1、創建scrapy項目
? ? ? ? 首先在自己的跟目錄文件下執行命令:
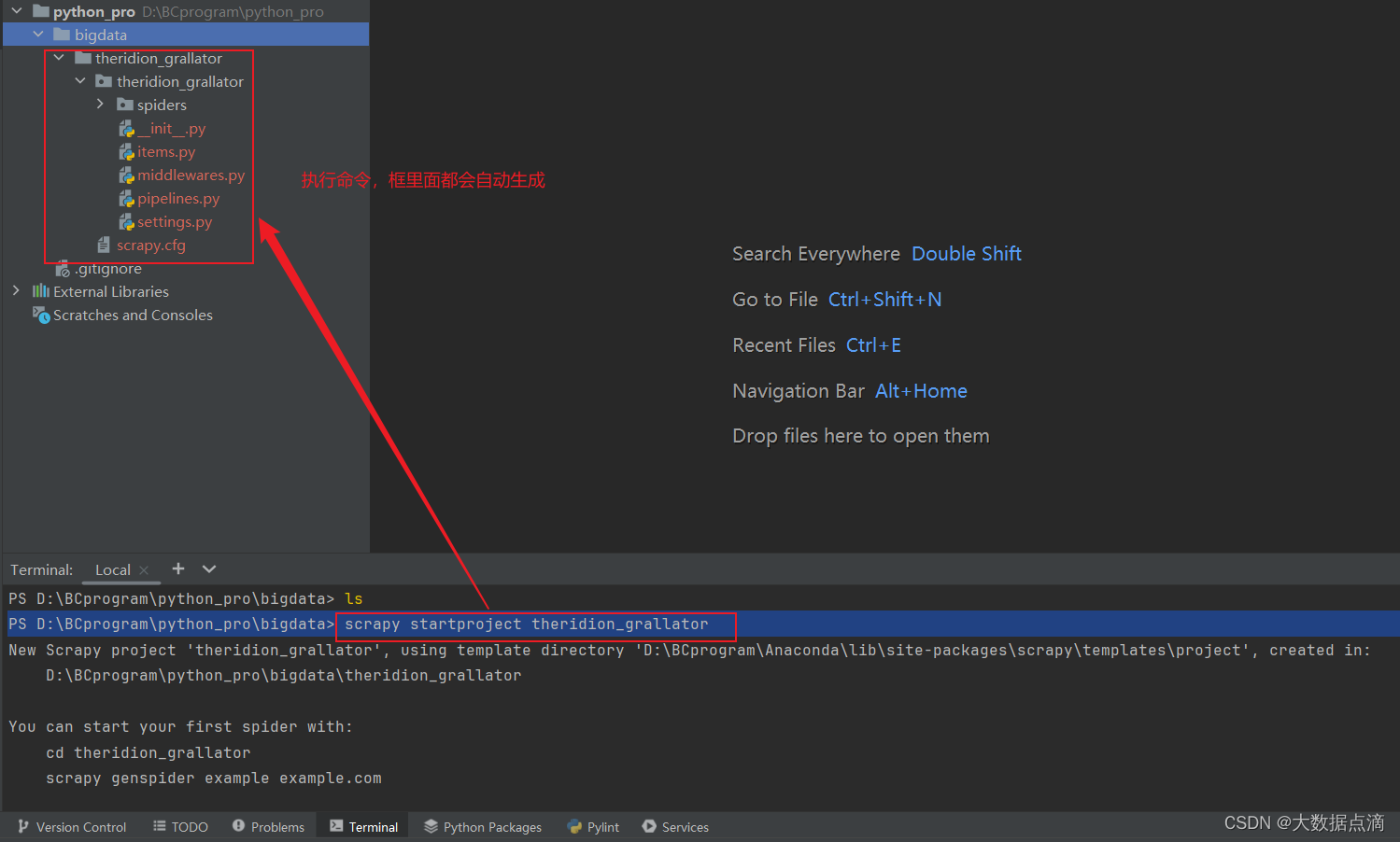
PS D:\BCprogram\python_pro\bigdata> scrapy startproject theridion_grallatorscrapy + startproject + 項目名 具體執行操作如下:1、創建項目目錄:Scrapy會在當前工作目錄下創建一個名為 theridion_grallator 的新目錄。這個目錄將成為你的Scrapy項目的根目錄。
2、生成基本文件結構:在 theridion_grallator 目錄下,Scrapy會自動生成一套標準的文件和子目錄結構,包括但不限于:theridion_grallator/: 項目根目錄。theridion_grallator/theridion_grallator/: 包含項目的設置文件 (settings.py)、爬蟲模塊(spiders/)、中間件 (middlewares.py)、管道 (pipelines.py) 等核心組件。theridion_grallator/items.py: 定義爬蟲項目中數據模型的地方。theridion_grallator/pipelines.py: 數據處理的管道定義,用于清洗或存儲爬取的數據。theridion_grallator/settings.py: 項目的配置文件,可以設置如用戶代理、下載延遲等參數。theridion_grallator/spiders/: 存放所有爬蟲腳本的目錄,初始時可能為空或包含一個示例爬蟲。scrapy.cfg: 項目的配置文件,位于根目錄,用于指定項目的設置模塊和其他元數據
2、創建一個爬蟲程序?
????????首先進入項目文件夾下,然后輸入命令:?
scrapy genspider 爬蟲程序的名稱? 要爬取網站的域名
D:\BCprogram\python_pro\bigdata\theridion_grallator> scrapy genspider game_4399 4399.com
?
當你運行 scrapy genspider game_4399 4399.com 命令時,Scrapy將執行以下操作:
1、創建爬蟲文件:Scrapy會在 theridion_grallator/spiders/ 目錄下創建一個名為 game_4399.py 的新文件。這個文件將包含你新建的爬蟲的代碼。
2、生成爬蟲模板:打開 game_4399.py 文件,你會看到Scrapy已經為你生成了一個基本的爬蟲模板,包括爬蟲類 Game_4399 和一些默認方法,如 start_requests()、parse() 等。
3、配置爬蟲域:Scrapy在爬蟲類中設置了 allowed_domains 屬性,將其值設為 ['4399.com'],這意味著爬蟲將只對4399.com域名下的URL進行爬取。
4、設置起始URL:在 start_requests() 方法中,Scrapy通常會生成一個請求(Request 對象)到指定的域名(這里為 4399.com),作為爬蟲開始爬取的起點。
5、定義解析函數:parse() 方法是默認的回調函數,當Scrapy收到響應后會調用它來解析網頁內容。你需要根據4399.com網站的HTML結構來定制這個方法,以提取所需的數據。
3、編寫爬蟲程序
在game_4399.py文件中編寫爬蟲代碼,代碼如下
import scrapyclass Game4399Spider(scrapy.Spider):name = "game_4399" # 爬蟲程序的名稱allowed_domains = ["4399.com"] # 允許爬取的域名# 默認情況下是:https://4399.com# 但是我們不從首頁開始爬取,所以改一下URLstart_urls = ["https://4399.com/flash/"] # 一開始爬取的URLdef parse(self, response): # 該方法用于對response對象進行數據解析# print(response) # <200 http://www.4399.com/flash/># print(response.text) # 打印頁面源代碼# response.xpath() # 通過xpath解析數據# response.css() # 通過css解析數據# 獲取4399小游戲的游戲名稱# txt = response.xpath('//ul[@class="n-game cf"]/li/a/b/text()')# txt 列表中的每一項是一個Selector:# <Selector query='//ul[@class="n-game cf"]/li/a/b/text()' data='逃離克萊蒙特城堡'>]# 要通過extract()方法拿到data中的內容# print(txt)# txt = response.xpath('//ul[@class="n-game cf"]/li/a/b/text()').extract()# print(txt) # 此時列表中的元素才是游戲的名字# 也可以先拿到每個li,然后再提取名字lis = response.xpath('//ul[@class="n-game cf"]/li')for li in lis:# name = li.xpath('./a/b/text()').extract()# # name 是一個列表# print(name) # ['王城霸業']# 一般我們都會這么寫:li.xpath('./a/b/text()').extract()[0]# 但是這樣如果列表為空就會報錯,所以換另一種寫法# extract_first方法取列表中的第一個,如果列表為空,返回Nonename = li.xpath('./a/b/text()').extract_first()print(name) # 王城霸業category = li.xpath('./em/a/text()').extract_first() # 游戲類別date = li.xpath('./em/text()').extract_first() # 日期print(category, date)# 通過yield向管道傳輸數據dic = {'name': name,'category': category,'date': date}# 可以認為這里是把數據返回給了管道pipeline,# 但是實際上是先給引擎,然后引擎再給管道,只是這個過程不用我們關心,scrapy會自動完成# 這里的數據會在管道程序中接收到yield dic4、運行scrapy爬蟲程序
在終端輸入命令,就可以看到爬蟲程序運行結果。
scrapy crawl 爬蟲程序名稱
D:\BCprogram\python_pro\bigdata\theridion_grallator> scrapy crawl game_4399
當你運行 scrapy crawl 爬蟲程序名稱 命令時,Scrapy執行以下操作來啟動指定的爬蟲:
1、加載項目設置:Scrapy首先讀取項目根目錄下的 settings.py 文件,加載項目配置。
2、初始化引擎:Scrapy初始化爬蟲引擎,準備開始爬取流程。
3、啟動爬蟲:根據提供的爬蟲名稱,Scrapy會找到對應的爬蟲類(通常在 spiders 目錄下的Python文件中),并實例化這個爬蟲。
4、執行start_requests:Scrapy調用爬蟲類中的 start_requests 方法,這個方法返回一個或多個 Request 對象,表示要發起的HTTP請求。
5、調度請求:每個 Request 對象被添加到調度器(Scheduler)中,等待被發送到下載器(Downloader)。
6、下載網頁:下載器接收到調度器的請求,下載網頁內容,并生成一個 Response 對象。
7、解析響應:下載完成后的 Response 對象被傳遞給爬蟲的解析函數(通常是 parse 或其他自定義的回調函數),在這里,爬蟲解析HTML,提取數據,可能還會生成新的 Request 對象,形成新的爬取循環。
8、處理數據:提取到的數據通常會經過中間件的處理,然后傳遞給管道(Pipelines),在那里進行進一步的清洗、驗證和持久化存儲。
9、錯誤處理:如果在爬取過程中遇到錯誤,比如網絡問題或服務器返回錯誤狀態碼,Scrapy會使用中間件和爬蟲的錯誤處理邏輯來處理這些問題。
10、監控和控制:Scrapy提供了一套日志系統,可以記錄爬取過程中的信息,還可以通過信號和擴展來實現更復雜的控制邏輯。
11、爬蟲結束:當沒有更多的請求待處理,或者達到預設的停止條件(如最大深度、最大請求數等),爬蟲會停止運行。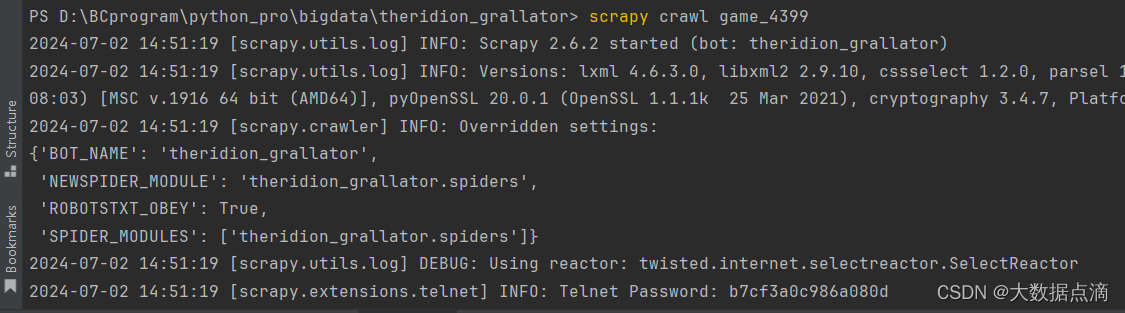









 開發平臺之HTTP端口規劃)

:一對一映射)







