文章目錄
- 前言
- 一、數據異構的常用方法
- 1. 完整克隆
- 2. MQ方式
- 3. binlog方式
- 二、MQ與Binlog方案實現
- MQ方式
- binlog方式
- 注意點
- 三、總結
前言
何謂數據異構:把數據按需(數據結構、存取方式、存取形式)異地構建存儲。比如我們將DB里面的數據持久化到Redis或者ES里面去,就是一種數據異構的方式。
常見應用場景
分庫分表中有一個最為常見的場景,為了提升數據庫的查詢能力,我們都會對數據庫做分庫分表操作。比如訂單庫,開始的時候我們是按照訂單ID作為分片鍵去分庫分表,后來的業務需求想按照商家維度去查詢,比如想查詢某一個商家下的所有訂單,就非常麻煩。
這個時候通過數據異構就能很好的解決此問題,如下圖:
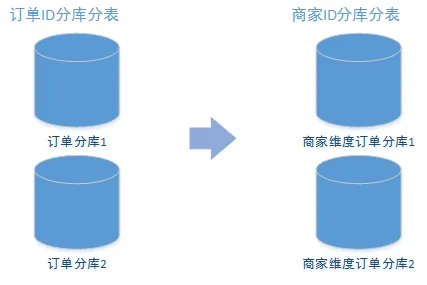
異構維度
數據異構總結起來大概有以下幾種場景
- 數據庫鏡像(DB→DB)
- 數據庫實時備份
- 多級索引(DB→ClickHouse)
- search build(比如分庫分表后的多維度數據查詢)(DB→ES)
- 業務cache刷新(DB→Redis)
- 價格、庫存變化等重要業務消息
數據異構方向
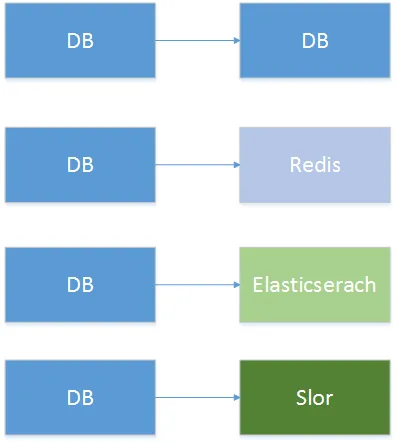
異構的幾種方向
在日常業務開發中大致可以分為以上幾種數據去向,DB-DB這種方式,一般常見于分庫分表后,聚合查詢的時候,比如我們按照訂單ID去分庫分表,那么這個時候我們要按照用戶ID去查詢,查詢這個用戶下面的訂單就非常不方便了(因為分庫分表后的查詢where條件必須帶分片鍵),當然可以使用統一加到內存中去,但這樣不太好。
所以我們就可以用數據庫異構的方式,重新按照用戶ID的維度來分一個表,像在上面常見應用場景中介紹的那樣。把數據異構到redis、elasticserach、slor中去要解決的問題跟按照多維度來查詢的需求差不多。這些存儲天生都有聚合的功能。當然同時也可以提高查詢性能,應對大訪問量,比如redis這種抗量銀彈。
一、數據異構的常用方法
1. 完整克隆
這個很簡單就是將數據庫A,全部拷貝一份到數據庫B,這樣的使用場景是離線統計跑任務腳本的時候可以,如MySQL→Hive,用于離線數據業務。缺點也很突出,不適用于持續增長的數據。
2. MQ方式
業務數據寫入DB的同時,也發送MQ一份,也就是業務里面實現雙寫。這種方式比較簡單,但也很難保證數據一致性,對簡單的業務場景可以采用這種方式。
3. binlog方式
通過實時的訂閱MySQL的binlog日志,消費到這些日志后,重新構建數據結構插入一個新的數據庫或者是其他存儲,比如es、slor等等。訂閱binlog日志可以比較好的能保證數據的一致性。
二、MQ與Binlog方案實現
MQ方式
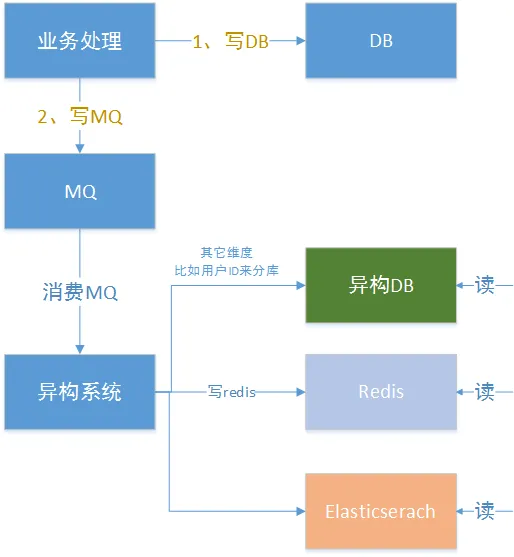
mq的方式,相對簡單,實際上是在業務邏輯中寫DB的同時去寫一次MQ,但是這種方式不能夠保證數據一致性,就是不能保證跨資源的事務,因為MQ可能出現消息堆積、重復消息、消息丟失等問題。
注:調用第三方遠程RPC的操作一定不要放到事務中。否則可能造成大事務問題,影響程序性能
binlog方式
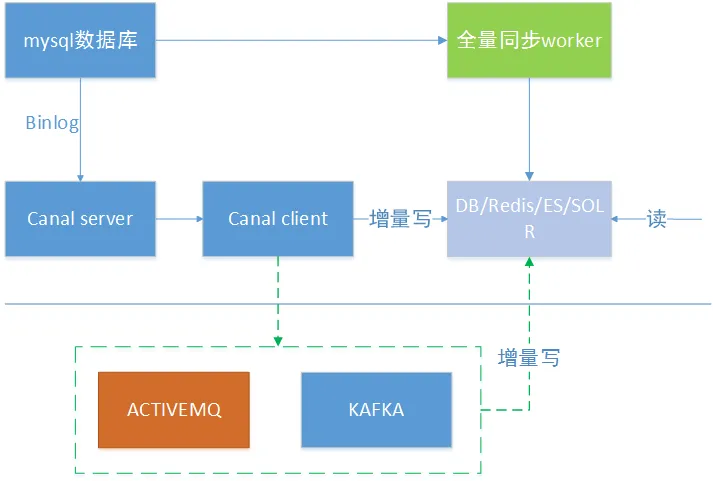
canal異構方式
binglog是數據的日志記錄方式,每次對數據的操作都會有binlog日志。現在有很多開源的訂閱binlog日志的組件,比如使用比較廣泛的canal,它是阿里開源的基于mysql數據庫binlog的增量訂閱和消費組件。
由于canal服務器目前讀取的binlog事件只保存在內存中,并且只有一個canal客戶端可以進行消費。所以如果需要多個消費客戶端,可以引入activemq或者kafka。如上圖綠色虛線框部分。
我們還需要確保全量對比來保證數據的一致性(canal+mq的重試機制基本可以保證寫入異構庫之后的數據一致性),這個時候可以有一個全量同步WORKER程序來保證,如上圖深綠色部分。
canal的工作原理
先來看下mysql主備(主從)復制原理如下圖,在此原理基礎之上我們再來理解canal的實現原理就一眼能明白了。
mysql主備復制實現原理
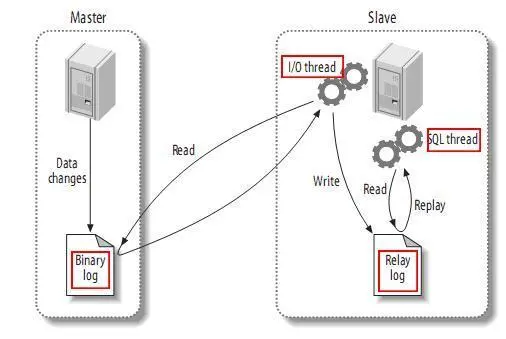
mysql主備(主從)復制原理,從上層來看,復制分成三步:
-
master將改變記錄到二進制日志(binary log)中(這些記錄叫做二進制日志事件,binary log events,可以通過show binlog events進行查看); -
slave將master的binary log events拷貝到它的中繼日志(relay log); -
slave重做中繼日志中的事件,將改變反映到它自己的數據。
再來看下canal的原理,如下圖:
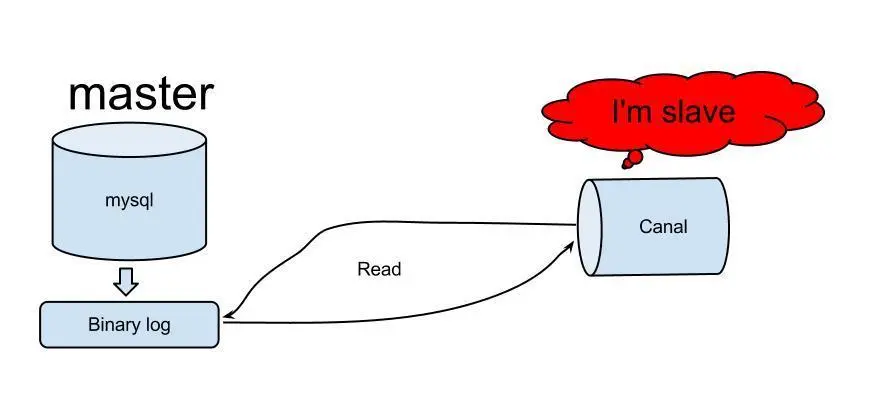
cannal實現原理相對比較簡單(參照上面的mysql主備復制實現原理):
-
canal模擬mysql slave的交互協議,偽裝自己為mysql slave,向mysql master發送dump協議 -
mysql master收到dump請求,開始推送binary log給slave(也就是canal) -
canal解析binary log對象(原始為byte流)
我們在部署canal server的時候要部署多臺,來保證高可用。但是canal的原理,是只有一臺服務器在跑處理,其它的服務器作為熱備。canal server的高可用是通過zookeeper來維護的。
有關canal更具體的使用和詳細原理請參照:https://github.com/alibaba/canal
注意點
- 確認
MySQL開啟binlog,使用show variables like 'log_bin';查看ON為已開啟,一般都是已經開啟的 - 確認目標庫可以產生
binlog,show master status注意Binlog_Do_DB,Binlog_Ignore_DB參數 - 確認
binlog格式為ROW,使用show variables like 'binlog_format';非ROW模式則可以登錄MySQL執行set global binlog_format=ROW; flush logs;或者通過更改MySQL配置文件并重啟MySQL生效。 - 為保證
binlake服務可以獲取Binlog,需添加授權,執行GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'admin'@'%' identified by 'admin'; FLUSH PRIVILEGES;
三、總結
本文主要敘述了數據異構的使用場景,方法。這里面涉及到的kafka以及canal并沒有深入分析,關于這塊的內容可以直接參考相關具體文檔,文中已給了鏈接地址。
根據數據異構的定義,將數據異地構建存儲,我們可以應用的地方就非常多,文中說的分庫分表之后按照其它維度來查詢的時候,我們想脫離DB直接用緩存比如redis來抗量的時候。數據異構這種方式都能夠很好的幫助我們來解決諸如此類的問題。







)


)

容器作用是什么?)




復習筆記)

)