背景意義
研究背景與意義
隨著工業自動化和智能制造的迅速發展,工人安全問題日益受到重視。特別是在涉及重型機械和危險操作的工作環境中,工人手部的安全保護顯得尤為重要。傳統的安全手套雖然在一定程度上能夠保護工人的手部,但在復雜的加工操作中,如何實時監測手部的狀態和安全性,成為了一個亟待解決的技術難題。因此,開發一個基于先進計算機視覺技術的手部檢測系統,不僅可以提高工人的安全性,還能提升生產效率。
本研究旨在基于改進的YOLOv11模型,構建一個高效的加工操作安全手套與手部檢測系統。該系統將利用包含1500張圖像的bandsaw_kolabira數據集進行訓練和驗證。數據集中包含了多種手套和手部的類別,包括藍色手套、白色手套、鋼制手套以及手部和頭部的標注信息。這些多樣化的類別為模型的訓練提供了豐富的樣本,有助于提高模型的準確性和魯棒性。
在實際應用中,該系統將能夠實時識別工人是否佩戴安全手套,并監測手部的活動狀態,從而有效預防因操作不當導致的安全事故。此外,通過對手部狀態的監測,系統還可以為工人提供實時反饋,幫助其調整操作姿勢,降低受傷風險。通過將計算機視覺技術與工人安全管理相結合,本研究不僅為安全生產提供了技術支持,也為未來智能制造的發展提供了新的思路和方向。
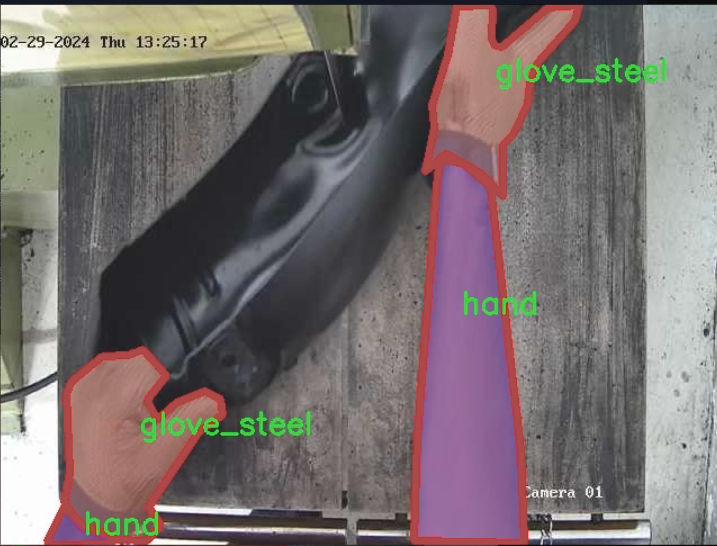
圖片效果
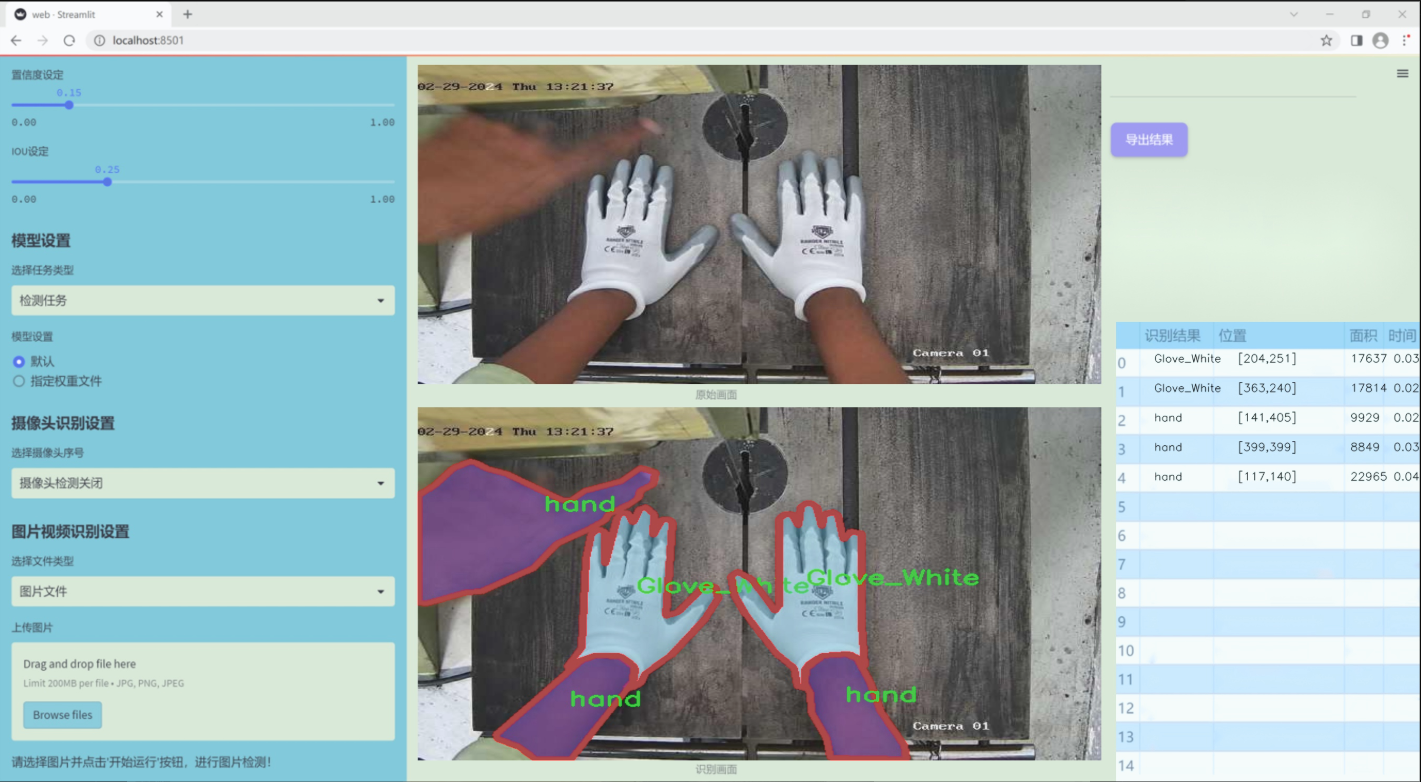
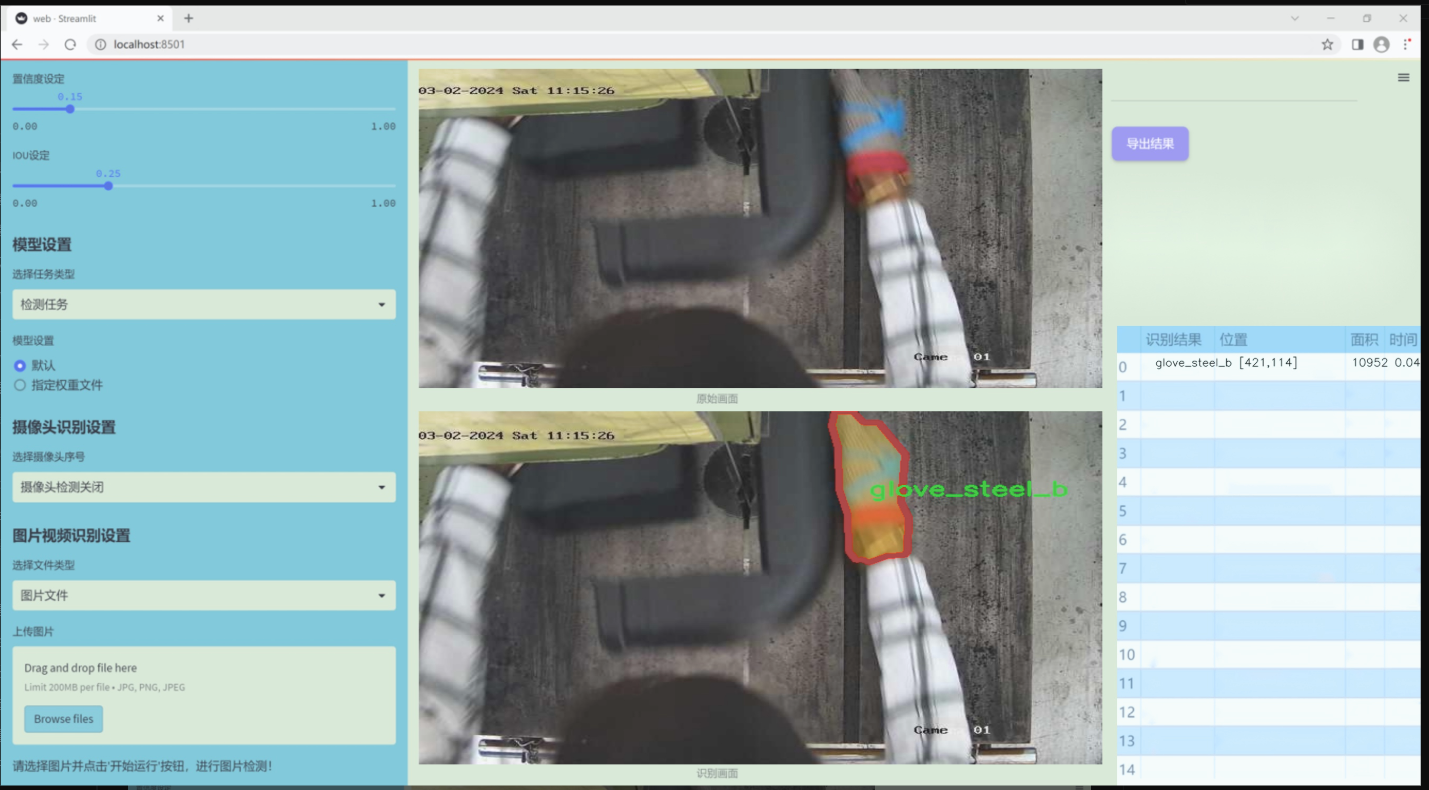
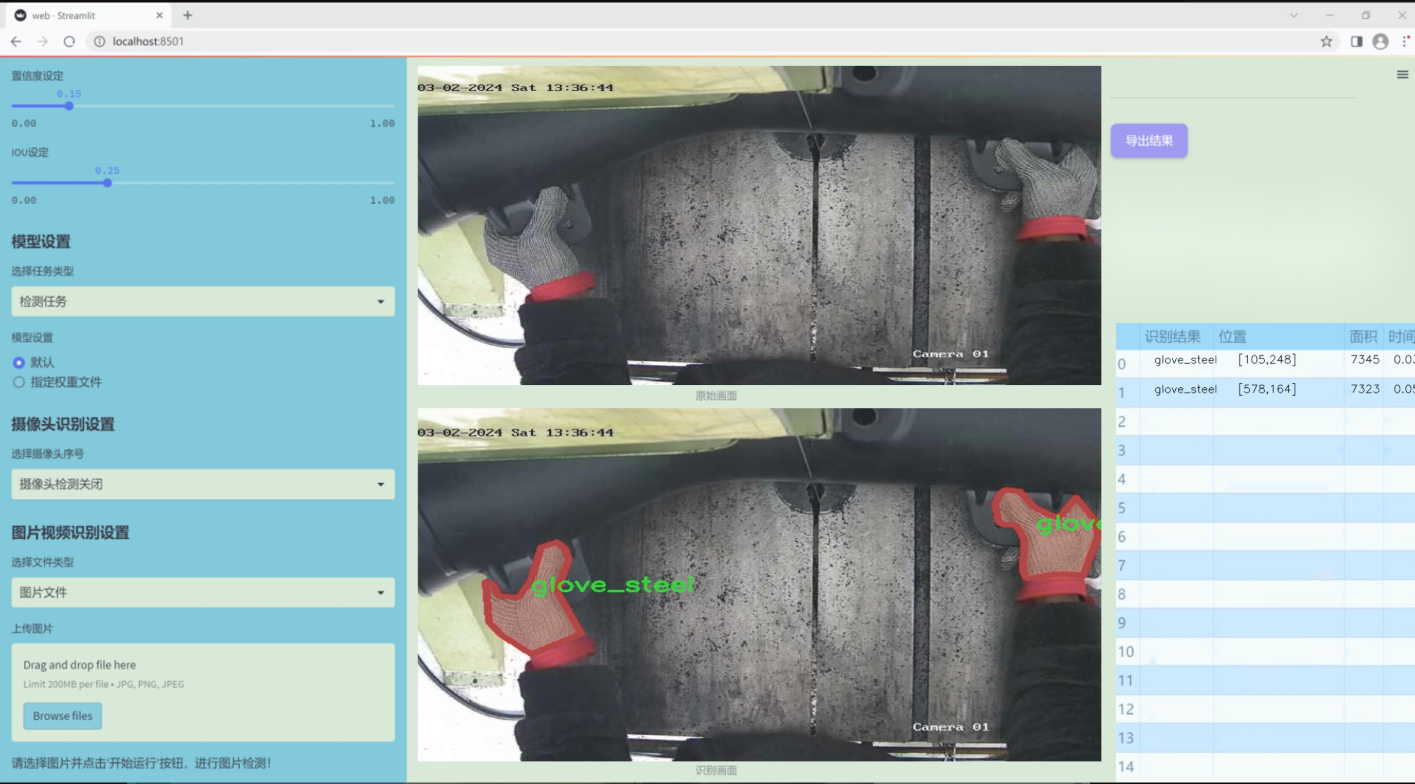
數據集信息
本項目數據集信息介紹
本項目旨在改進YOLOv11的加工操作安全手套與手部檢測系統,所使用的數據集圍繞“bandsaw_kolabira”主題構建,專注于提升在加工環境中對手部及手套的檢測能力。該數據集包含六個類別,具體為:藍色手套(Glove_Blue)、白色手套(Glove_White)、鋼制手套(glove_steel)、鋼制手套B型(glove_steel_b)、手部(hand)以及頭部(head)。這些類別的選擇旨在全面覆蓋加工操作中可能出現的關鍵安全元素,確保系統能夠有效識別并響應不同的安全風險。
在數據集的構建過程中,采集了大量在實際加工環境中拍攝的圖像,確保數據的多樣性和真實性。這些圖像不僅涵蓋了不同的光照條件和背景環境,還包括了各種手部動作和手套佩戴狀態,以增強模型的泛化能力。通過這種方式,數據集能夠有效模擬真實工作場景中可能遇到的各種情況,從而為YOLOv11模型的訓練提供堅實的基礎。
在數據集的標注過程中,采用了精確的邊界框標注技術,以確保每個類別的物體都能被準確識別。標注的質量直接影響到模型的性能,因此我們特別注重標注的一致性和準確性。此外,為了提升模型在實際應用中的表現,數據集中還包含了一些特殊情況的樣本,例如手套未佩戴、佩戴不當等情形,以便模型能夠在各種情況下做出正確的判斷。
綜上所述,本項目的數據集不僅涵蓋了多樣的類別和豐富的樣本,還注重了標注的精確性與場景的多樣性,為改進YOLOv11的加工操作安全手套與手部檢測系統提供了強有力的數據支持。通過對該數據集的深入分析與應用,我們期望能夠顯著提升系統在實際加工環境中的安全性和有效性。

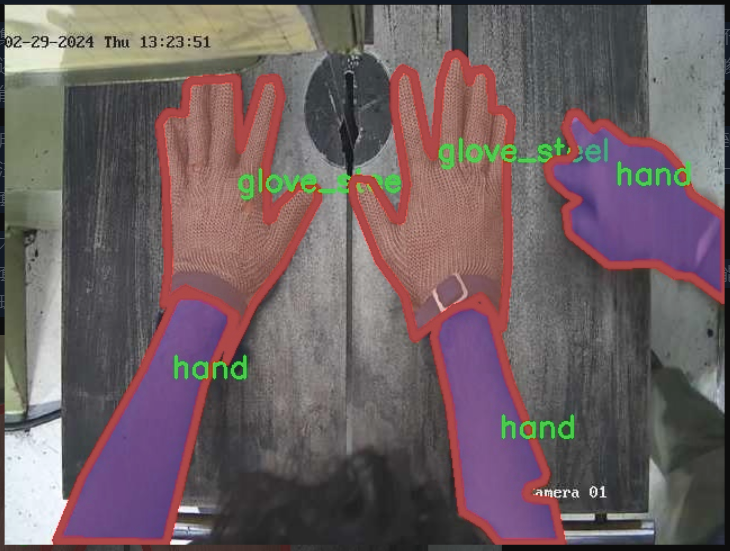


核心代碼
以下是代碼中最核心的部分,并附上詳細的中文注釋:
import torch
import torch.nn as nn
import torch.nn.functional as F
class OmniAttention(nn.Module):
def init(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):
super(OmniAttention, self).init()
# 計算注意力通道數
attention_channel = max(int(in_planes * reduction), min_channel)
self.kernel_size = kernel_size
self.kernel_num = kernel_num
self.temperature = 1.0 # 溫度參數,用于調整注意力分布
# 定義各個層self.avgpool = nn.AdaptiveAvgPool2d(1) # 自適應平均池化self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False) # 全連接層self.bn = nn.BatchNorm2d(attention_channel) # 批歸一化self.relu = nn.ReLU(inplace=True) # ReLU激活函數# 定義通道注意力self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)self.func_channel = self.get_channel_attention# 定義濾波器注意力if in_planes == groups and in_planes == out_planes: # 深度卷積self.func_filter = self.skipelse:self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)self.func_filter = self.get_filter_attention# 定義空間注意力if kernel_size == 1: # 點卷積self.func_spatial = self.skipelse:self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)self.func_spatial = self.get_spatial_attention# 定義核注意力if kernel_num == 1:self.func_kernel = self.skipelse:self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)self.func_kernel = self.get_kernel_attentionself._initialize_weights() # 初始化權重def _initialize_weights(self):# 初始化卷積層和批歸一化層的權重for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)if isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)@staticmethod
def skip(_):return 1.0 # 跳過操作,返回1.0def get_channel_attention(self, x):# 計算通道注意力channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return channel_attentiondef get_filter_attention(self, x):# 計算濾波器注意力filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return filter_attentiondef get_spatial_attention(self, x):# 計算空間注意力spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)spatial_attention = torch.sigmoid(spatial_attention / self.temperature)return spatial_attentiondef get_kernel_attention(self, x):# 計算核注意力kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)return kernel_attentiondef forward(self, x):# 前向傳播x = self.avgpool(x) # 自適應平均池化x = self.fc(x) # 全連接層x = self.bn(x) # 批歸一化x = self.relu(x) # ReLU激活return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x) # 返回各個注意力
生成拉普拉斯金字塔的函數
def generate_laplacian_pyramid(input_tensor, num_levels, size_align=True, mode=‘bilinear’):
pyramid = [] # 存儲金字塔層
current_tensor = input_tensor # 當前張量
_, _, H, W = current_tensor.shape # 獲取輸入張量的形狀
for _ in range(num_levels):
b, _, h, w = current_tensor.shape # 獲取當前張量的形狀
# 下采樣
downsampled_tensor = F.interpolate(current_tensor, (h//2 + h%2, w//2 + w%2), mode=mode, align_corners=(H%2) == 1)
if size_align:
# 對齊大小
upsampled_tensor = F.interpolate(downsampled_tensor, (H, W), mode=mode, align_corners=(H%2) == 1)
laplacian = F.interpolate(current_tensor, (H, W), mode=mode, align_corners=(H%2) == 1) - upsampled_tensor
else:
upsampled_tensor = F.interpolate(downsampled_tensor, (h, w), mode=mode, align_corners=(H%2) == 1)
laplacian = current_tensor - upsampled_tensor
pyramid.append(laplacian) # 添加拉普拉斯層
current_tensor = downsampled_tensor # 更新當前張量
if size_align:
current_tensor = F.interpolate(current_tensor, (H, W), mode=mode, align_corners=(H%2) == 1)
pyramid.append(current_tensor) # 添加最后一層
return pyramid # 返回金字塔
class AdaptiveDilatedConv(nn.Module):
“”“自適應膨脹卷積的封裝類”“”
def init(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):
super(AdaptiveDilatedConv, self).init()
# 定義卷積層
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.omni_attention = OmniAttention(in_channels, out_channels, kernel_size) # 實例化OmniAttention
def forward(self, x):# 前向傳播attention_weights = self.omni_attention(x) # 計算注意力權重x = self.conv(x) # 卷積操作return x * attention_weights # 返回加權后的輸出
代碼核心部分說明:
OmniAttention 類:實現了多種注意力機制,包括通道注意力、濾波器注意力、空間注意力和核注意力。通過這些注意力機制,可以動態調整特征圖的不同部分的權重,從而提高模型的表現。
generate_laplacian_pyramid 函數:用于生成拉普拉斯金字塔,主要用于圖像處理中的多尺度特征提取。通過逐層下采樣和上采樣,可以提取不同尺度的特征。
AdaptiveDilatedConv 類:實現了自適應膨脹卷積,結合了卷積操作和注意力機制。通過注意力機制,能夠動態調整卷積操作的權重,從而增強模型的表達能力。
這些核心部分共同構成了一個強大的卷積神經網絡架構,能夠在圖像處理和計算機視覺任務中取得良好的效果。
這個程序文件 fadc.py 是一個基于 PyTorch 的深度學習模型實現,主要涉及自適應膨脹卷積和頻率選擇機制。文件中包含多個類和函數,以下是對主要部分的講解。
首先,文件導入了必要的庫,包括 PyTorch 的核心庫和一些常用的模塊。然后,定義了一個名為 OmniAttention 的類,它是一個自定義的注意力機制。這個類的構造函數接收多個參數,包括輸入和輸出通道數、卷積核大小、組數、縮減比例等。它通過多個卷積層和激活函數來計算通道注意力、過濾器注意力、空間注意力和卷積核注意力。forward 方法將輸入張量通過一系列操作生成注意力權重,這些權重可以在后續的卷積操作中使用。
接下來,定義了一個名為 generate_laplacian_pyramid 的函數,用于生成拉普拉斯金字塔。該函數通過逐層下采樣輸入張量,并計算當前層與下采樣后的張量之間的差異,構建金字塔結構。此函數的輸出是一個包含多個層次的金字塔列表,通常用于圖像處理和特征提取。
然后,定義了 FrequencySelection 類,它用于選擇特定頻率的特征。該類支持多種操作模式,包括平均池化和拉普拉斯金字塔。構造函數中根據輸入參數初始化多個卷積層和頻率選擇機制。forward 方法根據選擇的頻率對輸入特征進行處理,并返回加權后的特征。
接下來是 AdaptiveDilatedConv 類,它是一個自適應膨脹卷積的實現,繼承自 ModulatedDeformConv2d。該類的構造函數中定義了多個參數,包括卷積類型、偏移頻率、卷積核分解等。它的 forward 方法實現了自適應卷積操作,結合了注意力機制和頻率選擇。
最后,定義了 AdaptiveDilatedDWConv 類,它是一個適應性膨脹深度卷積的實現。與前一個類類似,它也包含多個卷積層和注意力機制,并在 forward 方法中實現了深度卷積的操作。
整體來看,這個文件實現了一個復雜的卷積神經網絡結構,結合了自適應卷積、注意力機制和頻率選擇,適用于圖像處理和特征提取等任務。代碼中使用了大量的 PyTorch API,展示了深度學習模型的靈活性和可擴展性。
10.4 dyhead_prune.py
以下是保留的核心代碼部分,并附上詳細的中文注釋:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DyReLU(nn.Module):
“”“動態ReLU激活函數模塊,具有自適應的激活強度和偏置。”“”
def init(self, inp, reduction=4, lambda_a=1.0, use_bias=True):
super(DyReLU, self).init()
self.oup = inp # 輸出通道數
self.lambda_a = lambda_a * 2 # 激活強度的縮放因子
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自適應平均池化層
# 根據輸入通道數和縮減比例計算squeeze通道數squeeze = inp // reductionself.fc = nn.Sequential(nn.Linear(inp, squeeze), # 全連接層,輸入為inp,輸出為squeezenn.ReLU(inplace=True), # ReLU激活函數nn.Linear(squeeze, self.oup * 2), # 輸出為兩倍的輸出通道數h_sigmoid() # 使用h_sigmoid激活函數)def forward(self, x):"""前向傳播函數,計算動態激活值。"""b, c, h, w = x.size() # 獲取輸入的批量大小、通道數、高度和寬度y = self.avg_pool(x).view(b, c) # 對輸入進行自適應平均池化并調整形狀y = self.fc(y).view(b, self.oup * 2, 1, 1) # 通過全連接層并調整形狀# 從y中分離出兩個激活強度和偏置a1, b1 = torch.split(y, self.oup, dim=1)a1 = (a1 - 0.5) * self.lambda_a + 1.0 # 計算動態激活強度out = x * a1 + b1 # 計算輸出return out # 返回動態激活后的輸出
class DyDCNv2(nn.Module):
“”“帶有歸一化層的ModulatedDeformConv2d模塊。”“”
def init(self, in_channels, out_channels, stride=1, norm_cfg=dict(type=‘GN’, num_groups=16)):
super().init()
self.conv = ModulatedDeformConv2d(in_channels, out_channels, 3, stride=stride, padding=1) # 定義可調變形卷積層
self.norm = build_norm_layer(norm_cfg, out_channels)[1] if norm_cfg else None # 根據配置構建歸一化層
def forward(self, x, offset, mask):"""前向傳播函數,計算卷積輸出。"""x = self.conv(x.contiguous(), offset, mask) # 進行卷積操作if self.norm:x = self.norm(x) # 如果有歸一化層,則進行歸一化return x # 返回卷積后的輸出
class DyHeadBlock_Prune(nn.Module):
“”“包含三種注意力機制的DyHead模塊。”“”
def init(self, in_channels, norm_type=‘GN’):
super().init()
self.spatial_conv_high = DyDCNv2(in_channels, in_channels) # 高層特征卷積
self.spatial_conv_mid = DyDCNv2(in_channels, in_channels) # 中層特征卷積
self.spatial_conv_low = DyDCNv2(in_channels, in_channels, stride=2) # 低層特征卷積
self.spatial_conv_offset = nn.Conv2d(in_channels, 27, 3, padding=1) # 計算偏移和掩碼的卷積層
self.task_attn_module = DyReLU(in_channels) # 任務注意力模塊
def forward(self, x, level):"""前向傳播函數,計算不同層次特征的融合。"""offset_and_mask = self.spatial_conv_offset(x[level]) # 計算偏移和掩碼offset = offset_and_mask[:, :18, :, :] # 提取偏移mask = offset_and_mask[:, 18:, :, :].sigmoid() # 提取掩碼并應用sigmoidmid_feat = self.spatial_conv_mid(x[level], offset, mask) # 中層特征卷積sum_feat = mid_feat # 初始化特征和# 如果有低層特征,則進行卷積并加權if level > 0:low_feat = self.spatial_conv_low(x[level - 1], offset, mask)sum_feat += low_feat# 如果有高層特征,則進行卷積并加權if level < len(x) - 1:high_feat = F.interpolate(self.spatial_conv_high(x[level + 1], offset, mask), size=x[level].shape[-2:], mode='bilinear', align_corners=True)sum_feat += high_featreturn self.task_attn_module(sum_feat) # 返回經過任務注意力模塊處理的特征
代碼核心部分說明:
DyReLU:實現了動態ReLU激活函數,可以根據輸入自適應調整激活強度和偏置。
DyDCNv2:實現了帶有歸一化層的可調變形卷積,能夠根據輸入特征計算偏移和掩碼。
DyHeadBlock_Prune:集成了多個卷積層和注意力機制,能夠處理不同層次的特征并進行融合,最終輸出經過注意力機制加權的特征。
這個程序文件 dyhead_prune.py 是一個基于 PyTorch 的深度學習模塊,主要用于實現動態頭部(Dynamic Head)中的一些自定義激活函數和卷積操作。文件中定義了多個類,每個類實現了特定的功能,以下是對代碼的詳細講解。
首先,文件導入了必要的庫,包括 PyTorch 的核心庫和一些功能模塊,如卷積、激活函數等。它還嘗試從 mmcv 和 mmengine 導入一些功能,如果導入失敗則捕獲異常。
接下來,定義了一個 _make_divisible 函數,用于確保某個值可以被指定的除數整除,并且在必要時對其進行調整,以避免過大的變化。
然后,定義了幾個自定義的激活函數類,包括 swish、h_swish 和 h_sigmoid。這些類繼承自 nn.Module,并實現了 forward 方法,定義了它們各自的前向傳播邏輯。
DyReLU 類是一個動態激活函數,具有可調的參數和可選的空間注意力機制。它的構造函數接受多個參數,包括輸入通道數、縮減比例、初始化參數等。forward 方法中根據輸入的特征圖計算動態激活值,并根據條件選擇不同的輸出方式。
DyDCNv2 類是一個封裝了調制變形卷積(Modulated Deformable Convolution)的模塊,支持可選的歸一化層。它的構造函數接受輸入和輸出通道數、步幅以及歸一化配置,并在前向傳播中執行卷積操作。
DyHeadBlock_Prune 類是動態頭部的主要模塊,包含了多個卷積層和注意力機制。它的構造函數初始化了多個卷積層和注意力模塊,并定義了權重初始化的方法。forward 方法計算輸入特征圖的偏移量和掩碼,并通過不同的卷積層處理特征圖,最終結合不同層次的特征進行輸出。
整個文件的結構清晰,功能模塊化,適合在深度學習模型中使用,尤其是在需要動態調整特征圖的情況下。通過這些自定義的激活函數和卷積操作,可以實現更靈活的特征提取和表示學習。
源碼文件

源碼獲取
歡迎大家點贊、收藏、關注、評論啦 、查看👇🏻獲取聯系方式👇🏻
27.移除元素 26.刪除有序數組中的重復項 283.移動零 977.有序數組的平方)


)
)



)

)



)
帶論文文檔1萬字以上,文末可獲取,系統界面在最后面。)



