機器學習是現代AI的核心,從推薦系統到自動駕駛,無處不在。但每個智能應用背后,都離不開那些奠基性的模型。本文用最簡練的方式拆解核心機器學習模型,助你面試時對答如流,穩如老G。
線性回歸
線性回歸試圖通過"最佳擬合線"(讓所有數據點到直線的距離平方和最小,即最小二乘法)來尋找自變量和因變量的關系。比如下圖綠線比藍線更優,因為它離所有數據點更近。
Lasso回歸 (L1)
Lasso回歸通過添加"絕對值懲罰項"(lambda × 斜率絕對值)來防止模型過擬合,堪稱機器學習界的防沉迷系統。lambda越大,懲罰越狠——就像你媽發現你熬夜寫代碼時的怒氣值。
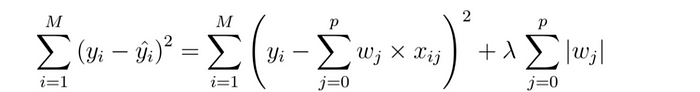
圖2:Lasso回歸成本函數
當特征多到能繞地球三圈時,L1會無情拋棄那些不重要的變量,堪稱特征選擇界的滅霸。
Ridge回歸 (L2)
Ridge和Lasso是親兄弟,區別在于懲罰項改用"平方懲罰"(lambda × 斜率2)。當特征們勾肩搭背搞多重共線性時,L2會讓所有系數雨露均沾地趨向零——堪稱機器學習界的端水大師。
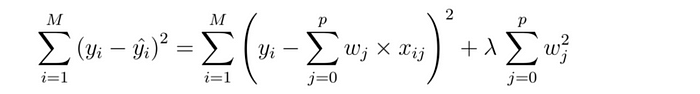
圖4:Ridge回歸成本函數
彈性網絡回歸
這位端水大師Pro Max版同時采用L1和L2懲罰,效果堪比機器學習界的鴛鴦鍋——辣度自由調節,總有一款適合你。
多項式回歸
當數據扭成麻花時,線性回歸就懵圈了。這時多項式回歸祭出***k.x?***大法,用曲線擬合數據,堪稱機器學習界的靈魂畫手。
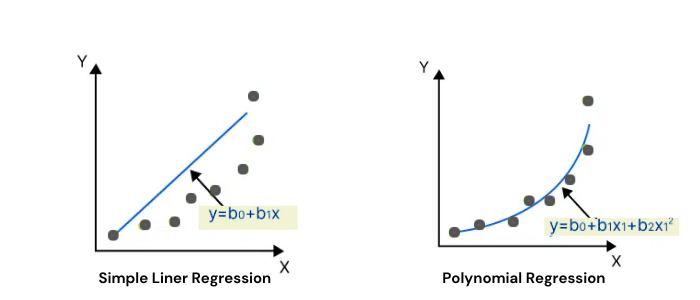
圖6:線性回歸 vs 多項式回歸的降維打擊
邏輯回歸
雖然名字帶"回歸",實則是分類界的扛把子。用sigmoid函數把輸出壓縮到0-1之間(比如預測你禿頭的概率),找最佳曲線時用的是最大似然估計法——就像S命先生掐指一算S。

圖7:線性回歸 vs 邏輯回歸的跨界PK
K近鄰算法 (KNN)
KNN是分類界的懶漢代表:平時不訓練,來新數據才臨時抱佛腳找最近的K個鄰居投票。K太小會誤把異類當知己,K太大又會忽視小眾群體——堪稱機器學習界的社交恐懼癥患者。
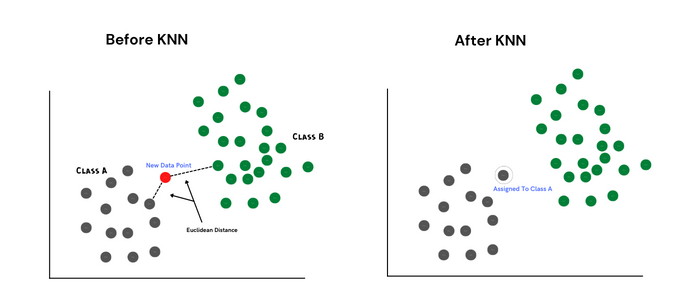
圖8:KNN施展魔法前后對比
樸素貝葉斯
基于貝葉斯定理的文本分類專家,天真地認為所有特征都互不相關(就像覺得程序員只穿格子衫)。公式長這樣:
P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) P(A|B) = \frac{P(B|A)P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)P(A)?
支持向量機 (SVM)
在n維空間找最佳超平面分割數據,就像用激光刀切蛋糕。支持向量是靠近切割線的數據點,它們決定了超平面的位置——堪稱機器學習界的邊界感大師。
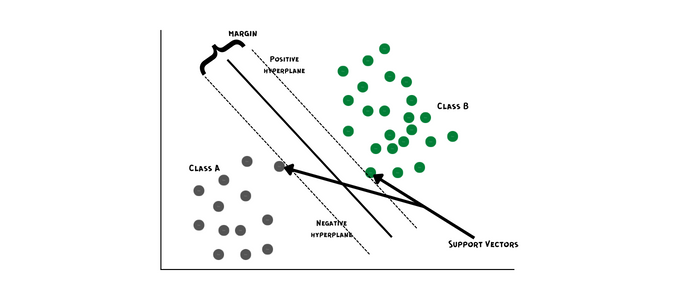
圖10:SVM在線性可分數據上的表演
決策樹
用if-else語句組成的樹狀結構,活像《龍與地下城》的選擇劇情書。節點是特征,分支是條件,葉節點是結局——堪稱機器學習界的《命運之門》游戲。
CART (基尼系數)
1. 概率表
2. 計算各屬性值的基尼指數:1 - (P/P+N)2 -(N/P+N)2
3. 計算屬性的基尼指數:各屬性值占比×其基尼指數的和ID3 (信息增益與熵)
1. 計算總信息熵
2. 計算各屬性值熵:-[P/P+N] * log[p/P+N] - [N/P+N * log[N/P+N]
3. 計算屬性信息增益:總熵 - 各屬性值熵的加權和
隨機森林
決策樹們的民主議會,通過bagging和隨機特征降低過擬合。每棵樹用不同數據子集訓練,最終投票決定結果——當一棵樹說你會禿,四棵樹說你會富,信誰的?當然是多數派!
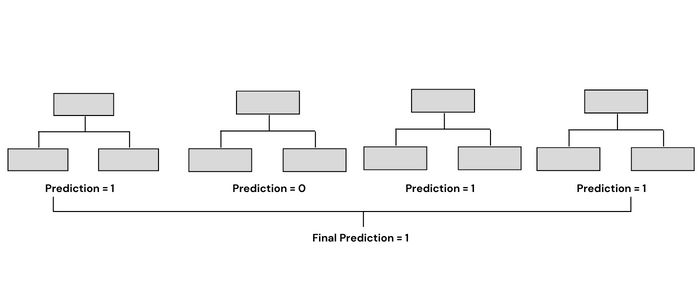
圖12:4個決策樹組成的迷你森林
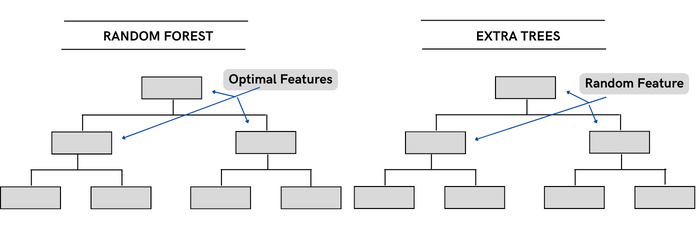
極限隨機樹 (Extra Trees)
隨機森林的叛逆兄弟:分裂節點時完全隨機選特征,訓練速度堪比吃了金坷垃。與隨機森林的兩大區別:
- 隨機選分裂點(閉眼扔飛鏢)
- 用全量數據而非bootstrap樣本
AdaBoost
把一堆"弱智"決策樁(只有一次分裂的決策樹)組合成天才團隊。給分錯的數據點加權重,后續模型重點關照——堪稱機器學習界的錯題本復習法。
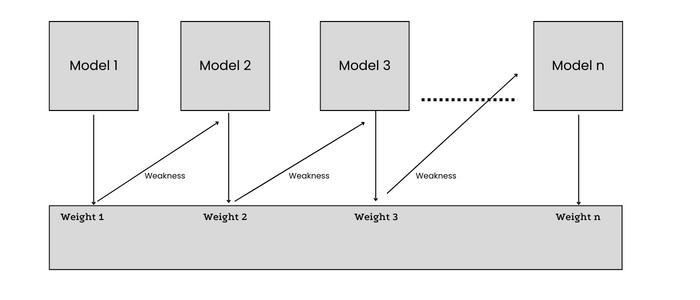
圖14:提升算法的集體智慧
梯度提升
讓決策樹們玩傳幫帶游戲:新樹專門學習老樹的殘差錯誤。通過不斷修正前人的錯誤,最終組成學霸天團——比AdaBoost更卷,因為用的是完整決策樹而非樹樁。
K均值聚類
無監督學習中的課代表,把數據分成K個簇(K由你定)。流程簡單粗暴:
- 隨機選K個中心點
- 計算每個點到中心的距離
- 把點分給最近的中心
- 重新計算中心點
- 重復直到中心點不動了
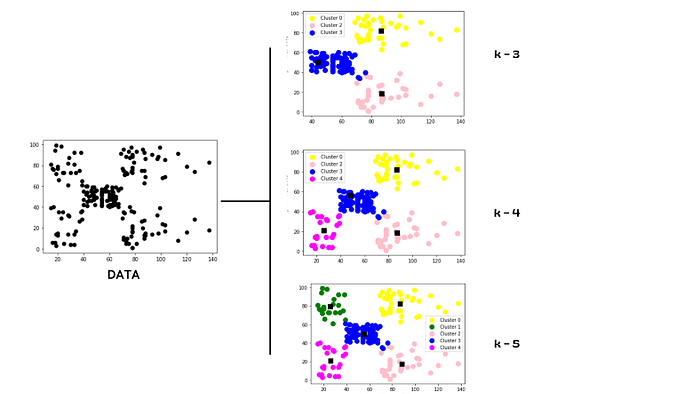
圖15:K均值在不同K值下的表演
層次聚類
有兩種流派:
- 自底向上(聚合式):每個點先單干,逐漸合并
- 自頂向下(分裂式):全體先抱團,逐漸分家
最終形成樹狀圖,堪稱機器學習界的族譜學家。
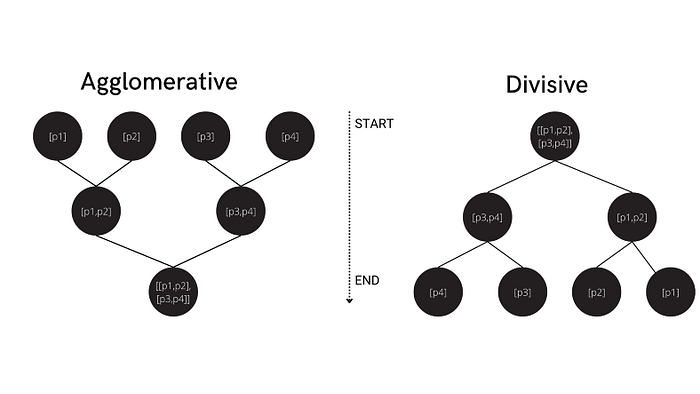
DBSCAN聚類
認為"物以類聚"的密度派,能自動發現任意形狀的簇。兩個關鍵參數:
epsilon:好基友的最大距離min_points:組隊最少人數
優點是可以識別噪聲點(比如公司團建時總找借口不來的同事)。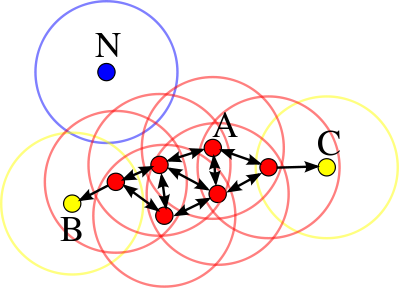
Apriori算法
購物籃分析專家,能發現"買尿布的人常買啤酒"這種神奇規律。通過支持度(出現頻率)和置信度(X出現時Y多大概率出現)挖掘關聯規則。
分層K折交叉驗證
K折驗證的公平版:確保每折中各類別比例與原數據一致。就像把披薩切成K塊,每塊都有相同的配料比例。

主成分分析 (PCA)
降維魔術師,把相關特征變成少數幾個"主成分"。雖然會損失信息,但能:
- 提升模型表現
- 降低計算開銷
- 方便可視化(三維人類看不懂十維數據)
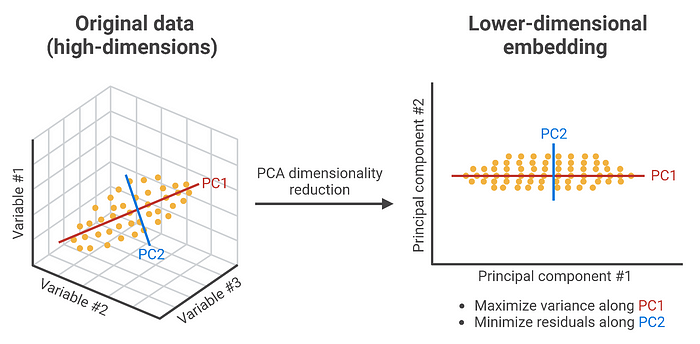
人工神經網絡 (ANN)
模仿人腦的"人工智障",由輸入層、隱藏層、輸出層組成。每個神經元都是戲精,要對輸入數據加權重、做激活函數變換。常用于圖像識別、NLP等領域。
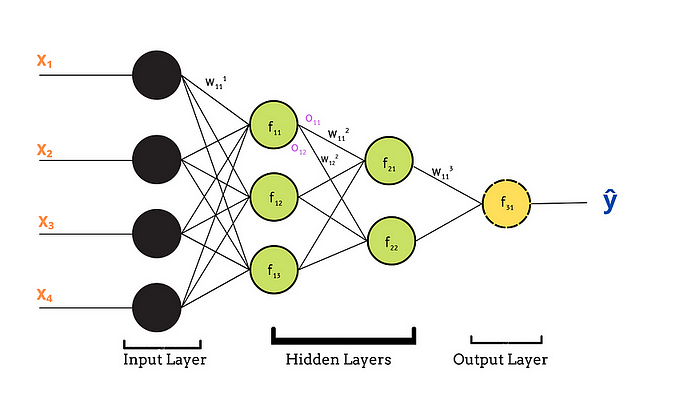
圖:多層神經網絡的復雜人際關系
卷積神經網絡 (CNN)
圖像處理界的福爾摩斯,用卷積層掃描圖片找邊緣、紋理等特征。支撐著人臉識別、自動駕駛等技術——畢竟普通神經網絡看圖片就像近視眼沒戴眼鏡。
Q學習
強化學習中的吃豆人AI,通過試錯積累經驗值(Q表)。廣泛應用于游戲AI、機器人控制等領域,學習過程就像:
- 機器人碰壁 → “疼!下次不走這”
- 找到充電樁 → “爽!多逛這里”

TF-IDF
文本分析中的"詞頻-逆文檔頻率"算法,能識別重要詞匯。比如在《程序員養生指南》中:
- “的” → 高頻但沒營養
- “枸杞” → 高頻且專有 → 重點標記
潛在狄利克雷分配 (LDA)
主題建模專家,能發現"程序員論壇50%聊禿頭,30%聊跑路,20%聊AI取代人類"。通過分析詞共現規律,挖掘文本的隱藏主題。
Word2Vec
讓計算機理解"國王-男=女王"的語義關系,把詞語變成向量。比傳統方法更懂語境,支撐著現代翻譯系統和聊天機器人。
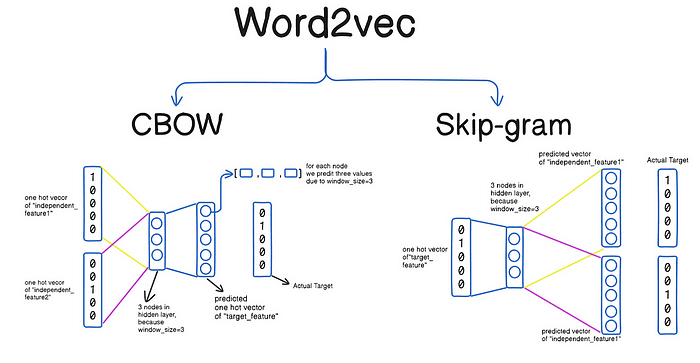
圖:詞向量的語義魔法
如果覺得這份指南有用,不妨:
- 留下你的👋掌聲和💬神評論











)






)
