Kubernetes 網絡架構的設計目標是為 Pod 提供一個高效、靈活且可擴展的網絡環境,同時確保 Pod 之間的通信簡單直接,類似于在同一個物理網絡中。以下是 Kubernetes 網絡架構的原理和核心組件的詳細解析:
一、Kubernetes 網絡模型的基本原則
Kubernetes 的網絡模型遵循以下三個基本原則:
1.每個 Pod 都有一個獨立的 IP 地址:
Pod 內的容器共享網絡命名空間,可以通過 localhost 相互訪問。
Pod 之間的通信不需要 NAT(網絡地址轉換),可以直接通過 IP 地址訪問。
Pod 的 IP 地址在集群內是唯一的,即使 Pod 被重新調度到其他節點,IP 地址也會保持不變。
2.Pod 之間的通信是直接的:
Pod 可以通過 IP 地址直接與其他 Pod 通信,而不需要經過額外的代理或網關。
這種直接通信的方式簡化了網絡配置,提高了通信效率。
3.Pod 的網絡配置是動態的:
Pod 的生命周期是短暫的,可能會因為更新、故障等原因被銷毀和重建。
Kubernetes 通過 CNI(容器網絡接口)插件動態管理 Pod 的網絡配置。
二、Kubernetes 網絡架構的核心組件
1.Pod 網絡
Pod 是 Kubernetes 中的最小部署單位,每個 Pod 都有一個獨立的網絡命名空間。Pod 網絡的實現依賴于 CNI 插件,常見的 CNI 插件包括 Flannel、Calico 和 WeaveNet。
Flannel:
使用 VXLAN 或 UDP 封裝數據包,實現跨節點的 Pod 通信。
簡單易用,適合中小規模集群。
通過 etcd 存儲網絡配置信息。
Calico:
基于 BGP 協議,直接在物理網絡上建立路由,無需封裝。
支持高性能路由和細粒度的網絡策略。
適合大規模集群,性能優于 Flannel。
WeaveNet:
提供加密的 Pod 到 Pod 通信,確保數據傳輸的安全性。
支持網絡隔離和加密功能。
2.Service 網絡
Service 是 Kubernetes 中用于抽象 Pod 的邏輯集合,通過一個穩定的虛擬 IP(ClusterIP)和端口將流量轉發到后端 Pod。
kube-proxy:
運行在每個節點上,負責實現 Service 的負載均衡和網絡代理功能。
使用 iptables 或 IPVS 規則將流量轉發到后端 Pod。
支持多種負載均衡算法,如輪詢、最少連接等。
Endpoint:
Endpoint 是 Service 和 Pod 之間的映射關系,記錄了所有健康且可用的 Pod 的 IP 地址和端口。
Endpoint Controller 會監控 Pod 的狀態變化,并動態更新 Endpoint 列表。
3.Ingress 網絡
Ingress 是 Kubernetes 中用于管理外部訪問到集群內服務的 HTTP/HTTPS 流量。
Ingress Controller:
監控 Ingress 資源,動態生成和更新路由規則。
常見的 Ingress Controller 包括 Nginx Ingress Controller、Traefik 等。
提供負載均衡、SSL/TLS 終端、重定向等功能。
Ingress 資源:
定義了 HTTP/HTTPS 流量的路由規則,包括路徑、后端 Service 和域名等。
示例配置:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:name: example-ingress
spec:rules:- host: example.comhttp:paths:- path: /path1pathType: Prefixbackend:service:name: service1port:number: 80- path: /path2pathType: Prefixbackend:service:name: service2port:number: 80
4.網絡策略
Kubernetes 支持通過 NetworkPolicy 資源定義 Pod 之間的訪問規則,控制流量的流入和流出。
NetworkPolicy:
定義了 Pod 之間的網絡隔離策略,支持白名單和黑名單模式。
示例配置:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:name: allow-access
spec:podSelector:matchLabels:role: frontendingress:- from:- podSelector:matchLabels:role: backend
三、Kubernetes 網絡架構的工作原理
1.Pod 網絡的創建和管理
當一個新的 Pod 被創建時,CNI 插件會為 Pod 分配一個 IP 地址,并將其加入到集群的網絡中。CNI 插件通過以下步驟實現 Pod 網絡的創建:
**1.分配 IP 地址:**從預定義的 IP 池中為 Pod 分配一個唯一的 IP 地址。
**2.創建網絡接口:**在宿主機上創建一個虛擬網絡接口(如 veth pair),并將一個端連接到 Pod 的網絡命名空間。
**3.配置路由:**在宿主機上配置路由規則,確保 Pod 的流量能夠正確轉發到目標 Pod。
2. Service 的流量轉發
Service 通過一個穩定的虛擬 IP(ClusterIP)和端口將流量轉發到后端 Pod。kube-proxy 負責實現 Service 的負載均衡和網絡代理功能,其工作原理如下:
1.監控 Endpoint 列表:kube-proxy 會監控 Service 的 Endpoint 列表,動態更新后端 Pod 的 IP 地址和端口。
2.配置 iptables 或 IPVS 規則:kube-proxy 會根據 Endpoint 列表配置 iptables 或 IPVS 規則,將流量轉發到后端 Pod。
3.負載均衡:kube-proxy 使用負載均衡算法(如輪詢、最少連接等)將流量分配到后端 Pod。
3. Ingress 的流量管理
Ingress Controller 負責管理外部訪問到集群內服務的 HTTP/HTTPS 流量。其工作原理如下:
監控 Ingress 資源:Ingress Controller 會監控 Ingress 資源,動態生成和更新路由規則。
解析域名和路徑:Ingress Controller 根據 Ingress 資源的配置,解析請求的域名和路徑,將流量轉發到對應的 Service。
負載均衡:Ingress Controller 使用負載均衡算法將流量分配到后端的 Pod。
4. 網絡策略的執行
NetworkPolicy 資源定義了 Pod 之間的訪問規則,CNI 插件負責執行這些規則。其工作原理如下:
監控 NetworkPolicy 資源:CNI 插件會監控 NetworkPolicy 資源,動態更新網絡策略。
配置防火墻規則:CNI 插件會根據 NetworkPolicy 資源的配置,為 Pod 配置防火墻規則,控制流量的流入和流出。
四、Calico網絡走向
BGP(Border Gateway Protocol,邊界網關協議)是一種用于在不同自治系統(Autonomous Systems,AS)之間交換路由信息的協議。它是互聯網的核心路由協議之一,主要用于實現跨網絡的路由選擇和路徑優化。
BGP 的工作原理
1.建立 BGP 會話:
BGP 對等體(peers)之間通過 TCP 連接建立會話。默認情況下,BGP 使用 TCP 端口 179。
會話建立后,對等體之間交換路由信息。
2.路由信息交換:
BGP 對等體之間交換路由信息,包括前綴(IP 地址范圍)、下一跳地址、自治系統路徑(AS_PATH)等。
每個 BGP 對等體維護一個路由表,記錄到達各個目的地的最優路徑。
3.路徑選擇:
BGP 使用多種屬性來選擇最優路徑,包括:
AS_PATH:記錄到達目的地所經過的自治系統路徑,用于避免環路。
本地優先級(Local Preference):用于在自治系統內部選擇最優路徑。
權重(Weight):僅在本地路由器上使用,用于選擇最優路徑。
MED(Multi-Exit Discriminator):用于在多個出口點選擇最優路徑。
IGP 度量值:用于選擇自治系統內部的最優路徑。
4.路由傳播:
BGP 對等體之間定期交換路由更新信息,以確保路由表的一致性。
路由更新信息包括新增、刪除和修改的路由。
Calico 網絡架構圖
以下是 Calico 的簡化架構圖,用于說明流量走向:
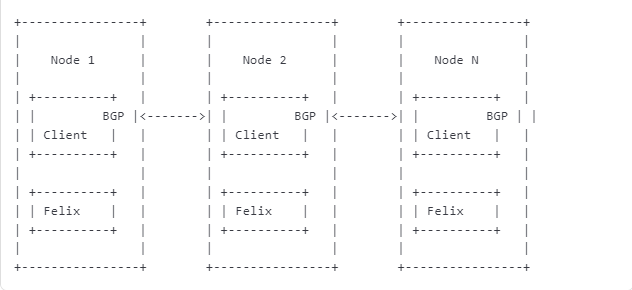
一、架構圖中的核心組件
Node:
每個 Kubernetes 節點上運行的組件。
包括 Felix、BGP 客戶端等。
Felix:
運行在每個節點上的代理進程。
負責管理網絡接口、路由規則、ACL 規則等。
Felix 監聽 etcd 中的配置變化,并在本地應用這些配置。
BGP 客戶端:
負責廣播和接收路由信息。
使用 BGP 協議將本地節點的路由信息傳播到其他節點。
etcd:
分布式鍵值存儲,用于存儲 Calico 的網絡配置和狀態信息。
確保網絡元數據的一致性。
二、流量走向解析
1.Pod 創建時的流量走向
假設在 Node 1 上創建了一個新的 Pod A:
1.IP 分配:
Felix 從 etcd 中獲取 IP 池信息,為 Pod A 分配一個 IP 地址(例如 192.168.1.2)。
這個 IP 地址屬于 Node 1 的子網范圍(例如 192.168.1.0/24)。
2.網絡接口配置:
Felix 在 Node 1 上創建一個虛擬網絡接口(如 veth),并將一端連接到 Pod A 的網絡命名空間,另一端連接到虛擬網橋(如 cali0)。
Felix 在內核路由表中添加一條路由規則,將 Pod A 的 IP 地址(192.168.1.2)指向虛擬網橋(cali0)。
3.BGP 路由廣播:
Felix 將 Pod A 的路由信息(192.168.1.2/32)注入到 BGP 客戶端。
BGP 客戶端將這條路由信息通過 BGP 協議廣播到其他節點(Node 2、Node N 等)。
其他節點的 BGP 客戶端接收到路由信息后,將其添加到本地路由表中。
2.跨節點 Pod 通信的流量走向
假設 Pod A(在 Node 1 上)需要與 Pod B(在 Node 2 上)通信:
1.發送流量:
Pod A 發送一個數據包到 Pod B 的 IP 地址(例如 192.168.2.2)。
數據包首先到達 Node 1 上的虛擬網橋(cali0)。
2.查找路由:
Node 1 的內核路由表根據 Pod B 的 IP 地址(192.168.2.2)查找路由。
路由表中有一條指向 Node 2 的路由(通過 BGP 協議廣播的)。
3.轉發到目標節點:
數據包通過 Node 1 的物理網絡接口發送到 Node 2。
Node 2 接收到數據包后,根據本地路由表將數據包轉發到虛擬網橋(cali0)。
4.到達目標 Pod:
數據包從 Node 2 的虛擬網橋(cali0)到達 Pod B 的虛擬網絡接口(veth)。
Pod B 接收到數據包并處理。
3.網絡策略的流量控制
假設為 Pod A 和 Pod B 定義了網絡策略,限制 Pod A 只能訪問 Pod B 的特定端口(例如 TCP 80):
1.策略配置:
網絡策略通過 Kubernetes 的 NetworkPolicy 資源定義。
Calico 的 Felix 會將這些策略轉換為 iptables 或 eBPF 規則。
2.流量過濾:
當 Pod A 發送數據包到 Pod B 時,數據包首先到達 Node 1 的虛擬網橋(cali0)。
Felix 在 Node 1 上應用的 iptables 或 eBPF 規則會檢查數據包是否符合網絡策略。
如果數據包符合策略(例如目標端口是 TCP 80),則允許通過;否則,丟棄數據包。
3.返回流量:
Pod B 的響應數據包會通過相同的路徑返回到 Pod A。
在 Node 2 上,Felix 也會檢查返回流量是否符合網絡策略。
三、架構圖中的流量走向示例
1.Pod A(Node 1)到 Pod B(Node 2)的流量走向
Pod A (192.168.1.2) --> Node 1 (cali0) --> Node 1 (路由表) --> Node 2 (物理網絡) --> Node 2 (路由表) --> Node 2 (cali0) --> Pod B (192.168.2.2)
2.返回流量(Pod B 到 Pod A)
Pod B (192.168.2.2) --> Node 2 (cali0) --> Node 2 (路由表) --> Node 1 (物理網絡) --> Node 1 (路由表) --> Node 1 (cali0) --> Pod A (192.168.1.2)
四、Calico 的優勢
1.高性能:
使用純三層網絡模型,無封裝開銷,性能高。
數據包直接通過物理網絡傳輸,無需額外的解封裝處理。
2.安全性:
支持細粒度的網絡策略,通過 iptables 或 eBPF 規則實現流量控制。
3.可擴展性:
使用 BGP 協議,適合大規模集群。
可以通過 BGP Route Reflector 減少 BGP 連接數量,提高效率。
五、總結
Calico 通過純三層網絡模型和 BGP 協議實現了高效的 Pod 通信。在跨節點通信中,數據包通過內核路由表和物理網絡傳輸,無需額外的封裝和解封裝。同時,Calico 的網絡策略功能確保了流量的安全性。這種設計使得 Calico 成為 Kubernetes 環境中一個高性能、可擴展且安全的網絡解決方案。
五、Flannel 網絡走向
VXLAN(Virtual Extensible LAN)是一種網絡虛擬化技術,用于在大型數據中心和云環境中創建虛擬網絡。它通過在物理網絡之上構建一個虛擬的、可擴展的網絡層,解決了傳統 VLAN(Virtual LAN)技術在大規模環境中的限制。
VXLAN 的工作原理
VXLAN 通過在以太網幀中封裝額外的 VXLAN 頭來實現虛擬網絡。以下是其工作原理的詳細說明:
1.封裝和解封裝
封裝:當一個虛擬機(VM)發送數據包時,VXLAN 網關(通常是虛擬交換機或物理交換機)會將原始以太網幀封裝到一個 UDP 數據包中。封裝的 UDP 數據包包含一個 8 字節的 VXLAN 頭,其中包含 VNI。
解封裝:當數據包到達目標 VXLAN 網關時,網關會解封裝 UDP 數據包,提取原始以太網幀,并將其轉發到目標 VM。
2.VXLAN 頭結構
VXLAN 頭包含以下字段:
VNI(VXLAN Network Identifier):24 位字段,用于標識不同的虛擬網絡。
Flags:8 位字段,其中第 3 位(I)必須設置為 1,表示 VNI 字段有效。
Reserved:保留字段,用于未來擴展。
3.VXLAN 網關
VXLAN 網關是實現 VXLAN 功能的關鍵組件,通常由虛擬交換機(如 VMware vSphere Distributed Switch 或 Open vSwitch)或物理交換機實現。網關負責封裝和解封裝數據包,并管理 VXLAN 隧道。
4.VXLAN 隧道
VXLAN 使用 UDP 協議在物理網絡上傳輸封裝的數據包。每個 VXLAN 隧道由一個源 IP 地址和目標 IP 地址標識,這些地址通常是 VXLAN 網關的 IP 地址。
以下是 Flannel 的網絡原理和架構圖的詳細解析。

一、Flannel 網絡原理
1.覆蓋網絡(Overlay Network)
Flannel 使用覆蓋網絡技術,通過在現有物理網絡之上構建一個虛擬網絡層,實現跨主機的 Pod 通信。具體來說,Flannel 將 Pod 的網絡流量封裝在宿主機的網絡協議中(如 VXLAN 或 UDP),從而實現跨主機的通信。
2.子網分配
Flannel 為每個 Kubernetes 節點分配一個子網段,每個子網段中的 IP 地址用于該節點上的 Pod。例如:
集群的總 IP 池是 10.244.0.0/16。
每個節點分配一個 /24 的子網,如 10.244.1.0/24、10.244.2.0/24 等。
3.后端實現
Flannel 支持多種后端實現方式,包括:
VXLAN:使用虛擬擴展局域網(VXLAN)封裝數據包,適用于大多數環境。
UDP:使用 UDP 封裝數據包,適合不支持 VXLAN 的環境。
Host-GW:直接在物理網絡上建立路由,不使用封裝,性能最高,但需要集群節點在同一個 L2 網絡中。
Flannel 流量走向
1.Pod 創建時的流量走向
假設在 Node 1 上創建了一個新的 Pod A:
1.IP 分配:
Flannel Agent 從 etcd 或 Kubernetes API 中獲取子網信息,為 Pod A 分配一個 IP 地址(例如 10.244.1.2)。
這個 IP 地址屬于 Node 1 的子網范圍(例如 10.244.1.0/24)。
2.網絡接口配置:
Flannel Agent 在 Node 1 上創建一個虛擬網絡接口(如 veth),并將一端連接到 Pod A 的網絡命名空間,另一端連接到虛擬網橋(如 flannel.1)。
Flannel Agent 在內核路由表中添加一條路由規則,將 Pod A 的 IP 地址(10.244.1.2)指向虛擬網橋(flannel.1)。
2. 跨節點 Pod 通信的流量走向
假設 Pod A(在 Node 1 上)需要與 Pod B(在 Node 2 上)通信:
1.發送流量:
Pod A 發送一個數據包到 Pod B 的 IP 地址(例如 10.244.2.2)。
數據包首先到達 Node 1 上的虛擬網橋(flannel.1)。
2.封裝數據包:
Flannel Agent 檢查目標 IP 地址(10.244.2.2),發現它屬于 Node 2 的子網。
Flannel Agent 將數據包封裝在 VXLAN 或 UDP 數據包中,目標地址是 Node 2 的宿主機 IP。
3.傳輸到目標節點:
封裝后的數據包通過 Node 1 的物理網絡接口發送到 Node 2。
Node 2 接收到封裝后的數據包后,Flannel Agent 解封裝數據包,提取出原始的 Pod 數據包。
4.到達目標 Pod:
解封裝后的數據包被發送到 Node 2 上的虛擬網橋(flannel.1),并最終到達目標 Pod(Pod B)。
3. 返回流量(Pod B 到 Pod A)
返回流量的路徑與上述過程類似:
1.Pod B 發送數據包:
Pod B 發送一個數據包到 Pod A 的 IP 地址(例如 10.244.1.2)。
數據包首先到達 Node 2 上的虛擬網橋(flannel.1)。
2.封裝數據包:
Flannel Agent 將數據包封裝在 VXLAN 或 UDP 數據包中,目標地址是 Node 1 的宿主機 IP。
3.傳輸到目標節點:
封裝后的數據包通過 Node 2 的物理網絡接口發送到 Node 1。
Node 1 接收到封裝后的數據包后,Flannel Agent 解封裝數據包,提取出原始的 Pod 數據包。
4.到達目標 Pod:
解封裝后的數據包被發送到 Node 1 上的虛擬網橋(flannel.1),并最終到達目標 Pod(Pod A)。
五、Flannel 的優勢與局限性
優勢
簡單易用:
Flannel 的配置和使用相對簡單,適合中小規模的 Kubernetes 集群。
兼容性強:
支持多種后端實現(VXLAN、UDP、Host-GW),適用于不同的網絡環境。
社區支持:
作為 Kubernetes 官方推薦的 CNI 插件之一,Flannel 有廣泛的社區支持和豐富的文檔。
局限性
性能瓶頸:
在大規模集群中,VXLAN 和 UDP 后端可能會引入額外的網絡開銷,影響性能。
網絡復雜性:
雖然 Flannel 本身比較簡單,但覆蓋網絡的實現可能會增加網絡的復雜性,尤其是在故障排查時。
不支持網絡策略:
Flannel 本身不支持 Kubernetes 的 NetworkPolicy,需要額外的解決方案(如 Calico)來實現網絡隔離和訪問控制。



ModalAI VOXL)









】)




Canvas基礎(萬字圖文講解))
