今天開始整cuda編程處理圖像,好久沒玩cuda,又從小白開始。情況不妙,第一個工程坑不少,記錄一下如下2個重要的錯誤:
(1)來自 CUDA 12.1.targets 的MSB3721錯誤
錯誤 命令““C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin\nvcc.exe” -XXXXX-C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\include" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\include" -G --keep-dir x64\Debug -maxrregcount=0 --machine 64 --compile ”已退出,返回代碼為 255。XXXXXX\CUDA 12.1.targets。
總之就是除了報這個錯誤,還有一長串別的都是跟sm_相關的錯誤,檢查代碼計算沒有問題,就是編譯一直一長串。。。
那么按照如下操作看看:
1)檢查工程配置屬性
鼠標落在解決方案上->右鍵->生成依賴項->生成自定義,查看確保已經選中如下:
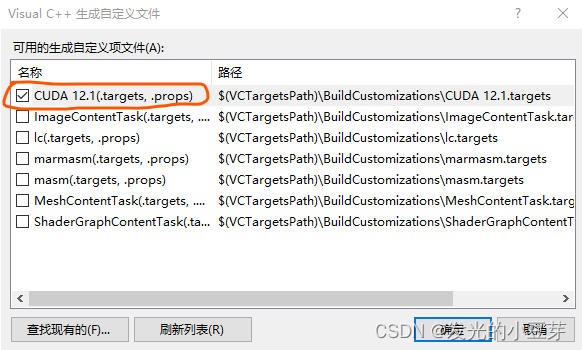
2)查看.cu文件的屬性
鼠標落點.cu文件,右鍵->屬性,查看項類型為如下:
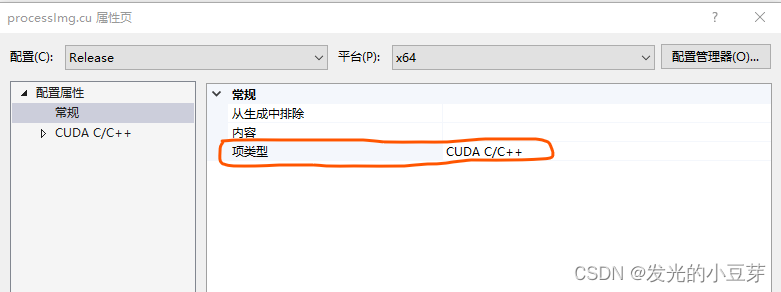
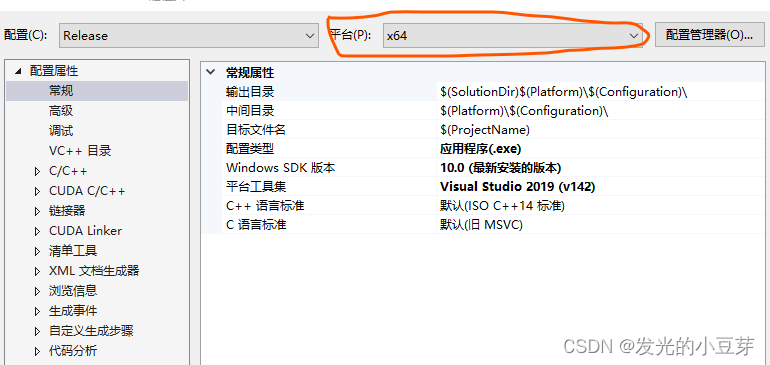
3)檢查編譯器,確保為X64(此處非常容易忽略)
查看狀態欄:

查看解決方案->屬性:
(2)提示調用語法錯誤‘<’
這個問題比較煩神,搜羅一圈都說cpp中不能直接調用核函數<<<,>>>,需要extern "c"去修飾,但是也不太明白怎么個修飾安置法。那么我再仔細理一下:
先上代碼:
.cpp 文件如下:
#include "processImg.cuh"
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <iostream>int main()
{int N = 1 << 20;int nBytes = N * sizeof(float);// 申請host內存float* x, * y, * z;x = (float*)malloc(nBytes);y = (float*)malloc(nBytes);z = (float*)malloc(nBytes);// 初始化數據for (int i = 0; i < N; ++i){x[i] = 10.0f;y[i] = 20.0f;}//------------調用核函數封裝函數-------------------------------AddKernelFunction(x, y, z);// 檢查執行結果float maxError = 0.f;for (int i = 0; i < N; i++)maxError = fmax(maxError, fabs(z[i] - 30.0f));std::cout << "最大誤差: " << maxError << std::endl;// 釋放host內存free(x);free(y);free(z);return 0;
}
.cuh 文件如下:
//------#######-------------------------------------
聲明文件,聲明在cu文件中定義的核函數及其封裝函數
//------#######-------------------------------------#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include <stdlib.h>
#include <assert.h>//--------供cpp調用的封裝核函數-----------------------------
extern "C" void AddKernelFunction(float* x, float* y, float* z);//-----------核函數--------------------------------------------
__global__ void add(float* x, float* y, float* z, int n);
.cu 文件如下:
//------#######------------------
核函數定義及封裝核函數的調用函數定義
//------#######------------------#include "processImg.cuh" #include "cuda_runtime.h"
#include "device_launch_parameters.h"__global__ void add(float* x, float* y, float* z, int n)
{// 獲取全局索引int index = threadIdx.x + blockIdx.x * blockDim.x;// 步長int stride = blockDim.x * gridDim.x;for (int i = index; i < n; i += stride){z[i] = x[i] + y[i];}
}
extern "C" void AddKernelFunction(float* x, float*y, float*z)
{int N = 1 << 20;int nBytes = N * sizeof(float);float* d_x, * d_y, * d_z;cudaMalloc((void**)&d_x, nBytes);cudaMalloc((void**)&d_y, nBytes);cudaMalloc((void**)&d_z, nBytes);cudaMemcpy((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice);cudaMemcpy((void*)d_y, (void*)y, nBytes, cudaMemcpyHostToDevice);dim3 blockSize(256);dim3 gridSize((N + blockSize.x - 1) / blockSize.x);// 執行kerneladd <<<gridSize,blockSize>>>(d_x, d_y, d_z, N);cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyHostToDevice);// 釋放device內存cudaFree(d_x);cudaFree(d_y);cudaFree(d_z);
}
沒錯,整個測試小工程有3個文件組成:
.cpp文件包含了工程的入口main()函數,里面定義了一些在CPU上的變量分配,并調用了核函數封裝函數。
.cuh文件,就是cu文件的聲明頭文件,聲明了cu文件中定義的函數。
.cu文件,核函數定義文件,同時定義了供外部調用的封裝函數。
當然了,其實cuda中的函數的定義和調用封裝等還有很多小細節有待挖掘和優化,計算前 memset一下會更好,路漫漫其修遠兮~










 開發平臺之HTTP端口規劃)

:一對一映射)






