大家好,我是AI研究者, 今天教大家部署 一個阿里云通義千問大模型。
QwQ大模型簡介
QwQ是由阿里云通義千問(Qwen)團隊推出的開源推理大模型,專注于提升AI在數學、編程和復雜邏輯推理方面的能力。其核心特點包括:
-
深度自省能力
-
能夠主動質疑自身假設,進行多輪自我反思,優化推理過程,類似于人類的深度思考模式16。
-
在解決“猜牌問題”等復雜邏輯推理任務時,展現出類似人類的逐步分析能力9。
-
-
對標OpenAI o1模型
-
在MATH-500評測中達到90.6%的準確率,超越OpenAI的o1-preview和o1-mini模型17。
-
在編程任務(LiveCodeBench)和研究生級科學推理(GPQA)測試中表現優異7。
-
-
高效架構設計
-
采用動態推理路徑,根據問題復雜度調整計算深度,提高效率1。
-
僅325億參數(QwQ-32B-Preview),在較小規模下實現高性能推理8。
-
-
開源與易用性
-
阿里云首個開源AI推理模型,支持本地部署及二次開發,適用于科研、教育、編程輔助等場景36。
-
-
當前局限性
-
語言切換時可能出現表達不連貫7。
-
復雜邏輯推理時可能陷入循環思考9。
-
QwQ的推出標志著國產大模型在推理能力上的重要突破,尤其在數學和編程領域展現出接近研究生水平的分析能力。
部署步驟
首先需要安裝ollama,這個在我之前的文章已經講到了,這里就不在贅述。
我們進入到ollama的官網:
https://ollama.com/
找到上方的Models ,然后點擊

此時會跳轉到模型列表頁面:
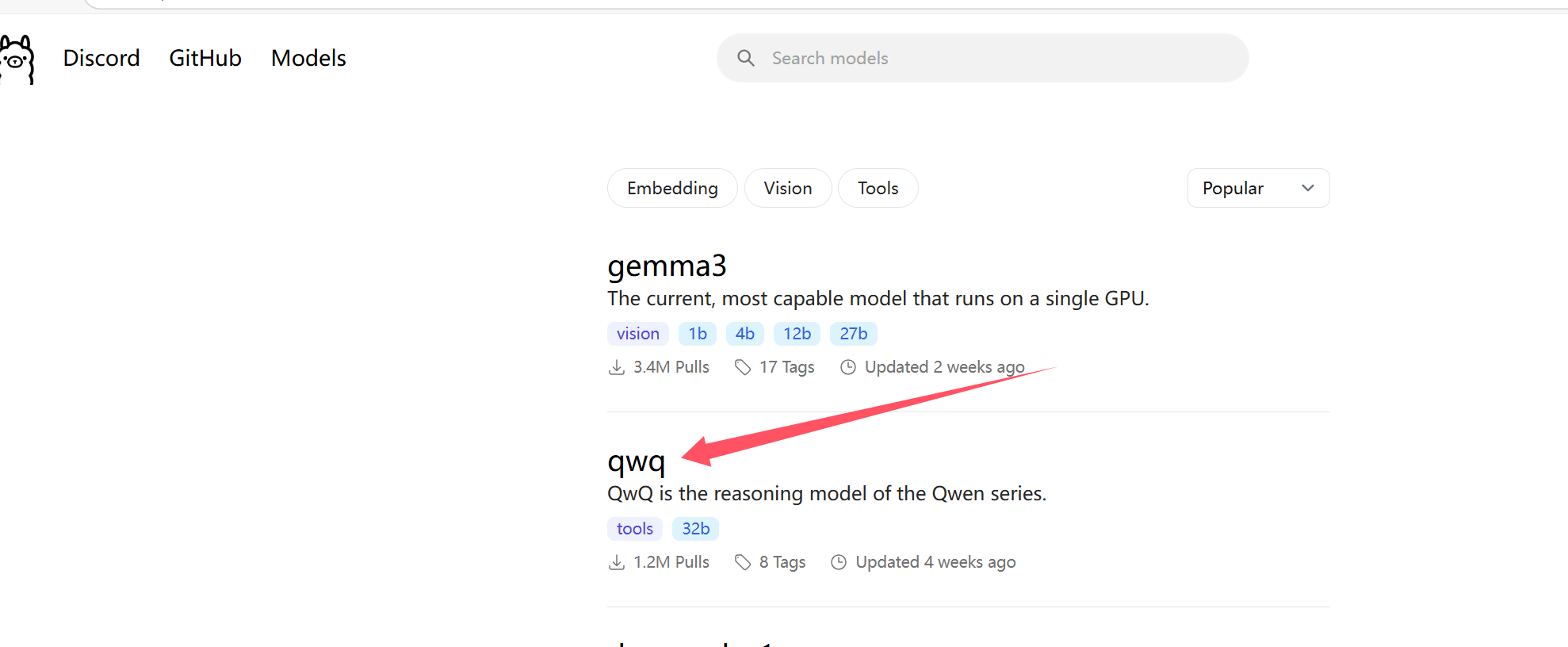
點擊?qwq 鏈接進去,此時我們會看到下拉框中有各個版本的大模型,如下圖所示:
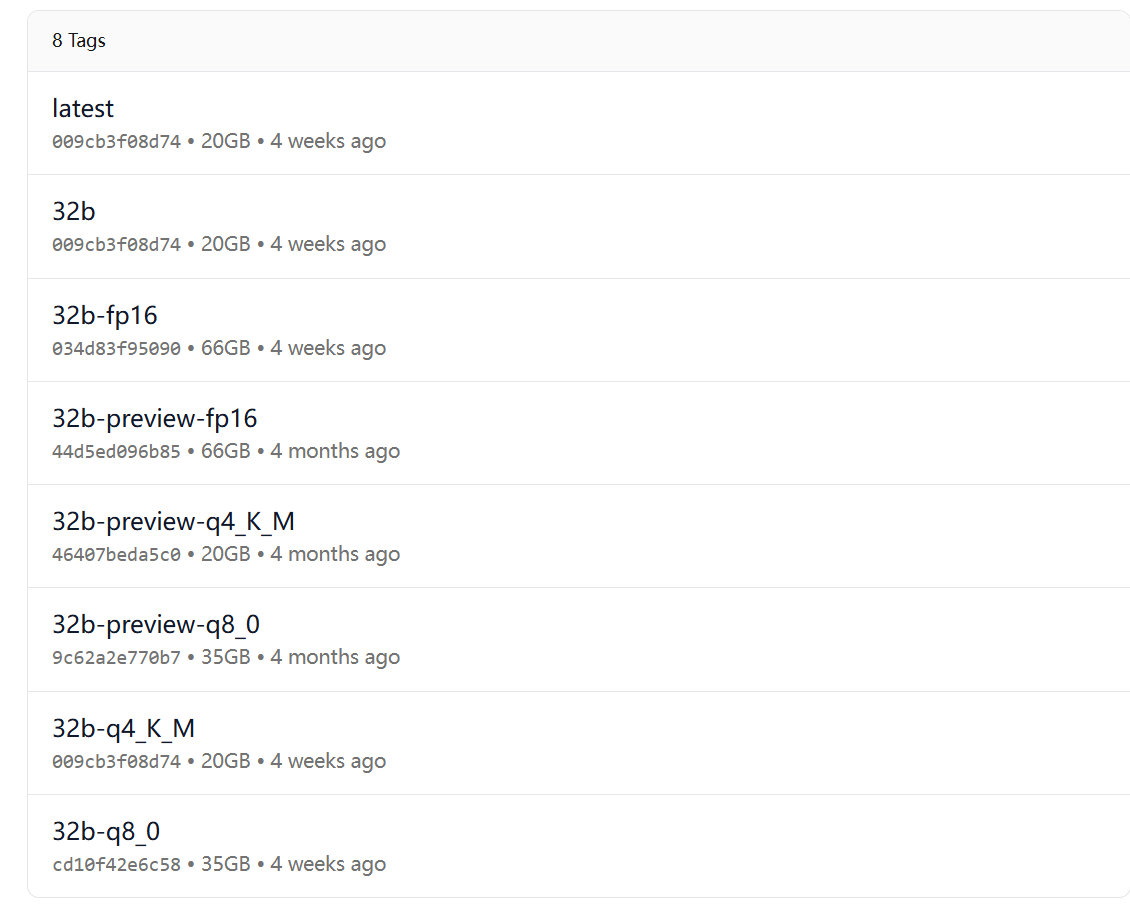
模型參數(1.5B、7B、8B等)是什么意思?
這些數字代表模型的?參數量(比如1.5B=15億,7B=70億),你可以簡單理解為模型的“腦細胞數量”:
- 參數越多?→ 模型越聰明(能處理復雜任務,比如寫代碼、邏輯推理),但需要的計算資源也越多。
- 參數越少?→ 模型更輕量(反應快、適合簡單任務),但對復雜問題可能表現一般。
舉個例子:
- 1.5B 模型 ≈ 一個“高中生”水平(能聊天、寫短文)。
- 7B 模型 ≈ “大學生”水平(能寫代碼、分析問題)。
- 70B 模型 ≈ “教授”水平(專業級回答,但需要頂級顯卡)。
K_M , fp 是什么意思?
q4_K_M, q8_0, fp16 這些指的是模型精度。這里的 q4 指的是 4bit 量化,q8 指的是 8bit 量化,fp16 就是原版模型。
因為量化都是有損的,只要把握數字越小,模型體積越小,所以模型能力會更弱這個邏輯就行。所以 q4 就是 QwQ32b 家族中,體積最小,性能有可能是最弱的那個(不排除 8bit 量化也都差不多的效果)。
我們部署就選用 32b-q4_K_M,選用它的原因很簡單, 體積小。耗能低。
?
?點進?32b-q4_K_M , 找到右邊的復制 安裝命令:
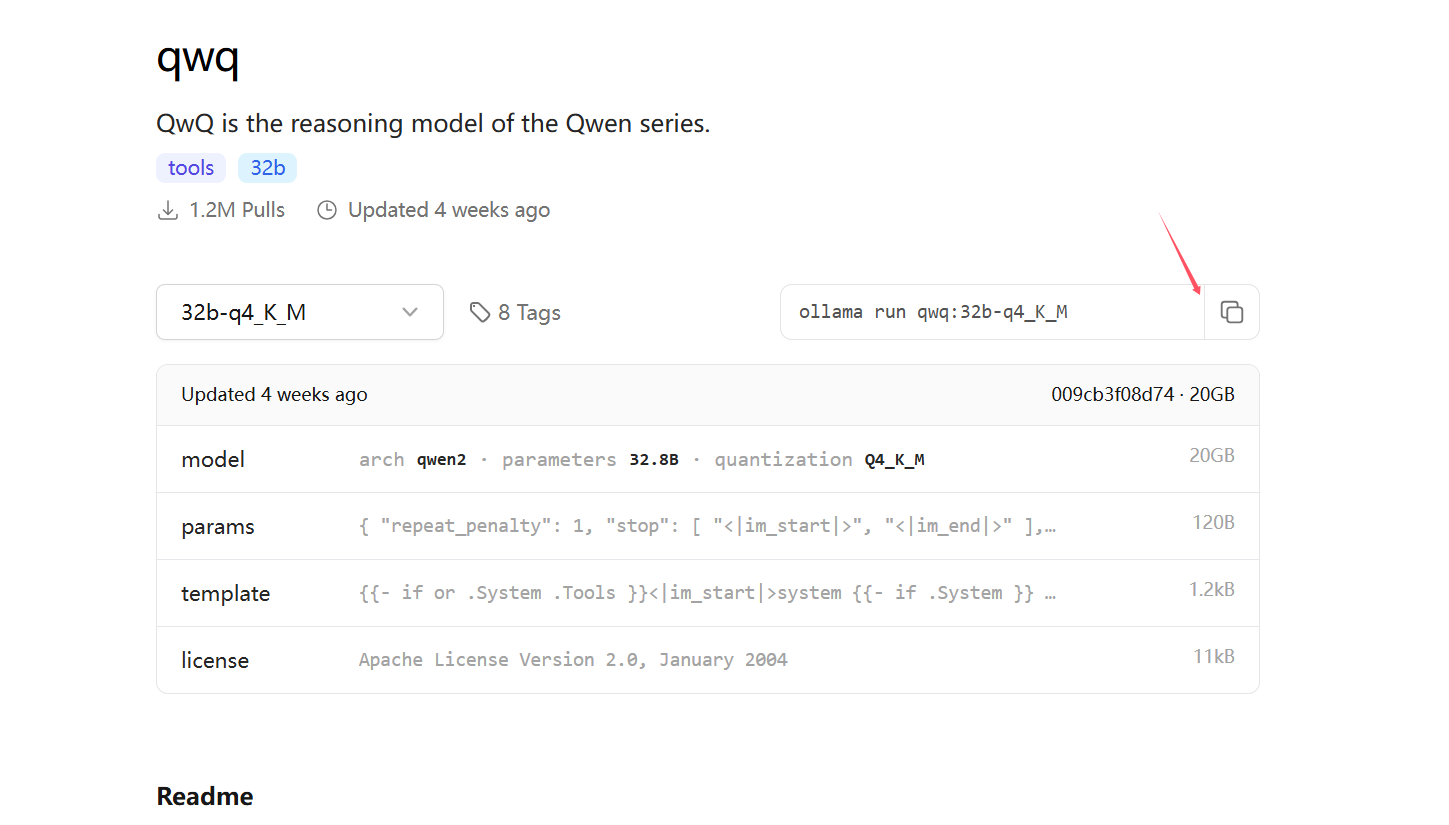
打開cmd, 粘貼上面復制的命令, 等待下載。

等了很久,如果出現了 “unable to allocate CUDA0 buffer” , 表示你的GPU內存不足。

然后運行 “nvidia-smi”, 查看 占用GPU的進程,然后全部關掉。

然后重新運行命令, 還是不行的話,就是機器跟不上了!
如果成功了,默認是運行了模型,直接可以在cmd輸入命令對話, 如果關掉了,下次運行就要輸入 運行模型命令:
ollama run 模型名稱

續航與散熱)



)





)



)



