目錄
1、數據庫自增
2、Redis自增
3、Zookeeper
4、其他
4.1、雪花算法
4.2、Tinyid
4.3、Leaf
4.4、數據庫號段?
1、數據庫自增
利用數據庫表的自增特性,或主鍵唯一性,實現分布式ID
REPLACE INTO id_table (stub) values (’a‘) ;
SELECT LAST_INSERT_ID();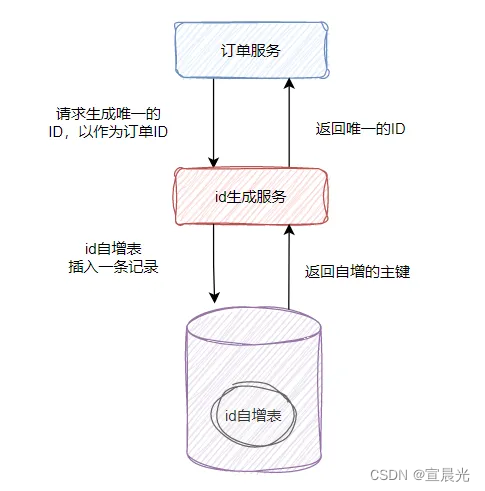
優點:
(1)單調遞增,不會影響數據庫的數據寫入性能。
(2)可讀性高。
缺點:
(1)ID生成涉及到數據庫操作,性能不高。
(2)需要額外引入中央數據庫,鏈路變長導致出錯概率增加。
(3)開發成本相對較高。
(4)數據庫壓力大。
2、Redis自增
Redis的自增命令incr生成全局唯一ID。具體實現方式是:在Redis中維護一個自增的計數器,每次生成ID時,從Redis中獲取計數器的值,然后將其加一并更新回Redis。
通過Redis的INCR自增命令來生成分布式ID。
127.0.0.1:6379> set distributed_id 1 // 將分布式ID初始化為1
OK
127.0.0.1:6379> incr distributed_id // +1,并返回結果
(integer) 2優點:
(1)單調遞增,不會影響數據庫的數據寫入性能。
(2)ID生成性能高。
(3)可讀性高。
缺點:
(1)需要額外引入Redis,鏈路變長導致出錯概率增加。
(2)Redis宕機后,RDB + AOF數據恢復較慢,需要Plan B提升恢復速度。
(3)開發成本相對較高。
3、Zookeeper
利用Zookeeper的順序節點特性來生成全局唯一ID。
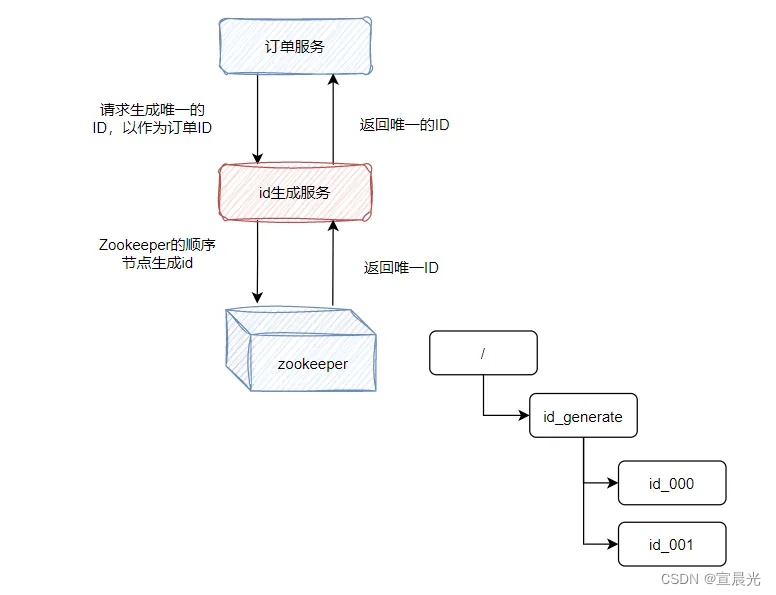
優點:
-
利用Zookeeper的集群特性保證高可用。
-
ID全局唯一。
缺點:
-
需要依賴Zookeeper集群。
-
可能會受到Zookeeper性能的限制。
-
并發競爭較大不適合用Zookeeper
4、其他
4.1、雪花算法
雪花算法是一種生成分布式全局唯一ID的算法,生成的ID稱為Snowflake IDs。這種算法由Twitter創建,并用于推文的ID。
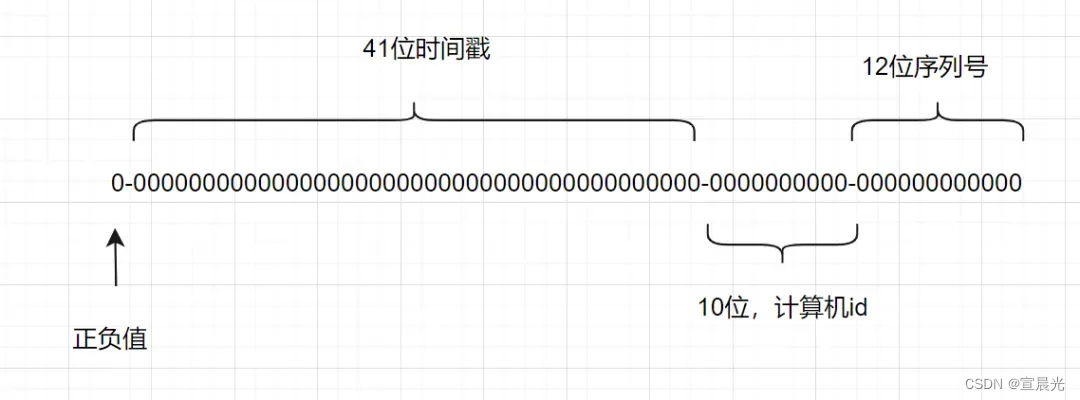
一個Snowflake ID有64位。
-
第1位:Java中long的最高位是符號位代表正負,正數是0,負數是1,一般生成ID都為正數,所以默認為0。
-
接下來前41位是時間戳,表示了自選定的時期以來的毫秒數。
-
接下來的10位代表計算機ID,防止沖突。
-
其余12位代表每臺機器上生成ID的序列號,這允許在同一毫秒內創建多個Snowflake ID。
Snowflake雪花算法的優點:
-
生成的ID全局唯一、趨勢遞增。
-
性能高,可擴展性強。
Snowflake雪花算法的缺點:
-
需要時鐘回撥處理機制。
-
依賴機器ID和數據中心ID的分配。
4.2、Tinyid
Tinyid是滴滴開源的輕量級分布式ID生成系統,它是基于號段模式原理實現的與Leaf如出一轍,每個服務獲取一個號段(1000,2000]、(2000,3000]、(3000,4000]
4.3、Leaf
Leaf是美團點評開源的分布式ID生成系統,包含基于數據庫和基于Zookeeper的兩種實現方式。以基于數據庫的自增ID生成策略為例(數據庫表結構):
CREATE TABLE leaf_alloc ( biz_tag VARCHAR(128) NOT NULL COMMENT '業務key', max_id BIGINT(20) NOT NULL COMMENT '當前已分配的最大id', step INT(11) NOT NULL COMMENT '每次id的增長步長', PRIMARY KEY (biz_tag)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4;4.4、數據庫號段?
數據庫號段,是在“數據庫自增ID”方案上做的優化,實現方式如下:
(1)從中央數據庫中獲取出一批分布式ID,并緩存到分布式ID服務本地,業務系統獲取分布式ID的時候,可直接在這個批次內遞增取值。
(2)若該批次分布式ID的號段用完,則需要更新數據庫中的初始值,再次獲取新批次的分布式ID,并重新緩存到分布式ID服務本地,以供使用。
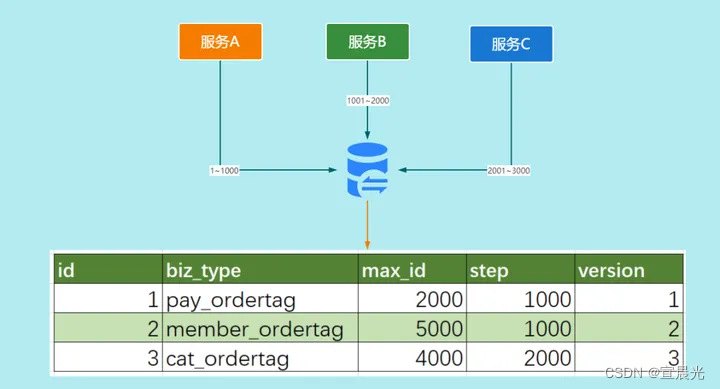
CREATE TABLE id_generator (id int(10) NOT NULL,max_id bigint(20) NOT NULL COMMENT '當前最大id',step int(10) NOT NULL COMMENT '號段的長度',biz_type int(10) NOT NULL COMMENT '業務類型',version int(10) NOT NULL COMMENT '版本號,是一個樂觀鎖,每次都更新version,保證并發時數據的正確性',PRIMARY KEY (`id`)
)優點:
(1)趨勢遞增,不會影響數據庫的數據寫入性能。
(2)ID生成性能高。
(3)數據庫壓力小。
(4)可讀性高。
缺點:
(1)開發成本很高。
(2)需要額外引入分布式ID服務和中央數據庫,鏈路變長導致出錯概率增加。











)



】磁盤管理與文件系統 LVM與磁盤配額(二))
)

![[MYSQL] MYSQL表的操作](http://pic.xiahunao.cn/[MYSQL] MYSQL表的操作)
