手機打電話時如何將通話對方的聲音在手機上識別成文字
--本地AI電話機器人
上一篇:手機打電話時由對方DTMF響應切換多級IVR語音應答(一)
下一篇:手機打電話時由對方DTMF響應切換多級IVR語音應答(二)
- 一、前言
本篇章的內容采用阿里的FunASR的模型和運算庫,采用純離線的方式(模型庫下載完畢并加載后,可以完全關閉Wifi和4G后再識別),進行手機本地的ASR(語音轉文字)識別。
由于本次只選用FunASR的離線部分的模型庫,App初次加載ASR時,會從服務器單獨下載8.15M的armeabi平臺的so動態庫,以及208M的asr_offline與vad的模型文件。存放與手機本地sdcard中,供App進行加載和使用。
其實這個功能在2023年11月的時候已經在“智能撥號器App”中簡單的調試了出來,效果也算勉強能看一看。但真正要達到商用的效果,還是得專項針對性的優化一番。在該App中的識別效果如下:
(由于FunASR的標點符號模型高達1.5G,太大了,此處不加載標點符號的模型)
?
智能撥號器App:http://120.78.211.195:8060/Dialer.apk
撥號器SDK示例app:http://120.78.211.195:8060/sdk/SdkDemo.apk
USB藍牙配件購買路徑(參考):https://item.taobao.com/item.htm?_u=pk10l4ccbcd&id=649368472986
- 二、目前業界的ASR識別的主流方向
業界內通常采用“端+云”的模式進行語音識別模塊的運算,即:本地ASR通常采用輕量級的語音識別模型,能夠處理簡單的語音指令(如喚醒詞、開燈/關燈等);而對于復雜的語音指令,則將語音信號上傳至云端進行處理。
如下圖的“車載語音的ASR識別”中,就將車載設備上接收到的語音數據,拆分為“本地ASR”和“云端ASR”兩個部分。并將兩個識別的結果已經對應的響應結果合并后,通過TTS模塊進行語音的應答。
相關的“端+云”架構模式,可以參考下圖:
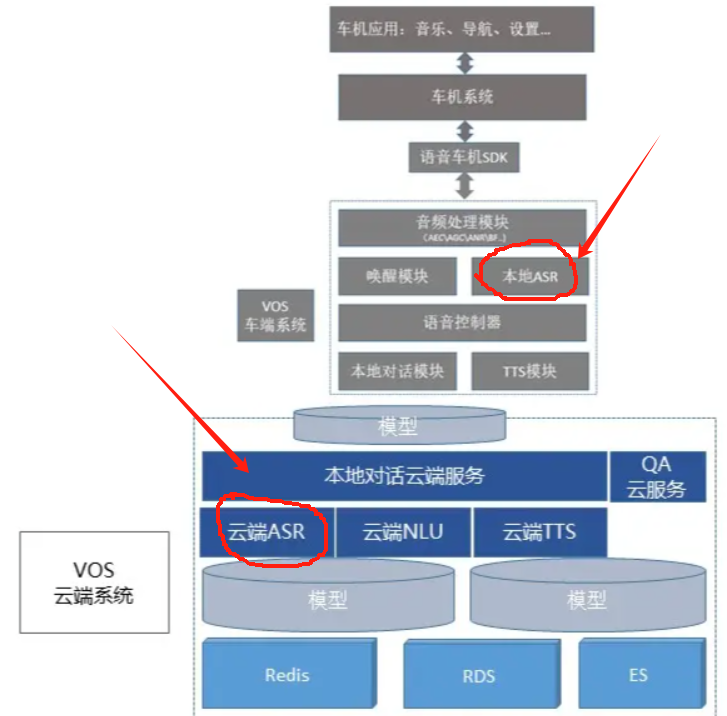
(圖片來源:
《車載語音系統(VOS)的架構與技術實現》
車載語音系統(VOS)的架構與技術實現?)
在一個典型的“智能客服系統”的架構中,ASR識別引擎所處的架構大致為如下的位置:
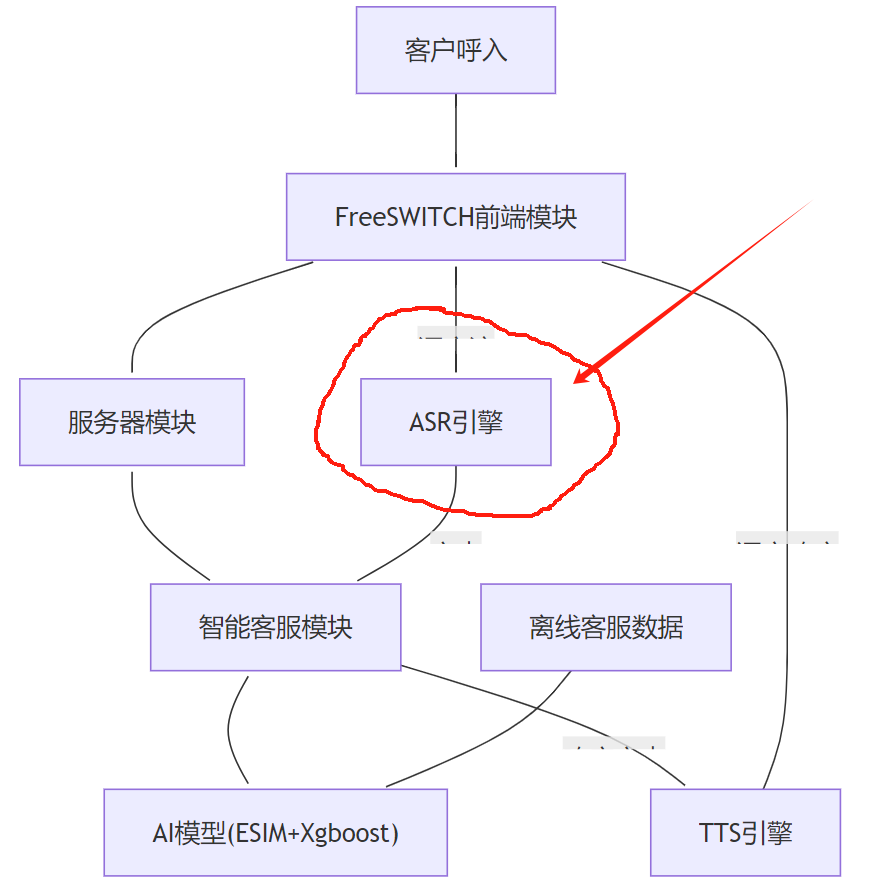
(圖片來源:
《基于FreeSWITCH和AI的熱門應用場景技術分析報告》
基于FreeSWITCH和AI的熱門應用場景技術分析報告?)
- 三、ASR模型和庫文件的加載
在SDK-Demo中,由于ASR識別使用的so動態庫和模型庫比較大,項目采用“動態加載”的方式,當界面中確實需要開啟“通話對方聲音轉文字”的功能時,才主動從服務器拉取so庫和ASR模型并進行加載。如下圖所示:
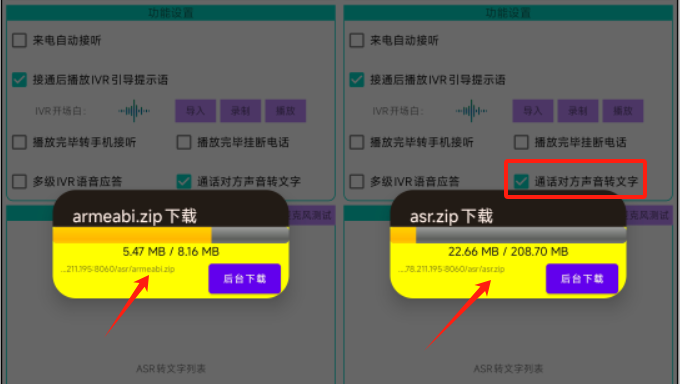
(SDK-Demo的APK才4.3M,armeabi的so庫就達8.15M,ASR僅離線模型就高達208M)
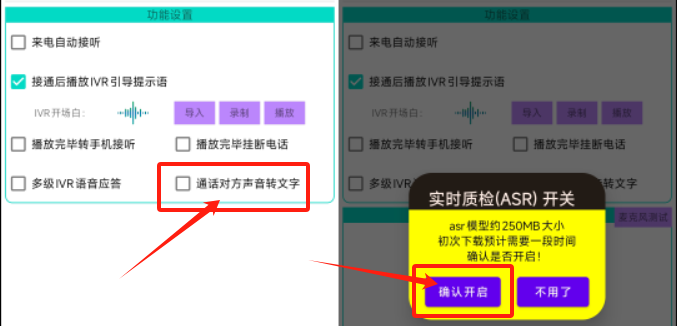
當界面中勾選對應的復選框后,App會判斷是否之前已下載過該ASR模型庫,若未下載則彈出【實時質檢(ASR)開關】的提示框,由用戶確認并手動下載對應的文件到手機本地SD卡。
用戶確認開啟后,將依次彈出兩個異步的下載進度條框,依次下載【armeabi.zip】和【asr.zip】后并解壓到SD卡的本地目錄。供App做進一步的加載使用。如下圖所示:
- 四、ASR的麥克風識別
App中,模型和so庫下載并解壓完畢后,SDK將對其進行動態加載。加載完畢后界面顯示【通話語音實時ASR轉文字】的區域。
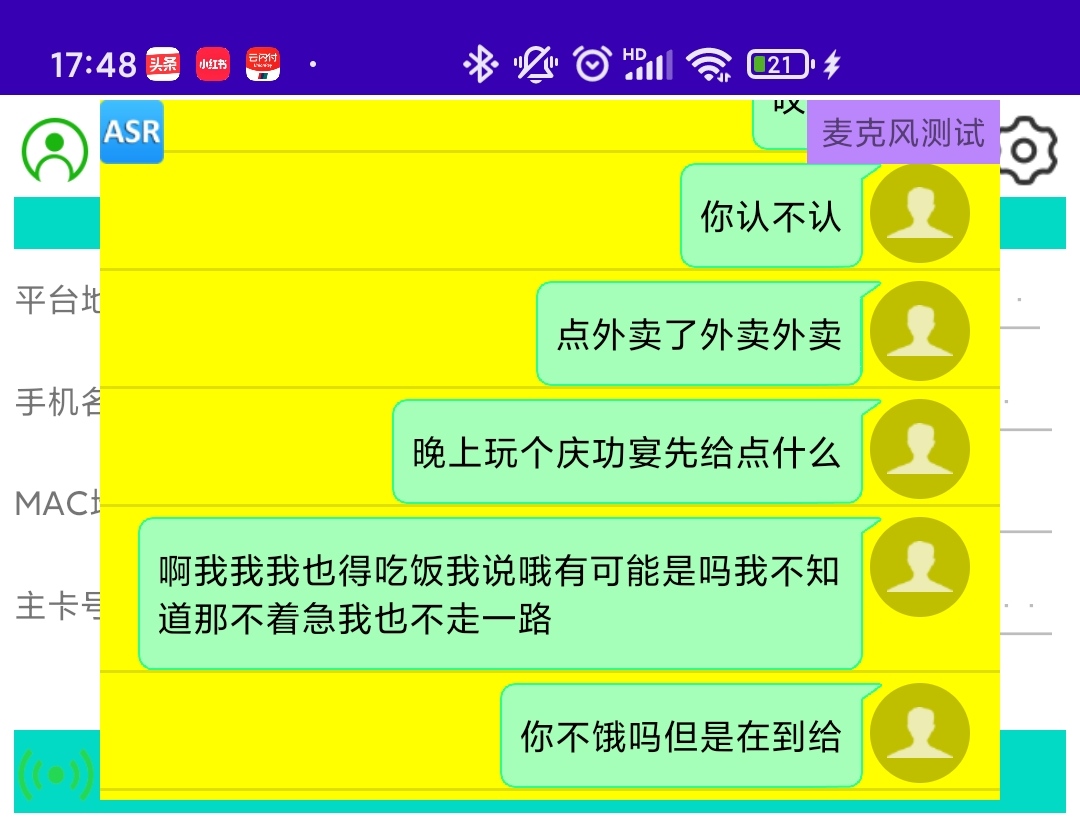
用戶可點擊區域右側的【麥克風測試】按鈕(點擊了之后文字顯示就變為“停止錄音”),進行手機本地的麥克風語音采集并根據這個語音數據進行ASR識別。識別后會同步將識別結果顯示在【通話語音實時ASR轉文字】的列表區域。如下圖所示:
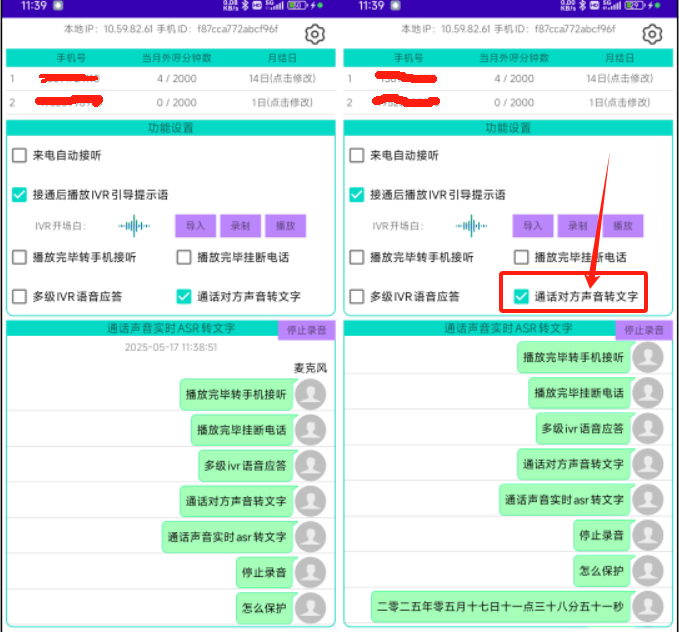
我們簡單的使用漢語,對著麥克風念了幾句話,識別結果可以參看圖中的列表的內容。
可以看出,準確率還可以,但沒有標點符號,并且識別效率太低。說完話之后要4-6秒才會識別出對應的結果。當前現狀根本沒法用在實時的商用場景。
- 五、ASR的電話通話識別
上一章講述的是單上行通道(僅麥克風數據)的識別結果。我們簡單的使用SDK-Demo的App,使用移動的手機卡來撥打10086和1008611這兩個電話。
看看在App中“通話后播放IVR引導提示語”和“通話聲音實時ASR轉文字”的功能的識別和展示效果。如下圖所示:
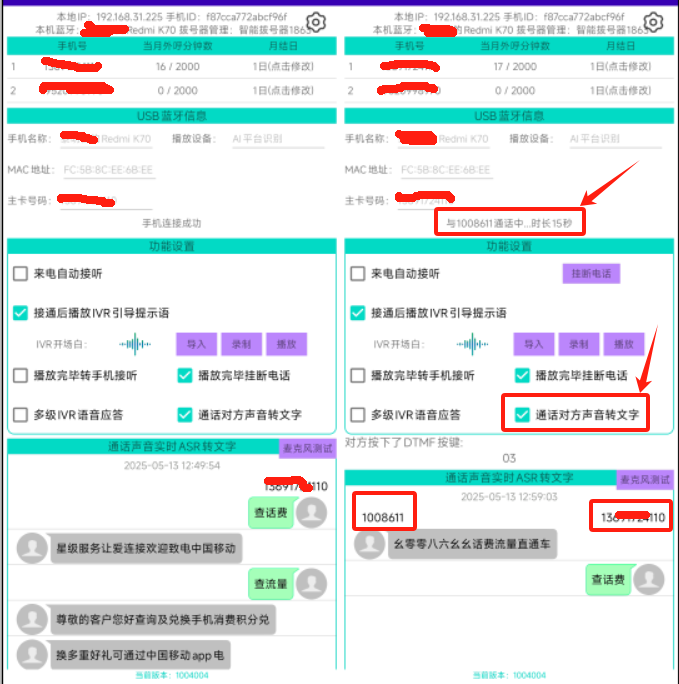
目前看來ASR的文字識別效果的準確率還可以。比如圖片右側的【136xxxxx110】號碼,它說的話是在IVR中預先錄制的“查話費/查流量/查余額”的語音。在識別過程中,ASR模型能夠很好的識別我們往通話對方注入的語音,并轉為文字進行展示。
通話列表左側的10086和1008611返回的語音中,從文字內容來看,識別準確度應該還算可以,但有兩點問題比較致命:
- 語音片段丟失,未被正常全部識別(估計可以通過加大緩沖區間來規避)
- 識別時效性太差,如上章所說,說一句話要4-6秒才會識別出結果,黃花菜都涼了。
- 六、總結
我們嘗試在藍牙電話SDK中,引入一些跟AI方向相關的算法和能力。本篇章中,我們想突破傳統的業內“端+云”的做法,想僅僅依靠端側的算力(畢竟智能手機處理性能這么強,存儲空間又大)來獨立完成ASR語音轉文字的功能。
目前從實踐的結果來看,算法和模型庫不給力啊。當前暫時沒有發現能夠直接移植到手機、且完全不依賴網絡,并能夠獲得比較良好的ASR識別的算法和模型庫。
后面有機會的話,還是要深入挖掘這個方向,或者實在不行就隨大流,部署一套“云”ASR識別的模型庫,看看識別效果、實時性等的差異,進行整體對比。
)



)



)






)


)
)