AIGCmagic社區知識星球是國內首個以AIGC全棧技術與商業變現為主線的學習交流平臺,涉及AI繪畫、AI視頻、大模型、AI多模態、數字人以及全行業AIGC賦能等100+應用方向。星球內部包含海量學習資源、專業問答、前沿資訊、內推招聘、AI課程、AIGC模型、AIGC數據集和源碼等干貨。
 ?
?
截至目前,星球內已經累積了2000+AICG時代的前沿技術、干貨資源以及學習資源;涵蓋了600+AIGC行業商業變現的落地實操與精華報告;完整構建了以AI繪畫、AI視頻、大模型、AI多模態以及數字人為核心的AIGC時代五大技術方向架構,其中包含近500萬字完整的AIGC學習資源與實踐經驗。
論文題目:《OmniCaptioner: One Captioner to Rule Them All》
發表時間:2025年4月
論文地址:[2504.07089] OmniCaptioner: One Captioner to Rule Them All
本文作者:AIGCmagic社區 劉一手
一句話總結:OmniCaptioner是一個多功能的視覺描述框架,能夠為多種視覺領域生成細粒度的文本描述,顯著提升視覺推理、圖像生成和下游監督微調的效率。
研究背景
(1)研究問題??:這篇文章要解決的問題是如何生成細粒度的文本描述,以覆蓋廣泛的視覺領域。現有的方法通常局限于特定類型的圖像(如自然圖像或幾何圖像),而本文提出的OMNICAPTIONER框架旨在為自然圖像、視覺文本圖像(如海報、用戶界面、教科書)和結構化視覺(如文檔、表格、圖表)提供統一的解決方案。
??(2)研究難點??:該問題的研究難點包括:如何在不同視覺領域之間進行有效的跨模態推理,如何將低層次的像素信息轉換為語義豐富的文本表示,以及如何在監督微調(SFT)過程中實現更快的收斂和更少的數據需求。
??(3)相關工作??:該問題的研究相關工作有:圖像描述生成、多模態大型語言模型(MLLMs)的預訓練和微調、特定領域的MLLMs(如文檔理解和數學MLLMs)。這些工作主要集中在特定領域的圖像描述生成和多模態預訓練,但缺乏一個統一的框架來處理多樣化的視覺內容。
研究方法
論文提出了OMNICAPTIONER框架,用于解決跨視覺領域生成細粒度文本描述的問題。具體來說:
(1)??多樣化視覺描述數據集??:首先,構建了一個多樣化的描述數據集,涵蓋自然圖像、結構化圖像、視覺文本圖像和視頻。數據集的多樣性體現在領域多樣性和描述公式多樣性兩個方面。
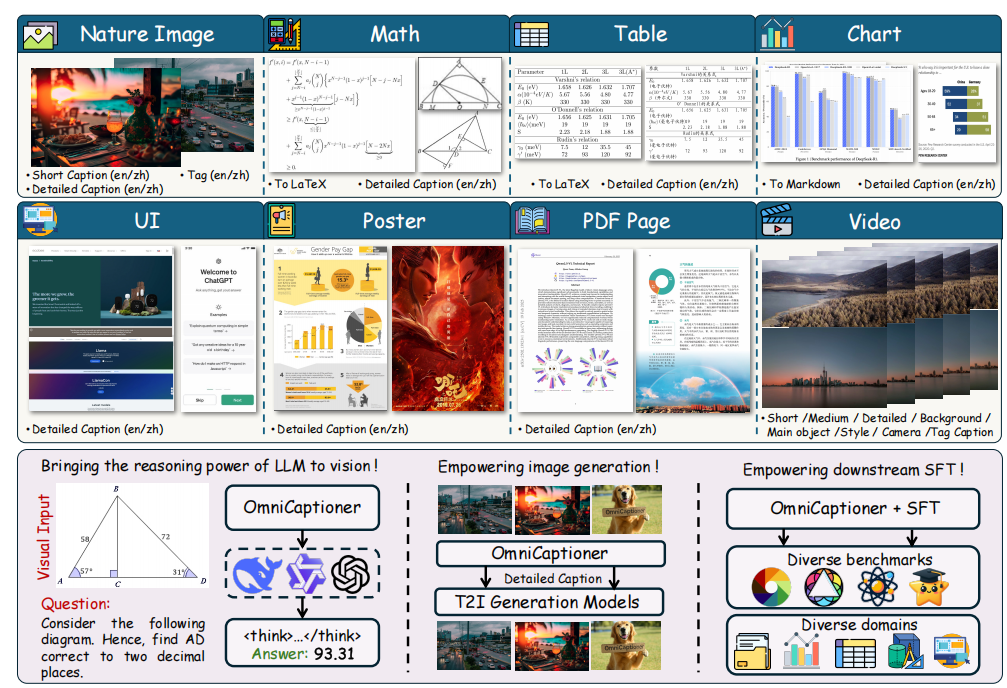
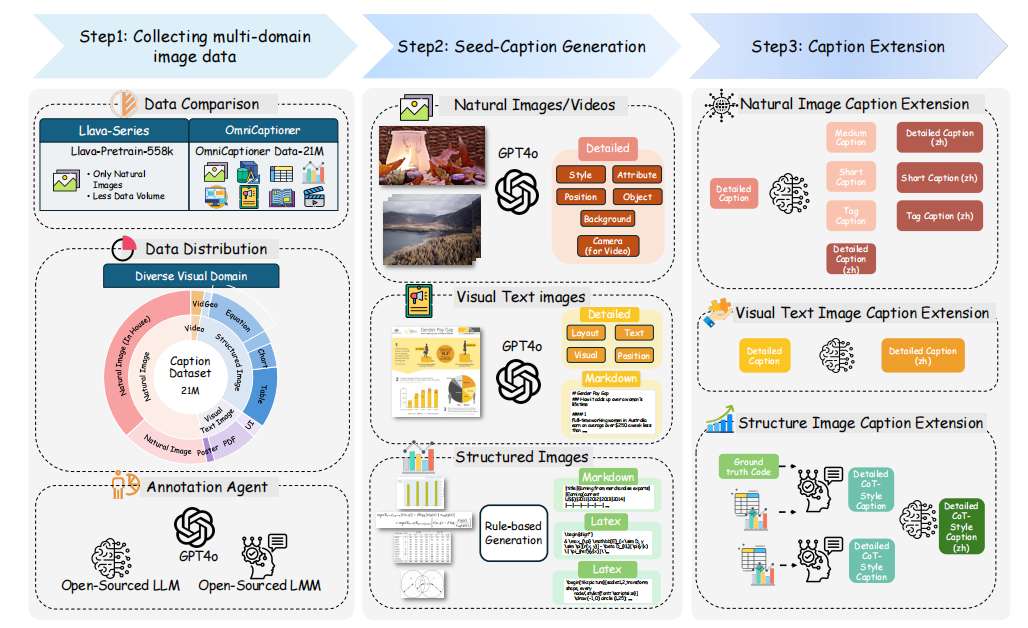
?(2)描述???????生成流程:提出了一個兩步描述生成管道,包括種子描述生成和描述擴展。種子描述生成階段利用強大的閉源多模態模型GPT-4o生成初始描述,確保準確的像素到詞的映射。描述擴展階段則引入風格變化和領域特定的推理知識,生成多樣化和上下文適當的描述。
??(3)統一預訓練過程??:為了有效處理OMNICAPTIONER數據集的多域特性,采用了不同的系統提示來最小化任務沖突并提高任務協調。通過為特定圖像類別定制系統提示和使用固定的問題模板,區分了預訓練過程中的任務和數據類型。

實驗設計
(1)視覺推理任務??:在視覺推理任務中,使用詳細的描述和相應的問題評估LLM的回答能力。選擇了五個基準數據集:MME、Mathverse、Mathvision、MMMU和Olympiad bench。使用的LLMs包括Qwen2.5-3B-Instruct、Qwen2.5-7B-Instruct、Qwen2.5-32B-Instruct、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Qwen-32B和DeepSeek-R1-Distill-LLaMA-70B。
??(2)SFT效率評估??:評估SFT過程的效率,選擇LLaVA-OneVision數據集進行評估。比較了OMNICAPTIONER和Qwen2-VL-Base+OV SFT在不同常用基準上的性能。
??(3)文本到圖像生成任務??:微調文本到圖像生成模型(如SANA-1.0-1.6B),使用不同描述生成器生成的圖像描述對進行訓練。訓練設置使用1024 x 1024的分辨率,并在GenEval基準上評估模型的生成性能。
實驗結果
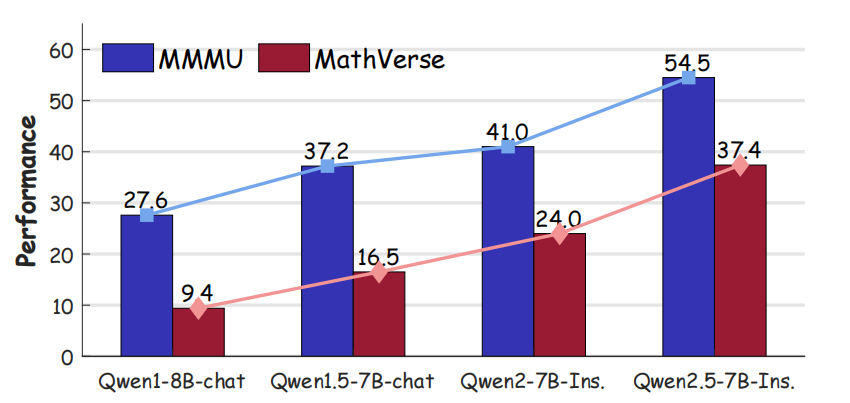
(1)視覺推理任務??:實驗結果表明,將描述集成到增強推理能力的LLMs中,無需額外微調即可在多個推理基準上達到最先進的性能。OMNICAPTIONER插入的LLMs在MathVision等多個模型大小上顯著優于現有模型,特別是在復雜的視覺和數學任務中。
(2)文本到圖像生成任務??:在GenEval基準上,OMNICAPTIONER模型顯著提高了文本到圖像生成的性能。與Qwen2-VL-Instruct相比,OMNICAPTIONER在顏色屬性、正對象、位置、顏色和計數等方面的得分均有提升。

(3)??SFT效率??:OMNICAPTIONER在SFT過程中表現出色,使用較少的SFT樣本即可達到與大規模SFT方法相當的性能。OMNICAPTIONER+OV SFT在多個評估基準上的表現優于Qwen2-VL-Base+OV SFT,表明OMNICAPTIONER在視覺感知方面的優越性。

論文結論
本文提出了OMNICAPTIONER框架,通過細粒度的像素到文本映射,實現了跨多樣化領域的視覺和文本模態的橋接。該方法增強了增強推理能力的LLMs的視覺推理能力,并通過全面的語義保留實現了精確的文本到圖像生成。OMNICAPTIONER開創了一個可擴展的多模態對齊和推理范式,實現了無縫的視覺語言互操作性,而無需昂貴的標簽監督微調。
論文腦圖
Omni-Captioner創新點總結
(1)統一的視覺描述???????框架??:OMNICAPTIONER提出了一個統一的框架,用于生成跨不同領域的描述,包括自然圖像、視覺文本圖像和結構化圖像。這種方法為更有效的廣義視覺描述設定了新的標準,使視覺-語言理解更加有效和可擴展。
??(2)全面的像素到文本轉換??:該框架利用詳細的描述將低層像素信息轉換為語義豐富的詳細文本描述,有效地彌合了視覺和文本模態之間的差距。特別是,這增強了文本到圖像生成的能力,通過提供更精確和上下文感知的文本指導,提高了視覺保真度和與預期語義的對齊。
??(3)增強的視覺推理能力??:通過整合詳細的長上下文描述,OMNICAPTIONER方法增強了視覺推理能力,特別是當集成到像DeepSeek-R1系列這樣的LLMs中時。利用OMNICAPTIONER提供的感知信息,LLMs可以在文本空間中進行推理和解決問題。
(4)??高效的監督微調(SFT)過程??:利用OMNICAPTIONER進行預訓練的知識,SFT過程變得更加高效,需要更少的數據并實現更快的收斂。
??(5)多樣化的視覺領域覆蓋??:OMNICAPTIONER的框架支持多樣化的視覺內容,包括自然圖像、視覺文本圖像(如海報、UI和教科書)和結構化圖像(如表格、圖表、方程和幾何圖)。
Omni-Captioner關鍵問題解答
??問題1:OMNICAPTIONER框架在構建多樣化視覺描述???????數據集方面有哪些具體的措施???
OMNICAPTIONER框架通過兩個主要措施來構建多樣化的視覺描述數據集:領域多樣性和描述公式多樣性。
??(1)領域多樣性??:數據集涵蓋了自然圖像、結構化圖像、視覺文本圖像和視頻。具體來源包括內部收藏、BLIP3Kale、DenseFusion、arXiv網站、開源的MMTab數據集、TinyChart、MAVIS和AutoGeo等。
(2)??描述???????公式多樣性??:對于同一視覺輸入,可能需要不同類型的描述。OMNICAPTIONER定義了多種描述格式,包括多語言(中文和英文)描述、不同粒度級別(從詳細到簡潔)和標簽式描述。例如,對于自然圖像,使用Qwen2.5-32B模型通過不同提示調整描述長度;對于視覺文本圖像,使用Qwen2.5-32B模型將詳細描述翻譯成中文;對于結構化圖像,優先保證種子描述的準確性,然后輸入到Qwen2-VL-76B模型進行鏈式思維(CoT)風格的描述生成。
??問題2:OMNICAPTIONER框架的兩步描述???????生成管道具體是如何設計的???
OMNICAPTIONER框架的兩步描述生成管道包括以下兩個階段:
??(1)種子描述???????生成??:在這個階段,目標是生成一個盡可能準確的初始描述,涵蓋圖像中所有相關的視覺元素。該階段利用強大的閉源多模態模型GPT-4o,通過精心設計的提示引導其描述自然圖像和視覺文本圖像中的所有可能視覺元素,確保準確的像素到詞映射。對于通過代碼生成的結構化圖像,使用預定義的代碼規則生成描述。生成的種子描述作為后續細化階段的基礎。
??(2)描述???????擴展??:在這個階段,重點是增強和多樣化生成的描述。通過引入雙語輸出(中文和英文)、不同長度(從詳細到簡短和標簽式)以及注入與特定領域相關的推理知識,豐富描述的語義深度。例如,對于自然圖像,使用Qwen2.5-32B模型通過不同提示調整描述長度;對于視覺文本圖像,使用Qwen2.5-32B模型將詳細描述翻譯成中文;對于結構化圖像,優先保證種子描述的準確性,然后輸入到Qwen2-VL-76B模型進行鏈式思維(CoT)風格的描述生成。
??問題3:OMNICAPTIONER框架在視覺推理任務中的表現如何?與其他模型相比有哪些優勢???
OMNICAPTIONER框架在視覺推理任務中表現出色,具體優勢如下:
??(1)無需額外微調即可達到先進性能??:將描述集成到增強推理能力的LLMs(如DeepSeek-R1系列)中,無需額外的微調即可在多個推理基準(如MathVision、MathVerse、MMMU和Olympiad bench)上達到最先進的性能。
??(2)顯著優于現有模型??:OMNICAPTIONER插入的LLMs在多個模型大小上顯著優于現有模型,特別是在復雜的視覺和數學任務中。例如,在MathVision基準上,OMNICAPTIONER+DS-R1-Distill-Qwen-7B和OMNICAPTIONER+DS-Distill-Qwen-32B分別達到了36.2和40.5的準確率,顯著高于其他模型。
??(3)增強的推理能力??:通過詳細的描述,OMNICAPTIONER框架使LLMs能夠在文本空間中進行視覺推理,包括幾何問題求解和空間分析,而無需直接的像素級感知。這種解耦感知和推理的方法避免了兩種能力之間的沖突,提高了推理的準確性和有效性。
推薦閱讀
AIGCmagic社區介紹:
2025年《AIGCmagic社區知識星球》五大AIGC方向全新升級!
AI多模態核心架構五部曲:
AI多模態模型架構之模態編碼器:圖像編碼、音頻編碼、視頻編碼
AI多模態模型架構之輸入投影器:LP、MLP和Cross-Attention
AI多模態模型架構之LLM主干(1):ChatGLM系列
AI多模態模型架構之LLM主干(2):Qwen系列
AI多模態模型架構之LLM主干(3):Llama系列 ?
AI多模態模型架構之模態生成器:Modality Generator
AI多模態實戰教程:
AI多模態教程:從0到1搭建VisualGLM圖文大模型案例
AI多模態教程:Mini-InternVL1.5多模態大模型實踐指南
AI多模態教程:Qwen-VL升級版多模態大模型實踐指南
AI多模態實戰教程:面壁智能MiniCPM-V多模態大模型問答交互、llama.cpp模型量化和推理
交流社群
加入「AIGCmagic社區」,一起交流討論:
AI視頻、AI繪畫、數字人、多模態、大模型、傳統深度學習、自動駕駛等多個不同方向;
可私信或添加微信號:【lzz9527288】,備注不同方向邀請入群;
更多精彩內容,盡在「AIGCmagic社區」,關注了解全棧式AIGC內容!


)




:行業融資全景剖析與代碼應用拓展)






—無重復字符的最長子串)



![大模型本地部署系列(3) Ollama部署QwQ[阿里云通義千問]](http://pic.xiahunao.cn/大模型本地部署系列(3) Ollama部署QwQ[阿里云通義千問])
