異常處理
棧展開過程: 棧展開過程沿著嵌套函數的調用鏈不斷查找,直到找到了與異常匹配的catch子句為止;也可能一直沒找到匹配的catch,則退出主函數后查找過程終止。棧展開過程中的對象被自動銷毀。
在棧展開的過程中,會自動運行類類型的局部對象的析構函數,這些異構函數不應該拋出異常。一旦在棧展開的過程中析構函數拋出了異常,且析構函數自身沒能捕獲到該異常,則程序將被終止。
拋出指針異常,要求在任何對應的處理代碼存在的地方,指針所指的對象都必須存在。
捕獲異常:
-
聲明的類型決定了處理代碼所能捕獲的異常類型。這個類型必須是完全類型,它可以是左值引用,但不能是右值引用。
-
最后一點需要注意的是,異常聲明的靜態類型將決定catch語句所能執行的操作。如果catch的參數是基類類型,則catch無法使用派生類特有的任何成員。
-
通常情況下,如果catch接受的異常與某個繼承體系有關,則最好將該catch的參數定義成引用類型。
-
因為catch語句是按照其出現的順序逐一進行匹配的,所以當程序使用具有繼承關系的多個異常時必須對catch語句的順序進行組織和管理,使得派生類異常的處理代碼出現在基類異常的處理代碼之前。
-
與實參和形參的匹配規則相比,異常和catch異常聲明的匹配規則受到更多限制。此時,絕大多數類型轉換都不被允許,除了一些極細小的差別之外,要求異常的類型和catch聲明的類型是精確匹配的:
【非常量向常量的轉換,派生類向基類的轉換,數組被轉換為指針,函數被轉換為指向該函數的指針】
除此之外,包括標準算術類型轉換和類類型轉換在內,其他所有轉換規則都不能在匹配catch的過程中使用。
重新拋出
一條catch語句通過重新拋出(rethrowing)的操作將異常傳遞給另外一個catch語句。這里的重新拋出仍然是一條throw語句,只不過不包含任何表達式:throw。一個重新拋出語句并不指定新的表達式,而是將當前的異常對象沿著調用鏈向上傳遞。
如果catch語句改變了參數內容,重新拋出異常后,只有當catch異常聲明是引用類型時,我們對參數的修改才會被保留并繼續傳播。
捕獲所有異常
我們使用省略號作為異常聲明catch(...),通常于重新拋出語句一起使用,其中catch執行當前局部能能完成的工作,隨后重新拋出異常。
如果catch(…)與其他幾個catch語句一起出現,則catch(…)必須在最后的位置。出現在捕獲所有異常語句后面的catch語句將永遠不會被匹配。
函數try語句塊于構造函數:
要想處理構造函數初始值拋出的異常,我們必須將構造函數寫成函數try語句塊。語句塊。與這個try關聯的catch既能處理構造函數體拋出的異常,也能處理成員初始化列表拋出的異常。
還有一種情況值得讀者注意,在初始化構造函數的參數時也可能發生異常,這樣的異常不屬于函數try語句塊的一部分。函數try語句塊只能處理構造函數開始執行后發生的異常。和其他函數調用一樣,如果在參數初始化的過程中發生了異常,則該異常屬于調用表達式的一部分,并將在調用者所在的上下文中處理。
template <typenameT>
Blob<T>::Blob(std::initializer_list<T> il) try:data(std::make_shared<std::vector<T>>(il)){}catch(const std::bat_alloc &e){handle_out_of_memory(e);}
noexpect說明符:
對于一個函數來說,noexcept說明要么出現在該函數的所有聲明語句和定義語句中,要么一次也不出現。該說明應該在函數的尾置返回類型之前。==我們也可以在函數指針的聲明和定義中指定noexcept。在typedef或類型別名中則不能出現noexcept。==在成員函數中,noexcept說明符需要跟在const及引用限定符之后,而在final、override或虛函數的=0之前。
一旦一個noexcept函數拋出了異常,程序就會調用terminate以確保遵守不在運行時拋出異常的承諾
noexcept表達式:
返回一個bool類型的右值常量表達式,用于表示給定的表達式是否會拋出異常,和sizeof類似,noexcept不會求其運算對象的值。noexcept(recoup(i))如果recoup不拋出異常則為true。

指針,函數,拷貝控制與異常說明
如果我們為某個指針做了不拋出異常的聲明,則該指針將只能指向不拋出異常的函數。
如果一個虛函數承諾了它不會拋出異常,則后續派生出來的虛函數也必須做出同樣的承諾
當編譯器合成拷貝控制成員時,同時也生成一個異常說明。如果對所有成員和基類的所有操作都承諾了不會拋出異常,則合成的成員是noexcept的。
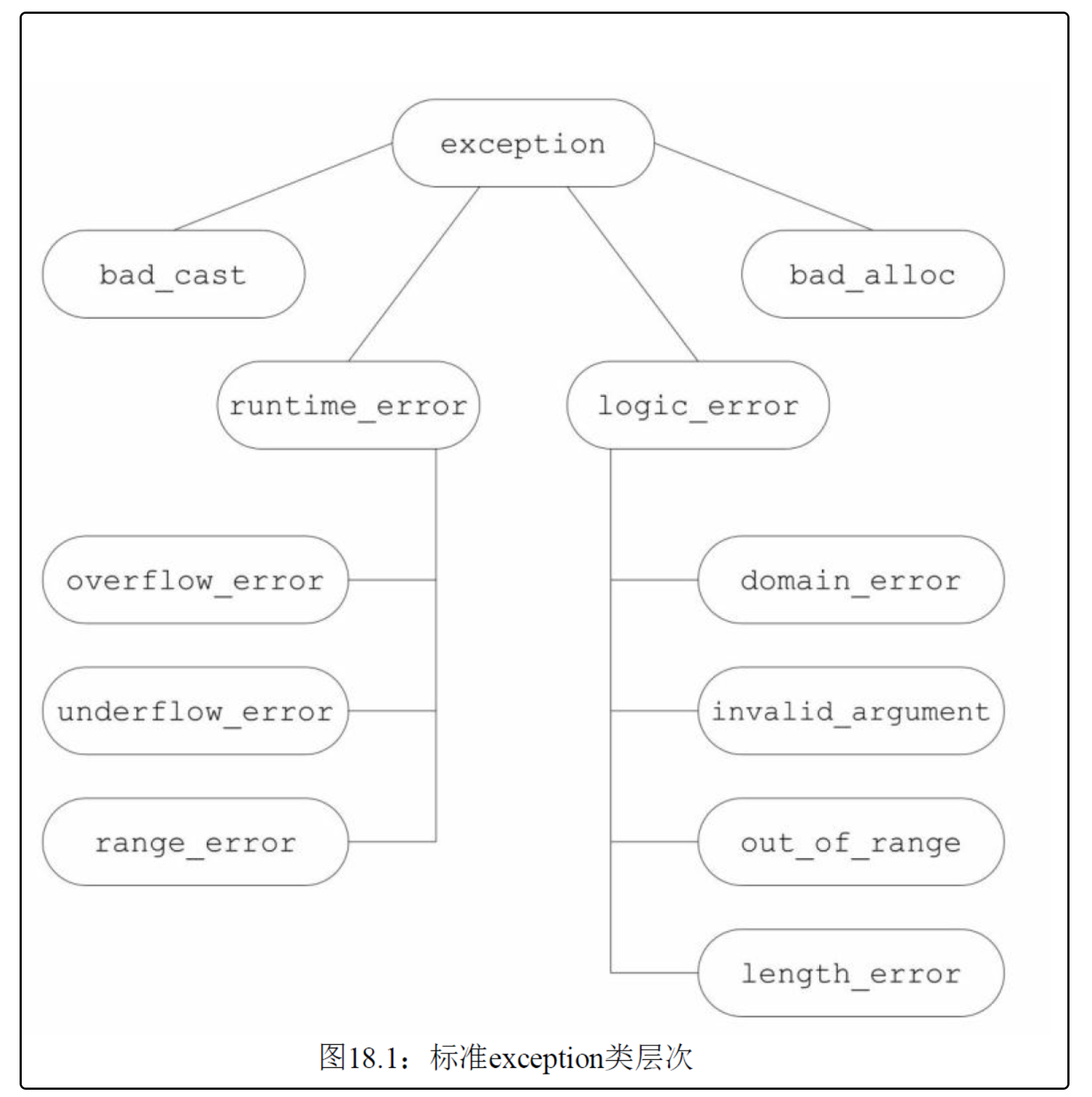
異常類的層次:
命名空間
? 一個命名空間的定義包含兩部分:首先是關鍵字namespace,隨后是命名空間的名字。在命名空間名字后面是一系列由花括號括起來的聲明和定義。只要能出現在全局作用域中的聲明就能置于命名空間內,主要包括:類、變量(及其初始化操作)、函數(及其定義)、模板和其他命名空間命名空間作用域后面無須分號。類的作用域后面又分號
? 命名空間的定義可以是不連續的,我們可以新定義一個命名空間,也可以為已存在的命名空間添加一些新成員。因此我們可以把類的聲明寫在頭文件中的命名空間中,把類的定義寫在源文件的命名空間中。
? 我們可以為一個項目定義一個命名空間,在該命名空間中定義不同的類,每個類都單獨的頭文件和定義源文件。使用的時候需要包含指定的頭文件,并且應用該項目的命名空間。
? 模板特例化必須定義在原始模板所屬的命名空間中。我們必須將模板特例化聲明為std的成員(特例化std命名空間內的模板)。
全局命名空間:
? ::name表示全局命名空間中的名字。
內聯命名空間
? 內聯命名空間中的名字可以直接被外層命名空間訪問。inline namesapce FifthEd{}關鍵字inline必須出現在命名空間第一次定義的地方,后續再打開命名空間的時候可以寫inline,也可以不寫。內聯命名空間可以作為版本控制。

未命名的命名空間
? 未命名命名空間在關鍵字namespace后直接跟花括號。未命名的命名空間中定義的變量擁有靜態生命周期:它們在第一次使用前創建,并且直到程序結束才銷毀。
? 如果一個頭文件定義了未命名的命名空間,則該命名空間中定義的名字將在每個包含了該頭文件的文件中對應不同實體。
? 和其他命名空間不同,未命名的命名空間僅在特定的文件內部有效,其作用范圍不會橫跨多個不同的文件。
? 未命名的命名空間中定義的名字的作用域與該命名空間所在的作用域相同。如果未命名的命名空間定義在文件的最外層作用域中,則該命名空間中的名字一定要與全局作用域中的名字有所區別。
? 未命名的命名空間可以嵌套使用,我們可以用外圍命名空間的名字訪問未命名的命名空間中的名字
定義名字別名
? namespace asodfjdlkasjflksadjflk primer使用primer作為別名
? namespace Qlib=asdlkfjlkasdjflk::asdfasd
using聲明和using指示
? using聲明using std::vector。using聲明會擴展候選函數集的規模。using聲明的函數如果和當前作用域中的函數完全一致則using聲明報錯
? using指示using namespace std. 如果存在多個using指示。則來自每個命名空間的名字都會成為候選函數集的一部分。using指示可以引入和當前作用域中完全重名的函數,我們只需要用作用域運算符就可以訪問命名空間中的函數
? using聲明和using指示在作用域上的區別直接決定了它們工作方式的不同。對于using聲明來說,我們只是簡單地令名字在局部作用域內有效。相反,using指示是令整個命名空間的所有內容變得有效。它具有將命名空間成員提升到包含命名空間本身和using指示的最近作用域的能力。

? 盡量避免使用using指示,在命名空間的定義源文件中可以使用using指示來簡化編碼。
函數實參傳遞和命名空間:
? 當我們給函數傳遞一個類類型的對象時,除了在常規的作用域查找外還會查找實參類所屬的命名空間。這一例外對于傳遞類的引用或指針的調用同樣有效。查找規則的這個例外允許概念上作為類接口一部分的非成員函數無須單獨的using聲明就能被程序使用。
? 對于標準庫中的move和forward函數,他們幾乎可以接收任何一個形參,因此我們編寫的move和forward函數幾乎一定會和標準庫的相關函數沖突。因此我們通常書寫std::move(std::forward)。
友元與命名空間
? 一個未聲明的類或函數如果第一次出現在友元聲明中,則我們認為它是最近的外層命名空間的成員。f2和f被隱式聲明為A的成員。

? 上述代碼中,我們聲明了一個C類的一個實例,調用f的時候會在C類所在的命名空間中查找(因為f接收一個類類型的實參),此時會找到f的隱士聲明(在C類之前)。調用f2它不接受類類型參數,也因此不會查找C類所在的命名空間,也就找不到f2的聲明語句。
多繼承與虛繼承
**繼承的構造函數與多繼承:**如果一個類從他的多個基類中繼承了相同的構造函數,則這個類必須為該構造函數定義它自己的版本。下面代碼中Base1和Base2都有一個接受const string &s的構造函數。

拷貝控制:多重繼承的派生類如果定義了自己的拷貝/賦值構造函數和賦值運算符,則必須在完整的對象上執行拷貝、移動或賦值操作。只有當派生類使用的是合成版本的拷貝、移動或賦值成員時,才會自動對其基類部分執行這些操作。
**派生類向基類的轉換:**在多繼承關系中,編譯器認為派生類向任何一個基類的轉換都是一樣好。因此函數調用過程中可能存在二義性錯誤。
對象、指針和引用的靜態類型決定了我們能使用那些成員。
**多繼承下的類作用域:**在多重繼承的情況下,相同的查找過程在所有直接基類中同時進行。如果名字在多個基類中都被找到,則對該名字的使用將具有二義性。 對于一個派生類來說,從它的幾個基類中分別繼承名字相同的成員是完全合法的,只不過在使用這個名字時必須明確指出它的版本。
**虛繼承:**避免在繼承體系中,派生類里有多個基類(可以是頂層基類,也可以是中間基類)對象。
在默認情況下,派生類中含有繼承鏈上每個類對應的子部分。如果某個類在派生過程中出現了多次,則派生類中將包含該類的多個子對象。
虛繼承令某個類做出聲明,承諾愿意共享它的基類。其中共享的基類對象稱為虛基類。在這種機制下,無論虛基類在繼承體系中出現了多少次,在派生類中都包含唯一一個共享的虛基類子對象。
在實際的編程過程中,位于中間層次的基類將其繼承聲明為虛繼承一般不會帶來什么問題。
無論基類是不是虛基類,派生類對象都能被可訪問基類的指針或引用操作。
class Raccoon : public virtual ZooAnimal { }
**構造函數與虛繼承:**派生類先
? 含有虛基類的對象的構造順序與一般的順序稍有區別:首先使用提供給最低層派生類的構造函數的初始值初始化該對象的虛基類子部分,接下來按照直接基類在派生列表中出現的次序依次對其進行初始化。
? 如果派生類沒有顯示初始化虛基類,則虛基類的默認構造函數將被調用,如果虛基類沒有默認構造函數,則代碼將會發生錯誤。
? 編譯器按照直接基類的聲明順序對其依次進行檢查,以確定其中是否含有虛基類。如果有,則先構造虛基類,然后按照聲明的順序逐一構造其他非虛基類。

免費證書的技術指南)







)



)



)

