一、開篇:為何踏上雙 Backbone 探索之路
????????在目標檢測的領域中,YOLOv8 憑借其高效與精準脫穎而出,成為眾多開發者和研究者的得力工具。然而,傳統的單 Backbone 架構,盡管已經在諸多場景中表現出色,但仍存在一些難以忽視的局限性。
????????單 Backbone 架構下,特征提取的能力存在一定瓶頸。它在捕捉細節特征與宏觀語義信息時,往往難以做到完美平衡。在面對復雜場景,如擁擠的城市街道中的車輛檢測,或者自然環境中多種類動物的識別時,單 Backbone 可能會因為無法同時兼顧局部細節和全局結構,導致出現誤檢或漏檢的情況。此外,隨著計算機視覺領域不斷拓展應用邊界,對目標檢測模型在多尺度目標、不同模態數據融合等方面的要求日益提高,單 Backbone 在擴展性上的不足也逐漸凸顯。
????????正是基于這些挑戰,雙 Backbone 架構成為了提升 YOLOv8 性能的一個極具潛力的方向。通過引入兩個不同的主干網絡,我們期望能夠融合更多元化的特征信息,從而實現更強大的目標檢測能力。
二、YOLOv8 單 Backbone 架構回眸
????????YOLOv8 的單 Backbone 架構采用了精心設計的卷積神經網絡結構,旨在高效地從輸入圖像中提取多層次的特征圖。它通過一系列精心設計的卷積模塊、池化操作等,逐步對圖像進行抽象和特征提取。例如,在其骨干網絡中,通過不斷調整卷積核的大小、步長等參數,實現對不同尺度目標的初步感知。
????????然而,這種單 Backbone 架構也有其內在的局限。一方面,其感受野的局限性使得在處理大場景或者遠距離目標時,難以充分捕捉目標之間的關系。比如在監控大片區域時,對于遠處的小目標,可能無法準確識別其類別和位置。另一方面,單 Backbone 的特征提取路徑相對單一,難以在同一時間對不同語義層級的信息進行全面捕捉。這在處理包含多種類型目標,且目標之間存在復雜遮擋關系的場景時,會導致模型的判斷失誤。
三、雙 Backbone 架構揭秘:多維度特征融合之道
雙 Backbone 架構在 YOLOv8 中的實現,主要分為共享輸入和雙輸入兩種典型結構。
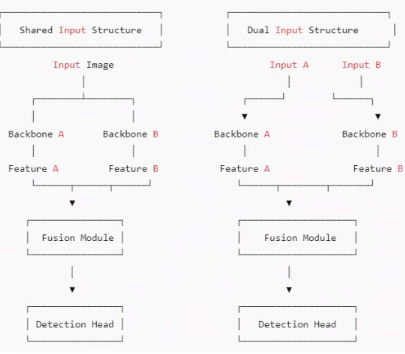
1. 共享輸入的雙 Backbone 結構
????????共享輸入的雙 Backbone 結構,就像是為模型開啟了兩扇不同視角的窗戶。它允許模型在處理同一幅圖像時,通過兩條并行的特征提取路徑,從不同的尺度和角度去理解圖像內容。一條路徑可以專注于提取圖像中目標的淺層紋理和邊緣信息,就像我們用放大鏡去觀察目標的細節;而另一條路徑則可以深入挖掘圖像的深層語義和結構關系,如同站在高處俯瞰全局。
????????這種結構帶來的優勢顯而易見。它極大地增強了模型對目標的判別能力,無論是面對微小的細節差異,還是復雜的語義關聯,都能有更準確的判斷。同時,對于不同尺度的目標,兩條路徑的特征融合也使得模型能夠更好地適應,不會因為目標過大或過小而出現檢測偏差。而且,在訓練和部署過程中,由于共享同一輸入圖像,參數的優化相對更加穩定,減少了模型出現不穩定訓練狀態的風險。
2. 雙輸入的雙 Backbone 結構
????????雙輸入的雙 Backbone 架構則更進一步,打破了傳統模型僅依賴單一圖像輸入的限制。它允許兩個 Backbone 分別處理不同來源的輸入,這些輸入可以是不同模態的數據,比如 RGB 圖像與深度圖像的結合,或者是不同時間點的圖像序列。
????????在實際應用中,這種結構展現出了強大的適應性。在多視角融合場景中,不同攝像頭采集的圖像通過各自的 Backbone 處理后,能夠相互補充視角盲區,讓模型能夠感知到更廣闊的場景范圍。這種結構不僅豐富了模型可利用的信息維度,還為其在多模態融合、時序建模等新興任務中提供了廣闊的發展空間。
四、雙 Backbone 的多元組合及獨特魅力
????????在 YOLOv8 的雙 Backbone 架構中,不同的組合方式猶如為模型調配出不同的 “能力配方”,以適應多樣化的任務需求。
1. CNN + CNN(輕量高效組合)
????????將兩個不同的 CNN 進行組合,是一種兼顧速度與性能的策略。例如,我們可以選擇一個輕量級的 CNN,如 MobileNet,它能夠快速地捕捉圖像中的淺層特征,就像快速掃描圖像的輪廓和大致紋理。再搭配一個相對較重但語義建模能力更強的 CNN,比如 ResNet。ResNet 可以深入挖掘圖像的深層語義信息,理解圖像中目標的內在關系。
????????這種組合方式特別適用于對實時性要求較高的場景,如自動駕駛中的實時目標檢測。輕量級的 CNN 可以保證模型在有限的計算資源下快速運行,而較重的 CNN 則確保了檢測的準確性。通過合理的特征融合策略,將兩者提取的特征進行整合,能夠在不犧牲太多速度的前提下,顯著提升模型對復雜背景和小目標的檢測能力。
2. CNN + Transformer(語義強化組合)
????????Transformer 的引入為 YOLOv8 帶來了全新的語義理解維度。我們都知道,CNN 擅長捕捉局部的紋理和空間結構信息,但在處理長距離依賴關系時往往力不從心。而 Transformer 則以其強大的自注意力機制,能夠在全局范圍內對圖像中的元素進行關聯和建模。
????????在這種組合中,我們可以讓 CNN 先處理圖像的低級特征,構建起目標的基本形態和局部細節。然后,將這些特征傳遞給 Transformer,由 Transformer 來梳理圖像中各個目標之間的長距離關系,理解它們的語義關聯。這種強強聯合的方式,在處理復雜場景,如大型集會中的人群檢測,或者密集停車場中的車輛檢測時,能夠極大地提升模型對目標的準確識別和定位能力,盡管計算量會有所增加,但在追求高精度的任務中,這種付出是值得的。
3. CNN + Mamba(動態感知組合)
????????Mamba 作為一種新興的架構,在處理長距離依賴和動態信息方面展現出了獨特的優勢。與 CNN 結合時,CNN 依舊負責提取圖像的靜態空間結構和紋理信息,而 Mamba 則專注于捕捉圖像中跨通道、跨區域甚至跨時間的動態信息。
????????在視頻目標檢測任務中,這種組合能夠更好地理解目標的運動軌跡和行為模式。例如在體育賽事視頻分析中,準確捕捉運動員的動作和位置變化。在遙感圖像分析領域,也能更有效地分析地理目標隨時間的變化情況。這種組合為 YOLOv8 賦予了更強的動態感知能力,使其在處理強調時間連續性和上下文理解的任務時,能夠游刃有余。
五、邁向實踐:YOLOv8 雙 Backbone 代碼實踐指引
代碼獲取:YOLOv8_improve/YOLOv8雙backbone at master · tgf123/YOLOv8_improve
1. 數據集
數據集的格式如下所示,如果是共享輸入(也就是輸入同一張圖片,那就將圖片復制一份,命名為train2 val2 test2),如果是雙模太數據集,那就如下所示:
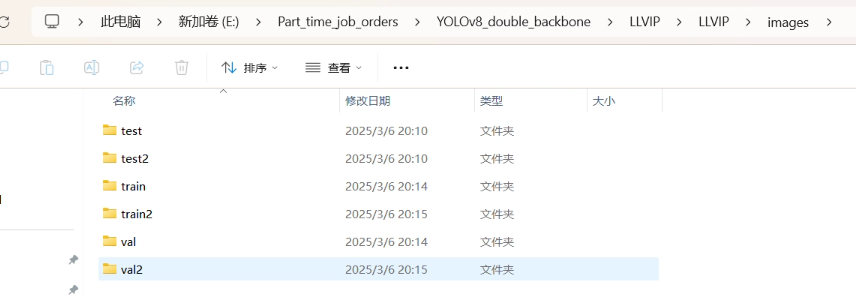
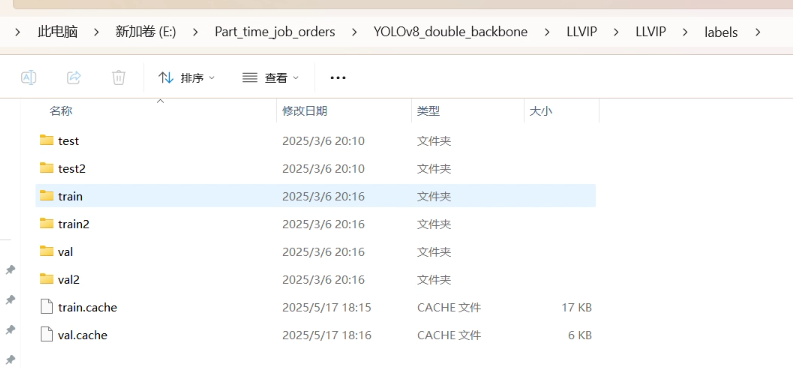
代碼中的數據集的配置文件如下所示:
# Train/val/test sets as dir: path/to/imgs
path: E:/Part_time_job_orders/YOLOv8_double_backbone/LLVIP/LLVIPtrain: images/train # train visible images (relative to 'path')
train2: images/train2 # train infrared images (relative to 'path')val: images/val # val visible images (relative to 'path')
val2: images/val2 # val infrared images (relative to 'path')test: # test images (optional)
test2: # test images (optional)#image_weights: True
nc: 1# Classes
names:0: Person2. CNN + CNN(輕量高效組合)
?首先看一下跑CNN+CNN組合的雙backbone,這個分為兩種,一個就是在在最基礎的YOLO backbone+YOLO backbone的基礎上改進,比如一個backbone不動,另一個對其改進,比如對C2F、sppf等。第二種就是YOLO backbone+其他的CNN backbone(ShuffleNetV1、starnet等)。比如下面兩幅圖,一個是YOLO backbone+YOLO backbone,一個是YOLO backbone+其他的CNN backbone
3. CNN + Transformer
CNN+Transformer組合的雙backbone,這個分為兩種,一個就是在在最基礎的YOLO backbone+YOLO backbone的基礎上改進,比如一個backbone不動,另一個對其改進,比如添加Transformer相關的模塊。第二種就是YOLO backbone+其他的Transformer backbone(Swintransformer等)。比如下面兩幅圖,一個是YOLO backbone+YOLO backbone,一個是YOLO backbone+其他的Transformer backbone
?




ModalAI VOXL)









】)




Canvas基礎(萬字圖文講解))