目錄
- 1 基本概念
- 2 基本操作
- 2.1 DCL
- 2.2 DDL
- 2.3 DML
- 2.4 DQL(高級查詢)
- 3 高級功能
- 3.1 視圖(無參函數)
- 3.2 存儲過程(有參函數)
- 3.3 觸發器
- 4 約束
- 4.1 主鍵約束
- 4.2 UNIQUE KEY(唯一鍵約束)
- 4.3 FOREIGN KEY(外鍵約束)
- 4.4 DEFAULT(默認值約束)
- 4.5 NOT NULL(非空約束)
- 5 索引
- 5.1 索引的定義和作用
- 5.2 常見的索引類型
- 5.3 索引實現
- 5.4 高級分類
- 5.5 索引失效
1 基本概念
數據庫定義
數據庫按照數據結構來組織、存儲和管理數據的倉庫;是一個長期存儲在計算機內的、有組織的、可共享的、統一管理的大量數據的集合。
關系型數據庫
關系模型定義:關系模型由埃德加?科德(Edgar F. Codd)在 1970 年提出。它將數據組織成二維表格的形式,由行和列組成,每一行代表一個記錄,每一列代表一個屬性。這種表格結構使得數據的組織和管理更加規范和有序。
表與表之間的關系:關系型數據庫中,表與表之間可以通過關聯關系來建立聯系,從而實現數據的整合和查詢。常見的關系有一對一、一對多和多對多。通過外鍵來實現表之間的關聯,外鍵是一個表中的字段,它引用了另一個表的主鍵,以此來建立表與表之間的聯系。例如,在 “訂單” 表和 “客戶” 表中,“訂單” 表可能有一個 “客戶 ID” 字段作為外鍵,關聯到 “客戶” 表的主鍵 “客戶 ID”,這樣就可以通過 “客戶 ID” 來查詢某個客戶的所有訂單信息,實現了兩張表之間的數據關聯。
OLTP
OLTP(online transaction processing)翻譯為聯機事務處理;主要對數據庫增刪改查;
OLTP主要用來記錄某類業務事件的發生;數據會以增刪改的方式在數據庫中進行數據的更新處理
操作,要求實時性高、穩定性強、確保數據及時更新成功;
-OLAP
OLAP(On-Line Analytical Processing)翻譯為聯機分析處理;主要對數據庫查詢;
當數據積累到一定的程度,我們需要對過去發生的事情做一個總結分析時,就需要把過去一段時間
內產生的數據拿出來進行統計分析,從中獲取我們想要的信息,為公司做決策提供支持,這時候就
是在做OLAP了;
-SQL
結構化查詢語言(Structured Query Language)簡稱SQL,是一種特殊目的的編程語言,是一種數據庫查詢和程序設計語言,用于存取數據以及查詢、更新和管理關系數據庫系統。SQL是關系數據庫系統的標準語言
分為 DQL(Data Query Language),DML(Data Manipulate Language),DDL(Data Control Language ),TCL(Transaction Control Language)
基本構成
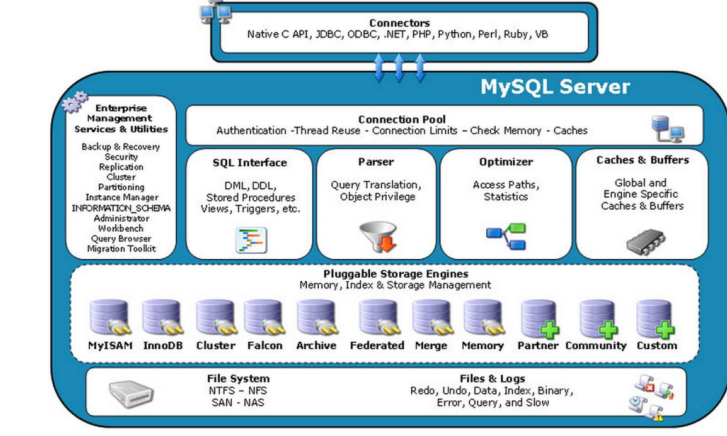
從一個select的命令執行流程講一下這個圖
- 連接層
客戶端通過如 Native C API、JDBC、ODBC 等 Connectors 建立與 MySQL Server 的連接,連接進入 Connection Pool 。在此會進行身份驗證(Authentication)、線程復用(Thread Reuse )等操作,滿足連接限制(Connection Limits )等規則后,才被允許進入下一步。 - SQL 接口層
SELECT 語句先進入 SQL Interface,在這里進行初步處理,判斷它屬于數據操作語言(DQL )。 - 解析層
隨后語句進入 Parser(解析器),進行詞法和語法分析,將 SELECT 語句拆解成一個個詞法單元,并檢查語法是否正確。同時進行語義分析,檢查語句中涉及的表、列等對象是否存在,以及用戶權限等。 - 優化層
經過解析的語句進入 Optimizer(優化器),優化器依據數據庫中的統計信息(Access Paths, Statistics ),嘗試找出執行 SELECT 查詢的最佳計劃,比如選擇合適索引、確定表連接順序和連接算法等。 - 存儲引擎層
確定執行計劃后,MySQL 通過 Pluggable Storage Engines(可插拔存儲引擎,如 MyISAM、InnoDB 等 )從底層文件系統(File System ,如 NTFS、NFS 等 )讀取數據。不同存儲引擎在內存、索引及存儲管理上各有特點。
其實還有一個查詢緩存,但是由于考慮到緩存變化,在mysql8.0取消了這個機制
三范式(用時間換空間)
- 第一范式(1NF):字段值不能再拆分,得是最小的原子單元 。比如 “地址” 字段不能既包含省市區又包含詳細街道,得拆開成多個字段 ,保證每列數據的獨立性。
- 第二范式(2NF):在滿足第一范式基礎上,要求非主鍵字段完全依賴主鍵 。不能出現部分依賴,像訂單表中 “訂單編號 + 產品編號” 是聯合主鍵,“產品價格” 依賴這倆沒問題,但 “下單時間” 只依賴 “訂單編號”,就不符合,得把 “下單時間” 移到只以 “訂單編號” 為主鍵的訂單主表 。
- 第三范式(3NF):滿足第二范式前提下,消除非主鍵字段間的傳遞依賴 。比如員工表中 “員工編號→部門編號→部門負責人”,“部門負責人” 間接依賴 “員工編號”,不符合,得把部門相關信息拆成獨立部門表 。
反范式
范式設計將相關信息分散到不同邏輯表,雖減少冗余,但多表查詢(如 JOIN 操作)開銷大。反范式通過允許少量冗余,用空間換時間,減少表連接等復雜操作,加快查詢速度 。
2 基本操作
2.1 DCL
創建用戶
以管理員(通常是 root )身份連接到 MySQL 數據庫,命令為mysql -u root -p ,輸入密碼后進入命令行。
使用CREATE USER命令創建新用戶,語法是CREATE USER 'username'@'host' IDENTIFIED BY 'password' 。
其中,username是新用戶名 ,host指定用戶允許從哪個主機連接(localhost表示本地,%表示任意 IP ),password是用戶密碼 。比如創建用戶testuser ,允許從任意主機連接,密碼為123abc ,命令是CREATE USER ‘testuser’@‘%’ IDENTIFIED BY ‘123abc’ 。引號
授予權限
權限有數據庫級、表級、列級等 ,常見權限包括SELECT(查詢)、INSERT(插入)、UPDATE(更新)、DELETE(刪除) 等。使用GRANT命令授予權限,語法為GRANT privileges ON database.table TO 'username'@'host' 。
-
授予特定權限:若要給testuser授予對testdb數據庫中所有表的查詢和插入權限,命令是GRANT SELECT,INSERT ON testdb.* TO ‘testuser’@‘%’ 。
-
授予所有權限:若希望testuser擁有對testdb數據庫的所有權限,命令是
GRANT ALL PRIVILEGES ON testdb.* TO 'testuser'@'%';若要授予對所有數據庫和表的完全訪問權限,則是GRANT ALL PRIVILEGES ON . TO ‘testuser’@‘%’。
綜合練習
-- 創建用戶
CREATE USER 'hello'@'%' IDENTIFIED BY 'password123';
-- 授予所有權限
GRANT ALL PRIVILEGES ON *.* TO 'hello'@'%';
//grant create on *.*to "hello"@"host"; 給與創造權限
-- 刷新權限
FLUSH PRIVILEGES;
-- 查詢用戶
select user host from mysql.user
-- 退出 MySQL
exit;
2.2 DDL
創建數據庫
CREATE DATABASE 數據庫名 DEFAULT CHARACTER SET utf8;
在 SQL 里,DEFAULT CHARACTER SET 是一個選項,用于設置數據庫或表默認使用的字符集。而 utf8 是一種可變長度的字符編碼,它能對世界上大部分字符進行編碼,涵蓋了眾多語言的字符。因此,DEFAULT CHARACTER SET utf8 意思是將默認字符集設定為 utf8,這意味著后續在該數據庫或表中存儲數據時,會按照 utf8 編碼規則來存儲字符。
刪除數據庫
DROP DATABASE 數據庫名;
選擇數據庫
USE 數據庫名;
創建表
CREATE TABLE `project` (
`id` INT UNSIGNED AUTO_INCREMENT ,
`course` VARCHAR(100) NOT NULL ,
`teacher` VARCHAR(40) NOT NULL ,
`price` DECIMAL(8,2) NOT NULL ,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
ENGINE=InnoDB 這個是指定引擎操作
常見數據類型
| 分類 | 數據類型 | 占用空間 | 取值范圍 | 用途示例 |
|---|---|---|---|---|
| 數值類型 | TINYINT | 1 字節 | 有符號:-128 到 127 無符號:0 到 255 | 狀態標識(如 0 或 1) |
| SMALLINT | 2 字節 | 有符號:-32768 到 32767 無符號:0 到 65535 | 較小數量統計 | |
| INT | 4 字節 | 有符號:-2147483648 到 2147483647 無符號:0 到 4294967295 | 用戶 ID、訂單編號 | |
| BIGINT | 8 字節 | 更大范圍整數 | 大型網站瀏覽量統計 | |
| FLOAT | 4 字節 | 約 7 位十進制精度 | 商品近似價格 | |
| DOUBLE | 8 字節 | 約 15 位十進制精度 | 科學計算數據存儲 | |
| DECIMAL(M,D) | 取決于 M 和 D | 精確小數 | 貨幣金額存儲 | |
| 日期和時間類型 | DATE | 3 字節 | ‘1000 - 01 - 01’ 到 ‘9999 - 12 - 31’ | 員工入職日期 |
| TIME | 3 字節 | ‘-838:59:59’ 到 ‘838:59:59’ | 會議開始時間 | |
| DATETIME | 8 字節 | ‘1000 - 01 - 01 00:00:00’ 到 ‘9999 - 12 - 31 23:59:59’ | 訂單創建時間 | |
| TIMESTAMP | 4 字節 | ‘1970 - 01 - 01 00:00:01’ UTC 到 ‘2038 - 01 - 19 03:14:07’ UTC | 數據最后修改時間 | |
| YEAR | 1 字節 | 4 位:1901 到 2155 2 位:70 到 69(代表 1970 到 2069) | 產品生產年份 | |
| 字符串類型 | CHAR(N) | N 字節(N 為 1 - 255) | 長度固定為 N | 身份證號碼 |
| VARCHAR(N) | L + 1 字節(L 為實際字符串長度,N 為 1 - 65535) | 可變長度,最大 N | 用戶昵稱、文章標題 | |
| TINYTEXT | L + 1 字節(L < 2^8) | 可變長度 | 短文本內容 | |
| TEXT | L + 2 字節(L < 2^16) | 可變長度 | 文章內容、評論 | |
| MEDIUMTEXT | L + 3 字節(L < 2^24) | 可變長度 | 較長文本內容 | |
| LONGTEXT | L + 4 字節(L < 2^32) | 可變長度 | 非常長的文本內容 | |
| 二進制類型 | BINARY(N) | N 字節(N 為 1 - 255) | 固定長度二進制數據 | 固定長度二進制編碼 |
| VARBINARY(N) | L + 1 字節(L 為實際數據長度,N 為 1 - 65535) | 可變長度二進制數據 | 可變長度二進制編碼 | |
| TINYBLOB | L + 1 字節(L < 2^8) | 可變長度二進制數據 | 小二進制文件(如小圖標) | |
| BLOB | L + 2 字節(L < 2^16) | 可變長度二進制數據 | 圖片、音頻片段 | |
| MEDIUMBLOB | L + 3 字節(L < 2^24) | 可變長度二進制數據 | 中等大小二進制文件 | |
| LONGBLOB | L + 4 字節(L < 2^32) | 可變長度二進制數據 | 大型二進制文件(如高清視頻) | |
| JSON 類型 | JSON | 取決于存儲的 JSON 數據大小 | 有效 JSON 數據 | 存儲半結構化數據(如用戶偏好設置) |
一個漢字通常占用3 個字節。不過,一些生僻字可能會占用 4 個字節
刪除表
DROP TABLE `table_name`;
TRUNCATE TABLE `table_name`; -- 截斷表 以頁為單位(至少有兩行數據),有自增索引的話,
從初始值開始累加
DELETE TABLE `table_name`; -- 逐行刪除,有自增索引的話,從之前值繼續累加
選delete就行了 因為支持回滾
2.3 DML
增
INSERT INTO table_name (field1, field2, ..., fieldn) VALUES (value1, value2, ..., valuen);
-- 常規做法 自增列會自己加載
insert into `project` (`course`,`teacher`,`price`)values ("sh","張山",23.2);
-- 不指定列 直接放
insert into `project` values (1,"英語","張山",23.2);
刪除
DELETE FROM table_name [WHERE Clause];、
CREATE TABLE students (id INT PRIMARY KEY,name VARCHAR(50),age INT
);INSERT INTO students (id, name, age) VALUES
(1, '張三', 20),
(2, '李四', 22),
(3, '王五', 21);
-- 刪除行
DELETE FROM students WHERE age = 22;--刪除列
ALTER TABLE table_name
DROP COLUMN column_name;
** 更改**
UPDATE table_name SET field1=new_value1, field2=new_value2 [, fieldn=new_valuen]
UPDATE 0voice_tblSETname = 'Mark' WHERE id = 2;
2.4 DQL(高級查詢)
展現數據庫和表
show databases/tables
展現表的內容 基礎查詢
SELECT field1, field2,...fieldN FROM table_name
條件查詢
-- 查詢姓名為 鄧洋洋 的學生信息
SELECT * FROM `student` WHERE `name` = '鄧洋洋';
-- 查詢性別為 男,并且班級為 2 的學生信息
SELECT * FROM `student` WHERE `gender`="男" AND `class_id`=2;
利用where 做判斷
查詢后排序
-- 關鍵字:order by field, asc:升序, desc:降序
SELECT * FROM `score` ORDER BY `num` ASC;
-- 按照多個字段排序
SELECT * FROM `score` ORDER BY `course_id` DESC, `num` DESC;
聚合查詢
以下是關于常見聚合查詢函數的表格總結:
| 函數名稱 | 功能描述 | 語法示例 | 適用數據類型 | 備注 |
|---|---|---|---|---|
COUNT() | 統計記錄的數量,COUNT(*) 統計所有記錄數(包含 NULL),COUNT(column_name) 統計指定列非 NULL 的記錄數 | COUNT(*) COUNT(column_name) | 所有數據類型(COUNT(*));一般用于數值、字符等列( COUNT(column_name)) | NULL 值處理方式不同,COUNT(*) 包含 NULL,COUNT(column_name) 忽略 NULL |
SUM() | 計算指定列中數值的總和 | SUM(column_name) | 數值類型(如 INT、FLOAT、DECIMAL 等) | 僅對數值列有效,忽略 NULL 值 |
AVG() | 計算指定列中數值的平均值 | AVG(column_name) | 數值類型(如 INT、FLOAT、DECIMAL 等) | 僅對數值列有效,忽略 NULL 值 |
MAX() | 找出指定列中的最大值 | MAX(column_name) | 數值、日期、字符串等數據類型 | 忽略 NULL 值 |
MIN() | 找出指定列中的最小值 | MIN(column_name) | 數值、日期、字符串等數據類型 | 忽略 NULL 值 |
GROUP_CONCAT() | 將分組后的某列值連接成一個字符串,可指定分隔符、去重、排序等 | GROUP_CONCAT([DISTINCT] column_name [ORDER BY column_name ASC/DESC] [SEPARATOR separator]) | 字符類型數據 | 常用于將分組后的字符串類型數據連接起來 |
分組查詢
-- 可以把查詢出來的結果根據某個條件來分組顯示
SELECT `gender` FROM `student` GROUP BY `gender`;
-- 分組加聚合
SELECT `gender`, count(*) as num FROM `student` GROUP BY `gender`;
-- 分組加條件
SELECT `gender`, count(*) as num FROM `student` GROUP BY `gender` HAVING num
±-------+
| gender |
±-------+
| 男 |
| 女 |
±-------+
±-------±----+
| gender | num |
±-------±----+
| 男 | 10 |
| 女 | 6 |
±-------±----+
±-------±----+
| gender | num |
±-------±----+
| 男 | 10 |
±-------±----+
關于執行順序
SQL 查詢語句各子句的執行順序如下:
FROM:這是最先執行的子句,它的作用是從指定的表或者視圖中選取數據。在這個階段,數據庫會根據 FROM 子句中指定的表名,從存儲介質中讀取相應的數據,并將這些數據加載到內存中,為后續的操作做準備。
JOIN:如果查詢中使用了 JOIN 操作(如 INNER JOIN、LEFT JOIN 等),數據庫會在 FROM 子句選取的數據基礎上,根據 JOIN 條件將多個表中的數據進行關聯。通過 JOIN 操作,可以將不同表中相關的數據組合在一起,形成一個新的結果集。
WHERE:該子句用于對 FROM 和 JOIN 操作得到的結果集進行過濾。數據庫會根據 WHERE 子句中指定的條件,對每一行數據進行判斷,只保留滿足條件的數據行,將不滿足條件的行過濾掉。
GROUP BY:GROUP BY 子句用于對經過 WHERE 子句過濾后的結果集進行分組。數據庫會根據 GROUP BY 子句中指定的列,將具有相同值的行分為一組。分組操作通常與聚合函數(如 SUM、AVG、COUNT 等)一起使用,以便對每個組的數據進行統計分析。
HAVING:HAVING 子句用于對分組后的結果進行過濾。它與 WHERE 子句類似,但 WHERE 子句是在分組之前對行進行過濾,而 HAVING 子句是在分組之后對組進行過濾。HAVING 子句通常與聚合函數一起使用,用于篩選滿足特定條件的組。
SELECT:該子句用于從經過前面各子句處理后的結果集中選取指定的列。數據庫會根據 SELECT 子句中指定的列名,從結果集中提取相應的數據,并將這些數據作為最終結果的一部分。
DISTINCT:如果 SELECT 子句中使用了 DISTINCT 關鍵字,數據庫會對 SELECT 子句選取的結果進行去重處理,只保留唯一的行。
ORDER BY:ORDER BY 子句用于對最終結果集進行排序。數據庫會根據 ORDER BY 子句中指定的列,按照升序(ASC)或降序(DESC)對結果集進行排序,使結果集按照指定的順序呈現
聯表查詢
在 SQL 中,INNER JOIN、LEFT JOIN 和 RIGHT JOIN 是用于合并多個表數據的連接操作,它們的主要區別在于處理不匹配行的方式。以下是它們的區別對比表格:
| 連接類型 | 關鍵字 | 操作原理 | 結果特點 | 示例(假設表 A 和表 B 通過列 col 連接) |
|---|---|---|---|---|
| 內連接 | INNER JOIN | 只返回兩個表中連接列匹配的行,即只有當表 A 中的某行與表 B 中的某行在連接列上有相同的值時,才會將這兩行組合并包含在結果集中。 | 結果集只包含兩個表中連接列值匹配的行,不包含任何不匹配的行。 | SELECT * FROM A INNER JOIN B ON A.col = B.col; |
| 左連接 | LEFT JOIN(部分數據庫支持 LEFT OUTER JOIN) | 以左表(FROM 子句中指定的第一個表)為基礎,返回左表中的所有行,對于右表,只返回與左表連接列匹配的行。如果左表中的某行在右表中沒有匹配的行,則右表的列值將顯示為 NULL。 | 結果集包含左表的所有行,右表中匹配的行正常顯示數據,不匹配的行對應列顯示為 NULL。 | SELECT * FROM A LEFT JOIN B ON A.col = B.col; |
| 右連接 | RIGHT JOIN(部分數據庫支持 RIGHT OUTER JOIN) | 與左連接相反,以右表為基礎,返回右表中的所有行,對于左表,只返回與右表連接列匹配的行。如果右表中的某行在左表中沒有匹配的行,則左表的列值將顯示為 NULL。 | 結果集包含右表的所有行,左表中匹配的行正常顯示數據,不匹配的行對應列顯示為 NULL。 | SELECT * FROM A RIGHT JOIN B ON A.col = B.col; |
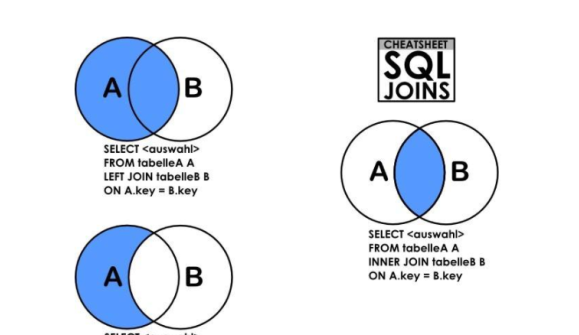
左 右 內連接
-- 創建 orders 表
CREATE TABLE orders (order_id INT PRIMARY KEY,customer_id INT,order_amount DECIMAL(10, 2)
);-- 插入數據
INSERT INTO orders (order_id, customer_id, order_amount) VALUES
(1, 101, 200.00),
(2, 102, 300.00);-- 創建 customers 表
CREATE TABLE customers (customer_id INT PRIMARY KEY,customer_name VARCHAR(50)
);-- 插入數據
INSERT INTO customers (customer_id, customer_name) VALUES
(101, '張三'),
(103, '李四');-- 查詢語句
SELECT o.order_id, c.customer_name, o.order_amount
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE o.order_amount > 150;
這個查詢的執行順序如下:
FROM:從 orders 表(別名 o)和 customers 表(別名 c)中選取數據。
JOIN(包含 ON):按照 ON 子句的條件 o.customer_id = c.customer_id,把 orders 表和 customers 表的數據進行關聯,生成一個臨時的結果集。
WHERE:對關聯后的結果集進行過濾,只保留 order_amount 大于 150 的行。
SELECT:從過濾后的結果集中選取 order_id、customer_name 和 order_amount 列。
子查詢
也是生成一個虛擬表
select * from course where teacher_id = (select tid from teacher where tname = '謝小二老師')
3 高級功能
3.1 視圖(無參函數)
視圖
定義:是一個虛擬的表,它是基于一個或多個實際表的查詢結果。視圖并不實際存儲數據,而是在查詢時動態地從基礎表中獲取數據。
作用:可以簡化復雜的查詢,提供數據的不同視角,并且可以對用戶隱藏敏感信息。例如,創建一個視圖只顯示學生的姓名和成績,而不顯示其他敏感信息,如身份證號碼等。
語法示例:在 MySQL 中,創建一個視圖來顯示學生的基本信息和成績。
CREATE VIEW student_view AS
SELECT s.student_name, g.grade
FROM students s
JOIN student_grades g ON s.student_id = g.student_id;
由于是虛擬表
SELECT * FROM sales_employees_view;
-- 或者指定列查詢
SELECT employee_name, salary FROM sales_employees_view;
3.2 存儲過程(有參函數)
定義:是一組預編譯的 SQL 語句集合,它可以接受參數、執行一系列的操作,并返回結果。存儲過程在數據庫服務器上存儲和執行,客戶端可以通過調用存儲過程來執行相應的操作。
作用:可以提高數據庫的性能和安全性,減少網絡傳輸開銷,并且方便對數據庫操作進行集中管理和維護。例如,將復雜的查詢邏輯封裝在存儲過程中,通過傳遞不同的參數來執行不同的查詢操作。
語法示例:在 MySQL 中,創建一個存儲過程來查詢學生的成績。
CREATE PROCEDURE get_student_grades(IN student_id INT)
BEGIN//開始SELECT grade FROM student_grades WHERE student_id = student_id;
END;//結束
IN :參數的值必須在調用存儲過程時指定,0在存儲過程中修改該參數的值不能被返回,可以設
置默認值
OUT :該值可在存儲過程內部被改變,并可返回
INOUT :調用時指定,并且可被改變和返回
使用 call get_student_grades(23);
3.3 觸發器
觸發器(trigger)是MySQL提供給程序員和數據分析員來保證數據完整性的一種方法,它是與表事件相關的特殊的存儲過程,它的執行不是由程序調用,也不是手工啟動,而是由事件來觸發,比如當對一個表進行DML操作( insert , delete , update )時就會激活它執行。
監視對象: table
監視事件: insert 、 update 、 delete
觸發時間: before , after
觸發事件: insert 、 update 、 delete
-- 創建 orders 表
CREATE TABLE orders (order_id INT AUTO_INCREMENT PRIMARY KEY,product_name VARCHAR(100),quantity INT
);-- 創建 order_logs 表
CREATE TABLE order_logs (log_id INT AUTO_INCREMENT PRIMARY KEY,order_id INT,action VARCHAR(20),log_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);-- 創建觸發器
DELIMITER //
CREATE TRIGGER after_order_insert
AFTER INSERT ON orders
FOR EACH ROW
BEGININSERT INTO order_logs (order_id, action)VALUES (NEW.order_id, 'INSERT');
END //
DELIMITER ;-- 測試插入數據
INSERT INTO orders (product_name, quantity) VALUES ('手機', 10);-- 查詢 order_logs 表驗證觸發器
SELECT * FROM order_logs; 假設存在 products 表存儲產品信息,product_price_logs 表記錄產品價格的更新日志。當 products 表中的產品價格更新時,觸發一個觸發器記錄更新信息。
在 INSERT 型觸發器中, NEW 用來表示將要( BEFORE )或已經( AFTER )插入的新數據;
在 DELETE 型觸發器中, OLD 用來表示將要或已經被刪除的原數據;
在 UPDATE 型觸發器中, OLD 用來表示將要或已經被修改的原數據, NEW 用來表示將要或已經修
改為的新數據;
4 約束
為了實現數據的完整性,對于innodb,提供了以下幾種約束,primary key,unique key,foreign key, default, not null
4.1 主鍵約束
定義:PRIMARY KEY 用于唯一標識表中的每一行記錄,一張表只能有一個主鍵。主鍵列的值不能為 NULL,且必須是唯一的。
作用:保證數據的唯一性和完整性,同時可以加快數據庫的查詢速度,因為數據庫通常會為主鍵自動創建索引。
-- 在創建表時定義主鍵
CREATE TABLE students (student_id INT PRIMARY KEY,student_name VARCHAR(50),age INT
);-- 或者使用復合主鍵(由多個列組成)
CREATE TABLE orders (order_id INT,product_id INT,quantity INT,PRIMARY KEY (order_id, product_id)
);
4.2 UNIQUE KEY(唯一鍵約束)
定義:UNIQUE KEY 用于確保列或列組合的值在表中是唯一的,但與主鍵不同的是,唯一鍵列可以包含 NULL 值,并且一張表可以有多個唯一鍵。
作用:保證數據的唯一性,防止重復數據的插入,但不強制要求非空。
-- 在創建表時定義唯一鍵
CREATE TABLE employees (employee_id INT,employee_email VARCHAR(100),UNIQUE (employee_email)
);-- 也可以在已有表上添加唯一鍵
ALTER TABLE employees
ADD UNIQUE (employee_id);
4.3 FOREIGN KEY(外鍵約束)
定義:FOREIGN KEY 用于建立表與表之間的關聯關系,一個表中的外鍵指向另一個表的主鍵。外鍵列的值必須是關聯表中主鍵列的有效值,或者為 NULL(如果允許為空)。
作用:保證數據的引用完整性,確保相關表之間的數據一致性。
-- 創建主表
CREATE TABLE departments (department_id INT PRIMARY KEY,department_name VARCHAR(50)
);-- 創建從表,并定義外鍵
CREATE TABLE employees (employee_id INT PRIMARY KEY,employee_name VARCHAR(50),department_id INT,FOREIGN KEY (department_id) REFERENCES departments(department_id)
);
建立關聯關系與保證數據完整性
維護數據一致性:外鍵用于確保相關表之間的數據一致性。通過在一個表中設置外鍵,使其指向另一個表的主鍵,數據庫可以保證外鍵列中的值在關聯表的主鍵列中存在,或者為空(如果允許為空)。這可以防止出現孤立數據,即子表中的記錄引用了父表中不存在的主鍵值,從而保證了數據的完整性和一致性。例如,在員工表和部門表的關聯中,員工表中的部門 ID 作為外鍵,保證了每個員工所屬的部門在部門表中是存在的,不會出現員工屬于一個不存在的部門的情況。
實現級聯操作:外鍵還可以實現級聯操作,如級聯刪除和級聯更新。當在父表中刪除或更新一條記錄時,通過外鍵的級聯設置,可以自動在子表中進行相應的刪除或更新操作,以確保數據的一致性。例如,當刪除一個部門時,可以通過外鍵的級聯設置,自動刪除該部門下的所有員工記錄
4.4 DEFAULT(默認值約束)
定義:DEFAULT 用于為列指定一個默認值,當插入記錄時,如果沒有為該列提供值,則使用默認值。
作用:簡化數據插入操作,確保列始終有一個合理的值。
語法示例:
-- 在創建表時定義默認值
CREATE TABLE products (product_id INT PRIMARY KEY,product_name VARCHAR(100),price DECIMAL(10, 2) DEFAULT 0.00
);-- 插入記錄時,如果不指定 price 列的值,將使用默認值
INSERT INTO products (product_id, product_name)
4.5 NOT NULL(非空約束)
定義:NOT NULL 用于確保列的值不能為空,插入記錄時必須為該列提供一個有效的值。
作用:保證數據的完整性,防止插入空值導致數據不完整。
語法示例:
-- 在創建表時定義非空約束
CREATE TABLE customers (customer_id INT PRIMARY KEY,customer_name VARCHAR(50) NOT NULL,email VARCHAR(100)
);-- 插入記錄時,customer_name 列必須有值
INSERT INTO customers (customer_id, customer_name, email) VALUES (1, '張三', 'zhangsan@example.com');
5 索引
5.1 索引的定義和作用
定義:索引是一種特殊的數據結構,它存儲了表中某些列的值以及這些值對應的行在磁盤上的物理位置(或邏輯位置)。通過索引,數據庫可以避免全表掃描,直接定位到包含所需數據的行,從而大大提高查詢效率。
作用
加快查詢速度:這是索引最主要的作用。例如,在一個包含大量記錄的表中,如果要查找某個特定值的記錄,沒有索引時數據庫需要逐行掃描整個表;而有了索引,數據庫可以根據索引快速定位到包含該值的行。
5.2 常見的索引類型
主鍵索引:一種特殊的唯一索引,每個表只能有一個主鍵索引,用于唯一標識表中的每一行記錄。主鍵索引的列值不能為 NULL,并且在創建表時可以直接指定某列為主鍵,數據庫會自動為主鍵創建索引。
主鍵索引:一種特殊的唯一索引,每個表只能有一個主鍵索引,用于唯一標識表中的每一行記錄。主鍵索引的列值不能為 NULL,并且在創建表時可以直接指定某列為主鍵,數據庫會自動為主鍵創建索引。例如:
CREATE TABLE students (student_id INT PRIMARY KEY,student_name VARCHAR(50),age INT
);
唯一索引:確保索引列的值是唯一的,但可以包含 NULL 值。一張表可以有多個唯一索引。例如:
CREATE UNIQUE INDEX idx_email ON employees (email);
普通索引:最基本的索引類型,它沒有唯一性的限制,主要用于提高查詢效率。例如:
CREATE INDEX idx_age ON students (age);
組合索引
對表上的多個列進行索引
INDEX idx(key1,key2[,...]);
**加粗樣式**UNIQUE(key1,key2[,...]);
PRIMARY KEY(key1,key2[,...]);
CREATE INDEX idx_multiple_columns ON table_name (column1, column2);
5.3 索引實現
使用b+實現,b+樹的優勢
查詢快:B+ 樹是多路平衡的,節點可有多子節點,樹矮,查數據時磁盤 I/O 次數少。而且節點內用二分查找定位,速度快。
范圍查詢強:葉子節點連成有序鏈表,做范圍查詢時,找到起始點后沿鏈表遍歷到結束點就行,不用多次從根節點查。
磁盤讀寫優:節點大小和磁盤塊適配,一次 I/O 能讀寫一個完整節點,減少磁盤碎片化,提升讀寫效率。
維護成本低:插入和刪除數據時,通過分裂、合并等操作自動保持平衡,操作簡單,不用復雜重構。
數據有序:索引鍵有序存,排序查詢可直接用這個順序,不用額外排序。
每一個索引都有一個b+樹
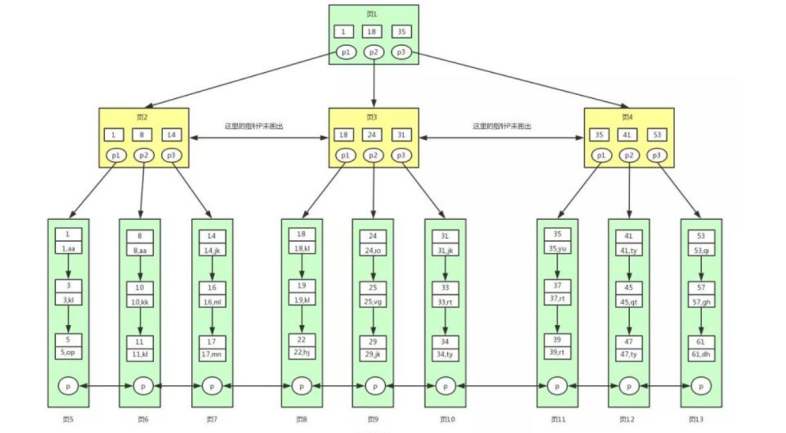
5.4 高級分類
聚集索引:一個表只能有一個聚集索引,它決定了表中數據的物理存儲順序。通常,主鍵索引就是聚集索引,數據記錄按照主鍵的順序存儲在磁盤上。
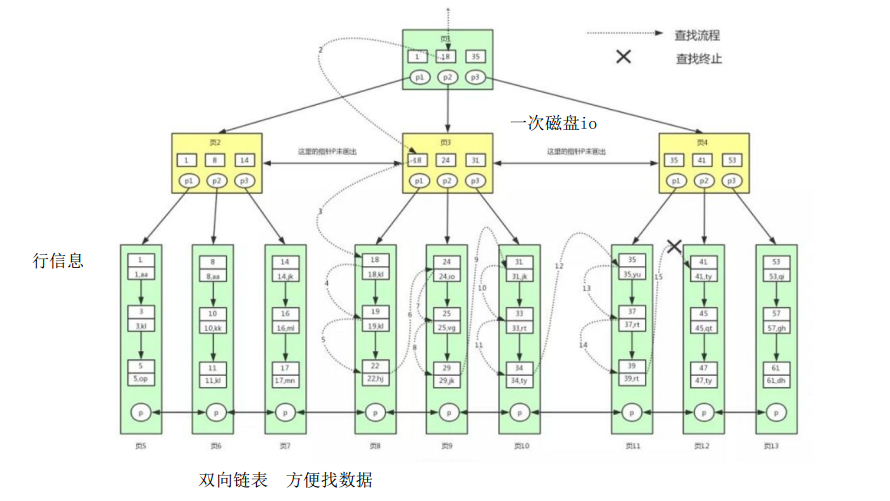
直接可以找到數據
輔助索引
葉子節點不包含行記錄的全部數據;輔助索引的葉子節點中,除了用來排序的 key 還包含一個bookmark ;該書簽存儲了聚集索引的 key
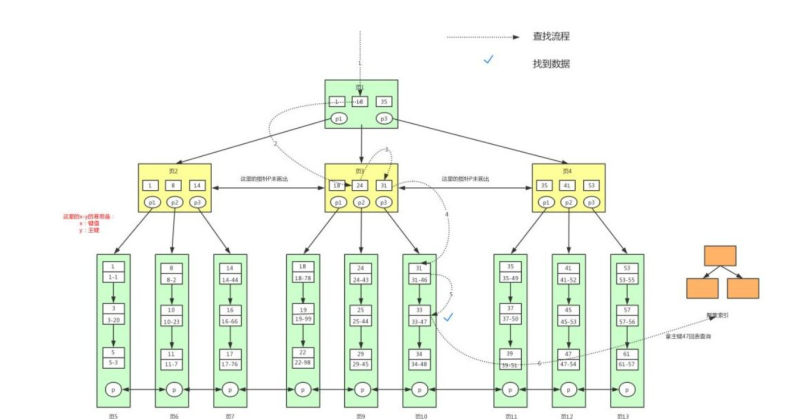
回表過程
當使用普通索引進行查詢時,如果查詢的列不在該普通索引中,就需要進行回表操作。具體步驟如下:
第一步:通過普通索引定位主鍵值:數據庫首先根據普通索引的 B + 樹結構,找到滿足查詢條件的索引鍵,并獲取對應的主鍵值。
第二步:根據主鍵值在聚集索引中查找數據記錄:使用第一步得到的主鍵值,在聚集索引的 B + 樹中進行查找,最終定位到實際的數據記錄
聯合 B + 樹索引(組合索引) 最左匹配原則
聯合 B + 樹索引是基于多個列創建的索引。例如,對于一個包含(col1, col2, col3)的聯合索引,B + 樹的索引鍵是這三個列值的組合。
索引順序:在聯合索引中,列的順序非常重要。B + 樹會首先按照第一列的值進行排序,當第一列的值相同時,再按照第二列的值排序,以此類推。例如,對于聯合索引(col1, col2),查詢條件WHERE col1 = ‘value1’ AND col2 = 'value2’可以充分利用該索引;而如果查詢條件只有WHERE col2 = ‘value2’,則可能無法使用該聯合索引。
范圍查詢:聯合索引對于范圍查詢也很有用。例如,對于聯合索引(col1, col2),查詢條件WHERE col1 = ‘value1’ AND col2 > 'value2’可以利用索引進行高效的范圍查詢。
覆蓋索引
覆蓋索引是指一個索引包含了查詢語句中所有需要引用的列。當查詢可以完全通過索引來滿足,而不需要訪問表中的數據行時,就可以避免回表操作,從而提高查詢性能。
假設有一個orders表,包含order_id(主鍵)、customer_id、order_date、total_amount等列。現在有一個查詢需求:查詢每個客戶最近一次訂單的日期和總金額。
SELECT customer_id, MAX(order_date), total_amount
FROM orders
GROUP BY customer_id;
CREATE INDEX idx_customer_order_date_amount ON orders (customer_id, order_date DESC, total_amount);
5.5 索引失效
對索引列做計算或函數操作
在 SQL 查詢里,要是對索引列使用了計算或者函數,索引就會失效。比如WHERE age + 1 = 20,這里對索引列age做了加法運算,數據庫無法直接用索引快速定位數據,只能全表掃描。
模糊查詢以通配符開頭
當用LIKE進行模糊查詢時,如果以通配符%開頭,像WHERE name LIKE ‘%張三’,索引也會失效。因為索引是按順序存儲數據的,以%開頭時,數據庫沒辦法利用索引快速定位。
類型不匹配
要是查詢條件里索引列的數據類型和查詢值的數據類型不一致,也會導致索引失效。例如,索引列id是整數類型,而查詢寫成WHERE id = ‘123’,數據庫可能不會使用索引。
索引列使用了OR
如果在查詢條件中,索引列使用了OR連接多個條件,并且其中部分條件無法使用索引,那么整個索引可能會失效。比如WHERE id = 1 OR name = ‘張三’,若name列沒有索引,可能導致id列的索引也無法發揮作用。
范圍查詢后使用索引列
在范圍查詢(如>、<、BETWEEN)之后,后續的索引列可能無法使用索引。例如,對于聯合索引(col1, col2),查詢WHERE col1 > 10 AND col2 = 20,在col1做了范圍查詢后,col2可能無法使用索引。
















)


