一、介紹
KTransformers v0.2.4 發布說明
? ? ? 我們非常高興地宣布,期待已久的 KTransformers v0.2.4 現已正式發布!在這個版本中,我們對整 體架構進行了重大重構,更新了超過 1 萬行代碼,為社區帶來了備受期待的多并發支持。
本次重構借鑒了 sglang 的優秀架構,在 C++ 中實現了高性能的異步并發調度機制,支持如 連續批
處理 、 分塊預填充( chunked prefill ) 等特性。由于支持并發場景下的 GPU 資源共享,整體吞吐量也 在一定程度上得到了提升。
1. 多并發支持
? ? 新增對多個并發推理請求的處理能力,支持同時接收和執行多個任務。 我們基于高性能且靈活的算子庫 flashinfer 實現了自定義的 custom_flashinfer ,并實現了 可變 批大小( variable batch size ) 的 CUDA Graph ,這在提升靈活性的同時,減少了內存和 padding的開銷。 在我們的基準測試中,4 路并發下的整體吞吐量提升了約 130% 。 在英特爾的支持下,我們在最新的 Xeon6 + MRDIMM-8800 平臺上測試了 KTransformers v0.2.4。通過提高并發度,模型的總輸出吞吐量從 17 tokens/s 提升到了 40 tokens/s 。我們觀察到當前瓶頸已轉移至 GPU ,使用高于 4090D 的顯卡預計還可以進一步提升性能。
2. 引擎架構優化
? ? 借鑒 sglang 的調度框架,我們通過更新約 11,000 行代碼 ,將 KTransformers 重構為一個更清晰的 三層架構,并全面支持多并發:
Server (服務層) :處理用戶請求,并提供兼容 OpenAI 的 API 。
Inference Engine (推理引擎) :負責模型推理,支持分塊預填充。
Scheduler (調度器) :管理任務調度與請求編排。通過 FCFS (先來先服務)方式組織排隊請求, 打包為批次并發送至推理引擎,從而支持連續批處理。
3. 項目結構重組
? ? ?所有 C/C++ 代碼現已統一歸類至 /csrc 目錄下。
4. 參數調整
? ?我們移除了一些遺留和已棄用的啟動參數,簡化了配置流程。未來版本中,我們計劃提供完整的參數列表和詳細文檔,以便用戶更靈活地進行配置與調試。
二、安裝Ktransformers
1.下載docker鏡像與啟動
# 拉鏡像
docker pull approachingai/ktransformers:v0.2.4-AVX512# 啟動
docker run -it --gpus all --privileged --shm-size 64g --name kt --network=host -v /data:/data approachingai/ktransformers:v0.2.4-AVX512 /bin/bash# 打開一個新終端
docker exec -it kt bash2.通過魔搭社區下載模型
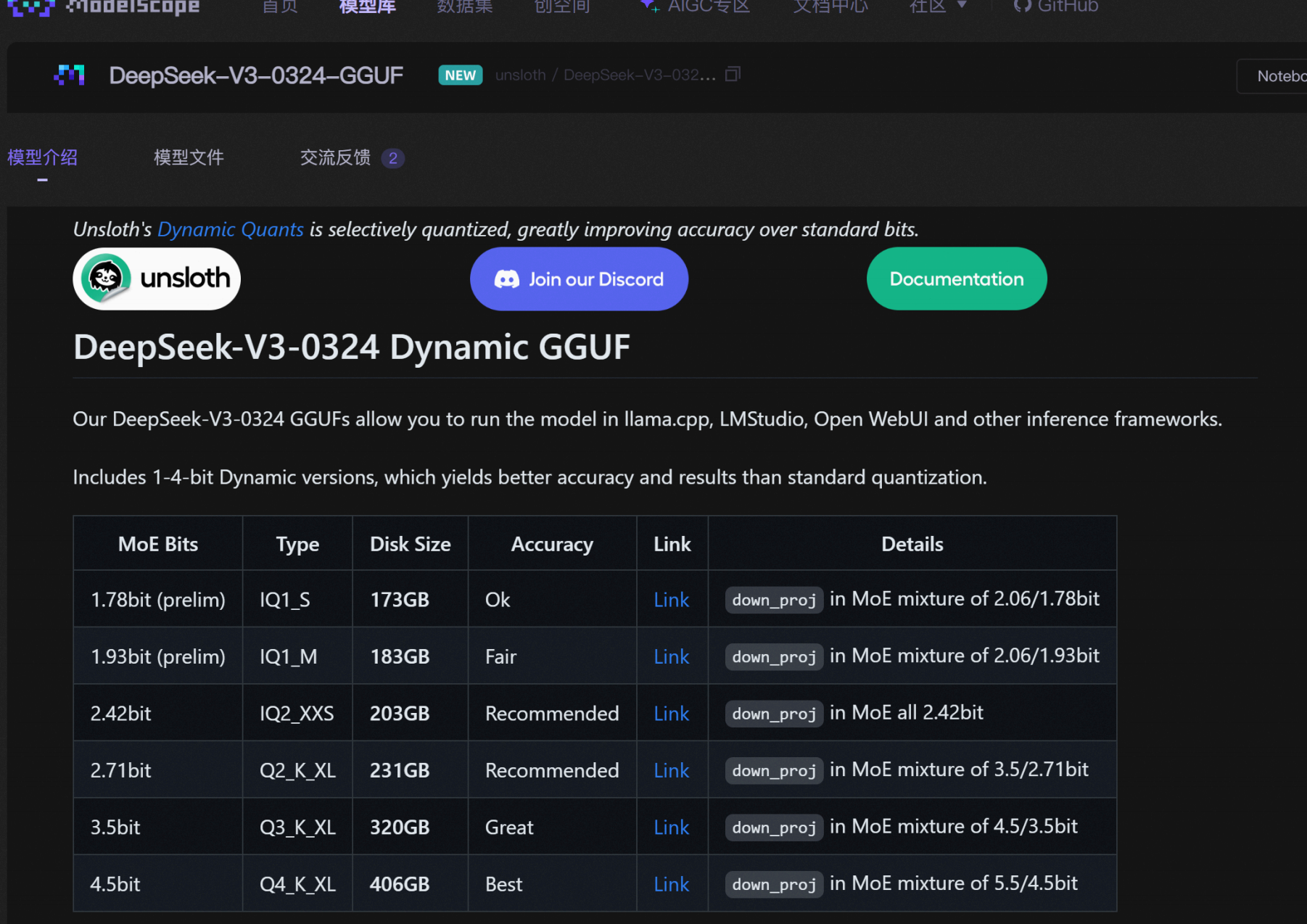
? ? ? ?本次實驗使用官方推薦的 DeepSeek-V3-0324 Q2_K_XL ( 1.58bit 模型目前不太穩定)模型,該模型也是目前最穩定的動態量化模型,需要14G 顯存 +170G 內存即可調用。
? ? ? 魔搭社區下載地址: https://www.modelscope.cn/models/unsloth/DeepSeek-V3-0324-GGUF/su
mmary
mkdir ./DeepSeek-V3-0324-GGUF# 下載模型
modelscope download --model unsloth/DeepSeek-V3-0324-GGUF --include
'**Q2_K_XL**' --local_dir /data/model/DeepSeek-V3-0324-GGUF/mkdir ./DeepSeek-V3-0324# 下載模型配置文件
modelscope download --model deepseek-ai/DeepSeek-V3-0324 --exclude
'*.safetensors' --local_dir /data/model/DeepSeek-V3-0324/三、利用Ktransformers啟動模型
? ? ? ? ?在安裝完成了 KTransformer v0.24 ,并下載好了模型權重和相應的模型配置之后,接下來即可嘗試進行調用了。KTransformer v0.24 支持兩種調用方法,分別借助 local_chat.py 進行命令行本地對話,以及實用 server/main.py 開啟服務,然后在默認 10002 端口進行 OpenAI 風格的 API 調用。這里我們重點嘗試使用后端服務模式調用DeepSeek 模型。
# 進去docker容器
docker exec -it kt /bin/bash# 啟動模型
python ktransformers/server/main.py \
--port 10002 \
--model_path /data/model/DeepSeek-V3-0324 \
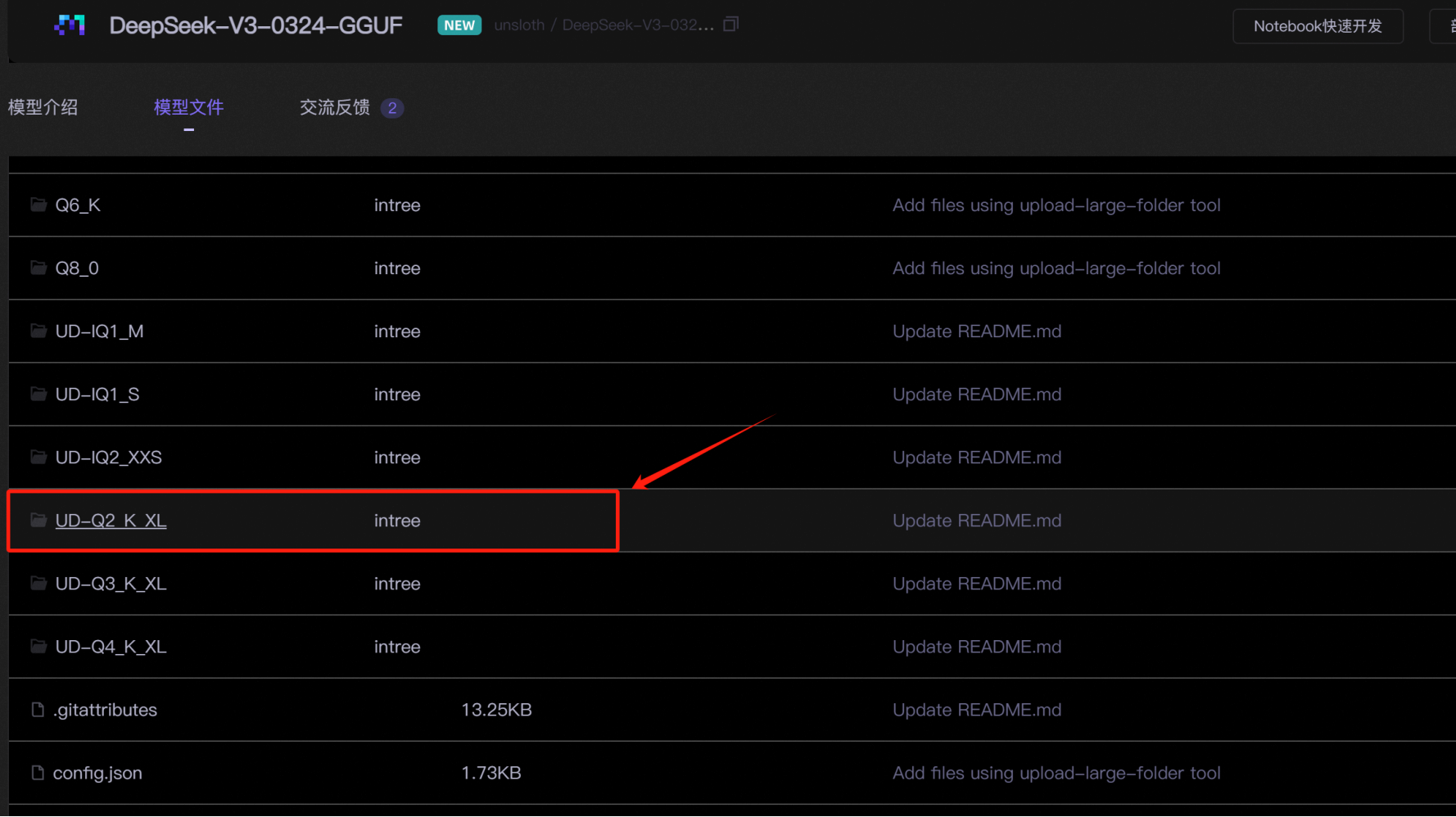
--gguf_path /data/model/DeepSeek-V3-0324-GGUF/UD-Q2_K_XL \
--max_new_tokens 1024 \
--cache_lens 32768 \
--chunk_size 256 \
--max_batch_size 4 \
--backend_type balance_serve
四、客戶端調用
1. linux curl調用
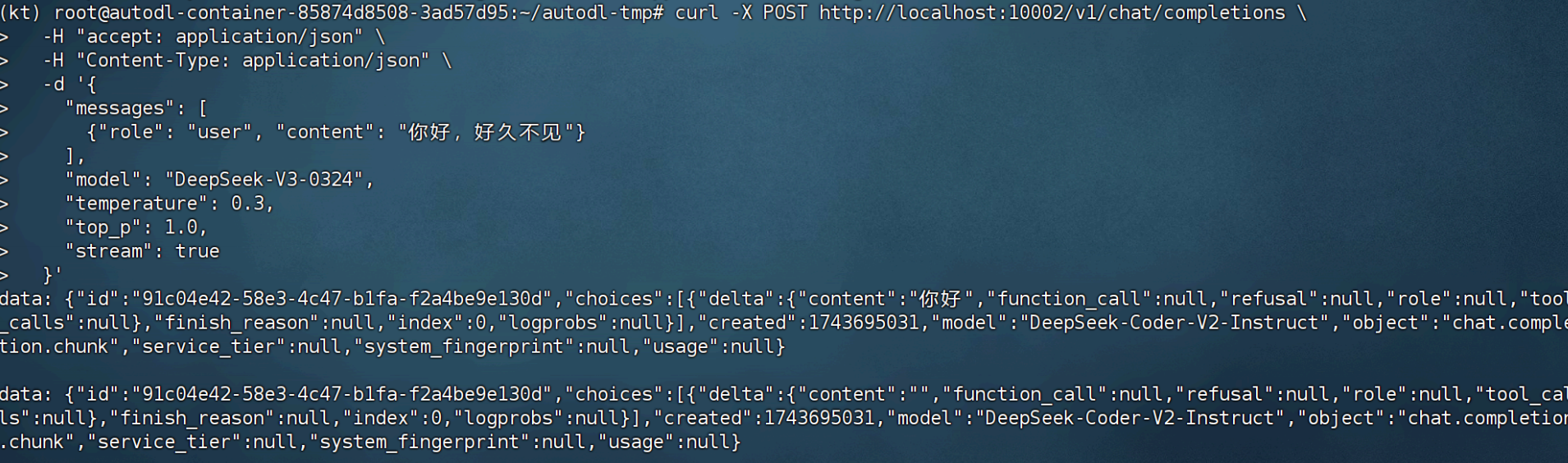
curl -X POST http://localhost:10002/v1/chat/completions \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": "你好,好久不見"}
],
"model": "DeepSeek-V3-0324",
"temperature": 0.3,
"top_p": 1.0,
"stream": true
}'?
2.代碼調用
from openai import OpenAI# 實例化客戶端
client = OpenAI(api_key="None",
base_url="http://localhost:10002/v1")# 調用 deepseekv3 模型
response = client.chat.completions.create(
model="DeepSeek-V3-0324",
messages=[
{"role": "user", "content": "你好,好久不見!"}
]
)# 輸出生成的響應內容
print(response.choices[0].message.content)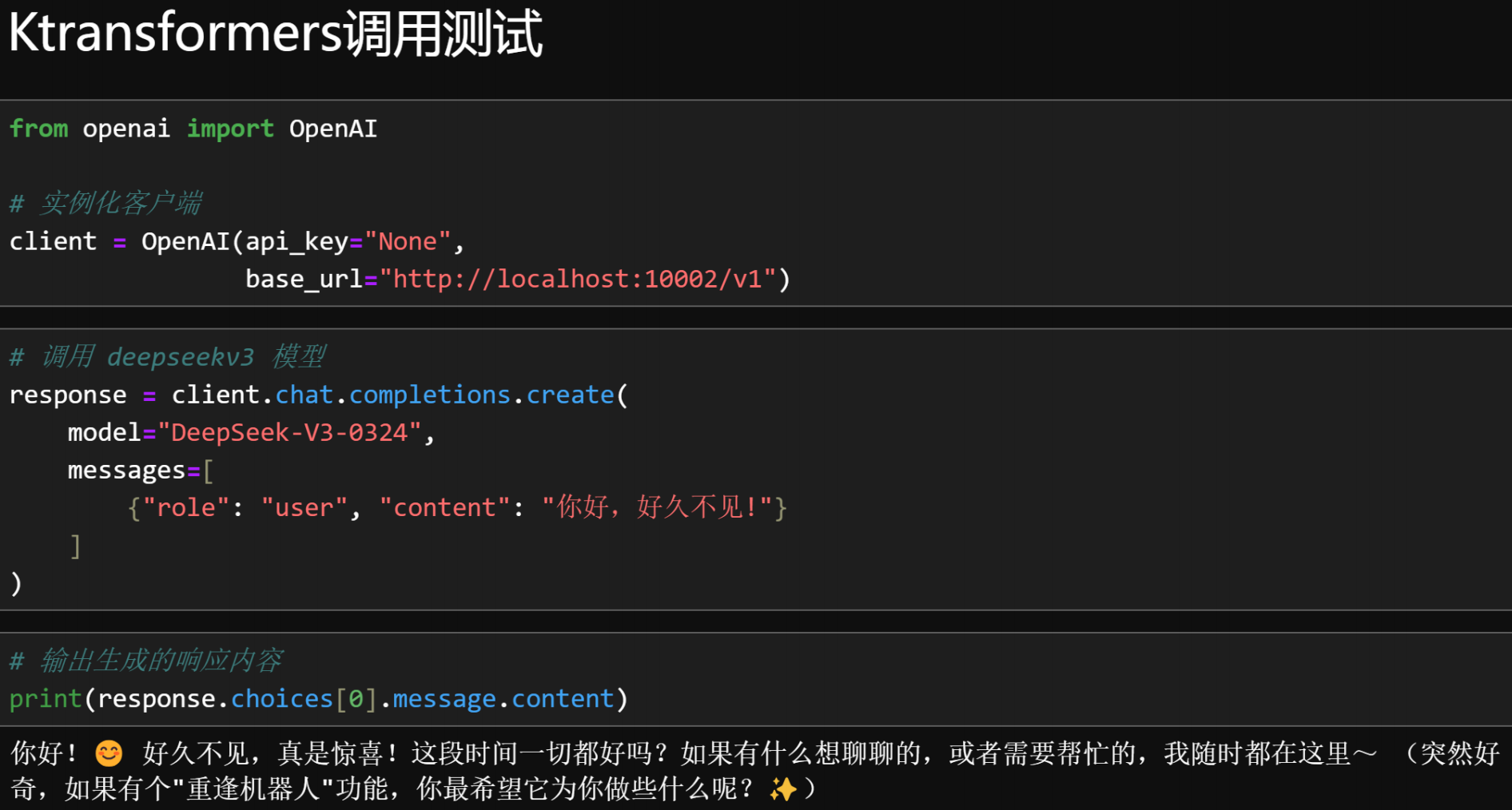

 平滑處理的實現)





)
)


(字符串))







