文章目錄
- 速覽
- 摘要
- 1. 引言
- 2. 相關工作
- 2.1. 大模型中的推理能力
- 2.2. 結合推理的語義分割
- 2.3. 用于分割任務的 MLLMs
- 3. 方法
- 3.1. 流程建模(Pipeline Formulation)
- 3.2. Seg-Zero 模型
- 3.3. 獎勵函數(Reward Functions)
- 3.4. 訓練(Training)
- 4. 實驗
- 4.1. 實驗設置(Experimental Settings)
- 4.2. SFT 與 RL 的對比
- 4.3. 消融實驗(Ablation Study)
- 4.4. 與其他方法的比較(Comparison with Other Methods)
- 4.5. 定性結果(Qualitative Results)
- 5. 結論(Conclusion)
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
中國香港中文大學;香港科技大學;中國人民大學
arxiv’25’03
項目地址:https://github.com/dvlab-research/Seg-Zero
速覽
動機
傳統的推理分割方法依賴于使用類別標簽和簡單描述進行的有監督微調,這限制了其跨領域的泛化能力,并且缺乏顯式的推理過程。
方法
提出了一個新框架 Seg-Zero,Seg表示分割,Zero表示零樣本,這個框架有很強的泛化能力和顯示推理過程,并且為解耦式,分為了推理模型( Qwen2.5-VL-3B)和分割模型(SAM2-Large)。
- 推理模型這里使用GRPO進行訓練,設計了幾個獎勵函數,都挺簡單的,分別是格式獎勵和IoU獎勵,不過他引入了一些軟硬獎勵、軟嚴格格式獎勵的說法,后面可以學一下
- 分割模型直接使用凍結的,沒有做任何處理
測試時就是先用推理模型推理出邊界框和關鍵點,然后作為提示給分割模型,分割模型給出像素級的掩碼。
實驗
實驗這里首先對比了一下使用SFT和RL,然后有一堆消融實驗,最后是和其他方法的比較,看起來性能也沒比別人高多少呢。
摘要
傳統的推理分割方法依賴于使用類別標簽和簡單描述進行的有監督微調,這限制了其跨領域的泛化能力,并且缺乏顯式的推理過程。為了解決這些問題,我們提出 Seg-Zero,這是一個新穎的框架,能夠展現出顯著的泛化能力,并通過認知強化學習推導出顯式的 chain-of-thought 推理過程。Seg-Zero 引入了一個解耦的架構,由一個推理模型和一個分割模型組成。
推理模型負責理解用戶意圖,生成顯式的推理鏈,并產生位置提示,這些提示隨后由分割模型用于生成精確的像素級掩碼。我們設計了一套復雜的獎勵機制,將格式獎勵和準確性獎勵結合,以有效引導優化方向。Seg-Zero 完全通過使用 GRPO 的強化學習方式進行訓練,且不依賴任何顯式推理數據,從而實現了穩健的零樣本泛化能力,并在測試時展現出涌現的推理能力。
實驗表明,Seg-Zero-7B 在 ReasonSeg 基準測試中實現了 57.5 的零樣本性能,超過了此前的 LISA-7B 模型 18%。這一顯著提升突顯了 Seg-Zero 在呈現顯式推理過程的同時具備跨領域泛化的能力。代碼地址如下:
https://github.com/dvlab-research/Seg-Zero
1. 引言
推理分割通過邏輯推理來解釋隱含查詢,從而生成像素級的掩碼。這項任務在現實應用中具有重要潛力,例如在機器人領域。與依賴簡單類別標簽(如 “person” 或 “car”)的傳統分割任務不同,推理分割應對的是更復雜且更細致的查詢,例如“識別能提供持續能量的食物”。這類查詢需要邏輯推理,并整合跨領域知識以生成準確的分割掩碼。
早期的嘗試(如 [3, 17, 32]),例如 LISA [17],探索了利用多模態大語言模型(MLLMs)來增強推理分割能力的方法。這些方法通過利用隱式語義標記,彌合了 MLLMs 與分割模型之間的差距。然而,典型的方法(如 [7, 17, 32])完全依賴于對包含簡單類別信息或基礎事實描述的混合數據集進行的有監督微調(SFT)[12, 13, 43]。盡管該范式能夠在特定數據集上有效地將 MLLMs [23, 24, 40] 與分割模型 [14] 對齊,我們觀察到它缺乏泛化能力。這可以通過以下現象說明:
(i) 盡管現有方法在領域內數據上表現優異,但在分布外(OOD)樣本上的性能顯著下降。
(ii) SFT 不可避免地導致模型對通用能力的災難性遺忘。
(iii) 缺乏顯式推理過程使得模型在復雜場景下的表現受限。
這些局限促使我們通過引入顯式推理過程來增強模型的通用分割能力和推理表現。
近期研究 [11] 表明,純強化學習(RL)訓練能夠激活測試時涌現的推理過程,這說明基于獎勵的優化在提升模型推理能力方面是有效的。此外,這種方法往往能夠提升泛化能力,而不是對特定數據集過擬合。 受此啟發,我們提出 Seg-Zero,這是一個旨在增強推理能力和認知能力的推理分割新框架。
Seg-Zero 采用了解耦架構,包括一個推理模型和一個分割模型。推理模型是一個能夠處理圖像和用戶指令的 MLLM。它不僅輸出區域級別的邊界框(bbox),還輸出像素級別的點,以精確地定位目標對象。隨后,分割模型利用這些 bbox 和點來生成像素級分割掩碼。
在訓練過程中,我們采用純強化學習方法,具體地說是 GRPO [34],用于微調推理模型,同時保持分割模型的參數凍結。我們沒有構建帶有顯式推理標注的數據集,而是探索 MLLM 自我進化的潛力,使其具備推理能力,從而從零開始實現涌現式推理。
為此,我們設計了一套復雜的獎勵機制,用于增強推理過程并規范輸出。這些獎勵函數分為兩類:
- 格式獎勵(format rewards),用于對推理過程和分割輸出的結構施加約束;
- 準確性獎勵(accuracy rewards),基于交并比(IoU)和 L1 距離指標計算。
如圖 1 所示,通過強化學習中優化后的獎勵機制,我們的 Seg-Zero 展現出測試階段的涌現式推理能力,與 LLMs 中展示的推理能力相似 [11, 27]。這種推理過程使模型能夠有效地處理復雜指令,將其分解為一系列順序的分析步驟,從而實現對目標對象的精確定位。
Seg-Zero 在領域內和 OOD 數據上均表現出卓越的性能,顯著超過通過 SFT 訓練的模型。此外,Seg-Zero 還能保持穩健的視覺問答能力,而無需任何 VQA 訓練數據。

實驗結果表明,僅使用來自 RefCOCOg [43] 的 9000 個訓練樣本,我們的 Seg-Zero-7B 就能展現出強大的測試時推理能力,并在同規模模型中實現更優的泛化性能。在 ReasonSeg [17] 基準上實現了 57.5 的 zero-shot 性能,相較于此前的 LISA-7B 提升了 18%。
我們的貢獻總結如下:
- 我們提出 Seg-Zero,這是一個為推理分割任務設計的新型架構。通過純 RL 算法,Seg-Zero 展現出涌現式的推理能力。
- 我們呈現了對比 SFT 與 RL 的詳細實驗,并引入推理鏈。結果表明 RL 結合推理鏈能夠持續提升模型性能。
- 大量實驗驗證了我們設計的有效性,并為基于 RL 的模型微調提供了有價值的參考。
250401:后面說,他這個推理鏈就是由RL訓練后的大模型生成的推理過程,我還以為有什么新的設計呢。
2. 相關工作
2.1. 大模型中的推理能力
近年來,大型語言模型(LLMs)展現出卓越的推理能力。通過延長 Chain-of-Thought(CoT)推理過程的長度,OpenAI-o1 [27] 引入了推理階段的擴展機制,從而顯著提升了其推理性能。在研究社區中,已有多項研究嘗試通過不同的方法實現測試時推理能力的擴展,包括基于過程的獎勵模型 [20, 38, 39]、強化學習(RL)[15, 34] 和搜索算法 [10, 37]。值得注意的是,最新的 DeepSeek-R1 [11] 采用 GRPO [34] 算法,僅使用少量的 RL 訓練步驟就達到了優異的性能。
隨著 LLMs 社區的發展,近來也有若干研究嘗試利用 MLLMs 的推理能力 [16, 36]。例如,Open-R1-Multimodal [16] 強調數學推理,而 R1-V [36] 則在計數任務中展現出卓越表現。然而,這些工作主要集中在高層次推理任務上,未考慮對圖像的細粒度像素級理解。為填補這一空白,我們提出的 Seg-Zero 旨在通過強化學習增強模型的像素級推理能力。
2.2. 結合推理的語義分割
語義分割的目標是為特定類別生成分割掩碼。已有大量研究 [1, 4, 5, 8, 21, 25, 33, 44](包括 DeepLab [6]、MaskFormer [9] 和 SAM [14])在該任務中取得了顯著進展,使其成為一個相對成熟的問題。
與使用明確類別標簽進行分割不同,指代表達分割(Referring Expression Segmentation)[13, 43] 關注于根據簡短、明確的文本查詢來分割目標對象。該任務更具挑戰性,因為圖像中往往存在多個具有不同屬性的同類對象,模型需要識別并分割出最符合文本描述的實例。
LISA [17] 進一步推動了該領域的發展,提出了推理分割任務。在該任務中,文本查詢更為復雜或更長,這要求模型具備更強的推理能力,以準確地解釋并分割目標對象。
2.3. 用于分割任務的 MLLMs
自從 LISA [17, 41] 引入 <SEG> 標記以連接 MLLMs 與分割模型以來,已有多項后續工作 [3, 7, 32] 探索了在分割任務中使用 MLLMs 的方法。大多數方法(包括 OneTokenSegAll [3] 和 PixelLM [32])遵循 LISA 的范式,通過使用特殊標記來連接 MLLMs 與分割模型。
然而,這種設計需要大量數據來同時微調 MLLM 與分割解碼器,甚至可能損害原始分割模型的像素級精度。我們提出的 Seg-Zero 同樣采用了解耦式設計,便于落地部署,并進一步利用 MLLMs 的推理能力,以獲得更優性能。
3. 方法
在本節中,我們介紹 Seg-Zero 模型及其相關的強化學習框架。我們首先在第 3.1 節中描述我們是如何處理分割問題的。接著,在第 3.2 節中介紹 Seg-Zero 的架構。最后,在第 3.3 節和第 3.4 節中,我們分別說明獎勵函數和訓練細節,它們均是在強化學習框架下實現的。
3.1. 流程建模(Pipeline Formulation)
給定一張圖像 I I I 和一個標簽 T T T,分割任務旨在生成一個二值分割掩碼 M M M,以準確標識與標簽 T T T 對應的區域。標簽 T T T 的復雜度可能不同,可以是一個簡單的類別標簽(例如 “bird”),一個簡短的短語(例如 “woman in blue”),甚至是一個冗長而復雜的描述(例如 “The unusual thing in the image”)。后兩種類型的表達更依賴于模型的推理能力,才能正確地分割出最相關的對象。
受到近期大模型推理能力提升的啟發 [11, 34, 36],我們利用這種能力來構建一個基于推理的分割流程。具體而言,我們將推理過程與分割過程解耦。
我們首先使用強化學習訓練 MLLM,以激活其推理能力,使其能夠生成推理過程,并輸出用于定位目標對象的準確邊界框 B B B 和兩個點 P 1 , P 2 P_1, P_2 P1?,P2?。這些邊界框和點隨后被作為提示輸入到 SOTA 分割模型 [14, 30] 中,以生成精細的分割掩碼。Seg-Zero 的訓練過程采用強化學習實現,如圖 2 所示。

3.2. Seg-Zero 模型
當前的多模態大語言模型(MLLMs)[2, 18, 24, 40, 45] 在處理多模態輸入方面表現出色,但難以生成細粒度的分割掩碼。相反,現代分割模型 [14, 30] 雖然具備精細分割能力,卻缺乏強大的推理能力。為彌合這一差距,我們提出 Seg-Zero,這是一個包含推理模型和分割模型的框架。此外,我們引入了一種新策略,在框架內有效激活 MLLM 的推理能力。其整體架構如圖 3 所示。
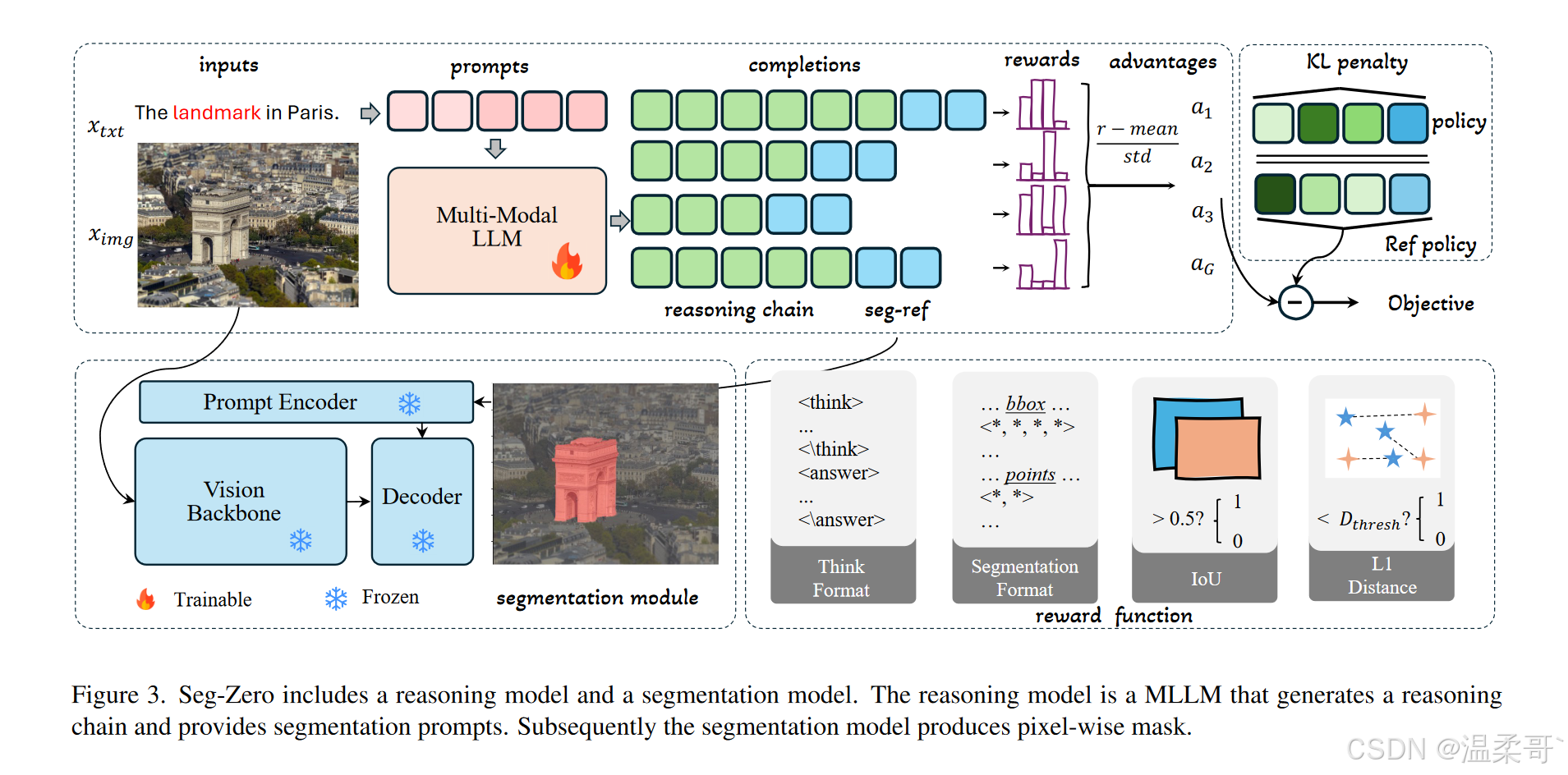
推理模型
我們采用 Qwen2.5-VL [2] 作為推理模型 F reason \mathcal{F}_{\text{reason}} Freason?。盡管 Qwen2.5-VL 在目標檢測中表現優異,能預測邊界框(bbox),但這種區域級別的 bbox 難以滿足像素級別定位的精細需求。與目標檢測不同,分割任務要求更精確地理解像素級細節,因為一個邊界框內可能包含多個目標。因此,除了邊界框,我們還引入位于目標對象內部的點,以提升定位精度。
在強化學習階段,我們引入格式獎勵,以確保模型生成結構化輸出。隨后,這些輸出會被一個后處理函數 G \mathcal{G} G 處理,從中提取邊界框 B B B 和兩個點 P 1 , P 2 P_1, P_2 P1?,P2?。該過程可形式化為:
B , P 1 , P 2 = G ( F reason ( I , T ) ) . (1) B, P_1, P_2 = \mathcal{G}(\mathcal{F}_{\text{reason}}(I, T)). \tag{1} B,P1?,P2?=G(Freason?(I,T)).(1)
分割模型
現代分割模型 [14, 30] 支持多種類型的提示,包括邊界框和點,用于生成準確的分割掩碼。我們采用性能優異且推理速度高效的 SAM2 [30] 作為分割模型 F seg \mathcal{F}_{\text{seg}} Fseg?。通過利用推理模型提供的邊界框和點,分割模型可以為目標對象生成精確、細粒度的掩碼。該過程可形式化為:
M = F seg ( B , P 1 , P 2 ) . (2) M = \mathcal{F}_{\text{seg}}(B, P_1, P_2). \tag{2} M=Fseg?(B,P1?,P2?).(2)
測試時推理
推理過程是推理分割任務中的核心部分。受 DeepSeek-R1-Zero 啟發,我們有意避免使用任何顯式的 Chain-of-Thought(CoT)數據來訓練 Seg-Zero 的推理能力。相反,我們希望從零激發模型的推理能力,使其能夠在輸出最終答案前,自主生成符合邏輯的 CoT。
為此,我們設計了結構化的用戶提示語和復雜的獎勵機制,以引導推理模型按照特定指令進行推理。如圖 4 所示,該用戶提示要求 Seg-Zero 分析并比較圖像中的對象,首先生成推理過程,隨后按照預定義格式輸出最終答案。

3.3. 獎勵函數(Reward Functions)
獎勵函數在強化學習中起著關鍵作用,因為它們決定了模型優化的方向。我們為強化學習手動設計了以下五種獎勵函數:
思維格式獎勵(Thinking Format Reward)
該獎勵旨在強制模型進行結構化的思考過程。它引導模型將其推理過程輸出在 <think> 和 </think> 標簽之間,最終答案則包含在 <answer> 和 </answer> 標簽之間。
分割格式獎勵(Segmentation Format Reward)
與計數或其他問答任務不同,分割任務對答案的格式要求很高。我們提供了兩種格式獎勵類型:軟約束和嚴格約束。
- 在軟約束下,如果答案中包含關鍵字
bbox和points,并且其對應的值分別為四個和兩個坐標,則視為格式正確; - 在嚴格約束下,僅當模型輸出完全匹配的關鍵字(例如
bbox、points_1、points_2)且結構正確,才視為格式正確。
250401:這個感覺軟約束就是,只要包含關鍵字,并且坐標是4個數和2個數的話,就可以;硬約束的話就是要能夠正確提取出來坐標的才可以。軟約束就是為了讓模型前期可以在一定程度上“寬松”輸出,允許有一點偏差,然后硬約束有助于后期精確化細化輸出。
邊界框 IoU 獎勵(Bbox IoU Reward)
該獎勵評估預測邊界框與真實邊界框之間的 IoU。如果它們的 IoU 大于 0.5,則獎勵為 1,否則為 0。
邊界框 L1 獎勵(Bbox L1 Reward)
該獎勵評估預測邊界框與真實邊界框之間的 L1 距離。如果其 L1 距離小于 10 像素,則獎勵為 1,否則為 0。
關鍵點 L1 獎勵(Point L1 Reward)
該獎勵評估預測關鍵點與真實關鍵點之間的 L1 距離。我們首先判斷預測點是否在邊界框內,然后如果預測點與真實點之間的最小距離小于 100 像素,則獎勵為 1,否則為 0。
3.4. 訓練(Training)
我們從公開的分割數據集中構建訓練數據,并使用 GRPO 算法訓練我們的 Seg-Zero 模型。
數據準備(Data Preparation)
訓練數據基于現有的指代表達分割數據集(如 RefCOCOg [43])中的原始掩碼標注生成。基于掩碼,我們提取其最左、最上、最右和最下的像素點,以生成邊界框 B B B。此外,我們計算掩碼內兩個最大內接圓的中心點,分別記為 P 1 P_1 P1? 和 P 2 P_2 P2?。因此,最終的真實標簽數據包含邊界框的坐標 [ B x 1 , B y 1 , B x 2 , B y 2 ] [B_{x1}, B_{y1}, B_{x2}, B_{y2}] [Bx1?,By1?,Bx2?,By2?] 以及兩個中心點的坐標 [ P 1 x , P 1 y ] [P_{1x}, P_{1y}] [P1x?,P1y?] 和 [ P 2 x , P 2 y ] [P_{2x}, P_{2y}] [P2x?,P2y?]。
我們不在訓練數據中加入任何 Chain-of-Thought(CoT)過程。為了保證不同數據集之間的一致性,所有圖像都會被統一調整為 840 × 840 840 \times 840 840×840 的分辨率。
GRPO
我們不使用任何顯式推理數據進行冷啟動訓練以教會模型推理能力。相反,我們讓 Seg-Zero 從零開始學習。具體來說,我們直接從預訓練的 Qwen2.5-VL-3B 模型開始訓練,使用前述獎勵函數,并應用 GRPO 算法 [34]。我們的強化學習過程如圖 2 所示。
250401:這里是直接使用強化微調,沒有使用有監督微調冷啟動一下。
4. 實驗
4.1. 實驗設置(Experimental Settings)
數據集(Datasets)
我們使用僅 9,000 個樣本在 RefCOCOg 數據集上訓練 Seg-Zero,數據準備策略參考第 3.4 節所述。測試數據包括 RefCOCO(+/g) [43] 和 ReasonSeg [17]。
實現細節(Implementation Details)
我們使用 Qwen2.5-VL-3B [2] 和 SAM2-Large [30] 作為默認的推理模型與分割模型。Seg-Zero 在一個 8xH200 GPU 服務器上,通過 DeepSpeed [29] 庫進行訓練。訓練過程中總 batch size 為 16,每步采樣數量為 8。初始學習率設為 1 × 1 0 ? 6 1 \times 10^{-6} 1×10?6,權重衰減設為 0.01。
評估指標(Evaluation Metrics)
參考以往工作 [13, 43],我們計算 gIoU 和 cIoU。gIoU 是所有圖像 IoU(Intersection-over-Unions)的平均值,而 cIoU 是累計交集與累計并集之比。除非特別說明,我們默認使用 gIoU 作為主要評估指標,因為它能同時公平地考慮大物體和小物體。
4.2. SFT 與 RL 的對比
我們比較了 SFT(有監督微調)與 RL(強化學習)兩種訓練方式的性能。基線模型為 Qwen2.5-VL-3B + SAM2。在非 CoT 設置中,我們移除了思維格式獎勵,因此模型在輸出最終答案之前不會生成 CoT 推理過程。我們的比較涵蓋了領域內和領域外(OOD)的分割任務 [26, 35],以及通用問答任務。相應結果見表 1、圖 1 和圖 5。

SFT vs. RL(無 CoT)
從表 1 的前兩行可以看出,在領域內數據集 RefCOCOg 上,SFT 與基線模型幾乎表現相當。這可能歸因于原始 Qwen2.5-VL-3B 模型本身的強大能力。然而,在 OOD 數據集 ReasonSeg 上,SFT 的性能顯著下降,說明 SFT 會對模型的泛化能力產生負面影響。
相比之下,將第一行與第三行進行對比,我們發現 RL 在領域內與領域外數據集上都能持續帶來性能提升,驗證了其有效性。此外,從圖 5 可以觀察到,SFT 模型在視覺問答能力方面存在災難性遺忘現象,而 RL 模型則能夠較好地保留這一能力。
無 CoT 的 RL vs. 有 CoT 的 RL
從表 1 的最后兩行可以看出,無論是否引入 CoT,RL 模型在領域內 RefCOCOg 和 OOD ReasonSeg 數據集上都顯著優于基線,說明 RL 能夠有效提升模型能力。
然而,加入 CoT 后,Seg-Zero 的性能進一步優于其無 CoT 的版本,這表明引入推理過程有助于模型更好地處理 OOD 樣本。
從圖 5 可見,在視覺問答任務中,對于使用 RL 訓練的模型,引入 CoT 雖然帶來輕微的性能提升,但仍是值得注意的趨勢。
4.3. 消融實驗(Ablation Study)
我們進行了多項消融實驗以驗證我們設計的有效性。在消融實驗中,默認設置如下:我們在 9,000 個樣本上采用 GRPO 算法進行強化學習,并在 RefCOCOg 測試集和 ReasonSeg 測試集上對模型進行評估。
邊界框與點的設計(Design of Bbox and Points)
表 2 展示了我們在邊界框與點提示設計上的效果。我們觀察到,單獨使用點提示時性能最差;當同時使用邊界框和點提示時,Seg-Zero 達到最優性能,說明這種組合能提升像素級定位精度。

軟獎勵 vs. 硬獎勵(Soft vs. Hard Accuracy Rewards)
在第 3.3 節中,我們描述了三種獎勵:bbox IoU 獎勵、bbox L1 獎勵和點的 L1 獎勵。我們使用特定閾值將這些指標轉化為二元獎勵。同時,我們也對它們的軟獎勵版本進行了消融研究。
對于 bbox IoU 獎勵,我們直接使用 IoU 值作為軟獎勵;對于基于 L1 的獎勵,我們將軟獎勵定義為: 1 ? L 1 _ dist max ? { image_size } . 1 - \frac{{L1}\_{\text{dist}}}{\max\{\text{image\_size}\}}. 1?max{image_size}L1_dist?. 從表 3 可以看出,雖然軟獎勵在 ReasonSeg 上帶來了一定程度的提升,但在 RefCOCOg 上相較于硬獎勵仍表現明顯不佳。

250401:軟獎勵就是這里描述的動態的獎勵,而硬獎勵就是前面介紹的二元獎勵。
軟格式獎勵 vs. 嚴格格式獎勵(Soft vs. Strict Format Rewards)
在第 3.3 節中,我們引入了兩種分割格式獎勵:軟格式和嚴格格式。從表 4 中可以看出,嚴格格式獎勵在 ReasonSeg 的 OOD 數據上顯著提升了性能。
通過對訓練過程的定性分析,我們發現嚴格格式獎勵在訓練初期階段收斂較慢,因為要采樣出嚴格匹配格式的輸出更具挑戰性。然而,隨著訓練步數的增加,使用嚴格格式獎勵的模型趨向于生成更長的響應。

250401:所以也沒說最后是兩個一起用了呢,還是只是用了軟格式呢?
推理模型規模(Reasoning Model Scale)
我們對不同規模的推理模型進行了消融實驗,模型參數規模從 2B 到 7B 不等,其他設置保持一致。如表 5 所示,模型在領域內和 OOD 數據上的性能隨著模型規模的增加而提升。

補全文本長度變化(Changes in Completion Length)
圖 7 展示了不同模型規模下補全文本長度的變化趨勢。結果表明,模型規模越大,越傾向于生成更長的響應。隨著訓練進行,最小生成長度逐漸增加。

不過在初期訓練階段,平均補全文本長度出現了短暫下降。通過分析訓練過程中的輸出,我們發現模型在初期優先學習正確的輸出格式,這通常會導致更短的回復。一旦格式獎勵趨于穩定,模型會轉而專注于生成更高準確率的答案,從而帶來更長、更詳細的響應。
我們可視化了訓練過程中獎勵變化的趨勢。如圖 8 所示,格式獎勵在幾個步驟內迅速收斂至 1,而準確性獎勵則逐步提升。這表明在訓練初期,格式獎勵主導了優化方向,導致模型補全文本變短(見圖 7)。但隨著格式獎勵收斂和準確性獎勵不斷增長,模型的補全文本長度(即 CoT 推理過程)開始擴展。

4.4. 與其他方法的比較(Comparison with Other Methods)
在本部分中,我們使用硬準確性獎勵和嚴格格式獎勵來訓練 Seg-Zero。采樣數量設置為 16,且我們僅在來自 RefCOCOg 的 9,000 個樣本上訓練 Seg-Zero。
我們與 OVSeg [19]、Grounded-SAM [31]、LISA [17]、SAM4MLLM [7]、LAVT [42]、ReLA [22]、PixelLM [32] 和 PerceptionGPT [28] 進行了對比實驗。
推理分割(Reasoning Segmentation)
我們在 ReasonSeg [17] 上比較了各方法的 zero-shot 性能,結果如表 6 所示。我們發現 Seg-Zero 在各方法中達到了 SOTA 的 zero-shot 性能。

指代表達分割(Referring Expression Segmentation)
指代表達分割的結果展示于表 7 中。此外,我們發現 RefCOCO(+/g) 中的真實標注并不夠精確,這說明 Seg-Zero 模型理論上應能取得比表中更好的表現。補充材料中提供了詳細分析。

4.5. 定性結果(Qualitative Results)
我們在圖 6 和圖 9 中展示了若干示例。可以清楚地觀察到,推理過程在分析用戶指令時非常有幫助,尤其是在同一類別中存在多個對象的情況下。例如,Seg-Zero 能夠判斷在“road trip”的上下文中,使用 “recreational vehicle” 比 “truck” 更合適,并能正確識別 “conductor” 是“位于舞臺前方”的人。


5. 結論(Conclusion)
本文提出了 Seg-Zero,這是一個新穎的框架,將 Chain-of-Thought(CoT)推理過程整合到分割任務中。我們設計了一套精巧的獎勵機制,結合了格式與準確性約束,用于引導優化方向。
通過完全基于強化學習進行訓練,Seg-Zero 實現了無需任何監督推理數據的推理能力涌現。我們展示了對 SFT 與 RL 的詳細對比,并引入了推理鏈設計。此外,我們還就 RL 的設計及其獎勵機制提供了深入的見解。

)


)







)
字段)
)
)



