目錄
簡介
一、遷移學習
1.什么是遷移學習
2. 遷移學習的步驟
二、殘差網絡ResNet
1.了解ResNet
2.ResNet網絡---殘差結構
三、代碼分析
1. 導入必要的庫
2. 模型準備(遷移學習)
3. 數據預處理
4. 自定義數據集類
5. 數據加載器
6. 設備配置
7. 訓練函數
8. 測試函數
9. 訓練配置和執行
整體流程總結
簡介
????????經過長久的卷積神經網絡的學習、我們學習了如何提高模型的準確率,但是最終我們的準確率還是沒達到百分之八十。原因是因為我們本身模型的局限,面對現有很多成熟的模型,它們有很好的效果,都是經過多次訓練選取了最佳的參數,那我們能不能去使用哪些大佬的模型呢?
????????答案是可以的,這就使用到遷移學習的知識。
深度學習之第五課卷積神經網絡 (CNN)如何訓練自己的數據集(食物分類)
深度學習之第六課卷積神經網絡 (CNN)如何保存和使用最優模型
深度學習之第七課卷積神經網絡 (CNN)調整學習率
一、遷移學習
1.什么是遷移學習
????????遷移學習是指利用已經訓練好的模型,在新的任務上進行微調。遷移學習可以加快模型訓練速度,提高模型性能,并且在數據稀缺的情況下也能很好地工作。
2. 遷移學習的步驟
????????1、選擇預訓練的模型和適當的層:通常,我們會選擇在大規模圖像數據集(如ImageNet)上預訓練的模型,如VGG、ResNet等。然后,根據新數據集的特點,選擇需要微調的模型層。對于低級特征的任務(如邊緣檢測),最好使用淺層模型的層,而對于高級特征的任務(如分類),則應選擇更深層次的模型。
????????2、凍結預訓練模型的參數:保持預訓練模型的權重不變,只訓練新增加的層或者微調一些層,避免因為在數據集中過擬合導致預訓練模型過度擬合。
????????3、在新數據集上訓練新增加的層:在凍結預訓練模型的參數情況下,訓練新增加的層。這樣,可以使新模型適應新的任務,從而獲得更高的性能。
????????4、微調預訓練模型的層:在新層上進行訓練后,可以解凍一些已經訓練過的層,并且將它們作為微調的目標。這樣做可以提高模型在新數據集上的性能。
????????5、評估和測試:在訓練完成之后,使用測試集對模型進行評估。如果模型的性能仍然不夠好,可以嘗試調整超參數或者更改微調層。
太多概念,我們直接使用殘差網絡進行遷移學習。
二、殘差網絡ResNet
1.了解ResNet
????????ResNet 網絡是在 2015年 由微軟實驗室中的何凱明等幾位大神提出,斬獲當年ImageNet競賽中分類任務第一名,目標檢測第一名。獲得COCO數據集中目標檢測第一名,圖像分割第一名。
傳統卷積神經網絡存在的問題?
卷積神經網絡都是通過卷積層和池化層的疊加組成的。 在實際的試驗中發現,隨著卷積層和池化層的疊加,學習效果不會逐漸變好,反而出現2個問題:
????????1、梯度消失和梯度爆炸 梯度消失:若每一層的誤差梯度小于1,反向傳播時,網絡越深,梯度越趨近于0 梯度爆炸:若每一層的誤差梯度大于1,反向傳播時,網絡越深,梯度越來越大
????????2、退化問題
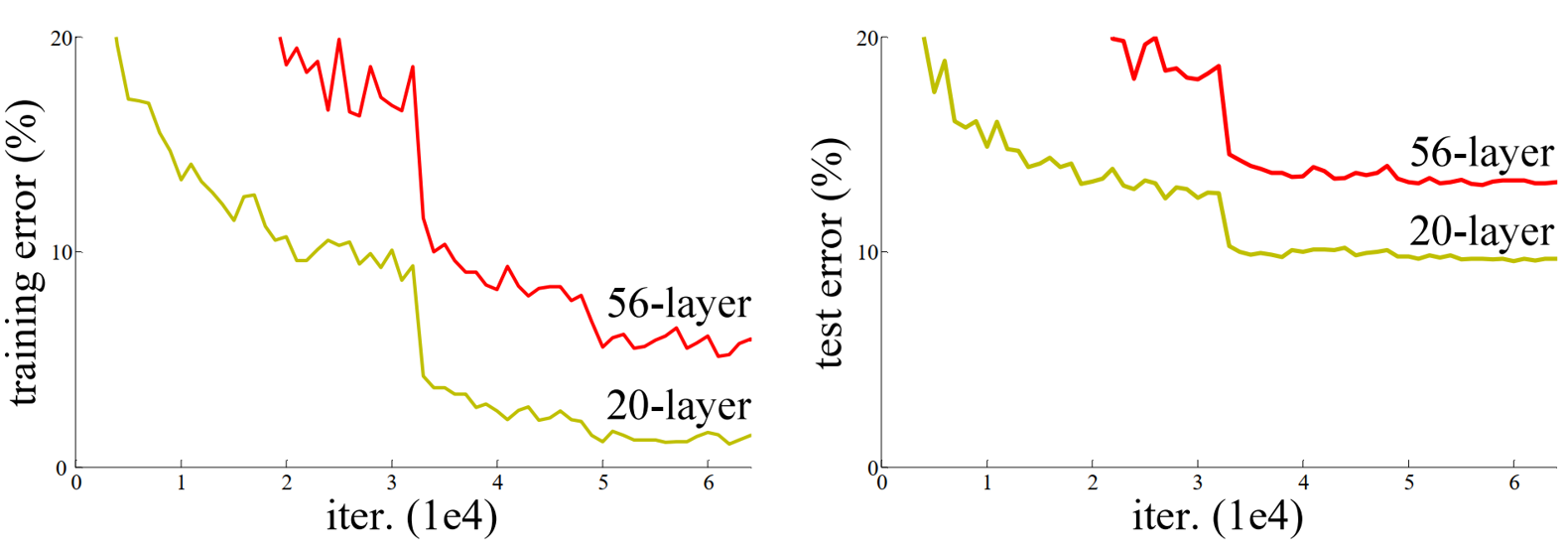
如何解決問題?
為了解決梯度消失或梯度爆炸問題,論文提出通過數據的預處理以及在網絡中使用 BN(Batch Normalization)層來解決。 為了解決深層網絡中的退化問題,可以人為地讓神經網絡某些層跳過下一層神經元的連接,隔層相連,弱化每層之間的強聯系。這種神經網絡被稱為 殘差網絡 (ResNets)。
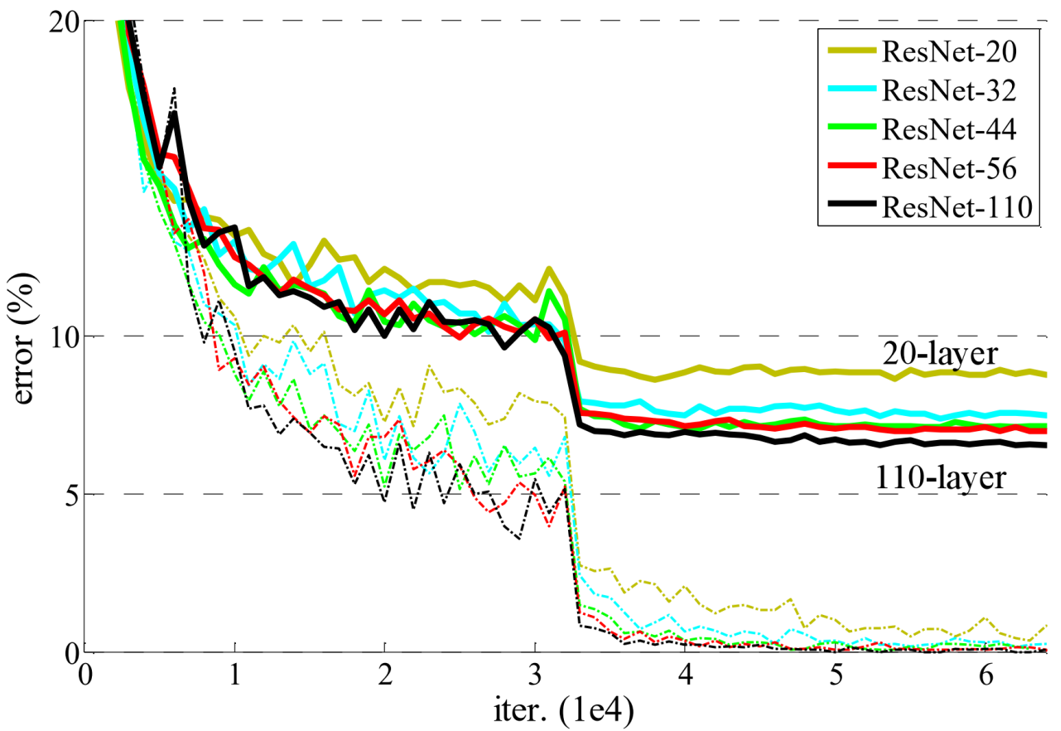
????????????????????????????????????????實線為測試集錯誤率 虛線為訓練集錯誤率
2.ResNet網絡---殘差結構
ResNet的經典網絡結構有:ResNet-18、ResNet-34、ResNet-50、ResNet-101、ResNet-152幾種,其中,ResNet-18和ResNet-34的基本結構相同,屬于相對淺層的網絡,后面3種的基本結構不同于ResNet-18和ResNet-34,屬于更深層的網絡。
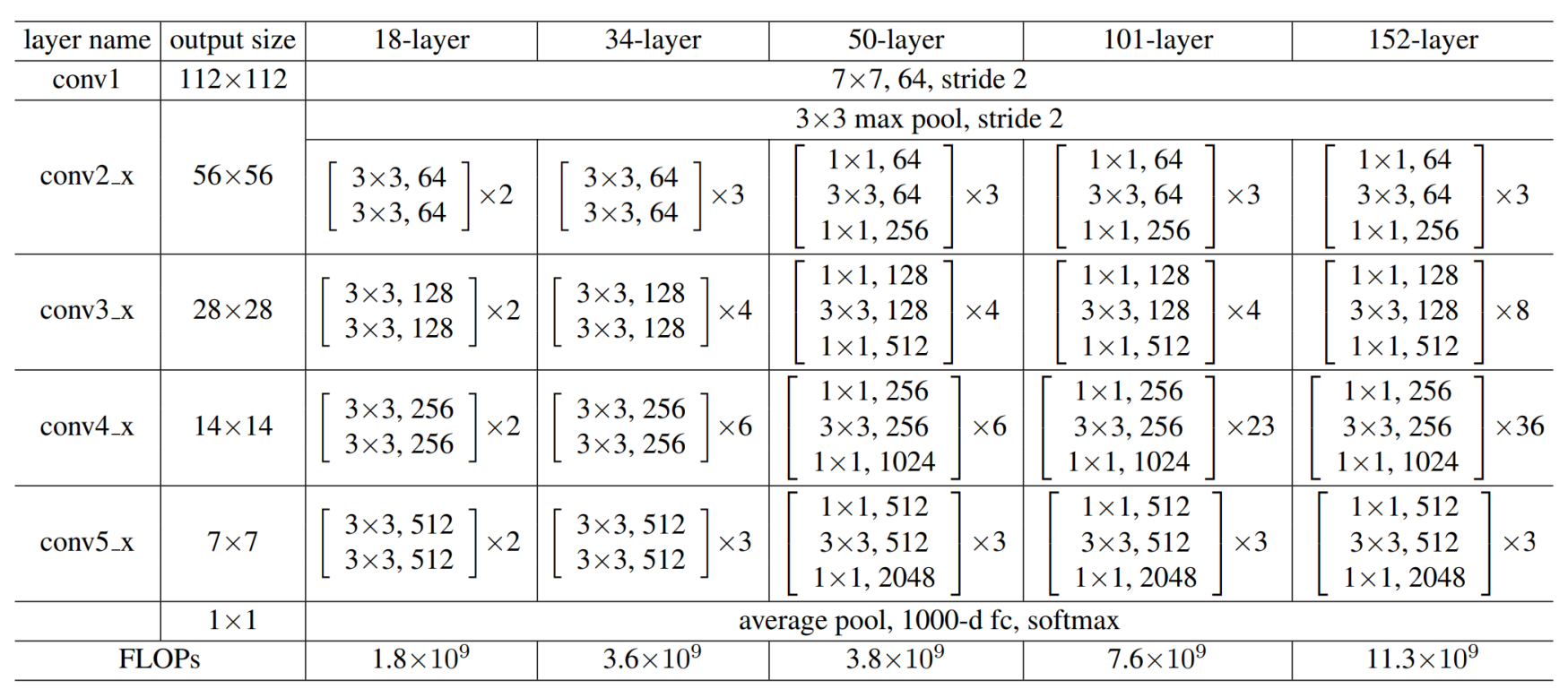
不論是多少層的ResNet網絡,它們都有以下共同點:
- 網絡一共包含5個卷積組,每個卷積組中包含1個或多個基本的卷積計算過程(Conv-> BN->ReLU)
- 每個卷積組中包含1次下采樣操作,使特征圖大小減半,下采樣通過以下兩種方式實現:
- 最大池化,步長取2,只用于第2個卷積組(Conv2_x)
- 卷積,步長取2,用于除第2個卷積組之外的4個卷積組
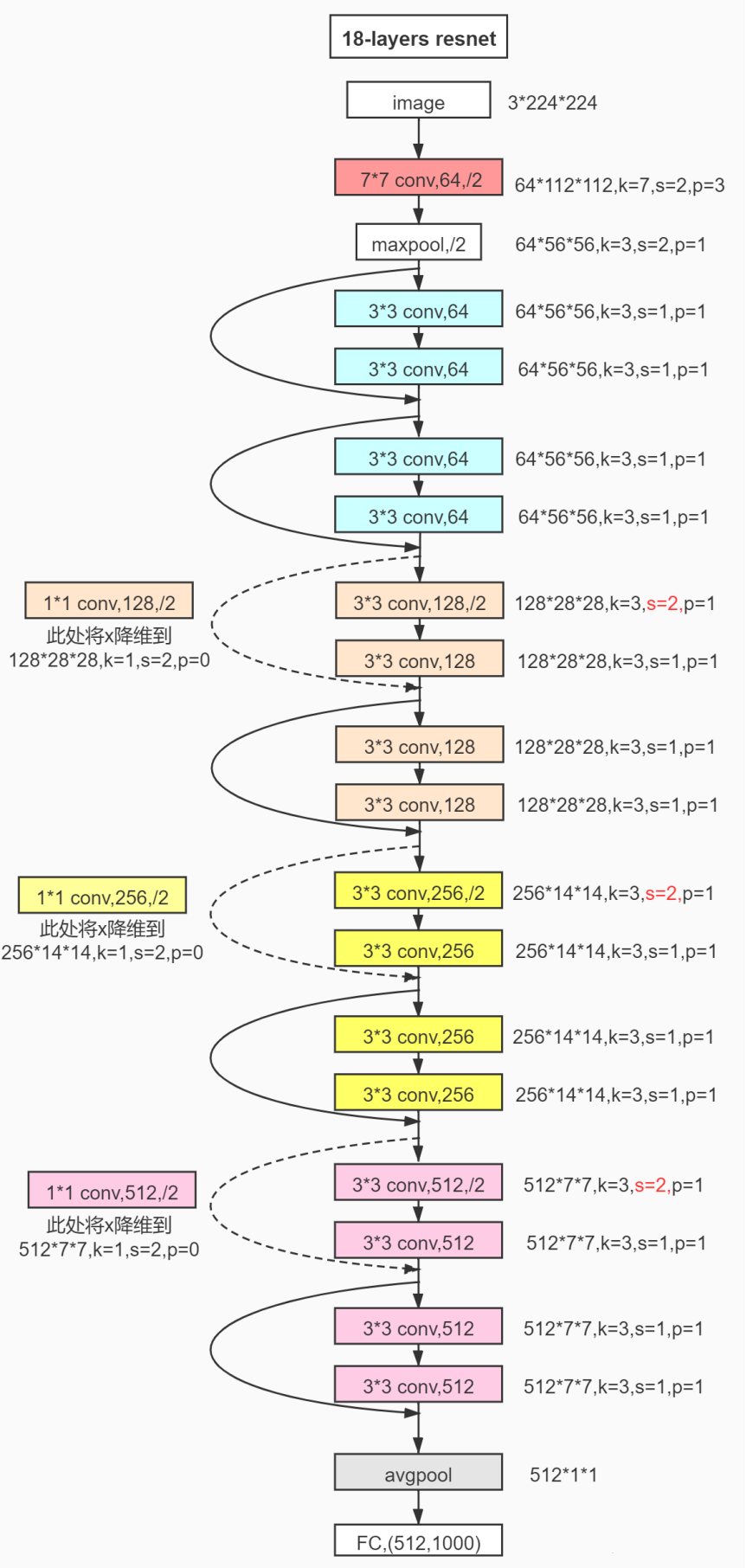
- 第1個卷積組只包含1次卷積計算操作,5種典型ResNet結構的第1個卷積組完全相同,卷積核均為7x7, 步長為均2
- 第2-5個卷積組都包含多個相同的殘差單元,在很多代碼實現上,通常把第2-5個卷積組分別叫做Stage1、Stage2、Stage3、Stage4
- 首先是第一層卷積使用kernel 7?7,步長為2,padding為3。之后進行BN,ReLU和maxpool。這些構成了第一部分卷積模塊conv1。
- 然后是四個stage,有些代碼中用make_layer()來生成stage,每個stage中有多個模塊,每個模塊叫做building block,resnet18= [2,2,2,2],就有8個building block。注意到他有兩種模塊BasicBlock和Bottleneck。resnet18和resnet34用的是BasicBlock,resnet50及以上用的是Bottleneck。無論BasicBlock還是Bottleneck模塊,都用到了殘差連接(shortcut connection)方式:
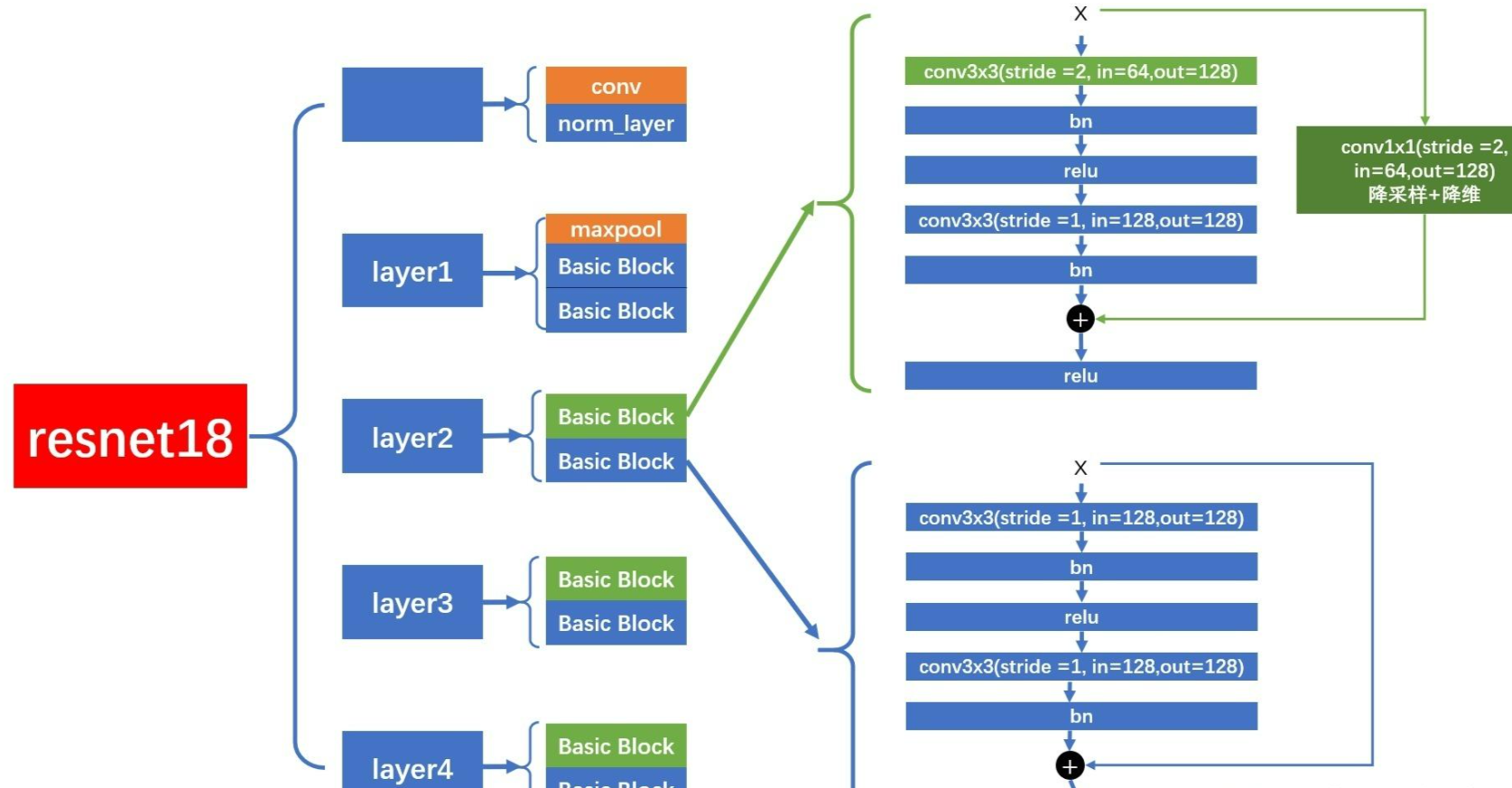
下圖以ResNet18為例介紹一下它的網絡模型
layer1
????????ResNet18 ,使用的是?BasicBlock。layer1,特點是沒有進行降采樣,卷積層的?stride = 1,不會降采樣。在進行?shortcut?連接時,也沒有經過?downsample?層。
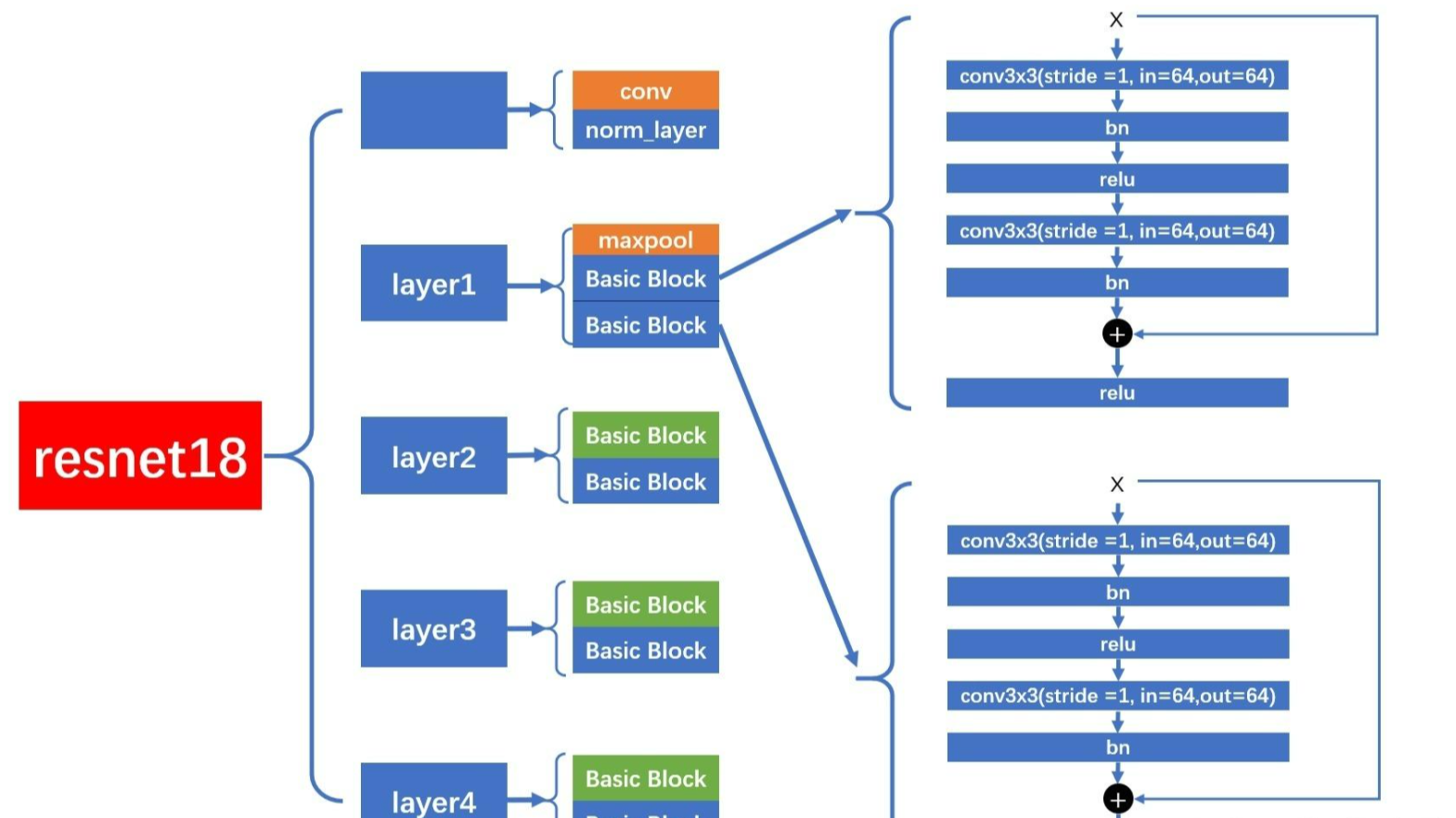
layer2,layer3,layer4
而?layer2,layer3,layer4?的結構圖如下,每個?layer?包含 2 個?BasicBlock,但是第 1 個?BasicBlock?的第 1 個卷積層的?stride = 2,會進行降采樣。在進行?shortcut?連接時,會經過?downsample?層,進行降采樣和降維。
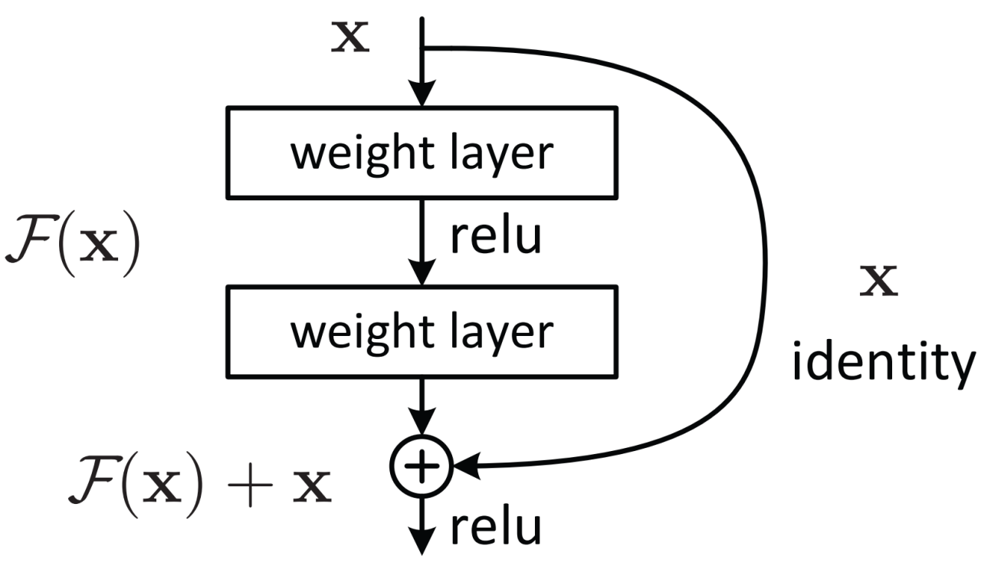
????????residual結構使用了一種shortcut的連接方式,也可理解為捷徑。讓特征矩陣隔層相加,注意F(X)和X形狀要相同,所謂相加是特征矩陣相同位置上的數字進行相加。
????????一個殘差塊有2條路徑 F(x)和 x,F(x) 路徑擬合殘差,可稱之為殘差路徑;?路徑為`identity mapping`恒等映射,可稱之為`shortcut`。圖中的⊕為`element-wise addition`,要求參與運算的F(x)??和?x的尺寸要相同。
其中關鍵技術?Batch Normalization是對每一個卷積后進行標準化
????????Batch Normalization目的:使所有的feature map滿足均值為0,方差為1的分布規律
三、代碼分析
1. 導入必要的庫
import torch
from torch.utils.data import DataLoader,Dataset # 數據加載相關
from PIL import Image # 圖像處理
from torchvision import transforms # 數據預處理
import numpy as np
from torch import nn # 神經網絡模塊
import torchvision.models as models # 預訓練模型2. 模型準備(遷移學習)
這部分是遷移學習的重點,
# 加載預訓練的ResNet-18模型
resnet_model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)# 凍結所有預訓練參數(遷移學習常用策略)
for param in resnet_model.parameters():print(param) # 打印參數(實際應用中可刪除)param.requires_grad = False # 凍結參數,不參與訓練# 獲取原模型最后一層的輸入特征數
in_features = resnet_model.fc.in_features # ResNet18的fc層輸入是512# 替換最后一層全連接層,輸出類別數為20(根據實際任務調整)
resnet_model.fc = nn.Linear(in_features, 20)# 收集需要更新的參數(只有新替換的全連接層參數)
params_to_update = []
for param in resnet_model.parameters():if param.requires_grad == True:params_to_update.append(param)????????這里采用了遷移學習策略:凍結預訓練模型的大部分參數,只訓練最后一層的分類器,這樣可以加快訓練速度并提高效果。
models.resnet18():創建 ResNet-18 網絡結構weights=models.ResNet18_Weights.DEFAULT:使用在 ImageNet 數據集上預訓練好的權重初始化模型
- 遷移學習的關鍵操作:保留預訓練模型學到的特征提取能力
requires_grad = False:告訴 PyTorch 不需要計算這些參數的梯度
- 原 ResNet-18 用于 1000 類分類,這里替換為 20 類分類
- 只訓練新替換的全連接層參數,大大減少計算量
3. 數據預處理
data_transforms = {'train': transforms.Compose([ # 訓練集的數據增強transforms.Resize([300, 300]), # 調整大小transforms.RandomRotation(45), # 隨機旋轉transforms.CenterCrop(224), # 中心裁剪transforms.RandomHorizontalFlip(p=0.5), # 隨機水平翻轉transforms.RandomVerticalFlip(p=0.5), # 隨機垂直翻轉transforms.ToTensor(), # 轉為Tensor# 歸一化,使用ImageNet的均值和標準差transforms.Normalize([0.485, 0.456, 0.486], [0.229, 0.224, 0.225])]),'valid': transforms.Compose([ # 驗證集不做數據增強,只做必要處理transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.486], [0.229, 0.224, 0.225])]),
}4. 自定義數據集類
class food_dataset(Dataset): # 繼承Dataset類def __init__(self, file_path, transform=None):self.file_path = file_pathself.imgs = [] # 存儲圖像路徑self.labels = [] # 存儲標簽self.transform = transform# 從文件中讀取圖像路徑和標簽with open(file_path, 'r') as f:samples = [x.strip().split(' ') for x in f.readlines()]for img_path, label in samples:self.imgs.append(img_path)self.labels.append(label)def __len__(self): # 返回數據集大小return len(self.imgs)def __getitem__(self, idx): # 獲取單個樣本image = Image.open(self.imgs[idx]) # 打開圖像if self.transform: # 應用預處理image = self.transform(image)# 處理標簽,轉為Tensorlabel = self.labels[idx]label = torch.from_numpy(np.array(label, dtype=np.int64))return image, label5. 數據加載器
# 創建訓練集和測試集
train_data = food_dataset(file_path='train.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path='test.txt', transform=data_transforms['train']) # 注意這里可能應該用'valid'# 創建數據加載器,用于批量加載數據
train_dataloader = DataLoader(train_data, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=32, shuffle=True)6. 設備配置
# 自動選擇可用的計算設備(GPU優先)
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")# 將模型移動到選定的設備
model = resnet_model.to(device)7. 訓練函數
def train(dataloader, model, loss_fn, optimizer):model.train() # 切換到訓練模式batch_size_num = 1for X, y in dataloader:X, y = X.to(device), y.to(device) # 將數據移動到設備# 前向傳播pred = model.forward(X)loss = loss_fn(pred, y) # 計算損失# 反向傳播和參數更新optimizer.zero_grad() # 梯度清零loss.backward() # 反向傳播計算梯度optimizer.step() # 更新參數# 打印訓練信息loss = loss.item()if batch_size_num % 64 == 0:print(f"loss: {loss:>7f} [number: {batch_size_num}]")batch_size_num += 18. 測試函數
best_acc = 0 # 記錄最佳準確率def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval() # 切換到評估模式test_loss, correct = 0, 0with torch.no_grad(): # 關閉梯度計算,節省內存for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)test_loss += loss_fn(pred, y).item()# 計算正確預測的數量correct += (pred.argmax(1) == y).type(torch.float).sum().item()# 計算平均損失和準確率test_loss /= num_batchescorrect /= sizeprint(f"Test result:\n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f}")# 保存最佳模型global best_accif correct > best_acc:best_acc = correcttorch.save(model, 'best3.pt') # 保存整個模型9. 訓練配置和執行
# 定義損失函數和優化器
loss_fn = nn.CrossEntropyLoss() # 交叉熵損失,適用于分類任務
optimizer = torch.optim.Adam(params_to_update, lr=0.001) # Adam優化器# 學習率調度器,每10個epoch學習率乘以0.5
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)# 訓練輪次
epochs = 20
acc_s = []
loss_s = []# 開始訓練
for t in range(epochs):print(f"Epoch {t+1}\n-----------------------")train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader, model, loss_fn)scheduler.step() # 更新學習率
print("Done!")
print(f"最佳的結果:\n Accuracy: {(100*best_acc):>0.1f}%")整體流程總結
- 加載預訓練的 ResNet-18 模型并修改最后一層以適應新任務
- 定義數據預處理和增強方法
- 創建自定義數據集類來讀取圖像和標簽
- 設置訓練設備(GPU 或 CPU)
- 定義訓練和測試函數
- 配置優化器、損失函數和學習率調度器
- 執行多輪訓練,每輪結束后在測試集上評估并保存最佳模型
最后我們都結果可以達到百分之90左右,效果得到很大的提升。
)



)

)



)
帶論文文檔1萬字以上,文末可獲取,系統界面在最后面。)







)