張量-pytroch網站-筆記
張量是一種特殊的數據結構,跟數組(array)和矩陣(matrix)非常相似。
張量和 NumPy 中的 ndarray 很像,不過張量可以在 GPU 或其他硬件加速器上運行。
事實上,張量和 NumPy 數組有時可以共享底層內存,也就是說,不用來回復制數據(具體可以參考:與 NumPy 的橋接)。
張量還被優化過,用來自動求導
| 概念 | 通俗理解 |
|---|---|
| Tensor(張量) | 就是一個高級的“數組”,支持多維度、高性能計算 |
| 用途 | 是 PyTorch 中處理數據的核心工具,用來裝模型的輸入、輸出和參數 |
| 優勢 | 可以在 GPU 上運行、和 NumPy 兼容、支持自動求導 |
?初始化一個張量(Tensor)
張量可以用很多不同的方法來創建。下面是一些例子:
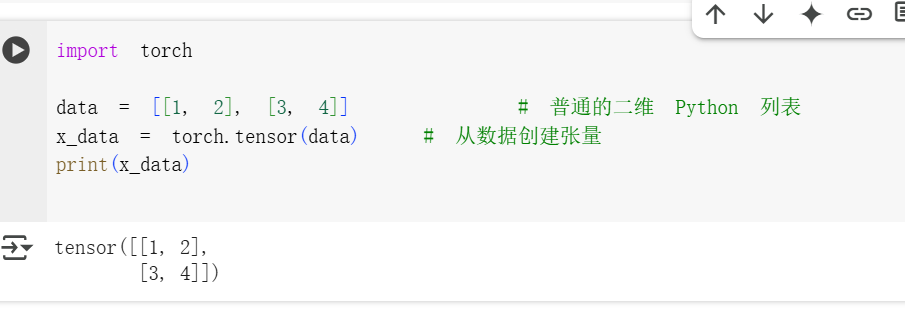
從已有數據直接創建
張量可以直接用數據來創建,數據類型(比如整數、浮點數)會自動識別。
-
張量就像“多維數組”
-
你可以直接傳入一個 Python 列表或列表嵌套,就能創建出張量
-
PyTorch 會自動判斷你傳入的數據是什么類型,比如整數、浮點數等
 ?從 NumPy 數組創建張量
?從 NumPy 數組創建張量
張量可以從 NumPy 數組創建
-
PyTorch 和 NumPy 是好兄弟
-
可以:
-
把 NumPy 數組變成張量:用于神經網絡訓練
-
也可以把張量變回 NumPy 數組:用于數學計算或繪圖
-
-
它們還可以共享內存,不需要復制,提高效率
-

反過來,把張量變成 NumPy:
 ?
?
從另一個張量創建新張量:
新張量會自動保留原張量的屬性(比如形狀、數據類型),除非你手動改了它。?

使用 torch.ones_like(x_data) 創建一個 和 x_data 形狀完全相同,但元素全部為 1 的張量。?
使用 torch.rand_like(x_data) 創建一個和 x_data 形狀一樣的 隨機數張量(數值范圍在 [0, 1) 之間的浮點數)
使用隨機值或常數值創建張量時,shape 是一個表示張量維度的元組。在下面這些函數中,shape 用來確定輸出張量的維度。

張量(Tensor)的屬性用來描述它的:
-
形狀(shape)
-
數據類型(datatype)
-
所在設備(device)

?
PyTorch 提供了 超過 1200 種張量操作,包括:
-
算術運算(加減乘除)
-
線性代數運算(矩陣乘法、逆矩陣等)
-
矩陣操作(轉置、索引、切片等)
-
采樣(比如從概率分布中隨機取樣)
所有這些操作都可以在:
-
CPU
-
或者加速器上運行,例如:
-
CUDA(NVIDIA 的 GPU)
-
MPS(Mac 上的 GPU 加速)
-
MTIA, XPU(英特爾或其他廠商的加速器)
-
?
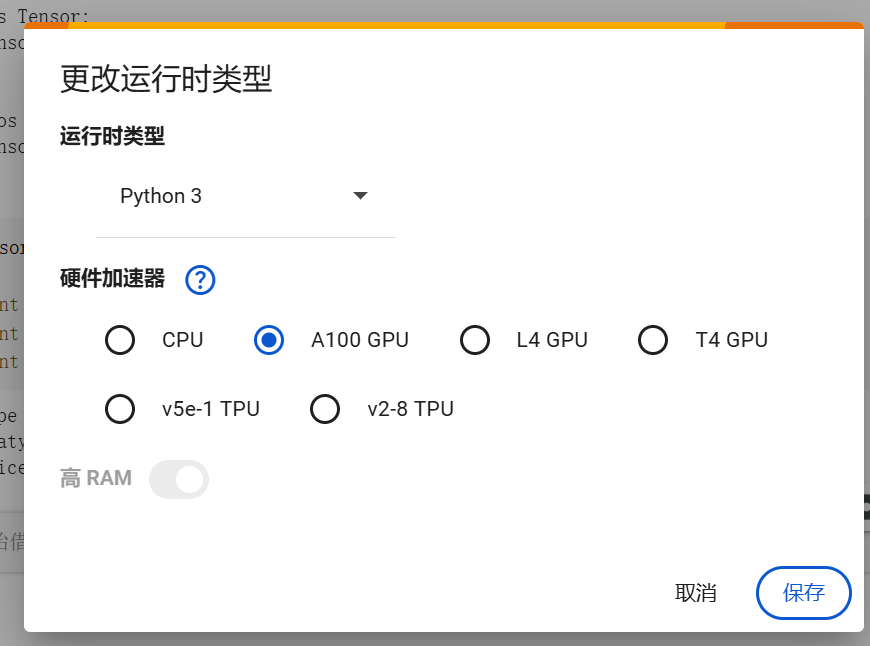
如果在用 Google Colab(一個在線的 Python 運行環境):
-
可以點擊菜單欄的:
Runtime > Change runtime type > GPU -
來分配一個 GPU 加速器,從而提升運算效率。
 ?
?
-
默認情況下,張量是在 CPU 上創建的。
-
如果想讓它在 GPU 上運算,就需要用
.to()方法顯式地移動: -
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") x = x.to(device)在不同設備(比如從 CPU → GPU)之間移動大張量時,會消耗時間和內存。
-
PyTorch 支持大量張量操作,這些操作可以在 CPU 或各種加速器(如 GPU)上運行。但默認張量是在 CPU 上,需要手動移動到 GPU,而且大張量的設備間拷貝是耗資源的,要謹慎操作。
-
你可以嘗試一下列表中的一些操作(指張量的操作)。如果你熟悉 NumPy 的 API(編程接口),你會發現 PyTorch 的張量 API 用起來非常簡單,就像“輕而易舉”一樣
-
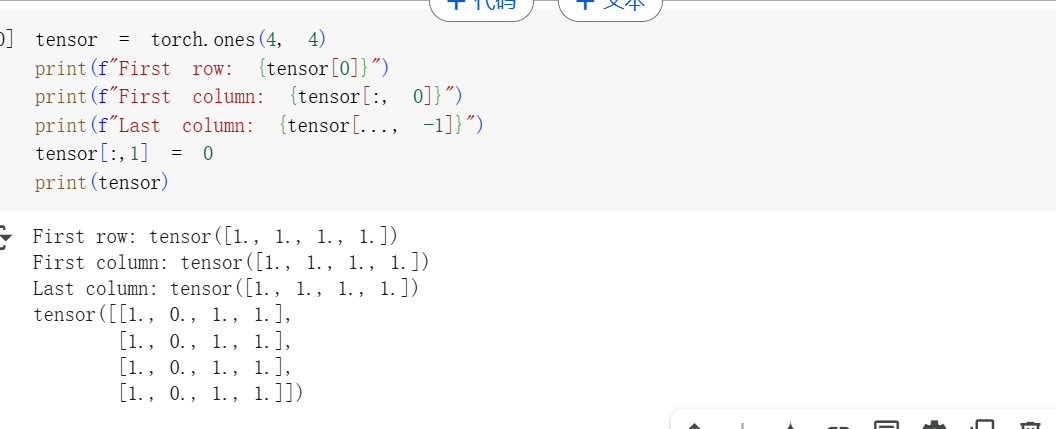
4行4列?標準索引和切片方法

dim=1 列,cat合并
-
torch.cat是 PyTorch 中的一個函數,用來拼接多個張量。 -
拼接時要求:除了指定拼接的那個維度以外,其他維度必須一致。
-
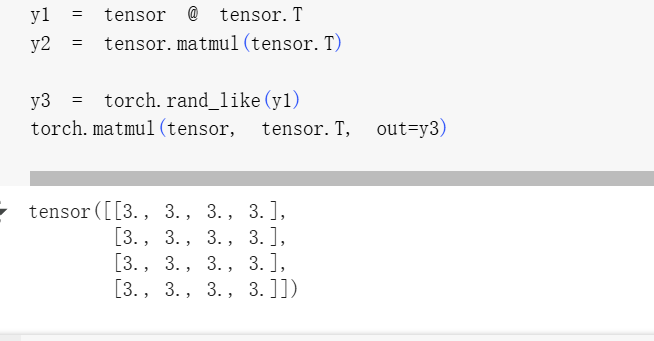
tensor.T:表示張量tensor的 轉置(把行列對換)。 -
@和matmul()都是做 矩陣乘法 的方式,它們等價。 -
out=y3是在指定:把結果 直接存儲進 y3,不返回新張量,節省內存。
-
這部分不是做矩陣乘法,而是逐個元素相乘(element-wise multiply)
-
也就是說
tensor[i][j] * tensor[i][j],每個元素單獨相乘。 -
和矩陣乘法的規則不同,不涉及轉置、不涉及矩陣行列數匹配。
-
總結對比:
運算類型 操作符 / 函數 是否逐元素? 是否需要轉置? 輸出維度變化? 矩陣乘法 @,matmul()? 否 ? 通常需要轉置 ? 會變 逐元素乘法(Hadamard) *,mul()? 是 ? 不需要 ? 不變
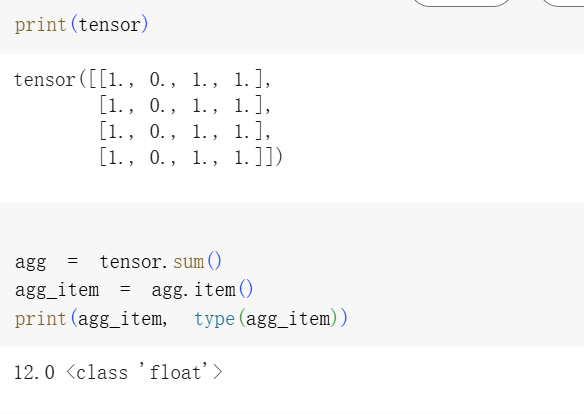
?單元素張量(single-element tensor)是指只有一個元素的張量。
比如你對一個張量做了求和(sum)、平均(mean)等操作,結果就是一個單個值的張量。
如果你想把這個張量變成普通的 Python 數值(比如 int 或 float),可以使用 .item() 方法
In-place operations(就地操作)是指那些直接把結果存回原變量的操作。
這類操作的特點是:不會創建新張量,而是直接修改原張量本身。
它們通常在函數名后面加一個 下劃線 _ 來表示,比如:
-
x.copy_(y):把y的值復制進 x,直接修改x的內容。 -
x.t_():將x轉置,結果直接替代原來的x。 -

-
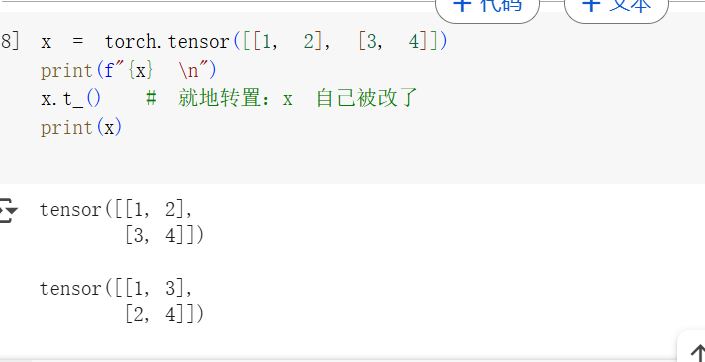
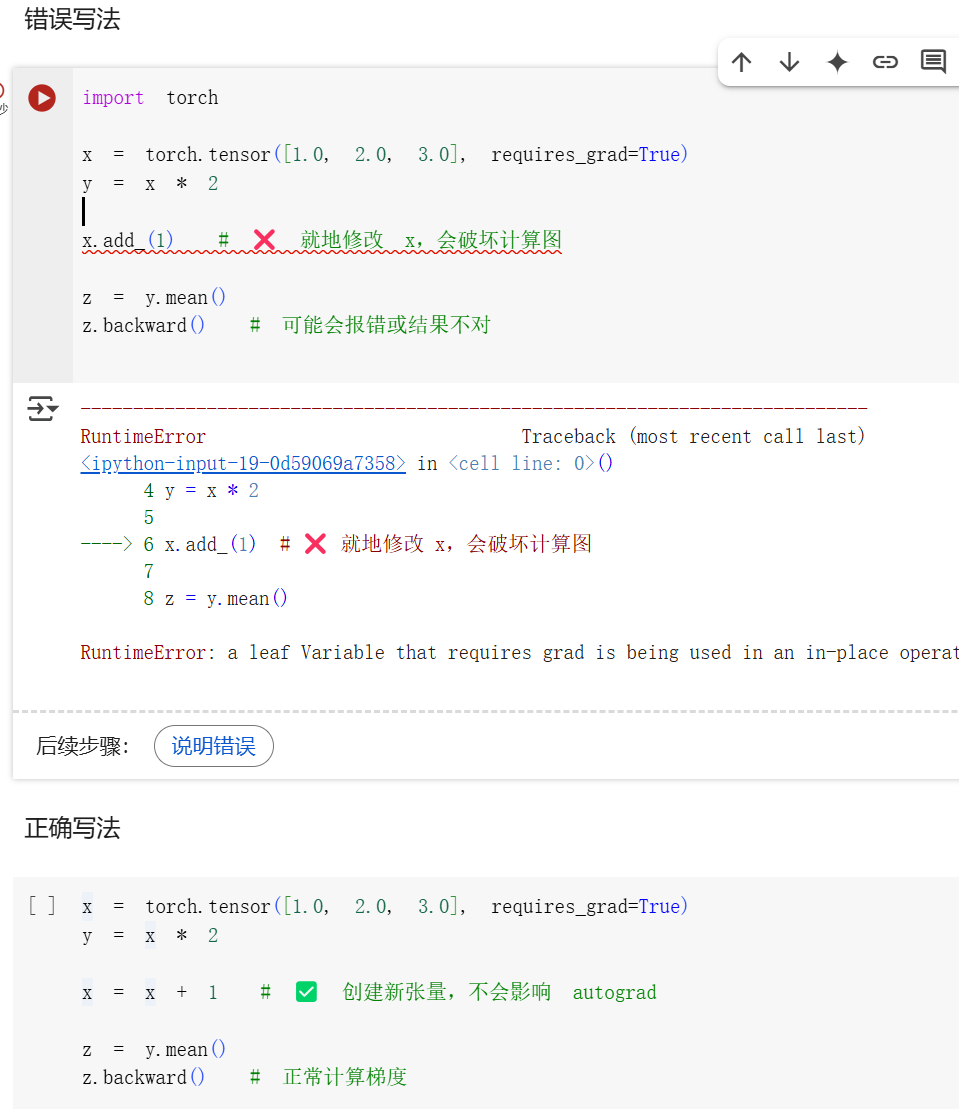
?就地操作(in-place operations)雖然可以節省一些內存,
但在計算梯度(導數)時可能會出問題,因為它們會立即丟失計算歷史(history),
所以一般不推薦在需要反向傳播(backpropagation)的時候使用 in-place 操作。
在 PyTorch 中,自動求導(autograd)系統需要記錄每一個操作的計算歷史,以便后面做反向傳播(計算梯度)。
-
普通操作會保留這些歷史;
-
就地操作(比如
x += 1或x.copy_(...))會直接覆蓋原變量的值,導致 PyTorch 無法回溯計算路徑,從而報錯或者計算錯誤。 -
-
in-place 操作雖然省內存,但有可能破壞 PyTorch 的計算圖,導致梯度無法正確求解,因此在訓練模型時最好避免使用。
 ?
?
當張量(Tensor)位于 CPU 上時,它和 NumPy 數組可以共享底層內存地址(memory location),
所以修改其中一個,另一個也會跟著改變。
 ?
?
改動 NumPy,也會影響張量?
)















)


