
前言
在前面的文章中,我們已經討論了 Channel 的概念和基本使用以及 Channel 的高階應用。這篇我們來看日常開發中更常用的Flow。
“冷流” 和 “熱流” 的本質
先來梳理一下所謂的 “冷流” 和 “熱流”。
核心概念
我們已經知道 Channel 是 “熱流”,而用 flow{} 構建器創建的 Flow 是 “冷流”(Flow 也有熱流形式,如 SharedFlow、
StateFlow,這個后面文章會詳細介紹)。
所謂的熱和冷,本質上是指"數據生產"和"數據消費"是否解耦為兩套獨立邏輯。
-
熱流:不依賴消費端,提前生產數據,即使沒有消費者也會持續工作
-
冷流:當有消費端觸發消費事件時,才開始生產數據,懶加載的思想
對比示例
讓我們通過代碼來直觀感受一下:
Channel(熱流)示例
suspend fun channelHotExample() {val channel = Channel<String>(Channel.BUFFERED)// 生產者開始工作,不管有沒有消費者val producer = GlobalScope.launch {repeat(3) { i ->delay(1000)channel.send("熱流數據-$i")println("\u001B[32m[Channel生產者] 數據已發送: 熱流數據-$i\u001B[0m")}channel.close()}// 等待2秒后才開始消費delay(2500)println("\u001B[34m[Channel消費者] 2秒后開始消費...\u001B[0m")for (data in channel) {println("\u001B[34m[Channel消費者] 收到: $data\u001B[0m")}producer.join()
}

Flow(冷流)示例
Flow 的創建和收集很簡單:用 flow {} 創建,用 collect 收集。
suspend fun flowColdExample() {// 定義Flow,但此時還沒有開始生產數據val flow = flow {repeat(3) { i ->delay(1000)println("\u001B[32m[Flow生產者] 數據開始發送: 冷流數據-$i\u001B[0m")emit("冷流數據-$i")println("\u001B[32m[Flow生產者] 數據發送完畢: 冷流數據-$i\u001B[0m")println()}}println("\u001B[36mFlow已定義,但還沒有開始生產數據\u001B[0m")println()delay(2000)println("\u001B[34m[Flow消費者] 開始收集,此時才開始生產數據...\u001B[0m")flow.collect { data ->println("\u001B[34m[Flow消費者] 收到: $data\u001B[0m")// 模擬處理邏輯delay(500)println("\u001B[34m[Flow消費者] 數據處理完畢: $data...\u001B[0m")}
}

熱流 vs 冷流對比
| 特性 | 熱流 | 冷流 |
|---|---|---|
| 數據生產 | 立即開始,不管有沒有消費者 | 只有在被收集時才開始生產 |
| 數據共享 | 多個消費者共享同一份數據 | 每個收集器都有獨立的數據流 |
| 資源消耗 | 持續消耗資源 | 按需消耗資源 |
| 背壓處理 | 通過緩沖區和掛起機制 | 天然支持背壓,生產速度跟隨消費 |
| 生命周期 | 獨立于消費者 | 與收集器生命周期綁定 |
| 內存使用 | 需要緩沖區存儲數據 | 按需生產,內存友好 |
Flow 的基本使用
Flow 的創建有多種方式,不同方式背后的實現原理和適用場景也不同。
flow 構建器
flow{} 構建器是最常用的也是很重要的一種方式。后面提到的 flowOf、asFlow、以及 channelFlow,本質上都是對 flow{}
的封裝或擴展。
使用示例
先來看個最簡單的例子:
suspend fun basicFlowBuilder() {val numberFlow = flow {repeat(5) { i ->delay(500)emit(i) // 發射數據}}numberFlow.collect { value ->println("[消費者] 收到: $value")}
}
使用起來非常簡單,用
flow{}創建,用collect收集即可。
flowOf
當你有一組已知的靜態數據需要轉成 Flow,flowOf 最方便:
suspend fun flowOfExample() {val staticFlow = flowOf("Apple", "Banana", "Cherry")staticFlow.collect { fruit ->println("[消費者] 水果: $fruit")}}源碼
// Flow.kt
public fun <T> flowOf(vararg elements: T): Flow<T> = flow {for (element in elements) {emit(element)}
}可以看到,flowOf 本質就是對 flow 的封裝:遍歷所有元素并逐個 emit。
asFlow 擴展函數
將各類數據結構直接轉換為 Flow

示例:
suspend fun asFlowExample() {
// 集合轉Flowval listFlow = listOf(1, 2, 3, 4, 5).asFlow()listFlow.collect { number ->println("\u001B[34m[消費者] 數字: $number\u001B[0m")}// 區間轉Flowval rangeFlow = (1..3).asFlow()rangeFlow.collect { value ->println("\u001B[34m[消費者] 區間值: $value\u001B[0m")}// 數組轉Flowval arrayFlow = arrayOf("A", "B", "C").asFlow()arrayFlow.collect { letter ->println("\u001B[34m[消費者] 字母: $letter\u001B[0m")}}
源碼
// Iterable -> Flow
public fun <T> Iterable<T>.asFlow(): Flow<T> = flow {forEach { value ->emit(value)}
}// Array -> Flow
public fun <T> Array<T>.asFlow(): Flow<T> = flow {forEach { value ->emit(value)}
}核心特點:同步轉換、按需發射、內存友好。
Flow 源碼分析
Flow 內部的實現還是很有意思的, 我們就基于上述示例代碼結合源碼進行分析,來看一看 flow 內部的執行流程。
1. 創建階段
例如:
val numberFlow = flow {repeat(5) { i ->delay(500)emit(i)}
}flow{}
public fun <T> flow(@BuilderInference block: suspend FlowCollector<T>.() -> Unit): Flow<T> = SafeFlow(block)
-
參數類型:
suspend FlowCollector<T>.() -> Unit(一個可掛起的擴展函數類型) -
返回值:返回
SafeFlow
FlowCollector
public fun interface FlowCollector<in T> {/*** Collects the value emitted by the upstream.* This method is not thread-safe and should not be invoked concurrently.*/public suspend fun emit(value: T)
}
可以看到,FlowCollector 接口提供了 emit 方法,因此我們才能在 flow{} 代碼塊里直接調用 emit(),因為這個代碼塊本身就是FlowCollector 的擴展函數。
SafeFlow
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {override suspend fun collectSafely(collector: FlowCollector<T>) {collector.block()//這里的 block,實際上就是我們寫的生產邏輯的代碼塊}
}
關鍵點:
flow { ... }返回SafeFlow實例- 傳入的
block實際就是我們寫的生產邏輯代碼塊 - 此時生產邏輯并沒有被執行,等待
collectSafely被調用后才會執行生產邏輯
2. 收集階段
numberFlow.collect { value ->println("[消費者] 收到: $value")
}
numberFlow 是 SafeFlow 的實例
AbstractFlow.collect()
SafeFlow 繼承自 AbstractFlow,當我們調用 numberFlow.collect 時,實際上是走到了 AbstractFlow.collect()
// kotlinx-coroutines-core/common/src/flow/AbstractFlow.kt
public abstract class AbstractFlow<T> : Flow<T>, CancellableFlow<T> {/*** 這里的 collector,就是我們寫的消費邏輯的代碼塊*/public final override suspend fun collect(collector: FlowCollector<T>) {// 創建 SafeCollector ,并且把消費邏輯代碼塊作為參數傳遞進去val safeCollector = SafeCollector(collector, coroutineContext)try {//調用實現類(SafeFlow)的collectSafely,此時的safeCollector是包含了消費邏輯代碼塊的collectSafely(safeCollector)} finally {safeCollector.releaseIntercepted()}}
}
關鍵點:
safeCollector創建時,把collector傳入,并且把collector包裝成SafeCollector,也就是保存了消費邏輯代碼塊- 然后,調用了
collectSafely,這里會走到實現類(SafeFlow)的collectSafely
SafeFlow.collectSafely()
//這里的 block 參數上面說過了,是我們生產邏輯的代碼塊
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {//這里的collector,則是把消費邏輯包裝后的SafeCollector,當觸發 collect 后,會觸發生產邏輯,此時,collector也是包含消費邏輯了的。override suspend fun collectSafely(collector: FlowCollector<T>) {collector.block()}
}關鍵點:
-
collector.block()中的collector是SafeCollector實例 -
block是我們寫的生產邏輯(flow { ... }中的代碼),也就是示例中的:
repeat(5) { i ->delay(500)emit(i)
}當執行到 emit(i) 時,實際上調用的是 SafeCollector.emit(i)。
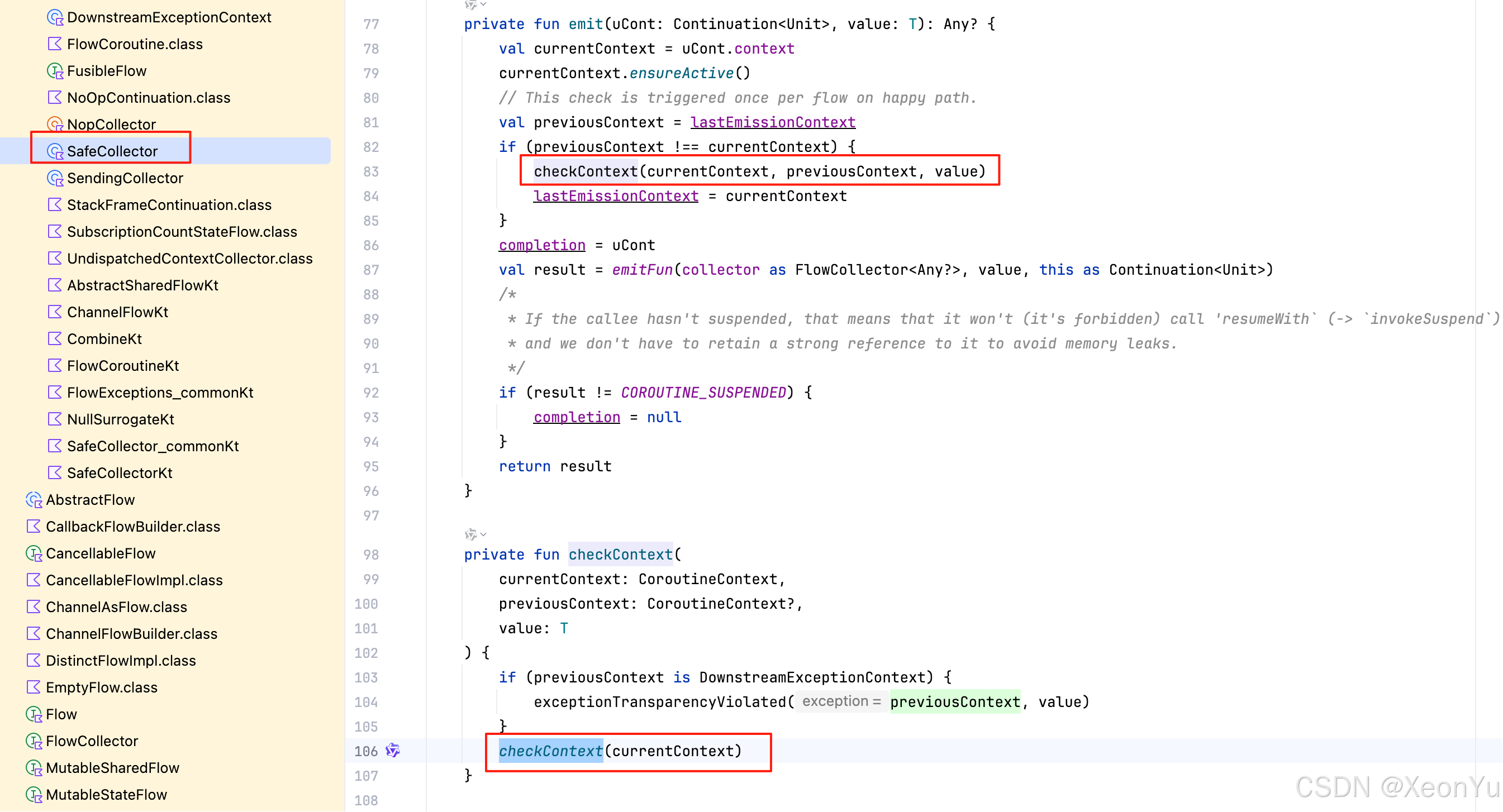
SafeCollector.emit()
internal actual class SafeCollector<T> actual constructor(@JvmField internal actual val collector: FlowCollector<T>,//保存的消費代碼塊@JvmField internal actual val collectContext: CoroutineContext
) : FlowCollector<T>, ContinuationImpl(NoOpContinuation, EmptyCoroutineContext), CoroutineStackFrame {/*** This is a crafty implementation of state-machine reusing.* First it checks that it is not used concurrently (which we explicitly prohibit) and* then just cache an instance of the completion in order to avoid extra allocation on each emit,* making it effectively garbage-free on its hot-path.*/override suspend fun emit(value: T) {return suspendCoroutineUninterceptedOrReturn sc@{ uCont ->try {emit(uCont, value)//執行下面的私有方法} catch (e: Throwable) {// Save the fact that exception from emit (or even check context) has been thrown// Note, that this can the first emit and lastEmissionContext may not be saved yet,// hence we use `uCont.context` here.lastEmissionContext = DownstreamExceptionContext(e, uCont.context)throw e}}}private fun emit(uCont: Continuation<Unit>, value: T): Any? {val currentContext = uCont.contextcurrentContext.ensureActive()//檢查協程是否處于活躍狀態// This check is triggered once per flow on happy path.//上下文檢查,flow 不允許跨協程發送數據,這個后面會講到val previousContext = lastEmissionContextif (previousContext !== currentContext) {checkContext(currentContext, previousContext, value)lastEmissionContext = currentContext}completion = uCont//真正執行消費的地方:collector 是我們寫的消費邏輯代碼塊,value 就是 生產邏輯中發送的數據val result = emitFun(collector as FlowCollector<Any?>, value, this as Continuation<Unit>)/** If the callee hasn't suspended, that means that it won't (it's forbidden) call 'resumeWith` (-> `invokeSuspend`)* and we don't have to retain a strong reference to it to avoid memory leaks.*/if (result != COROUTINE_SUSPENDED) {completion = null}return result}
}
關鍵點:
SafeCollector保存了消費邏輯代碼塊,也就是參數collectoremit最終會調用到emitFunemitFun(collector, value, this)中的collector是我們傳入的消費邏輯代碼塊,就是示例代碼中的
{ value -> println("[消費者] 收到: $value") }
emitFun
@Suppress("UNCHECKED_CAST")
private val emitFun =FlowCollector<Any?>::emit as Function3<FlowCollector<Any?>, Any?, Continuation<Unit>, Any?>這里要轉換來看
// emitFun 的類型是 Function3<FlowCollector<Any?>, Any?, Continuation<Unit>, Any?>
// 相當于下面代碼:
fun emitFun(collector: FlowCollector<Any?>, value: Any?, completion: Continuation<Unit>): Any? {return collector.emit(value, completion) // 調用消費者的 emit 方法
}
當執行 emitFun(collector, value, this) 時:
-
collector是我們的消費邏輯({ value -> println("收到: $value") }) -
value是數據(比如 0, 1, 2) -
this是 SafeCollector 自己作為Continuation
我們的消費邏輯代碼塊實際上就是一個 FlowCollector 的實現
// 當我們寫 collect { value -> println("收到: $value") } 時
// 實際上創建了一個匿名類,實現了 FlowCollector 接口:val consumer = object : FlowCollector<Int> {override suspend fun emit(value: Int) {println("收到: $value") // 我們的消費邏輯}
}
所以當調用 emitFun(collector, value, completion) 時,實際上是在調用我們的消費邏輯
換句話說,當我們調用 emit 時,相當于是把 emit() 替換為消費代碼塊里的代碼。
例如:
suspend fun basicFlowBuilder() {val numberFlow = flow {repeat(5) { i ->delay(500)emit(i) // 發射數據}}numberFlow.collect { value ->println("[消費者] 收到: $value")}
}
就相當于:
suspend fun basicFlowBuilder() {repeat(5) { i ->delay(500)println("[消費者] 收到: $value")//消費代碼塊替換掉 emit}
}
整體執行流程
1.numberFlow.collect { value -> println("[消費者] 收到: $value") }
↓
2.AbstractFlow.collect(collector) 被調用-collector = { value -> println("[消費者] 收到: $value") }(我們的消費邏輯)
↓
3.SafeCollector(collector, coroutineContext) 被創建-SafeCollector.collector = 我們的消費邏輯
-SafeCollector 自己也實現了 FlowCollector<T>
↓
4.SafeFlow.collectSafely(safeCollector) 被調用-safeCollector 是 SafeCollector 實例
↓
5.safeCollector.block() 執行-block 是我們的生產邏輯 : repeat (5) { i -> delay(500); emit(i) }
-當執行到 emit (i) 時 , 調用 SafeCollector.emit(i)
↓
6.SafeCollector.emit(i) 執行-檢查上下文一致性
-調用 emitFun (SafeCollector.collector, i, continuation)
-SafeCollector.collector 就是我們的消費邏輯
↓
7.我們的消費邏輯被執行:println("[消費者] 收到: $i")
↓
8.繼續下一次循環,直到 repeat(5) 完成
總結
-
SafeFlow負責執行生產邏輯,SafeCollector負責執行消費邏輯。 -
collector.block()中的collector是SafeCollector實例,保存了消費邏輯代碼塊 -
block是我們的生產邏輯(flow { ... }中的代碼) -
當生產邏輯調用
emit(value)時,會觸發SafeCollector.emit(value) -
SafeCollector.emit(value)最終會調用我們傳入的消費邏輯
以上就是 Flow 內部的實現機制。這就是為什么說 Flow 是"冷流",因為生產邏輯只有在被收集時才開始執行,而且每次收集都是全新的執行。
到這里,Flow 內部的執行機制就搞明白了。
Flow 的重要限制
在看其他創建方式之前,先明確一個非常重要的限制:Flow 不允許在不同協程中調用 emit()。
示例
suspend fun wrongConcurrentEmitExample() {val errorFlow = flow {println("\u001B[32m[主協程] 開始創建Flow\u001B[0m")//在新協程中調用emitlaunch {delay(1000)emit("來自子協程的數據") // 這里會拋出異常!}emit("正常數據") // 這個是正常的}try {errorFlow.collect { data ->println("\u001B[34m[消費者] 收到: $data\u001B[0m")}} catch (e: Exception) {println("\u001B[31m[異常] ${e.message}\u001B[0m")}
}

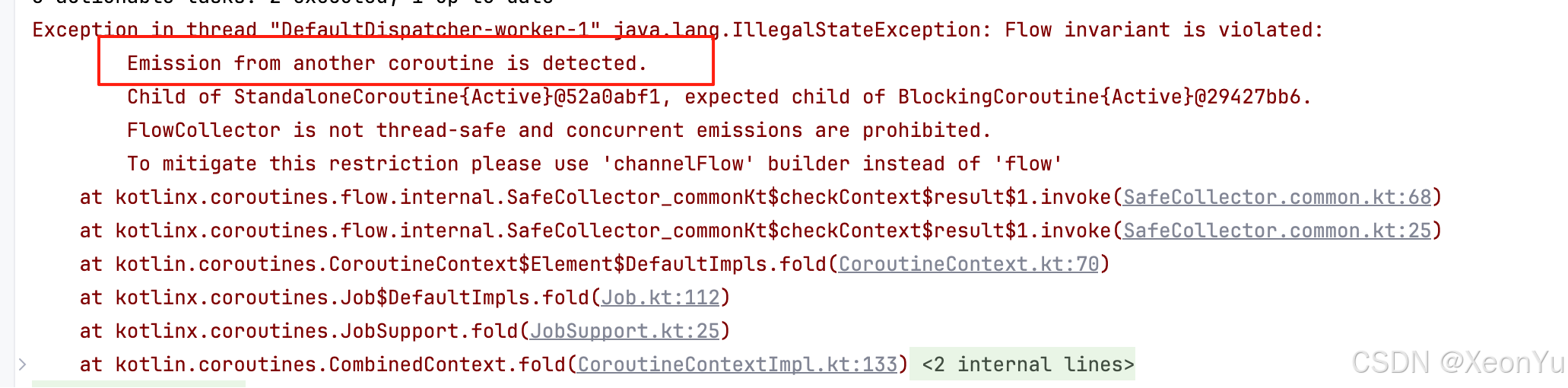
拋出的異常表明:FlowCollector 不是線程安全的,禁止并發發送數據。
報錯堆棧:
SafeCollector 的檢查機制
collect 內部會構建 SafeCollector,這個我們前面分析源碼的時候已經知道了

SafeCollector 在執行 emit 時會檢查上下文:
當協程上下文不一致時,會拋出異常:
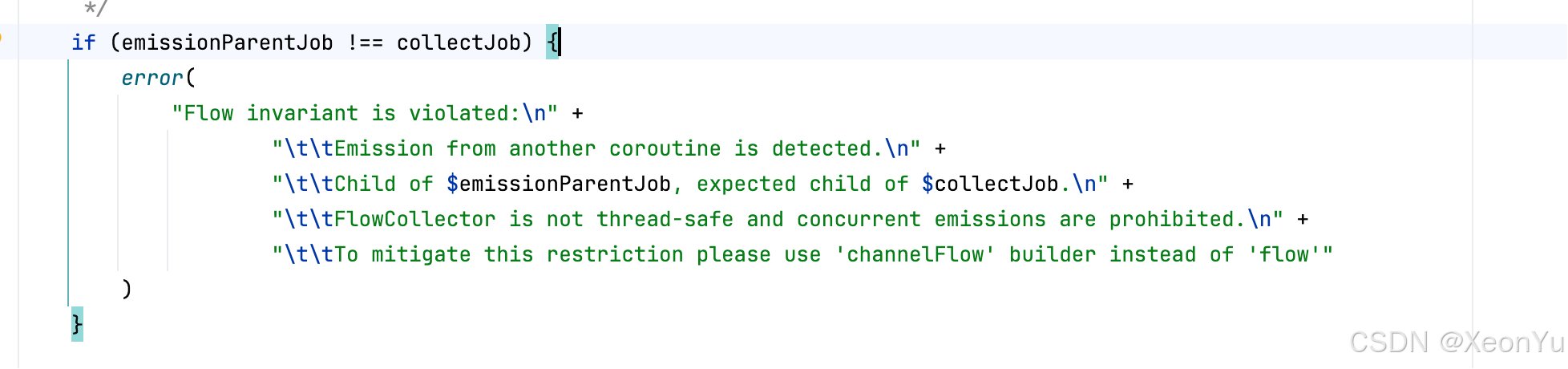
關鍵代碼:
if (emissionParentJob !== collectJob) {error("Flow invariant is violated:\n" +"\t\tEmission from another coroutine is detected.\n" +"\t\tChild of $emissionParentJob, expected child of $collectJob.\n" +"\t\tFlowCollector is not thread-safe and concurrent emissions are prohibited.\n" +"\t\tTo mitigate this restriction please use 'channelFlow' builder instead of 'flow'")
}
關鍵點:
emit發生時的Job必須與collect的Job一致(或為其子層級)。因此在另一協程中調用emit會觸發異常。
為什么要有這個限制?
根因在于 Flow 的冷流本質。
冷流的設計理念
Flow 是冷流,每次 collect 都會重新執行 flow{} 代碼塊,就像一次函數調用:
-
調用者(collect)與被調用者(flow{})在同一執行上下文中
-
生產與消費是同步協作,而非并發競爭
-
過程需要順序、可預測
協程上下文的一致性
在 Flow 中,emit 的協程上下文應當與 collect 保持一致。否則:
-
上下文一致性被破壞,可能產生線程切換問題
-
異常無法被正確傳播到消費者
-
取消機制失效,子協程取消無法正確傳遞
源碼分析的時候也提到過,emit() 的代碼相當于是把消費邏輯代碼塊給替換掉 emit(),如果說 Flow
生產邏輯可以跨協程并發執行,那么,消費邏輯邏輯代碼塊就會出現跟預期不符的邏輯。
例如,我原本在消費邏輯默認是在主線程中運行,如果可以跨協程 emit,例如,切到了 IO 線程,那么,消費邏輯就會跑到 emit
所在的IO線程中執行,無法保證上下文一致。
總結
Flow 在使用上還是很簡單的,關鍵是要搞清楚概念特性以及底層實現原理,以及結合特性用在合適的場景中去。
核心原則:Flow 是用來處理數據流的,如果你的場景是一次性的數據獲取,直接用 suspend fun 就夠了。記住,合適的工具做合適的事情,這樣代碼才會既清晰又高效。
Flow 雖然在生產端存在限制,不能跨協程并發地生產數據,但 Kotlin 還給我們提供了其他的解決方案,具備更加靈活的生產端。下一篇文章,我們將深入探討如何突破Flow 的限制,看看 Channel 與 Flow 的結合之道。
好了, 本篇文章就是這些,希望能幫到你。下一篇:突破 Flow 限制:Channel 與 Flow 的結合之道
感謝閱讀,如果對你有幫助請三連(點贊、收藏、加關注)支持。有任何疑問或建議,歡迎在評論區留言討論。如需轉載,請注明出處:喻志強的博客



變換記錄)
三極管)




)

:Open-WebUI的安裝)

細節)

)
 的原理和流程)


: 什么是機器學習)