
1.簡單介紹一下大模型【LLMs】?
????????大模型:一般指1億以上參數的模型,但是這個標準一直在升級,目前萬億參數以上的模型也有了。大語言模型(Large Language Model,LLM)是針對語言的大模型。
2.目前主流的開源模型體系有哪些?
????????目前主流的開源模型體系分三種:
1. 第一種:prefix Decoder 系
????????介紹:輸入雙向注意力,輸出單向注意力
????????代表模型:ChatGLM、ChatGLM2、U-PaLM
2. 第二種:causal Decoder 系
????????介紹:從左到右的單向注意力
????????代表模型:LLaMA-7B、LLaMa 衍生物
3. 第三種:Encoder-Decoder
????????介紹:輸入雙向注意力,輸出單向注意力
????????代表模型:T5、Flan-T5、BART

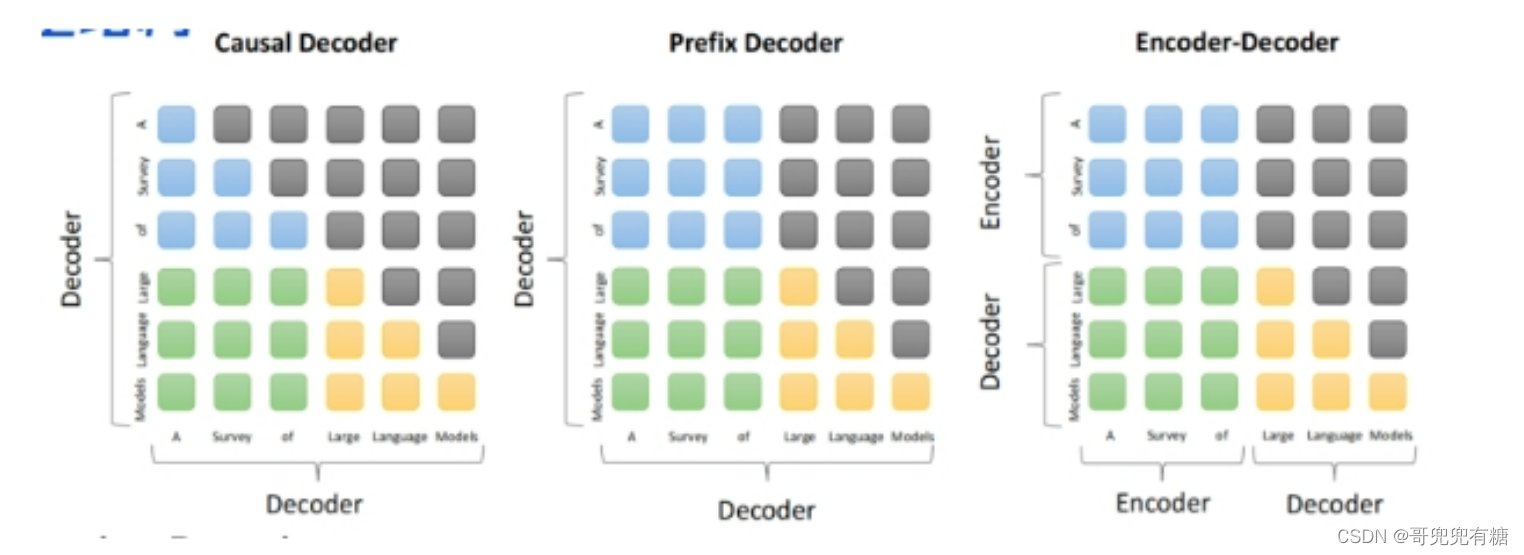
3. prefix Decoder 和 causal Decoder 和 EncoderDecoder 區別是什么?
????????prefix Decoder 和 causal Decoder 和 Encoder-Decoder 區別 在于 attention mask不同:
1. Encoder-Decoder:
2. 在輸入上采用雙向注意力,對問題的編碼理解更充分
3. 適用任務:在偏理解的 NLP 任務上效果好
4. 缺點:在長文本生成任務上效果差,訓練效率低;
5. causal Decoder:
6. 自回歸語言模型,預訓練和下游應用是完全一致的,嚴格遵守只有后面的token才能看到前面的 token的規則;
7. 適用任務:文本生成任務效果好
8. 優點:訓練效率高,zero-shot 能力更強,具有涌現能力
9. prefix Decoder:
10. 特點:prefix部分的token互相能看到,causal Decoder 和 Encoder-Decoder 折中;
11. 缺點:訓練效率低?
4. 大模型LLM的訓練目標是什么?
1. 語言模型 根據 已有詞 預測下一個詞,訓練目標為最大似然函數:

訓練效率:Prefix Decoder < Causal Decoder Causal Decoder 結構會在所有token 上計算損失,而 Prefix Decoder 只會在 輸出上 計算損失。
2. 去噪自編碼器 隨機替換掉一些文本段,訓練語言模型去恢復被打亂的文本段。
目標函數為:
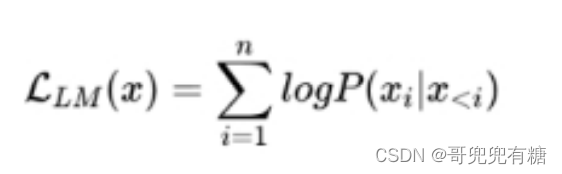
去噪自編碼器的實現難度更高。采用去噪自編碼器作為訓練目標的任務有GLM-130B、T5.
5. 涌現能力是啥原因?
根據前人分析和論文總結,大致是2個猜想:
1. 任務的評價指標不夠平滑;
2. 復雜任務 vs 子任務,這個其實好理解,比如我們假設某個任務 T 有 5 個子任務 Sub-T 構成,每個 sub-T 隨著模型增長,指標從 40% 提升到 60%,但是最終任務的指標只從 1.1% 提升到了 7%,也 就是說宏觀上看到了涌現現象,但是子任務效果其實是平滑增長的。
6.為何現在的大模型大部分是Decoder only結構?
????????因為decoder-only結構模型在沒有任何微調數據的情況下,zero-shot的表現能力最好。而encoderdecoder則需要在一定量的標注數據上做multitask-finetuning才能夠激發最佳性能。 目前的Large LM的訓練范式還是在大規模語料shang 做自監督學習,很顯然zero-shot性能更好的 decoder-only架構才能更好的利用這些無標注的數據。
???????? 大模型使用decoder-only架構除了訓練效率和工程實現上的優勢外,在理論上因為Encoder的雙向注意 力會存在低秩的問題,這可能會削弱模型的表達能力。就生成任務而言,引入雙向注意力并無實質的好處。而Encoder-decoder模型架構之所以能夠在某些場景下表現更好,大概是因為它多了一倍參數。所 以在同等參數量、同等推理成本下,Decoder-only架構就是最優的選擇了。
7. 大模型【LLMs】后面跟的 175B、60B、540B等指什么?
175B、60B、540B等:這些一般指參數的個數,B是Billion/十億的意思,175B是1750億參數,這是 ChatGPT大約的參數規模。
8. 大模型【LLMs】具有什么優點?
1. 可以利用大量的無標注數據來訓練一個通用的模型,然后再用少量的有標注數據來微調模型,以適 應特定的任務。這種預訓練和微調的方法可以減少數據標注的成本和時間,提高模型的泛化能力;
2. 可以利用生成式人工智能技術來產生新穎和有價值的內容,例如圖像、文本、音樂等。這種生成能 力可以幫助用戶在創意、娛樂、教育等領域獲得更好的體驗和效果;
3. 可以利用涌現能力(Emergent Capabilities)來完成一些之前無法完成或者很難完成的任務,例如 數學應用題、常識推理、符號操作等。這種涌現能力可以反映模型的智能水平和推理能力。
9. 大模型【LLMs】具有什么缺點?
1. 需要消耗大量的計算資源和存儲資源來訓練和運行,這會增加經濟和環境的負擔。據估計,訓練一 個GPT-3模型需要消耗約30萬美元,并產生約284噸二氧化碳排放;
2. 需要面對數據質量和安全性的問題,例如數據偏見、數據泄露、數據濫用等。這些問題可能會導致 模型產生不準確或不道德的輸出,并影響用戶或社會的利益;
3. 需要考慮可解釋性、可靠性、可持續性等方面的挑戰,例如如何理解和控制模型的行為、如何保證 模型的正確性和穩定性、如何平衡模型的效益和風險等。這些挑戰需要多方面的研究和合作,以確 保大模型能夠健康地發展。
八股文進階版:http://t.csdnimg.cn/5yxMO
)
)





中文版幫助手冊下載和自定義一般鍵盤快捷鍵)











