你是不是也曾在朋友面前自信滿滿地說:“AI我可太熟了!”然后隨便丟一句“寫篇短文”給大模型,坐等它秒出結果?但你有沒有想過,那幾秒鐘里,AI到底干了什么?從你敲下的幾個字,到屏幕上蹦出的流暢句子,這背后可不是什么“魔法”。如果你連LLM(大語言模型)如何生成文本都不清楚,還好意思說自己懂AI?別急,今天我就帶你拆開這臺“寫作機器”,用最直白的方式講清楚每個步驟,看完你再吹牛,至少底氣足點!
一、LLM文本生成的核心步驟
1. 輸入階段(Input):一切從你開始
一切的開始,來自用戶的輸入。你可以輸入一個提示、一個問題,或者是一段未完成的句子,模型會基于這個“起點”繼續生成內容。
2. 分詞(Tokenization):把句子拆成小塊
為了讓模型理解文本,首先需要將文字拆解成更小的單元——Token。Token 可能是一個詞、一個子詞,甚至是一個字符,具體取決于使用的分詞器(如 BPE、WordPiece 等)。比如“Hello, I'm an AI assistant.”可能會被拆成['Hello', ',', 'I', "'m", 'an', 'AI', 'assistant', '.']。
3. 嵌入(Embedding):給每個小塊賦予“含義”
接下來,分詞后的每個Token會被轉換為向量,也就是我們常說的“嵌入表示”。這個過程幫助模型理解每個Token的語義信息。比如,“Hello”和“Hi”在嵌入空間里會很接近。
4. 位置編碼(Positional Encoding):記住誰在前誰在后
由于 Transformer 本身不具備處理“順序”的能力,因此需要為每個Token添加位置信息,以便模型知道哪個詞在前,哪個在后。位置編碼給每個Token加上順序信息,確保模型理解詞序,比如“貓追狗”和“狗追貓”的區別。
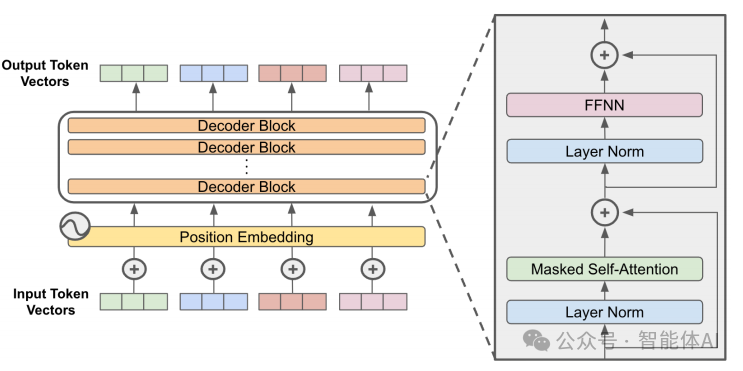
5. Transformer處理階段:大腦開始運轉
這一步是 LLM 的“核心大腦”部分。嵌入和位置編碼后的向量會被送入多層Transformer結構中,每層都包含自注意力機制和前饋神經網絡。自注意力(Self-Attention)允許模型在處理某個詞時,同時“關注”其他詞,從而捕捉長距離的上下文依賴。它通常有多層(比如Llama3有32層),逐步完善文本。
6. 輸出轉換(Output Transformation):準備“選詞”
經過多層 Transformer 后,輸出結果還不能直接變成文字。我們需要通過一個線性變換,將它映射回詞表中的每個詞可能性。處理后的結果變成一個巨大的向量,每個維度對應詞匯表中的一個詞。
7. Softmax函數:把潛力變成概率
接下來應用 Softmax,把這些值轉化為概率分布,表示下一個Token是詞表中每個詞的可能性有多大。
8. 采樣(Sampling):決定下一個詞
有了概率分布,模型就可以選擇下一個Token了。不同的策略會影響生成結果,比如:
-
貪心采樣(Greedy):每次選最高概率的詞。
-
隨機采樣(Random):按概率隨機選擇一個詞。
-
核采樣(Top-p):在累計概率前p%的詞中隨機選一個。
-
溫度采樣(Temperature):控制生成的多樣性。
9. 生成文本:一步步拼湊
Token 一個個被采樣出來,拼接在一起,直到模型遇到結束標記,或達到設定長度,完成整個文本生成過程。模型通過重復預測和采樣的過程,直到生成完整的句子。
10. 后處理(Post-processing):給文本“化妝”
最后,對生成的文本進行一些清理,比如去掉特殊符號、調整格式,甚至可以進行語法檢查,使得文本更自然可讀。
二、用代碼案例深入理解生成流程(程序員最興奮的章節

)
我們以 OpenAI 的 GPT-2 模型為例,配合?tikToken?分詞器和 PyTorch 框架,來展示如何分詞、嵌入,并查看每個Token的語義向量。
import?torch
import?tikToken
from?transformers?import?GPT2Model# 初始化編碼器
encoder = tikToken.get_encoding("gpt2")
model = GPT2Model.from_pretrained("gpt2")# 輸入文本
text =?"Hello, I'm an AI assistant."
Token_ids = encoder.encode(text)
Tokens = [encoder.decode([tid])?for?tid?in?Token_ids]# 轉換為張量
inputs = torch.tensor([Token_ids])# 獲取模型嵌入輸出
with?torch.no_grad():outputs = model(inputs)last_hidden_states = outputs.last_hidden_state
for?Token, emb?in?zip(Tokens, last_hidden_states[0]):print(f"Token:?{Token}\nEmbedding:?{emb}\n")每一個Token對應的向量(Embedding),都承載著它在語義空間中的“位置”。
三、繼續深入:從位置編碼到輸出生成
示例1:位置編碼 Positional Encoding
Transformer需要位置信息才能理解順序。以下代碼實現了位置編碼的生成:
import?torchimport?mathdef?positional_encoding(seq_length, d_model):? ??pe?= torch.zeros(seq_length, d_model)? ??position?= torch.arange(0, seq_length, dtype=torch.float).unsqueeze(1)? ??div_term?= torch.exp(torch.arange(0, d_model,?2).float() * (-math.log(10000.0) / d_model))? ??pe[:,?0::2] = torch.sin(position * div_term)? ??pe[:,?1::2] = torch.cos(position * div_term)? ??return?pepos_encoding?= positional_encoding(10,?16)print(pos_encoding)
示例2:構建一個簡化的 Transformer 模型
import torch.nn?as nnclass SimpleTransformer(nn.Module):? ? def?__init__(self, input_dim, model_dim, num_heads, num_layers):? ? ? ??super(SimpleTransformer, self).__init__()? ? ? ? self.embedding = nn.Embedding(input_dim, model_dim)? ? ? ? self.position_encoding =?positional_encoding(5000, model_dim)? ? ? ? self.transformer_layers = nn.TransformerEncoder(? ? ? ? ? ? nn.TransformerEncoderLayer(model_dim, num_heads, model_dim *?4), num_layers? ? ? ? )? ? ? ? self.fc_out = nn.Linear(model_dim, input_dim)? ? def?forward(self, x):? ? ? ? x = self.embedding(x) + self.position_encoding[:x.size(1), :]? ? ? ? x = self.transformer_layers(x)? ? ? ? return self.fc_out(x)# 示例運行model =?SimpleTransformer(input_dim=10000, model_dim=512, num_heads=8, num_layers=6)input_seq = torch.randint(0,?10000, (10,?20))output_seq =?model(input_seq)# Softmax 轉換為概率output_layer = nn.Linear(512,?10000)output_seq_transformed =?output_layer(output_seq)softmax = nn.Softmax(dim=-1)probabilities =?softmax(output_seq_transformed)
可以看到,最終得到的是一個維度為?(batch_size, seq_length, vocab_size)?的概率分布,用于采樣生成下一個詞。
示例3:采樣策略與預測
# 貪心預測predicted_tokens = torch.argmax(probabilities, dim=-1)print(predicted_tokens)# 隨機采樣predicted_tokens_random = torch.multinomial(? ? probabilities.view(-1, probabilities.size(-1)), 1).view(probabilities.size()[:-1])print(predicted_tokens_random)
示例4:文本生成主流程
以?LLaMA3?為例,下面是一個典型的生成循環:def generate_text(model, tokenizer, start_text, max_length):
? ? tokens = tokenizer.encode(start_text)? ? generated = tokens.copy()? ? for _ in?range(max_length -?len(tokens)):? ? ? ? input_tensor = torch.tensor([generated])? ? ? ? with torch.no_grad():? ? ? ? ? ? output =?model(input_tensor)? ? ? ? next_token_logits = output[:, -1, :]? ? ? ? next_token_probs = torch.softmax(next_token_logits, dim=-1)? ? ? ? next_token = torch.multinomial(next_token_probs, num_samples=1).item()? ? ? ? generated.append(next_token)? ? return tokenizer.decode(generated)
四、總結
看完這篇,LLM從輸入到輸出的“魔法”流程你總算搞清楚了吧?別再只是當個“AI用家”了,懂點門道,下次跟人聊AI也能硬氣地說:“生成文本?小意思,我連Transformer怎么跑都知道!”當然,這只是AI世界的入門課,想真正在這個領域站穩腳跟,還有更多硬核知識等著你去啃。怎么樣,敢不敢給LLM丟個復雜問題,測試一下你剛學的“理論”?
)
)

藍橋杯準備(需要寫的基礎))


)
)






)

并發部署DeepSeek-V3-0324模型)

 平滑處理的實現)
