic));try {while (true) {// 拉取消息,設置超時時間為100毫秒ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("Consumed message with key: %s, value: %s, partition: %d, offset: %d%n",record.key(), record.value(), record.partition(), record.offset());}}} finally {// 關閉消費者consumer.close();}}
}
在這段代碼中,首先配置了 Kafka 集群地址、消費組 ID 以及消息鍵和值的反序列化器 。然后創建了KafkaConsumer實例,并使用consumer.subscribe方法訂閱了指定的主題。在一個無限循環中,通過consumer.poll方法拉取消息,設置超時時間為 100 毫秒 。每次拉取到消息后,遍歷消息記錄并打印出消息的鍵、值、分區和偏移量。最后在程序結束時關閉消費者。
3. Broker:消息的存儲和管理者
Broker 是 Kafka 集群中的服務器,就像是快遞站的倉庫,負責存儲消息、響應生產者和消費者的請求。一個 Kafka 集群通常由多個 Broker 組成,它們共同協作,實現了 Kafka 的分布式特性和高可用性。
每個 Broker 都存儲了部分主題的分區數據,并且以日志文件的形式將消息持久化存儲在磁盤上 。當生產者發送消息時,Broker 會接收消息并將其追加到相應的分區日志文件中;當消費者請求消息時,Broker 會從對應的分區日志文件中讀取消息并返回給消費者。
Broker 之間也會進行通信和協作,比如在副本同步過程中,從副本(Follower)會定期向主副本(Leader)拉取消息,以保持與主副本的同步。如果主副本所在的 Broker 出現故障,Kafka 會通過選舉機制從從副本中選出一個新的主副本,確保系統的正常運行和數據的可用性。
例如,在一個分布式的日志收集系統中,多個應用服務器產生的日志消息由 Producer 發送到 Kafka 集群的不同 Broker 上存儲。當數據分析系統需要分析這些日志時,作為 Consumer 向 Broker 請求日志消息,Broker 會根據請求返回相應的日志數據。
4. Topic:消息的分類標簽
Topic 是消息的邏輯分類,就像是快遞站按照不同的收件地址對包裹進行分類一樣。每個消息都屬于某個 Topic,生產者在發送消息時需要指定消息所屬的 Topic,消費者在訂閱消息時也需要指定要消費的 Topic。
在實際應用中,不同的業務場景可以使用不同的 Topic 來區分消息。比如在一個電商系統中,可以創建 “order-topic” 用于存儲訂單相關的消息,“user-behavior-topic” 用于存儲用戶行為相關的消息。這樣可以方便地對不同類型的消息進行管理和處理。
例如,當用戶在電商平臺上下單時,訂單信息會作為一條消息發送到 “order-topic” 中;而用戶的瀏覽商品、添加購物車等行為數據會發送到 “user-behavior-topic” 中。不同的消費者可以根據自己的需求訂閱相應的 Topic 進行消息消費。
5. Partition:Topic 的物理分割
Partition 是 Topic 的物理分區,就像是將一個大的快遞區域劃分成多個小的分區來進行管理。每個 Topic 可以包含多個 Partition,通過分區機制,Kafka 可以實現數據的分片存儲和并行處理,從而提高系統的吞吐量和性能。
每個 Partition 是一個有序的、不可變的消息日志,消息按照追加的方式寫入 Partition 。并且每個 Partition 都有一個唯一的標識符,稱為分區 ID。生產者在發送消息時,可以根據一定的分區策略將消息發送到指定的 Partition 中。比如可以根據消息的鍵進行哈希計算,然后根據哈希值將消息分配到相應的 Partition,這樣可以保證具有相同鍵的消息總是發送到同一 Partition 中,從而實現分區內消息的順序性。
消費者在消費消息時,一個消費組內的多個消費者可以分別消費不同的 Partition,實現并行消費。例如,在一個大數據處理場景中,有一個包含大量用戶行為數據的 Topic,通過將其劃分為多個 Partition,可以讓多個消費者同時從不同的 Partition 中消費數據,大大提高數據處理的速度。
6. Replica:數據備份保障
Replica 是 Partition 的副本,就像是給每個快遞包裹都準備了備份,用于保證數據的高可用性和容錯性。每個 Partition 可以有多個副本,其中一個副本為主副本(Leader),其他副本為從副本(Follower)。
主副本負責處理生產者和消費者的讀寫請求,從副本則會定期從主副本拉取消息,保持與主副本的同步 。當主副本所在的 Broker 出現故障時,Kafka 會自動從從副本中選舉一個新的主副本,確保數據不丟失并且服務不中斷。
例如,在一個金融交易系統中,訂單數據的可靠性至關重要。Kafka 通過為訂單相關的 Partition 設置多個副本,當某個 Broker 出現故障時,其他副本可以迅速接替工作,保證訂單數據的完整性和交易的正常進行。
(二)架構圖詳解
下面是 Kafka 的架構圖:
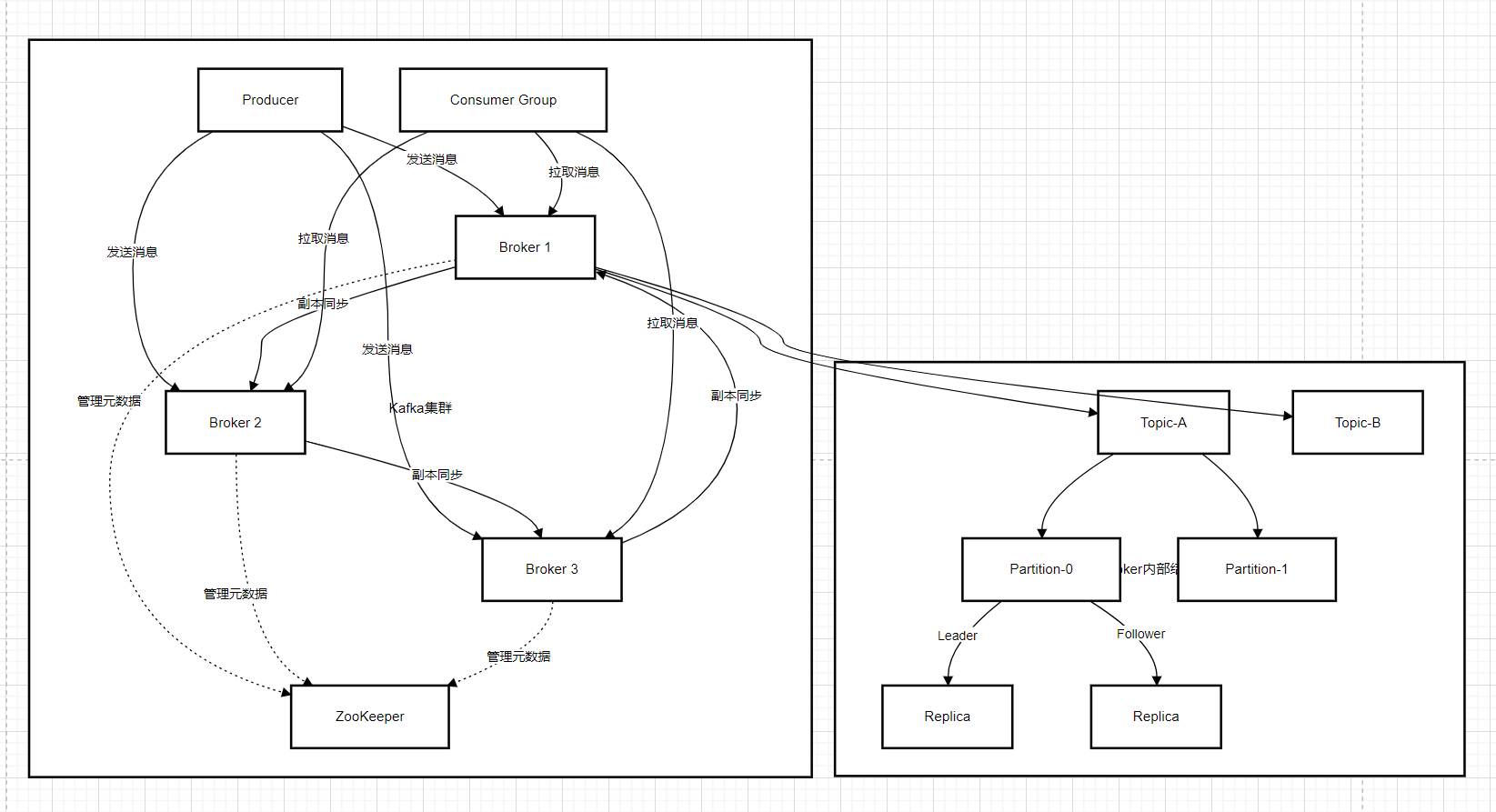
從架構圖中可以清晰地看到各個組件之間的交互關系和數據流向:
-
生產者發送消息:Producer 根據配置的分區策略,將消息發送到指定 Topic 的某個 Partition 的 Leader 副本上。例如,一個電商系統的訂單生產者,將訂單消息發送到 “order-topic” 的某個分區。
-
Broker 存儲消息:Broker 接收到消息后,將其追加到對應的 Partition 的日志文件中,并將消息同步給該 Partition 的 Follower 副本。比如,Broker1 接收到 “order-topic” 分區 1 的消息后,存儲消息并同步給 Broker2 和 Broker3 上的該分區的 Follower 副本。
-
消費者消費消息:Consumer 向 Kafka 集群發送拉取消息的請求,Kafka 根據消費組的配置和分區分配策略,將消息從相應 Partition 的 Leader 副本返回給 Consumer。例如,一個訂單處理系統的消費者,從 “order-topic” 中拉取訂單消息進行處理。
-
Zookeeper 協調管理:在傳統架構中,Zookeeper 負責管理 Kafka 集群的元信息,如 Broker 列表、Topic 和 Partition 的元數據等 。它還負責選舉 Controller(控制節點),Controller 負責管理分區的 Leader 選舉等重要工作。雖然 Kafka 正在逐步引入 KRaft 模式來取代 Zookeeper,但在當前很多生產環境中,Zookeeper 仍然發揮著重要作用 。例如,當一個新的 Broker 加入集群時,Zookeeper 會感知到并更新集群的元信息,通知其他組件。
通過這個架構圖和上述的交互流程,我們可以直觀地理解 Kafka 是如何高效地進行消息的生產、存儲和消費,以及如何通過各個組件的協同工作實現分布式、高可用和高性能的特性。
四、Kafka 原理深度剖析
(一)消息生產過程
1. 生產者分區策略
生產者在發送消息時,需要決定將消息發送到 Topic 的哪個 Partition 中,這就涉及到分區策略。Kafka 提供了多種分區策略,每種策略都有其適用場景。
- 隨機策略:就像是抽獎一樣,隨機地將消息分配到各個 Partition 中。這種策略實現簡單,但是可能會導致消息分布不均勻,某些 Partition 可能會接收過多的消息,而某些 Partition 則接收較少。例如:
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;import java.util.List;
import java.util.Random;public class RandomPartitioner implements Partitioner {private final Random random = new Random();@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);return random.nextInt(partitions.size());}@Overridepublic void close() {// 關閉時的操作,這里為空}@Overridepublic void configure(java.util.Map<String, ?> configs) {// 配置時的操作,這里為空}
}
在這個自定義分區器中,通過Random類生成一個隨機數,作為分區的索引,從而實現隨機分區。
- 輪詢策略:這是 Kafka 的默認分區策略,它就像一個有條不紊的分發員,按照順序依次將消息分配到各個 Partition 中,保證消息能夠均勻地分布在各個 Partition 上,實現負載均衡。例如:
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;public class RoundRobinPartitioner implements Partitioner {private final AtomicInteger nextPartition = new AtomicInteger(0);@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();return nextPartition.getAndIncrement() % numPartitions;}@Overridepublic void close() {// 關閉時的操作,這里為空}@Overridepublic void configure(java.util.Map<String, ?> configs) {// 配置時的操作,這里為空}
}
在這個輪詢分區器中,使用AtomicInteger來記錄下一個要使用的分區索引,每次調用partition方法時,通過getAndIncrement方法獲取當前索引并自增,然后對分區數量取模,得到要使用的分區索引,從而實現輪詢分區。
- 按消息鍵策略:根據消息的鍵(Key)來決定分區,具有相同鍵的消息會被發送到同一個 Partition 中。這種策略可以保證具有相同鍵的消息在分區內的順序性,適用于需要保證某些消息順序處理的場景,比如訂單處理,同一個訂單的消息需要按順序處理。例如:
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;import java.util.List;public class KeyHashPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();return Math.abs(key.hashCode()) % numPartitions;}@Overridepublic void close() {// 關閉時的操作,這里為空}@Overridepublic void configure(java.util.Map<String, ?> configs) {// 配置時的操作,這里為空}
}
在這個按消息鍵分區器中,通過對消息鍵的hashCode取絕對值后對分區數量取模,得到要使用的分區索引,從而保證相同鍵的消息被發送到同一個分區。
在實際使用中,可以根據業務需求選擇合適的分區策略,也可以通過實現Partitioner接口來自定義分區策略。例如,如果業務中需要根據用戶 ID 進行分區,保證同一個用戶的消息都在同一個分區,可以這樣實現:
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;import java.util.List;public class UserIdPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 假設消息的鍵是用戶IDString userId = (String) key;List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();return Math.abs(userId.hashCode()) % numPartitions;}@Overridepublic void close() {// 關閉時的操作,這里為空}@Overridepublic void configure(java.util.Map<String, ?> configs) {// 配置時的操作,這里為空}
}
然后在生產者配置中指定使用這個自定義分區器:
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 指定自定義分區器
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, UserIdPartitioner.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
通過這種方式,就可以根據業務需求靈活地選擇和實現分區策略,確保消息在 Kafka 集群中的合理分布和處理。
2. 消息序列化與發送
在 Kafka 中,消息在發送前需要進行序列化,將消息對象轉換為字節數組,因為 Kafka 只處理字節數組格式的數據 。序列化的作用主要有兩個:一是將消息對象轉換為適合在網絡中傳輸和在磁盤上存儲的格式;二是可以減少消息的大小,提高傳輸和存儲效率。
Kafka 提供了多種默認的序列化器,如StringSerializer用于將字符串序列化,ByteArraySerializer用于將字節數組序列化等 。在實際應用中,如果默認的序列化器不能滿足需求,還可以自定義序列化器。例如,當需要發送自定義的 Java 對象時,就需要自定義序列化器將對象轉換為字節數組。
下面是一個自定義序列化器的示例,假設我們有一個User類:
import java.io.Serializable;public class User implements Serializable {private String name;private int age;public User(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public int getAge() {return age;}@Overridepublic String toString() {return "User{" +"name='" + name + '\'' +", age=" + age +'}';}
}
然后實現自定義序列化器:
import org.apache.kafka.common.serialization.Serializer;import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.util.Map;public class UserSerializer implements Serializer<User> {@Overridepublic void configure(Map<String, ?> configs, boolean isKey) {// 配置方法,這里可以進行一些初始化操作,暫時為空}@Overridepublic byte[] serialize(String topic, User data) {if (data == null) {return null;}ByteArrayOutputStream bos = new ByteArrayOutputStream();try (ObjectOutputStream oos = new ObjectOutputStream(bos)) {oos.writeObject(data);return bos.toByteArray();} catch (IOException e) {throw new RuntimeException("Failed to serialize User object", e);}}@Overridepublic void close() {// 關閉方法,這里可以進行一些清理操作,暫時為空}
}
在生產者中使用這個自定義序列化器:
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 使用自定義的UserSerializer
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, UserSerializer.class.getName());
KafkaProducer<String, User> producer = new KafkaProducer<>(props);User user = new User("Alice", 25);
ProducerRecord<String, User> record = new ProducerRecord<>("user-topic", user);
producer.send(record);
消息序列化完成后,生產者就會將消息發送到 Kafka 集群。在發送過程中,涉及到兩個重要的線程:主線程(main 線程)和發送線程(Sender 線程) 。主線程負責創建消息,并將消息添加到一個雙端隊列RecordAccumulator中 。發送線程不斷從RecordAccumulator中拉取消息,然后將消息發送到 Kafka Broker。
生產者在發送消息時,可以選擇同步發送或異步發送 。同步發送時,調用send方法會阻塞當前線程,直到消息被成功發送或發送失敗,通過調用get方法可以獲取發送結果;異步發送時,調用send方法后會立即返回,不會阻塞當前線程,通過傳入回調函數可以在消息發送成功或失敗時進行相應的處理。例如:
// 異步發送消息,帶回調函數
producer.send(record, (metadata, exception) -> {if (exception == null) {System.out.printf("Message sent to topic %s partition %d offset %d%n",metadata.topic(), metadata.partition(), metadata.offset());} else {System.out.println("Failed to send message: " + exception.getMessage());}
});// 同步發送消息
try {producer.send(record).get();System.out.println("Message sent successfully");
} catch (InterruptedException | ExecutionException e) {System.out.println("Failed to send message: " + e.getMessage());
}
在實際應用中,異步發送通常更常用,因為它可以提高生產者的吞吐量,避免線程阻塞,讓主線程可以繼續處理其他任務。而同步發送則適用于對消息發送結果有嚴格要求,需要確保消息成功發送后再進行后續操作的場景。
(二)消息存儲機制
1. 日志結構存儲
Kafka 采用日志結構存儲消息,每個 Topic 由多個 Partition 組成,每個 Partition 對應一個物理日志文件,消息以追加的方式順序寫入日志文件 。這種存儲方式就像是一本不斷記錄新內容的日記,新的消息不斷地被添加到日記的末尾。
日志結構存儲有很多優點,首先是順序寫入,磁盤的順序寫入速度遠遠高于隨機寫入 。傳統的隨機寫入就像是在一本厚厚的字典中隨機查找一個字并修改它,需要花費很多時間在翻頁查找上;而順序寫入則像是在一張白紙上依次寫下新的內容,速度就快多了。Kafka 的順序寫入方式大大提高了寫入性能,減少了磁盤尋道時間,能夠高效地處理大量的消息寫入。
其次,順序寫入也有利于提高讀取性能 。消費者在讀取消息時,通常也是按照順序讀取的,這樣可以充分利用磁盤的順序讀取優勢,快速地從日志文件中獲取消息。例如,在一個實時監控系統中,大量的監控數據不斷地被寫入 Kafka,采用日志結構存儲,Kafka 可以快速地將這些數據寫入磁盤,并且在數據分析系統需要讀取這些數據時,也能快速地將數據返回,保證監控數據的實時性和準確性。
另外,Kafka 還使用了稀疏索引來加速消息的查找 。它為每個日志文件創建了一個索引文件,索引文件中記錄了消息的偏移量(Offset)和對應的物理位置 。通過索引文件,Kafka 可以快速定位到指定偏移量的消息,而不需要遍歷整個日志文件。比如,當消費者需要獲取某個特定偏移量的消息時,Kafka 可以通過索引文件快速找到該消息在日志文件中的位置,然后直接讀取該位置的消息,大大提高了消息查找的效率。
2. 數據壓縮與分段
為了節省存儲空間和網絡帶寬,Kafka 支持對消息進行壓縮 。Kafka 提供了多種壓縮算法,如 GZIP、Snappy、LZ4 等 ,每種算法都有其特點和適用場景。
-
GZIP:具有較高的壓縮比,能夠顯著減少消息的大小,但是壓縮和解壓縮的速度相對較慢 。適用于對存儲空間要求較高,對壓縮和解壓縮速度要求不是特別嚴格的場景,比如日志歸檔,日志數據量大,對存儲空間要求高,而在歸檔時對速度要求相對較低。
-
Snappy:壓縮和解壓縮速度非常快,但是壓縮比相對較低 。適用于對實時性要求較高,需要快速處理大量消息的場景,比如實時數據處理,在處理大量實時數據時,快速的壓縮和解壓縮速度可以保證數據的及時處理。
-
LZ4:在壓縮比和速度之間取得了較好的平衡,既具有較高的壓縮比,又有較快的壓縮和解壓縮速度 。適用于大多數場景,是一種比較常用的壓縮算法。
Kafka 的壓縮是在生產者端進行的,生產者將多條消息收集成一個批次(batch),然后對整個批次進行壓縮 。壓縮后的批次被發送到 Kafka Broker,Broker 直接存儲和轉發壓縮后的數據,不會對數據進行解壓 。當消費者消費消息時,會在消費端對壓縮的批次進行解壓,得到原始的消息。
例如,在一個電商系統中,大量的訂單消息需要發送到 Kafka 進行處理。如果不進行壓縮,這些訂單消息會占用大量的網絡帶寬和 Kafka Broker 的磁盤空間。通過在生產者端使用 LZ4 壓縮算法對訂單消息進行壓縮,不僅可以減少網絡傳輸的數據量,降低網絡帶寬的消耗,還可以減少 Kafka Broker 的磁盤占用,提高系統的整體性能。
除了數據壓縮,Kafka 還采用了數據分段存儲的方式 。每個 Partition 的日志文件會被分成多個段(Segment),每個段包含一定數量的消息 。當一個段的大小達到一定閾值或者經過一定時間后,會創建一個新的段 。每個段都有一個對應的索引文件,用于加速消息的查找。
數據分段存儲有很多好處,首先可以方便地管理和維護日志文件 。當一個段的消息不再需要時,可以直接刪除該段,而不會影響其他段的消息。其次,分段存儲也有利于提高消息的讀取性能 。當消費者需要讀取某個時間段內的消息時,可以直接定位到對應的段,而不需要讀取整個日志文件。例如,在一個長時間運行的物聯網數據采集系統中,Kafka 會不斷地接收大量的傳感器數據。通過數據分段存儲,Kafka 可以將不同時間段的傳感器數據存儲在不同的段中。當數據分析系統需要分析某個特定時間段的傳感器數據時,Kafka 可以快速地定位到對應的段,讀取該段中的數據,提高數據處理的效率。
Kafka 還會定期清理過期的段,以釋放磁盤空間 。清理策略可以根據配置的保留時間或日志大小來決定 。當一個段中的消息超過了保留時間或者日志文件的大小超過了配置的限制時,Kafka 會將該段標記為可刪除,然后在適當的時候將其刪除 。通過這種方式,Kafka 可以有效地管理磁盤空間,確保系統的穩定運行。
(三)消息消費原理
1. 消費者拉取策略
消費者從 Kafka 集群拉取消息是通過主動輪詢(Polling)的方式進行的 。消費者會定期向 Kafka 集群發送拉取請求,Kafka 集群根據請求返回相應的消息。這種拉取方式就像是你定期去快遞站詢問有沒有自己的包裹,而不是在快遞站一直等待包裹的到來。
消費者在拉取消息時,有幾個重要的參數需要關注:
-
拉取頻率:消費者拉取消息的頻率可以通過配置參數來控制。如果拉取頻率過高,會增加網絡開銷和 Kafka 集群的負載;如果拉取頻率過低,可能會導致消息處理延遲。例如,在一個實時數據分析系統中,如果消費者拉取消息的頻率過低,就不能及時獲取最新的數據進行分析,影響分析結果的實時性。
-
批量拉取:消費者可以一次拉取多條消息,而不是一條一條地拉取,這樣可以減少網絡請求次數,提高拉取效率 。通過設置
fetch.max.bytes參數可以控制每次拉取的最大字節數,設置max.poll.records參數可以控制每次拉取的最大消息數量 。比如,在一個處理大量日志數據的場景中,通過批量拉取可以將多個日志消息一次性拉取回來進行處理,減少網絡請求的次數,提高日志處理的效率。 -
偏移量(Offset):偏移量是消息在分區中的唯一標識,用于確定消費者拉取消息的位置 。每個分區都有一個獨立的偏移量,消費者通過維護自己的偏移量來記錄已經消費的消息位置 。當消費者重啟或者加入新的消費者時,會根據偏移量來確定從哪里開始繼續消費消息。例如,在一個電商訂單處理系統中,消費者在處理訂單消息時,會記錄下已經處理的訂單消息的偏移量。當系統出現故障重啟后,消費者可以根據之前記錄的偏移
五、Kafka 應用場景大放送
(一)日志收集與處理
在當今的數字化時代,各種服務和應用程序就像勤勞的小蜜蜂,不斷地產生著海量的日志數據。這些日志數據記錄了系統的運行狀態、用戶的操作行為等重要信息,對于系統的監控、故障排查和數據分析都有著至關重要的作用 。而 Kafka 就像是一個高效的日志收集大師,能夠輕松地收集各種服務的日志,將這些零散的日志數據集中起來,然后以統一接口服務的方式開放給各種消費者 。
以一個大型電商平臺為例,它的系統中包含了眾多的服務,如用戶服務、訂單服務、支付服務、物流服務等 。每個服務都會產生大量的日志,這些日志分散在不同的服務器上,如果不進行有效的收集和管理,就會像一團亂麻,難以從中獲取有價值的信息 。通過使用 Kafka,各個服務可以將自己產生的日志發送到 Kafka 集群中。比如,訂單服務在用戶下單、取消訂單、支付成功等關鍵操作時,會生成相應的日志消息,并將這些消息發送到 Kafka 的 “order - log - topic” 主題中;用戶服務在用戶注冊、登錄、修改個人信息等操作時,也會將日志消息發送到 Kafka 的 “user - log - topic” 主題中 。
Kafka 集群接收這些日志消息后,會將它們存儲起來。此時,Kafka 就像是一個巨大的日志倉庫,安全地保存著所有的日志數據 。而后續的處理工作就可以交給各種消費者來完成了。其中一個常見的處理方式是將日志存儲到 Hadoop 分布式文件系統(HDFS)中,以便進行離線分析 。Hadoop 具有強大的分布式存儲和計算能力,能夠處理海量的數據 。通過 Kafka Connect 等工具,可以將 Kafka 中的日志數據源源不斷地傳輸到 HDFS 中 。例如,每天晚上電商平臺可以對 HDFS 中的日志數據進行批量處理,分析用戶的購買行為、訂單趨勢等,為業務決策提供數據支持 。
除了離線分析,實時分析也是日志處理的重要需求 。這時候,Kafka 就可以與一些實時分析工具或框架相結合,如 ELK(Elasticsearch - Logstash - Kibana)技術棧 。Logstash 作為一個數據收集引擎,能夠從 Kafka 集群中讀取日志消息,并對消息進行過濾、轉換等操作 。然后,將處理后的日志數據發送到 Elasticsearch 中進行存儲和索引 。Elasticsearch 是一個分布式搜索引擎,具有高擴展性和快速的搜索能力,能夠快速地對日志數據進行檢索和分析 。最后,Kibana 作為一個可視化工具,連接到 Elasticsearch,將日志數據以直觀的圖表、報表等形式展示出來,方便運維人員和數據分析人員進行實時監控和分析 。例如,通過 Kibana 可以實時查看訂單服務的請求量、錯誤率等指標,一旦發現異常情況,能夠及時進行處理 。
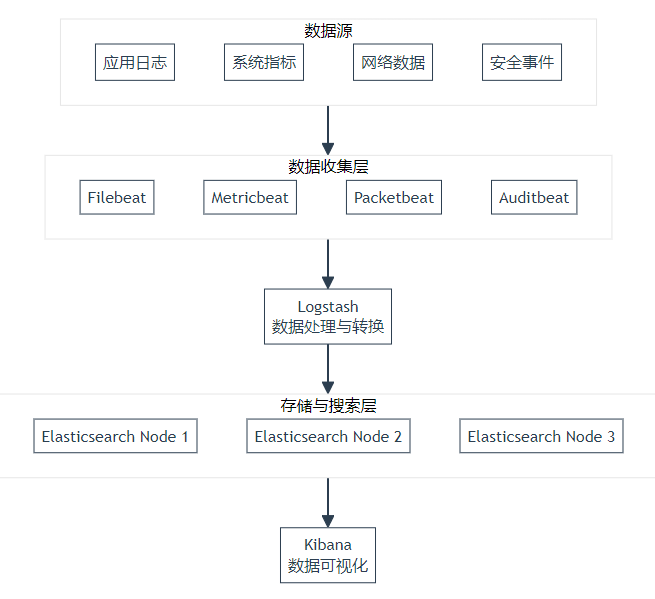
在這個 ELK 架構中,Kafka 扮演著至關重要的角色 。它作為日志數據的中轉站,一方面接收來自各個服務的日志消息,保證了日志數據的不丟失和高效傳輸;另一方面,為 Logstash 提供了穩定的數據源,使得 ELK 能夠順利地進行實時日志分析 。如果沒有 Kafka,各個服務直接將日志發送給 Logstash,可能會因為網絡波動、Logstash 的負載過高而導致日志丟失或處理不及時 。而 Kafka 的高吞吐量、持久化存儲和可擴展性等特性,有效地解決了這些問題,確保了日志收集與處理系統的穩定運行 。
(二)消息隊列與解耦
在分布式系統的大家庭中,各個模塊就像是獨立的個體,它們有著各自的職責和任務,但又需要相互協作來完成整個系統的功能 。然而,直接的模塊間調用就像是一根緊緊捆綁的繩子,會導致模塊之間的耦合度非常高,牽一發而動全身 。而 Kafka 作為消息隊列,就像是一個靈活的信使,能夠在模塊之間傳遞消息,實現生產者和消費者的解耦,讓各個模塊可以獨立地發展和演進 。
以一個電商系統中的訂單模塊和庫存模塊為例 。在傳統的緊密耦合架構下,當用戶下單時,訂單模塊需要直接調用庫存模塊來檢查庫存并扣減庫存 。這種方式雖然簡單直接,但存在很多問題 。比如,如果庫存模塊出現故障,訂單模塊也會受到影響,導致用戶無法下單;而且,當業務量增加,需要對庫存模塊進行升級或擴展時,可能會影響到訂單模塊的正常運行 。
而引入 Kafka 作為消息隊列后,情況就大不一樣了 。當用戶下單時,訂單模塊會將訂單消息發送到 Kafka 的 “order - topic” 主題中,然后就可以繼續處理其他任務,而不需要等待庫存模塊的響應 。庫存模塊作為消費者,從 “order - topic” 主題中訂閱消息,當它接收到訂單消息后,再進行庫存檢查和扣減庫存的操作 。這樣,訂單模塊和庫存模塊之間就實現了異步通信和解耦 。訂單模塊不需要關心庫存模塊的具體實現和運行狀態,庫存模塊也可以獨立地進行升級和擴展,而不會影響到訂單模塊 。
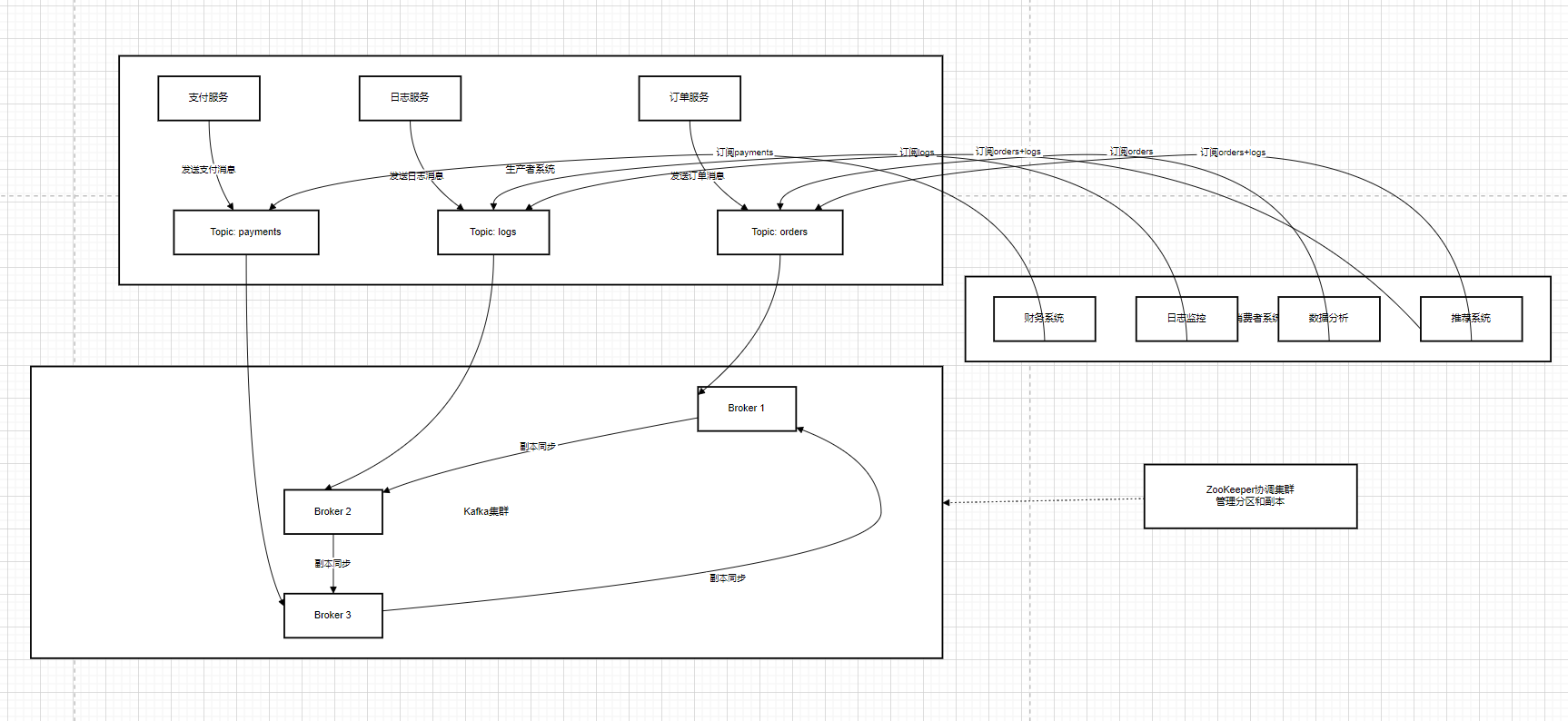
在這個過程中,Kafka 就像是一個緩沖池,它可以緩存訂單消息 。當訂單模塊產生訂單消息的速度過快,超過了庫存模塊的處理能力時,Kafka 可以暫時存儲這些消息,避免消息的丟失 。等庫存模塊有能力處理時,再從 Kafka 中拉取消息進行處理 。這就提高了系統的可靠性和穩定性,使得系統能夠更好地應對高并發的業務場景 。
除了訂單模塊和庫存模塊,在分布式系統中還有很多其他的模塊之間也可以通過 Kafka 進行解耦 。比如,支付模塊和訂單模塊之間,當用戶支付成功后,支付模塊可以將支付結果消息發送到 Kafka,訂單模塊從 Kafka 中獲取消息,然后更新訂單狀態 。這樣,支付模塊和訂單模塊之間就實現了松耦合,各自可以獨立地進行開發、測試和部署 。通過 Kafka 的消息隊列和異步通信機制,分布式系統中的各個模塊可以更加靈活、高效地協作,提高了系統的可擴展性和穩定性,為業務的發展提供了有力的支持 。
(三)用戶活動跟蹤
在互聯網的世界里,用戶就像是舞臺上的演員,他們在 Web 或 App 上的每一個動作,如瀏覽、點擊、搜索等,都像是一場精彩的表演 。而 Kafka 就像是一個忠實的記錄者,能夠將用戶的這些活動信息記錄下來,為后續的分析和應用提供豐富的數據資源 。
以一個在線購物 App 為例,當用戶打開 App 時,就會產生一個 “用戶打開 App” 的活動消息;用戶瀏覽商品列表時,會產生 “用戶瀏覽商品” 的消息,消息中可能包含瀏覽的商品 ID、瀏覽時間等信息;當用戶點擊某個商品查看詳情時,會生成 “用戶點擊商品詳情” 的消息;如果用戶進行搜索操作,還會產生 “用戶搜索” 的消息,包含搜索關鍵詞等內容 。這些用戶活動消息會被各個服務器收集起來,并發送到 Kafka 的 “user - activity - topic” 主題中 。
Kafka 收集到這些用戶活動數據后,就可以發揮其強大的作用了 。首先,通過對這些數據進行實時監控分析,可以了解用戶的實時行為 。比如,通過監控 “用戶點擊商品詳情” 的消息數量和頻率,可以知道哪些商品受到用戶的關注,從而及時調整商品的推薦策略,將熱門商品推薦給更多的用戶 。再比如,通過分析 “用戶搜索” 的關鍵詞,可以了解用戶的需求和興趣點,為商品的優化和推廣提供方向 。
其次,利用這些用戶活動數據還可以構建用戶畫像 。用戶畫像就像是用戶在數字世界中的一張全方位照片,通過收集用戶的基本信息、行為數據、偏好數據等,對用戶進行多維度的刻畫 。在構建用戶畫像的過程中,Kafka 中的用戶活動數據起著關鍵的作用 。例如,通過分析用戶瀏覽和購買的商品類別,可以了解用戶的消費偏好;通過分析用戶的登錄時間和使用頻率,可以了解用戶的活躍程度和使用習慣 。將這些信息整合起來,就可以構建出一個詳細的用戶畫像,為精準營銷、個性化推薦等提供有力的支持 。比如,電商平臺可以根據用戶畫像,向用戶推薦他們可能感興趣的商品,提高用戶的購買轉化率 。
(四)運營指標監控
在分布式應用的龐大體系中,各種運營指標就像是系統的 “健康指標”,反映著系統的運行狀態和性能表現 。Kafka 就像是一個高效的 “數據快遞員”,在收集和傳輸運營監控數據方面發揮著重要作用,確保這些關鍵數據能夠及時、準確地傳遞到需要的地方 。
以一個大型分布式電商應用為例,它包含了眾多的服務節點,如 Web 服務器、應用服務器、數據庫服務器等 。每個服務節點都會產生各種運營指標數據,比如 Web 服務器的 CPU 利用率、內存使用情況、網絡流量、請求響應時間等;應用服務器的并發用戶數、業務處理吞吐量、錯誤率等;數據庫服務器的磁盤 I/O 讀寫速率、查詢執行時間等 。這些指標數據對于監控系統的性能、發現潛在問題以及進行性能優化都非常重要 。
為了收集這些運營指標數據,通常會在各個服務節點上部署采集器(agent) 。這些采集器就像是一個個小偵探,負責收集所在節點的各種指標數據 。然后,采集器將收集到的指標數據發送到 Kafka 集群中 。比如,Web 服務器上的采集器會定時采集 CPU 利用率和內存使用情況等數據,并將這些數據封裝成消息發送到 Kafka 的 “web - server - metrics - topic” 主題中;應用服務器上的采集器會收集并發用戶數和業務處理吞吐量等數據,發送到 “app - server - metrics - topic” 主題中 。
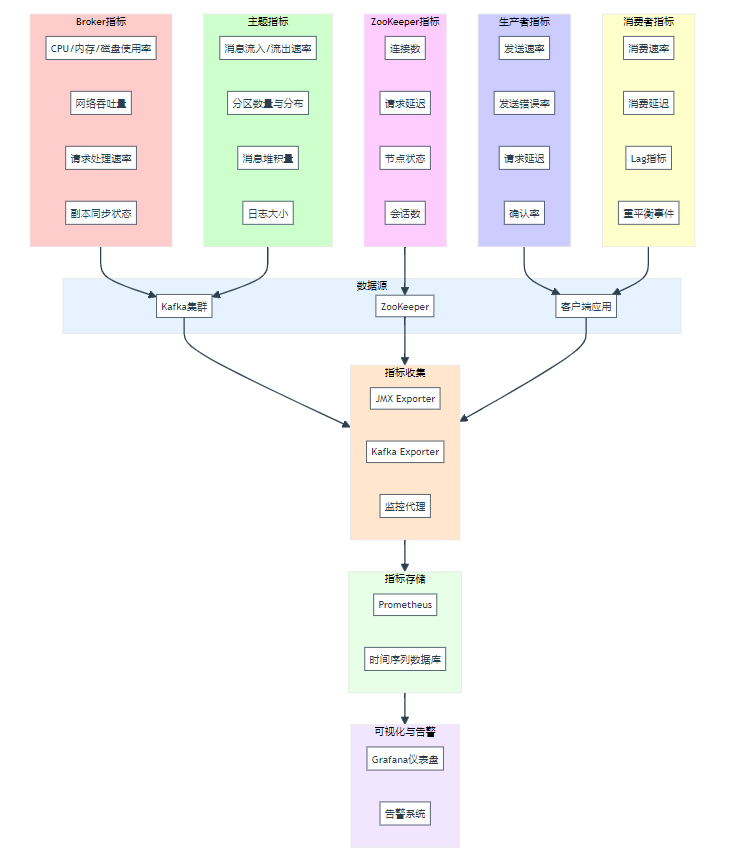
Kafka 集群接收這些指標數據消息后,會將它們存儲起來,并等待被消費 。監控系統和報警系統作為消費者,從 Kafka 集群中訂閱相應的主題 。監控系統可以實時獲取這些指標數據,并以直觀的圖表、儀表盤等形式展示出來,讓運維人員和管理人員能夠實時了解系統的運行狀態 。例如,通過監控系統可以實時查看各個 Web 服務器的 CPU 利用率曲線,如果發現某個服務器的 CPU 利用率持續過高,可能意味著該服務器負載過重,需要進一步排查原因并進行優化 。
報警系統則會根據預設的閾值對指標數據進行判斷 。當某個指標數據超過閾值時,報警系統就會觸發報警 。比如,當應用服務器的錯誤率超過 5% 時,報警系統會立即發送郵件或短信通知相關人員,以便及時采取措施解決問題,避免問題進一步惡化影響系統的正常運行 。通過 Kafka 在運營指標監控中的應用,能夠實現對分布式應用的全面、實時監控,及時發現和解決問題,保障系統的穩定、高效運行 。
(五)流式處理
在大數據處理的領域中,實時數據流就像是奔騰不息的河流,源源不斷地產生著各種數據 。Kafka 在流處理中扮演著關鍵的角色,它就像是這條數據河流的 “中轉站”,為實時數據流的處理和分析提供了強大的支持 。當 Kafka 與 Spark Streaming、Flink 等流處理框架結合時,就像是組成了一個強大的 “數據處理戰隊”,能夠對實時數據流進行高效的處理和分析 。
以一個實時電商數據分析的場景為例,用戶在電商平臺上的各種實時行為數據,如商品瀏覽、添加購物車、下單、支付等,都會作為實時數據流發送到 Kafka 集群中 。這些數據被發送到 Kafka 的 “ecommerce - stream - topic” 主題中,Kafka 負責接收、存儲和轉發這些數據,確保數據的不丟失和高效傳輸 。
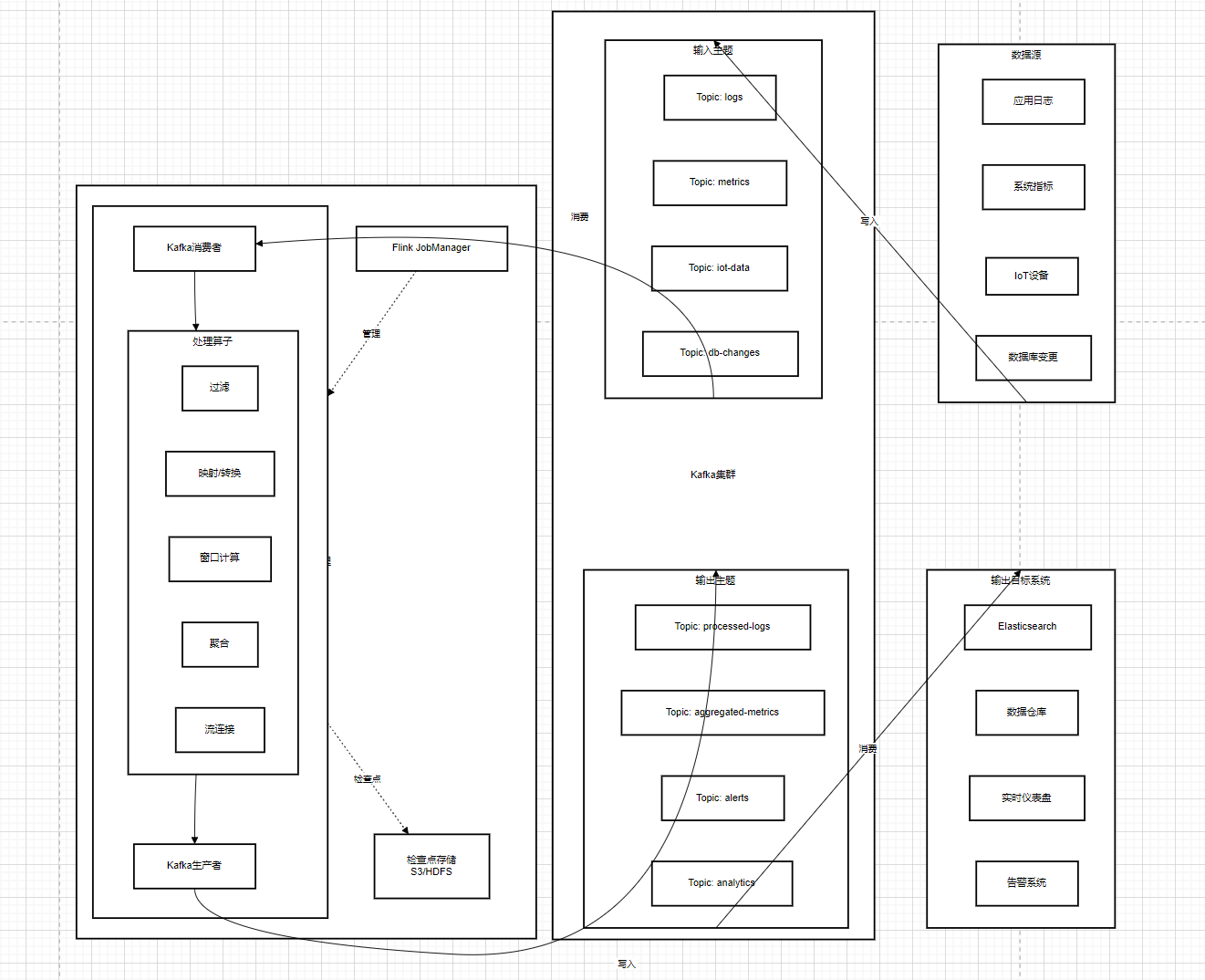
Flink 作為流處理框架,從 Kafka 的 “ecommerce - stream - topic” 主題中讀取實時數據流 。Flink 就像是一個智能的 “數據加工工廠”,它可以對這些實時數據進行各種復雜的處理和分析操作 。比如,Flink 可以對用戶的瀏覽行為數據進行實時統計,計算出每個商品的瀏覽量和瀏覽時長,從而了解用戶對不同商品的關注度;通過對添加購物車和下單的數據進行關聯分析,可以計算出購物車到訂單的轉化率,幫助電商平臺了解用戶的購買意愿和購買行為的轉化情況;還可以根據用戶的支付數據,實時統計不同支付方式的占比,以及不同時間段的支付金額,為電商平臺的運營決策提供實時的數據支持 。
在這個過程中,Kafka 與 Flink 之間的協作非常緊密 。Kafka 為 Flink 提供了穩定的數據源,保證了實時數據流的持續供應 。而 Flink 則充分發揮其強大的流處理能力,對 Kafka 中的數據進行高效的處理和分析 。通過這種結合,電商平臺可以實時了解用戶的行為和業務的運行情況,及時做出決策和調整 。比如,當發現某個商品的瀏覽量突然增加,但下單量卻很少時,電商平臺可以及時調整該商品的推薦策略或進行促銷活動,提高用戶的購買轉化率 。
除了電商場景,在物聯網、金融、社交網絡等眾多領域,Kafka 與流處理框架的結合都有著廣泛的應用 。例如,在物聯網領域,大量的傳感器會實時產生各種數據,如溫度、濕度、壓力等 。這些數據通過 Kafka 傳輸到流處理框架中,進行實時的數據分析和處理,實現對設備的實時監控和故障預警 。在金融領域,股票交易數據、銀行轉賬數據等實時數據流通過 Kafka 與流處理框架結合,可以實現實時的風險監控和交易分析 。通過 Kafka 在流處理中的重要作用,能夠實現對實時數據流的高效處理和分析,為各個領域的業務發展提供有力的數據支持 。
六、Java 操作 Kafka 實戰
(一)環境搭建
在開始使用 Java 操作 Kafka 之前,我們得先把環境搭建好,這就好比蓋房子得先把地基打好。下面是詳細的搭建步驟:
1. 安裝 Java 環境:
Kafka 是基于 Java 開發的,所以首先要確保你的機器上安裝了 Java 環境。如果你還沒安裝,可以從Oracle 官網下載最新的 Java Development Kit(JDK)。下載完成后,按照安裝向導的提示進行安裝即可。安裝完成后,打開命令行,輸入java -version,如果能正確顯示 Java 的版本信息,那就說明安裝成功啦。
2. 下載 Kafka:
你可以從Apache Kafka 官網下載 Kafka 的二進制包。選擇適合你操作系統的版本,比如kafka_2.13-3.5.1.tgz(這里的2.13是 Scala 的版本,3.5.1是 Kafka 的版本)。下載完成后,將壓縮包解壓到你想要安裝的目錄,比如/usr/local/kafka。
3. 配置 Kafka:
進入 Kafka 的安裝目錄,找到config文件夾,里面有幾個重要的配置文件,我們主要關注server.properties。打開這個文件,你會看到很多配置項,下面是一些常見的配置項及其說明:
-
broker.id:每個 Kafka Broker 在集群中都有一個唯一的 ID,用于標識自己。在單機環境下,默認設置為0即可;如果是集群環境,每個 Broker 的broker.id必須不同。 -
listeners:指定 Kafka Broker 監聽的地址和端口,默認是PLAINTEXT://``localhost:9092。如果你想讓其他機器也能訪問你的 Kafka,需要將localhost改為你的機器 IP 地址。 -
log.dirs:Kafka 存儲消息日志的目錄。你可以根據自己的磁盤空間和需求,指定一個合適的目錄,比如/data/kafka-logs。注意,這個目錄必須提前創建好,并且 Kafka 進程對該目錄要有讀寫權限。 -
zookeeper.connect:Kafka 依賴 Zookeeper 來管理集群狀態和元數據。這里指定 Zookeeper 的連接地址和端口,格式為host1:port1,host2:port2,...。在單機環境下,如果你的 Zookeeper 也在本地運行,默認是localhost:2181。
配置完成后,保存文件。如果你對其他配置項感興趣,可以查閱 Kafka 的官方文檔,里面有更詳細的說明。
4. 啟動 Kafka:
在啟動 Kafka 之前,需要先啟動 Zookeeper。如果你使用的是 Kafka 自帶的 Zookeeper,可以在 Kafka 的安裝目錄下執行以下命令啟動 Zookeeper:
bin/zookeeper-server-start.sh config/zookeeper.properties
Zookeeper 啟動后,會在控制臺輸出一些日志信息。然后,在另一個終端窗口中,執行以下命令啟動 Kafka:
bin/kafka-server-start.sh config/server.properties
Kafka 啟動成功后,也會在控制臺輸出一堆日志信息。如果沒有報錯,那就說明 Kafka 已經成功啟動啦!
5. 添加 Maven 依賴:
如果你使用 Maven 來管理項目依賴,在你的項目pom.xml文件中添加以下依賴:
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.5.1</version>
</dependency>
這樣,Maven 就會自動下載 Kafka 的客戶端庫及其依賴項。如果你使用 Gradle,對應的依賴配置如下:
implementation 'org.apache.kafka:kafka-clients:3.5.1'
到這里,Java 操作 Kafka 的環境就搭建好啦!是不是感覺也沒那么復雜?接下來,我們就可以開始編寫代碼,體驗 Java 與 Kafka 的交互之旅啦!
(二)生產者代碼實現
環境搭建好后,我們就可以開始編寫 Java 代碼,實現 Kafka 生產者啦。生產者的主要職責就是將消息發送到 Kafka 集群中指定的主題(Topic)。下面是一個完整的 Kafka 生產者示例代碼:
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {// Kafka集群地址String bootstrapServers = "localhost:9092";// 要發送的主題String topic = "my-topic";// 創建Kafka生產者配置Properties props = new Properties();// 指定Kafka集群地址props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);// 鍵的序列化器,將鍵轉換為字節數組,這里使用StringSerializer將字符串類型的鍵進行序列化props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 值的序列化器,將值轉換為字節數組,這里使用StringSerializer將字符串類型的值進行序列化props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 創建Kafka生產者實例KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 發送10條消息for (int i = 0; i < 10; i++) {// 消息的鍵String key = "key-" + i;// 消息的值String value = "message-" + i;// 創建ProducerRecord對象,包含主題、鍵和值ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);// 發送消息,這里使用異步發送,并添加回調函數處理結果producer.send(record, (metadata, exception) -> {if (exception == null) {System.out.printf("Message sent to topic %s partition %d offset %d%n",metadata.topic(), metadata.partition(), metadata.offset());} else {System.out.println("Failed to send message: " + exception.getMessage());}});}// 關閉生產者,釋放資源producer.close();}
}
代碼解釋:
-
配置生產者屬性:
首先創建一個
Properties對象,用于配置 Kafka 生產者的屬性。BOOTSTRAP_SERVERS_CONFIG指定了 Kafka 集群的地址,生產者會通過這個地址連接到 Kafka 集群。KEY_SERIALIZER_CLASS_CONFIG和VALUE_SERIALIZER_CLASS_CONFIG分別指定了消息鍵和值的序列化器。因為 Kafka 在網絡中傳輸的是字節數組,所以需要將消息的鍵和值進行序列化。這里我們使用StringSerializer,它會將字符串類型的鍵和值轉換為字節數組。 -
創建生產者實例:
使用配置好的屬性創建
KafkaProducer實例。這個實例就是我們用來發送消息的工具。 -
發送消息:
在一個循環中,創建
ProducerRecord對象,它包含了要發送到的主題、消息的鍵和值。然后使用producer.send方法發送消息。這里我們使用的是異步發送方式,send方法會立即返回,不會阻塞當前線程。同時,我們傳入了一個回調函數,當消息發送完成后,Kafka 會調用這個回調函數,并將發送結果(metadata)和可能出現的異常(exception)傳遞給回調函數。如果發送成功,exception為null,我們可以從metadata中獲取消息發送到的主題、分區和偏移量;如果發送失敗,exception不為null,我們可以打印出錯誤信息,方便調試。 -
關閉生產者:
在消息發送完成后,調用
producer.close方法關閉生產者,釋放相關資源。這一步很重要,否則可能會導致資源泄漏。
運行這段代碼后,你會在控制臺看到每條消息發送的結果。如果一切正常,你會看到消息被成功發送到指定的主題和分區,并打印出相應的偏移量。如果發送過程中出現錯誤,也會打印出錯誤信息,你可以根據錯誤信息排查問題。
(三)消費者代碼實現
有了生產者發送消息,自然就需要消費者來接收和處理消息啦。下面是一個使用 Java 編寫的 Kafka 消費者示例代碼:
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class KafkaConsumerExample {public static void main(String[] args) {// Kafka集群地址String bootstrapServers = "localhost:9092";// 消費者組IDString groupId = "my-group";// 要消費的主題String topic = "my-topic";// 創建Kafka消費者配置Properties props = new Properties();// 指定Kafka集群地址props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);// 指定消費者組IDprops.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);// 鍵的反序列化器,將字節數組轉換為鍵,這里使用StringDeserializer將字節數組反序列化為字符串類型的鍵props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 值的反序列化器,將字節數組轉換為值,這里使用StringDeserializer將字節數組反序列化為字符串類型的值props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 當沒有初始偏移量或當前偏移量無效時,從最早的消息開始消費props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");// 創建Kafka消費者實例KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 訂閱主題consumer.subscribe(Collections.singletonList(topic));try {while (true) {// 拉取消息,設置超時時間為100毫秒ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("Consumed message with key: %s, value: %s, partition: %d, offset: %d%n",record.key(), record.value(), record.partition(), record.offset());}}} finally {// 關閉消費者,釋放資源consumer.close();}}
}
代碼解釋:
-
配置消費者屬性:
同樣創建一個
Properties對象來配置 Kafka 消費者。BOOTSTRAP_SERVERS_CONFIG指定 Kafka 集群地址,消費者通過這個地址連接到集群。GROUP_ID_CONFIG指定消費者組 ID,同一消費者組內的消費者會共同消費主題的消息,并且 Kafka 會保證同一個分區的消息只會被組內的一個消費者消費,實現負載均衡。KEY_DESERIALIZER_CLASS_CONFIG和VALUE_DESERIALIZER_CLASS_CONFIG分別指定消息鍵和值的反序列化器,將從 Kafka 接收到的字節數組轉換為 Java 對象。AUTO_OFFSET_RESET_CONFIG配置了消費者在沒有初始偏移量或當前偏移量無效時的行為,這里設置為earliest,表示從最早的消息開始消費;如果設置為latest,則從最新的消息開始消費。 -
創建消費者實例:
使用配置好的屬性創建
KafkaConsumer實例。 -
訂閱主題:
使用
consumer.subscribe方法訂閱要消費的主題。這里我們訂閱了一個名為my-topic的主題。如果要訂閱多個主題,可以將主題列表傳遞給subscribe方法。 -
拉取并處理消息:
在一個無限循環中,使用
consumer.poll方法拉取消息。poll方法會阻塞當前線程,直到有新消息到達或者超時。這里我們設置超時時間為 100 毫秒。每次拉取到消息后,會返回一個ConsumerRecords對象,它包含了多個ConsumerRecord,每個ConsumerRecord代表一條消息。我們遍歷這些消息,并打印出消息的鍵、值、分區和偏移量。 -
關閉消費者:
當程序結束時,調用
consumer.close方法關閉消費者,釋放資源。
運行這段代碼后,消費者會持續從指定的主題中拉取消息,并在控制臺打印出消息的內容。你可以在生產者代碼中多發送一些消息,然后觀察消費者的輸出,看看是否能正確接收和處理消息。
(四)常見問題與解決方案
在使用 Java 操作 Kafka 的過程中,可能會遇到一些問題。下面是一些常見問題及其解決方案:
1. 連接超時:
-
問題描述:生產者或消費者在連接 Kafka 集群時,出現連接超時錯誤,提示類似于
org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.。 -
可能原因:
-
Kafka 集群地址配置錯誤,比如 IP 地址或端口號錯誤。
-
Kafka 集群沒有正常啟動,或者網絡連接存在問題。
-
防火墻阻止了生產者或消費者與 Kafka 集群的通信。
-
-
解決方案:
-
檢查
bootstrap.servers配置,確保 Kafka 集群地址正確無誤。 -
確認 Kafka 集群已經成功啟動,并且各個 Broker 之間通信正常。可以通過 Kafka 自帶的命令行工具(如
kafka-topics.sh)來檢查集群狀態。 -
檢查防火墻設置,確保生產者和消費者所在的機器能夠訪問 Kafka 集群的端口(默認是 9092)。如果是在云服務器上,還需要檢查安全組規則。
-
2. 消息丟失:
-
問題描述:生產者發送的消息在 Kafka 集群中丟失,消費者無法消費到。
-
可能原因:
-
生產者發送消息時沒有正確處理錯誤,比如在異步發送時,沒有在回調函數中處理發送失敗的情況。
-
Kafka 的副本同步出現問題,導致消息還未同步到其他副本,主副本就發生了故障,從而消息丟失。
-
生產者設置了不合理的
acks參數。acks參數表示生產者在收到多少個副本的確認后才認為消息發送成功。如果設置為0,生產者不會等待任何確認,消息可能會因為網絡問題而丟失;如果設置為1,生產者只等待主副本的確認,當主副本確認后但還未同步到其他副本時主副本故障,消息也可能丟失;只有設置為all或-1,生產者才會等待所有同步副本的確認,這樣可以最大程度保證消息不丟失,但會影響性能。
-
-
解決方案:
-
在生產者發送消息時,正確處理回調函數中的錯誤,確保在發送失敗時進行適當的重試或其他處理。
-
確保 Kafka 集群的副本同步正常,可以通過監控工具(如 Kafka Manager)查看副本的同步狀態。同時,合理設置
replication.factor(副本因子)和min.insync.replicas(最小同步副本數),保證數據的可靠性。 -
根據業務需求,合理設置生產者的
acks參數。如果對消息可靠性要求極高,建議設置為all或-1,并適當調整retries(重試次數)和retry.backoff.ms(重試間隔時間)參數。
-
3. 重復消費:
-
問題描述:消費者多次消費到同一條消息。
-
可能原因:
-
消費者在消費消息后,沒有及時提交偏移量(offset),導致在重新啟動或發生再均衡(rebalance)時,從上次未提交的偏移量開始消費,從而重復消費。
-
自動提交偏移量時,提交的時機不當。比如在消息還未處理完成時就提交了偏移量,當消費者重啟后,會從已提交的偏移量開始消費,導致之前未處理完的消息被重新消費。
-
-
解決方案:
-
如果使用手動提交偏移量,確保在消息處理完成后再提交偏移量。可以使用
commitSync(同步提交)或commitAsync(異步提交)方法。同步提交會阻塞當前線程,直到提交成功;異步提交不會阻塞線程,但需要注意處理回調函數中的錯誤。 -
如果使用自動提交偏移量,合理設置
enable.auto.commit(是否開啟自動提交)和auto.commit.interval.ms(自動提交間隔時間)參數。確保在消息處理完成后,再進行自動提交,避免消息處理過程中提交偏移量。
-
4. 分區分配不均:
-
問題描述:在消費者組中,各個消費者分配到的分區數量不均衡,導致部分消費者負載過高,部分消費者負載過低。
-
可能原因:
-
消費者組中的消費者數量與主題的分區數量不匹配。比如消費者數量大于分區數量,就會有部分消費者空閑;消費者數量小于分區數量,就會導致部分消費者需要處理多個分區的消息,負載過高。
-
分區分配策略設置不合理。Kafka 提供了多種分區分配策略,如 Range、RoundRobin、Sticky 等,如果策略設置不當,可能會導致分區分配不均。
-
-
解決方案:
-
根據主題的分區數量,合理調整消費者組中的消費者數量,盡量使消費者數量與分區數量保持一致,或者是分區數量的整數倍,以實現負載均衡。
-
根據業務需求,選擇合適的分區分配策略。如果希望分區分配更加均勻,可以使用 RoundRobin 策略;如果希望盡量保持之前的分區分配結果,減少不必要的再均衡,可以使用 Sticky 策略。可以通過在消費者配置中設置
partition.assignment.strategy參數來指定分區分配策略。
-
七、總結與展望
在 Java 開發的廣闊天地中,Kafka 無疑是一顆耀眼的明星,憑借其卓越的性能和豐富的特性,為開發者們解決了諸多數據傳輸與處理的難題 。它就像是一位神通廣大的超級英雄,在大數據處理、消息隊列、日志收集、實時數據處理等多個領域大顯身手,成為了分布式系統架構中不可或缺的一部分 。
通過對 Kafka 的深入學習,我們了解到它的高吞吐量、低延遲、持久化存儲和可擴展性等特性,這些特性使得 Kafka 能夠輕松應對各種復雜的業務場景 。在架構方面,Kafka 的 Producer、Consumer、Broker、Topic、Partition 和 Replica 等核心組件相互協作,構建了一個高效、可靠的分布式消息系統 。從原理上看,消息的生產、存儲和消費過程都有著精妙的設計,分區策略、序列化機制、日志結構存儲等技術細節,都體現了 Kafka 的強大之處 。
在實際應用中,Kafka 在日志收集與處理、消息隊列與解耦、用戶活動跟蹤、運營指標監控和流式處理等場景中發揮著關鍵作用 。它就像是一條無形的紐帶,將各個業務系統緊密地連接在一起,實現了數據的高效流通和共享 。通過 Java 操作 Kafka 的實戰,我們也掌握了如何在項目中實際運用 Kafka,從環境搭建到生產者和消費者的代碼實現,再到常見問題的解決,這些實踐經驗都將為我們今后的開發工作提供有力的支持 。
Kafka 的發展前景一片光明 。隨著大數據和分布式系統技術的不斷發展,Kafka 也在持續演進 。在流處理能力方面,KSQL 和 Kafka Streams 將不斷增強,能夠處理更加復雜的流處理任務,為實時數據處理提供更強大的支持 。在云原生支持方面,Kafka 與 Kubernetes 等容器編排工具的集成將更加緊密,使得 Kafka 在云原生環境中的部署和管理更加便捷,能夠更好地適應云計算時代的發展需求 。同時,Kafka 在多租戶支持、運維和監控工具、存儲引擎等方面也將不斷優化和改進,以滿足企業日益增長的業務需求 。
對于廣大 Java 開發者來說,Kafka 是一個值得深入學習和掌握的技術 。它不僅能夠提升我們在分布式系統開發方面的能力,還能為我們打開大數據處理的大門,讓我們在數據驅動的時代中搶占先機 。希望大家通過本文的學習,對 Kafka 有更深入的了解,并在實際項目中充分發揮 Kafka 的優勢,創造出更加高效、可靠的分布式系統 。讓我們一起搭乘 Kafka 這趟技術快車,駛向大數據和分布式系統開發的未來!
)
)



)

)



)
帶論文文檔1萬字以上,文末可獲取,系統界面在最后面。)






