RAG而言用戶輸入的數據通常是各種各樣文檔,本文主要采用langchain實現PDF/HTML文檔的處理方法
PDF文檔解析
PDF文檔很常見格式,但內部結構常常較復雜:
- 復雜的版式布局
- 多樣的元素(段落、表格、公式、圖片等)
- 文本流無法直接獲取
- 特殊元素如頁眉頁腳、側邊欄
主流分為兩類:
- 基于規則匹配(實戰不常用,效果差)
技巧:轉md
在實際應用中,我們經常會遇到這樣的情況:
- PDF文檔中的數學公式在導入知識庫過程中變成亂碼
- 解析過程極慢,特別是對于包含大量公式的長文檔
幾乎所有主流大模型都原生支持Markdown格式,它們的輸出也多采用Markdown,因此我們可以考慮選擇將pdf識別前轉為md格式。現在主流方法采用MinerU(star33k)
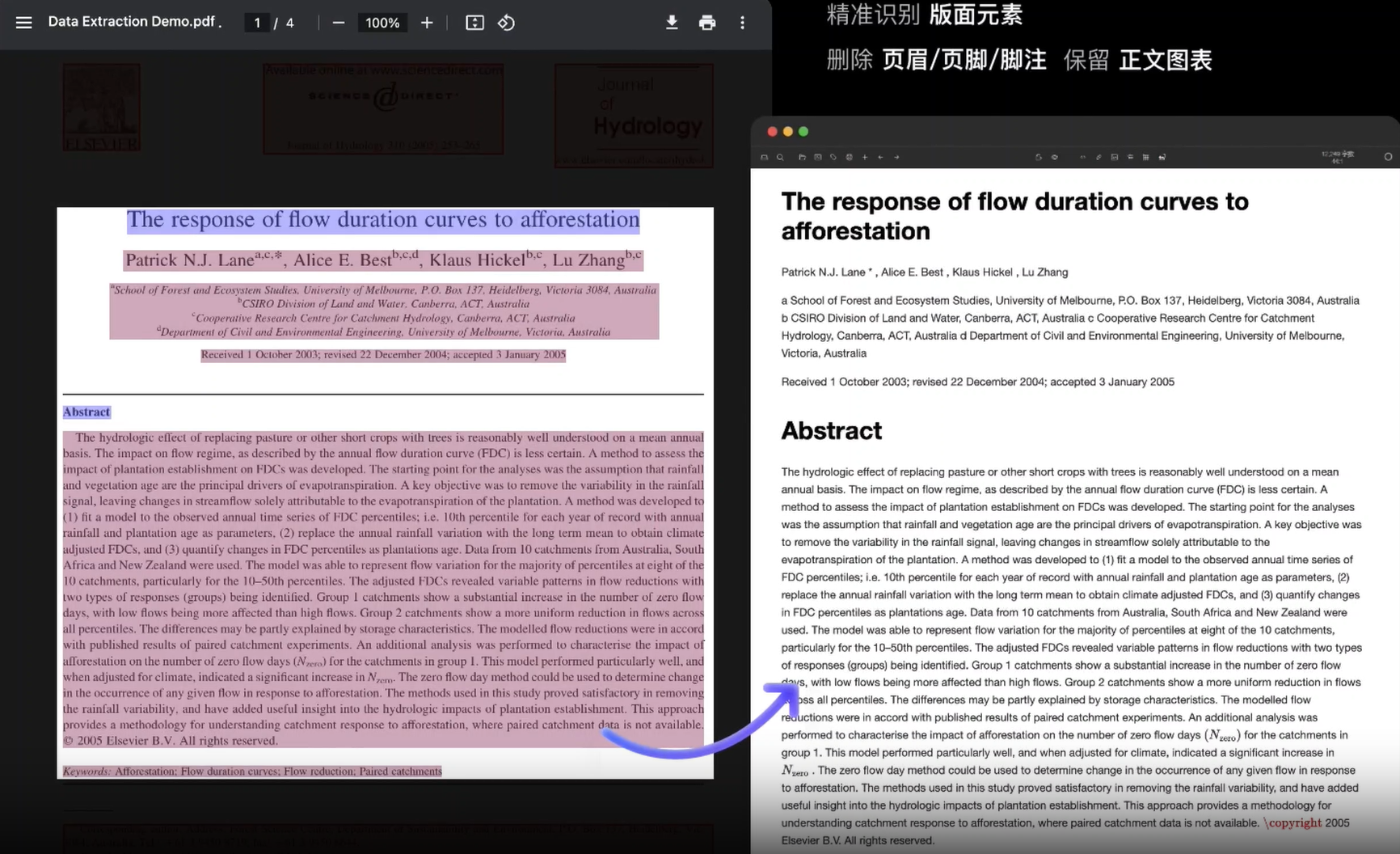
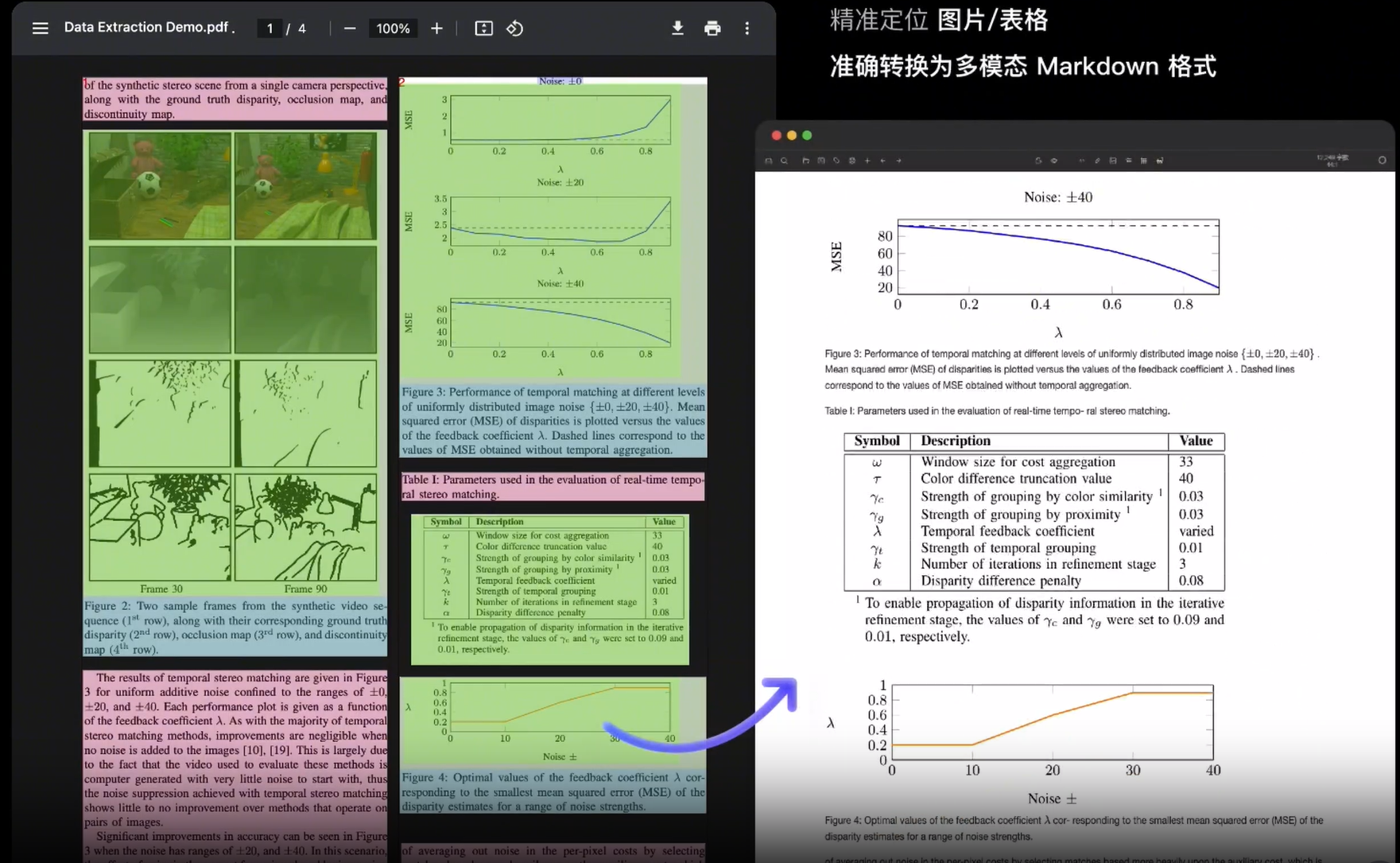
常規電子版解析
pdfplumber 對中文支持較好,且在表格解析方面表現優秀,但對雙攔文本的解析能力較差;pdfminer 和 PyMuPDF 對中文支持良好,但表格解析效果較弱;PyPDF2 對英文支持較好,但中文支持較差;papermage集成了pdfminer 和其他工具,特引適合處理論文場景。開發者可以根據實際業務場景的測試結果選擇合適的工具odfplumber 或 pdfminer 都是蘭不錯的選擇。
-
PyMuPDF (fitz):功能強大的PDF解析庫,支持文本提取、表格識別和版面分析。
-
LangChain中的解析器:
- PyMuPDFLoader:基于PyMuPDF的封裝,可提取文本和圖片
-
基于機器視覺的解析工具:
- 深度學習方案:如百度飛槳的PP-Structure、上海AI實驗室的MADU
- 商業解決方案:如PDFPlumber、LlamaIndex的LlamaParse
代碼示例
# 使用LangChain的PyMuPDFLoader
from langchain.document_loaders import PyMuPDFLoaderloader = PyMuPDFLoader("example.pdf")
documents = loader.load()# 直接使用PyMuPDF進行高級解析
import fitz # PyMuPDF# 打開PDF
doc = fitz.open("example.pdf")# 提取所有文本(按頁)
for page_num, page in enumerate(doc):text = page.get_text()print(f"頁面 {page_num + 1}:\n{text}\n")# 提取表格
for page_num, page in enumerate(doc):tables = page.find_tables()for i, table in enumerate(tables):# 轉換為pandas DataFramedf = table.to_pandas()print(f"頁面 {page_num + 1}, 表格 {i + 1}:\n{df}\n")# 提取圖片
for page_num, page in enumerate(doc):image_list = page.get_images(full=True)for img_index, img in enumerate(image_list):xref = img[0] # 圖片的xref(引用號)image = doc.extract_image(xref)# 可以保存圖片或進行進一步處理print(f"頁面 {page_num + 1}, 圖片 {img_index + 1}: {image['ext']}")
含圖片電子版解析
基于深度學習匹配
比規則匹配有更好的效果
Layout-parser、Pp-StructureV2、PDF-Extract-Kit、pix2text、MinerU、 marker
HTML文檔解析
HTML是網頁的標準標記語言,包含文本、圖片、視頻等多種內容,通過不同標簽組織。
常用解析工具
-
Beautiful Soup:Python中最常用的HTML解析庫,能通過標簽和CSS選擇器精確提取內容。
-
LangChain中的解析器:
- WebBaseLoader:結合urllib和Beautiful Soup,先下載HTML再解析
- BSHTMLLoader:直接解析本地HTML文件
代碼示例
# 使用LangChain的WebBaseLoader解析網頁
from langchain.document_loaders import WebBaseLoaderloader = WebBaseLoader("https://example.com")
documents = loader.load()# 使用Beautiful Soup定制解析
from bs4 import BeautifulSoup
import requestsresponse = requests.get("https://example.com")
soup = BeautifulSoup(response.text, "html.parser")# 提取所有代碼塊
code_blocks = soup.find_all("div", class_="highlight")
for block in code_blocks:print(block.get_text())# 提取所有標題和段落
content = []
for heading in soup.find_all(["h1", "h2", "h3"]):content.append({"type": "heading", "text": heading.get_text()})# 獲取標題后的段落for p in heading.find_next_siblings("p"):if p.find_next(["h1", "h2", "h3"]) == p:breakcontent.append({"type": "paragraph", "text": p.get_text()})
進階技巧
對于復雜的HTML頁面,可以考慮以下策略:
- 使用CSS選擇器精確定位元素
- 識別并過濾導航欄、廣告等無關內容
- 保留文檔結構(標題層級關系)
- 特殊處理表格、代碼塊等結構化內容
基于深度學習的通用文檔解析:以DeepDoc為例
傳統的解析方法各有局限,近年來基于深度學習的文檔解析技術取得了突破性進展。DeepDoc(來自RapidocAI)是一個典型代表,它采用機器視覺方式解析文檔。
DeepDoc的工作流程
- 文檔轉圖像:將PDF等文檔轉換為圖像
- OCR文本識別:識別圖像中的文本內容
- 布局分析:使用專門模型識別文檔布局結構
- 表格識別與解析:使用TSR(Table Structure Recognition)模型解析表格
- 內容整合:將識別的各部分內容整合成結構化數據
代碼示例
# 使用DeepDoc進行文檔解析
from rapidocr import RapidOCR
from deepdoc import LayoutAnalyzer, TableStructureRecognizer# 初始化模型
ocr = RapidOCR()
layout_analyzer = LayoutAnalyzer()
table_recognizer = TableStructureRecognizer()# 文檔OCR
image_path = "document.png" # 可以是PDF轉換的圖像
ocr_result = ocr.recognize(image_path)
texts, positions = ocr_result# 布局分析
layout_result = layout_analyzer.analyze(image_path)
# 識別出的布局元素:標題、段落、表格、圖片等
elements = layout_result["elements"]# 處理識別到的表格
for element in elements:if element["type"] == "table":table_image = element["image"]# 表格結構識別table_result = table_recognizer.recognize(table_image)# 表格數據可轉換為CSV或DataFrametable_data = table_result["data"]# 整合所有內容
document_content = []
for element in sorted(elements, key=lambda x: x["position"]):if element["type"] == "title":document_content.append({"type": "title", "text": element["text"]})elif element["type"] == "paragraph":document_content.append({"type": "paragraph", "text": element["text"]})elif element["type"] == "table":document_content.append({"type": "table", "data": element["table_data"]})# 其他類型元素...
DeepDoc的優勢
- 多格式支持:可處理PDF、Word、Excel、PPT、HTML等多種格式
- 結構保留:準確識別文檔的層次結構和布局
- 表格處理:精確解析復雜表格,包括合并單元格
- 圖像處理:可提取和關聯文檔中的圖像內容
- 多語言支持:支持中英文等多種語言的文檔解析
通用文檔解析:Unstructured庫
對于需要處理多種文檔格式但又不想為每種格式單獨編寫解析代碼的場景,Unstructured庫提供了統一的解決方案。
Unstructured的工作原理
Unstructured可自動識別文件格式,并調用相應的解析器提取內容,支持多種常見文檔格式。
代碼示例
from unstructured.partition.auto import partition# 自動識別文件格式并解析
elements = partition("document.pdf") # 也可以是docx, pptx, html等# 提取所有文本元素
text_elements = [el for el in elements if hasattr(el, "text")]
for element in text_elements:print(element.text)# 根據元素類型處理
from unstructured.partition.html import partition_html
from unstructured.chunking.title import chunk_by_title# HTML特定解析
html_elements = partition_html("document.html")# 按標題分塊
chunks = chunk_by_title(elements)
for chunk in chunks:print(f"標題: {chunk.title}")print(f"內容: {chunk.text}")
構建文檔處理管道
在實際的RAG系統中,我們通常需要構建完整的文檔處理管道,將解析、清洗、分塊等步驟串聯起來。
完整處理流程示例
import os
from typing import List, Dict, Any
from langchain.document_loaders import PyMuPDFLoader, WebBaseLoader, UnstructuredExcelLoader
from langchain.text_splitter import RecursiveCharacterTextSplitterdef process_document(file_path: str) -> List[Dict[str, Any]]:"""處理各種格式的文檔,返回標準化的文檔塊"""# 根據文件擴展名選擇合適的加載器ext = os.path.splitext(file_path)[1].lower()if ext == ".pdf":loader = PyMuPDFLoader(file_path)elif ext == ".html" or ext == ".htm":# 假設是本地HTML文件with open(file_path, "r", encoding="utf-8") as f:content = f.read()loader = WebBaseLoader(file_path)elif ext in [".xlsx", ".xls"]:loader = UnstructuredExcelLoader(file_path)else:# 對于其他格式,使用Unstructuredfrom langchain.document_loaders import UnstructuredFileLoaderloader = UnstructuredFileLoader(file_path)# 加載文檔documents = loader.load()# 文本清洗(去除多余空格、特殊字符等)cleaned_documents = []for doc in documents:text = doc.page_content# 基本清洗text = text.replace("\n\n", " ").replace("\t", " ")text = ' '.join(text.split()) # 規范化空格# 更新文檔doc.page_content = textcleaned_documents.append(doc)# 文本分塊text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200,separators=["\n\n", "\n", ". ", " ", ""])chunks = text_splitter.split_documents(cleaned_documents)# 轉換為標準格式processed_chunks = []for chunk in chunks:processed_chunks.append({"text": chunk.page_content,"metadata": chunk.metadata,"source": file_path,"chunk_id": f"{os.path.basename(file_path)}_{chunks.index(chunk)}"})return processed_chunks# 使用示例
pdf_chunks = process_document("example.pdf")
html_chunks = process_document("example.html")
excel_chunks = process_document("example.xlsx")# 合并所有文檔的處理結果
all_chunks = pdf_chunks + html_chunks + excel_chunks# 現在可以將這些塊用于向量化和索引

)



)






)


)
)
 機器人環境和環境數據)
)
