Linux多線程系列三: 生產者消費者模型,信號量,基于阻塞隊列和環形隊列的這兩種生產者消費者代碼的實現
- 一.生產者消費者模型的理論
- 1.現實生活中的生產者消費者模型
- 2.多線程當中的生產者消費者模型
- 3.理論
- 二.基于阻塞隊列的生產者消費者模型的基礎代碼
- 1.阻塞隊列的介紹
- 2.大致框架
- 1.BlockQueue.hpp
- 2.cp_based_block_queue.cpp
- 3.LockGuard.hpp
- 3.BlockQueue.hpp的編寫
- 4.測試代碼的編寫
- 5.演示
- 三.基于阻塞隊列的生產者消費者模型的擴展代碼
- 1.傳遞任務版本
- 1.Task.hpp
- 2.測試代碼
- 3.演示
- 2.多生產者多消費者版本
- 1.改測試代碼
- 四.生產者消費者模型的再一次理解與阻塞隊列版本的優劣
- 1.多執行流解耦
- 2.提高效率
- 3.小結一下
- 五.信號量的深入理解與使用
- 1.理論
- 2.接口介紹
- 六.基于環形隊列的單生產者單消費者模型
- 1.思路
- 2.基礎代碼
- 1.RingQueue.hpp
- 1.結構
- 2.代碼
- 3.細節
- 3.擴展代碼
- 七.基于環形隊列的多生產者多消費者模型
- 1.先申請信號量,后申請鎖的原因
- 2.RingQueue代碼
- 3.測試
- 八.基于環形隊列的生產者消費者模型與基于阻塞隊列的生產者消費者模型的對比
學習了同步與互斥之后,我們來學一下應用同步與互斥的一個非常重要的模型:生產者消費者模型
一.生產者消費者模型的理論
1.現實生活中的生產者消費者模型
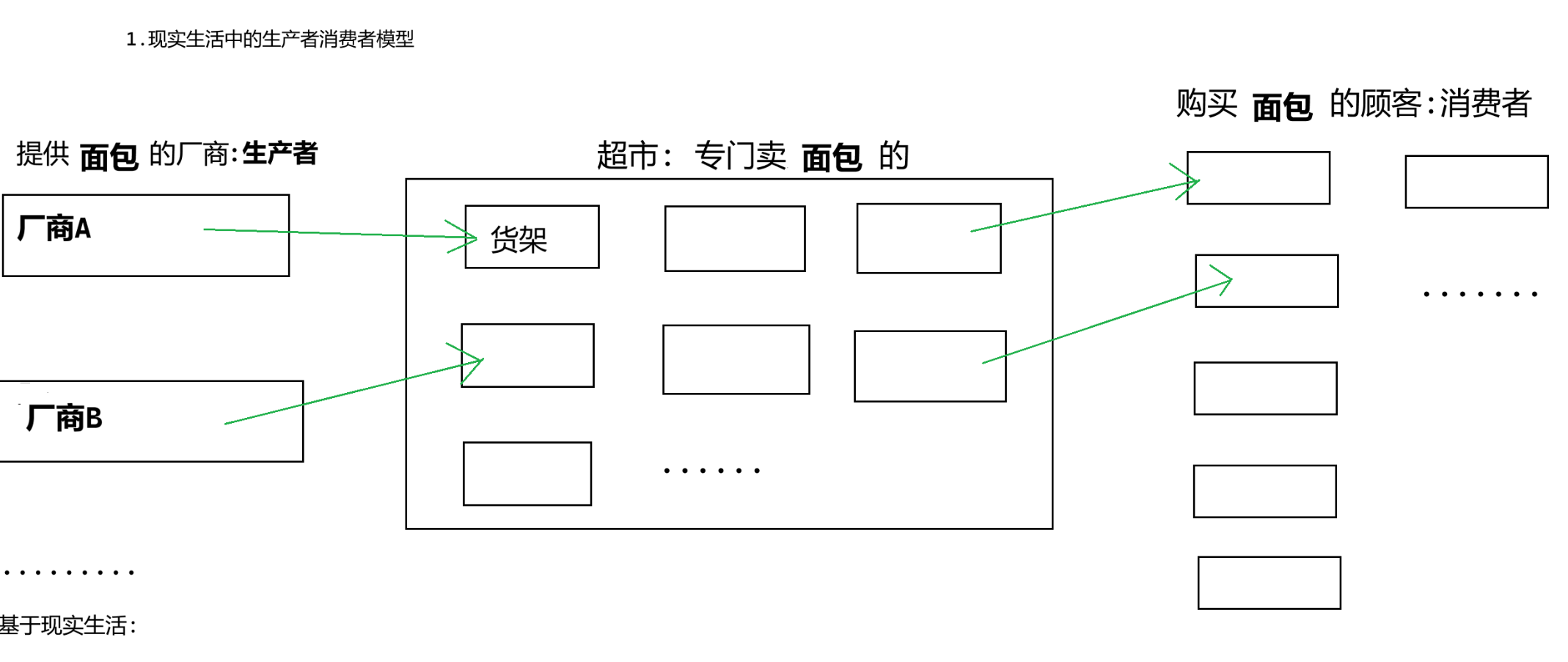
我們理解一下它們之間的關系

2.多線程當中的生產者消費者模型
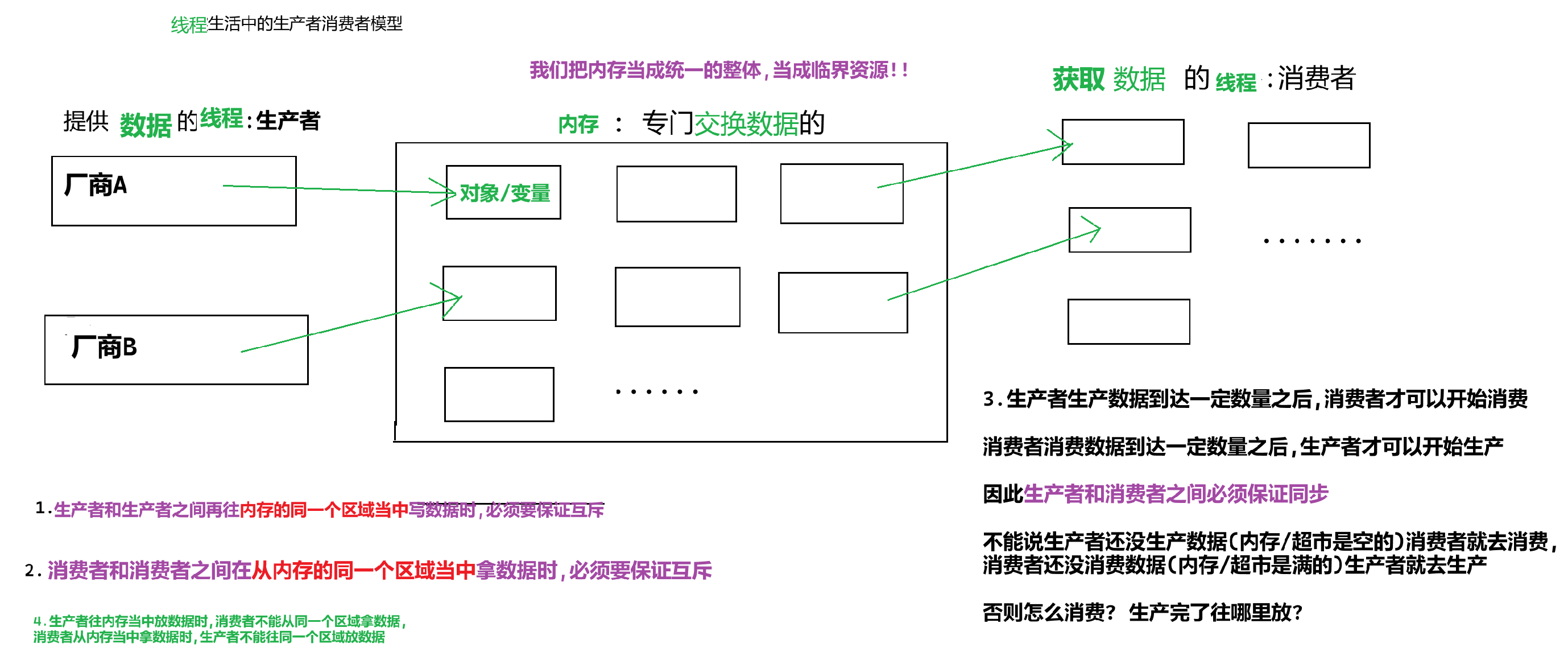
3.理論

大家目前就先記住三種關系即可,知道目的和如何實現
然后我們直接開始寫代碼,寫完擴展代碼之后在解釋原因
二.基于阻塞隊列的生產者消費者模型的基礎代碼
1.阻塞隊列的介紹

2.大致框架
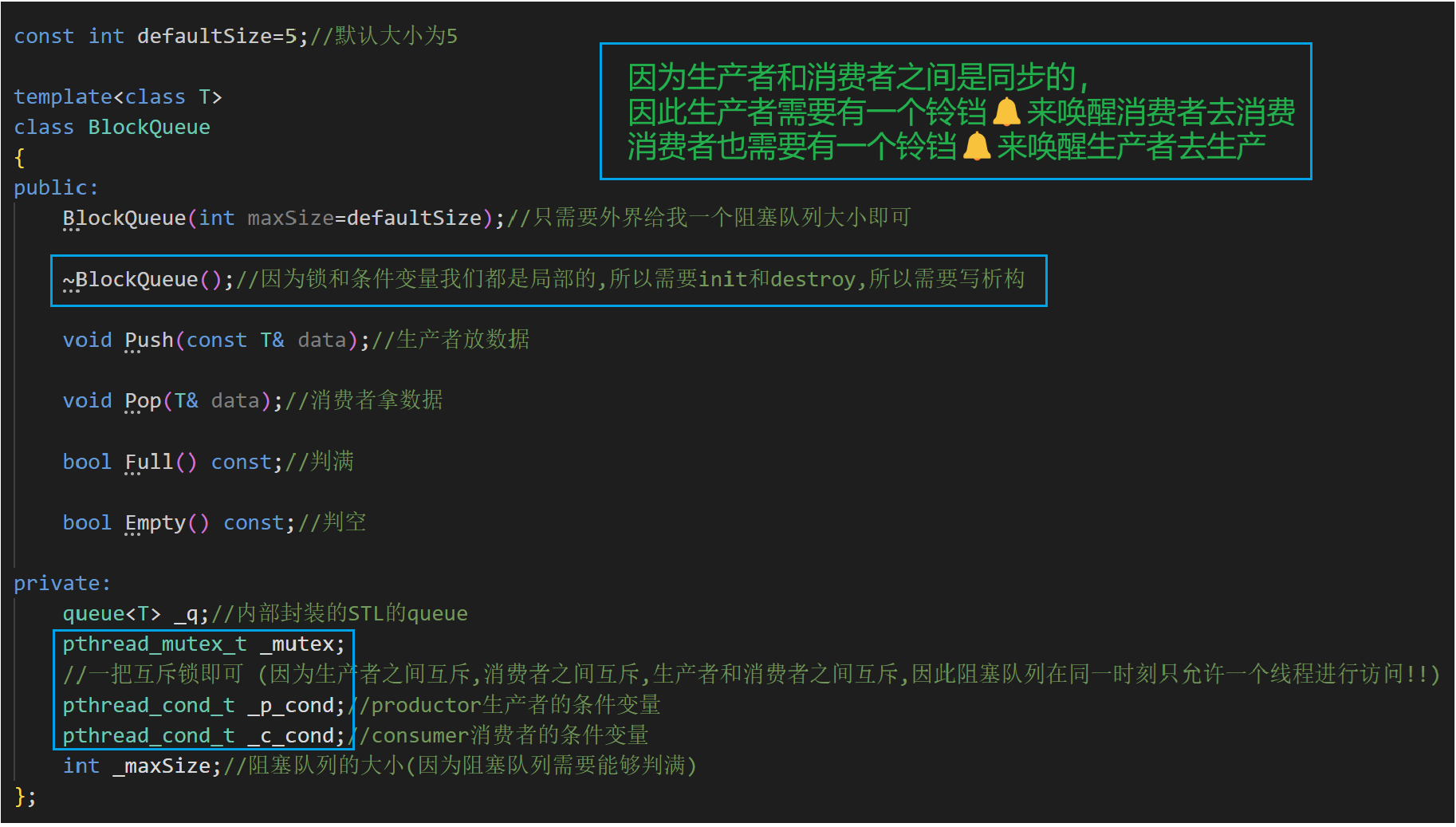
1.BlockQueue.hpp
不要忘了條件變量是🔔哦
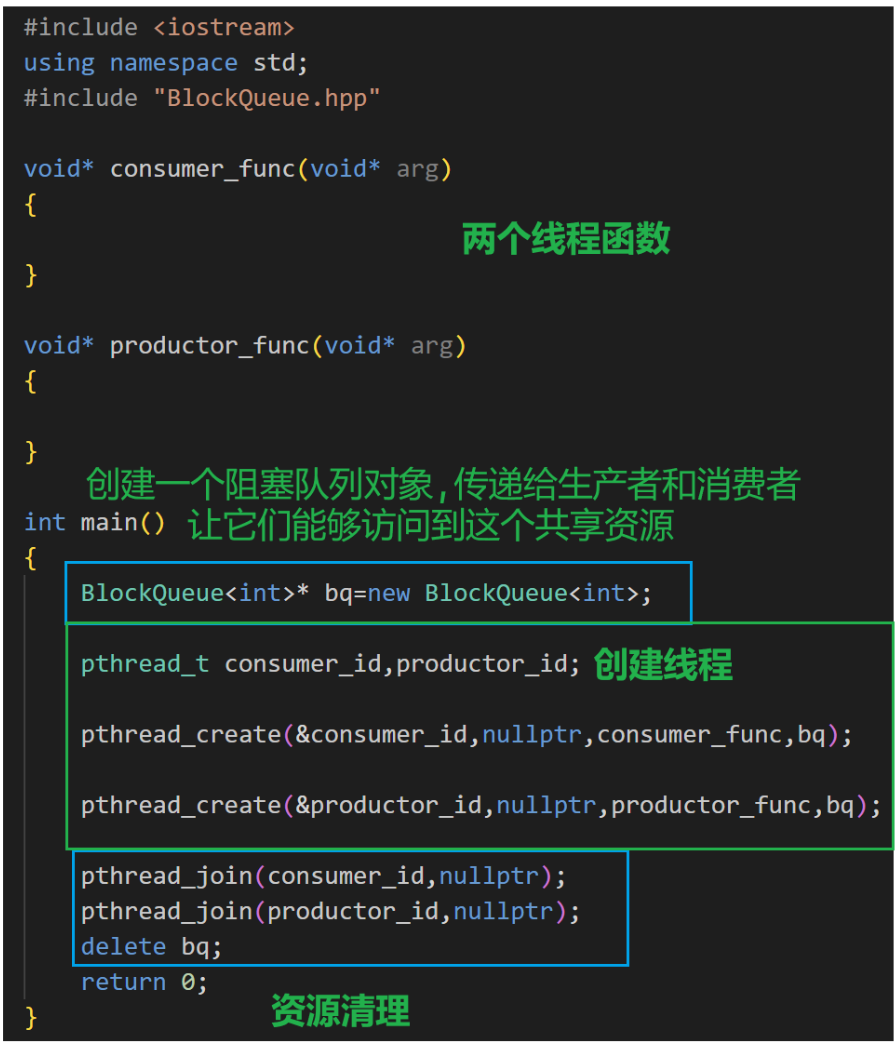
2.cp_based_block_queue.cpp
c:consumer
p:productor
基于阻塞隊列的cp模型
3.LockGuard.hpp
#pragma once
//構造: 申請鎖
//析構: 釋放鎖
class LockGuard
{
public:LockGuard(pthread_mutex_t* lock):pmutex(lock){pthread_mutex_lock(pmutex);}~LockGuard(){pthread_mutex_unlock(pmutex);}
private:pthread_mutex_t* pmutex;
};
這是我們之前利用RAII思想封裝的鎖的守衛者/聰明的鎖,我們先不用它,最后再用(因為它太好用了,好用到不方便解釋)
3.BlockQueue.hpp的編寫

下面就剩下Push和Pop了

代碼:
#pragma once
#include <pthread.h>
#include <queue>
#include "Lock_guard.hpp"
const int defaultSize=5;//默認大小為5template<class T>
class BlockQueue
{
public:BlockQueue(int maxSize=defaultSize)//工作: 初始化鎖,條件變量,_maxSize:_maxSize(maxSize){pthread_mutex_init(&_mutex,nullptr);pthread_cond_init(&_c_cond,nullptr);pthread_cond_init(&_p_cond,nullptr);}~BlockQueue()//釋放: 初始化鎖,條件變量{pthread_mutex_destroy(&_mutex);pthread_cond_destroy(&_c_cond);pthread_cond_destroy(&_p_cond);}void Push(const T& data)//生產者放數據{//1. 生產者和生產者之間互斥,而且隊列只能在隊尾放數據: 因此需要加鎖pthread_mutex_lock(&_mutex);//2. 如果隊列滿了,生產者需要去自己的條件變量下排隊,等待消費者喚醒//if(Full()): 無法防止偽喚醒帶來的bugwhile(Full())//能夠防止偽喚醒帶來的bug -> 代碼的魯棒性強{pthread_cond_wait(&_p_cond,&_mutex);}//3. 條件滿足,直接放數據即可_q.push(data);//4. 大家可以自定義生產多少數據之后再喚醒消費者,我這里先暫且: 只要有一個數據就喚醒消費者pthread_cond_signal(&_c_cond);//搖消費者的鈴鐺,喚醒一個消費者//5. Push完成 -> 釋放鎖pthread_mutex_unlock(&_mutex);}void Pop(T& data)//消費者拿數據(跟Push異曲同工之妙){//1. 消費者跟消費者之間互斥,且隊列只能從隊頭出數據: 因此需要加鎖pthread_mutex_lock(&_mutex);//2. 判斷是否空while(Empty()){pthread_cond_wait(&_c_cond,&_mutex);//去自己的條件變量那里排隊,等著生產者喚醒}//3. 條件滿足,直接拿數據即可data=_q.front();_q.pop();//4. 只要拿了一個數據就喚醒生產者,當然大家可以自定義pthread_cond_signal(&_p_cond);//搖生產者的鈴鐺,喚醒一個生產者//5. Pop完成 -> 釋放鎖pthread_mutex_unlock(&_mutex);}bool Full() const//判滿{return _q.size()==_maxSize;//判斷隊列中的數據個數是否==_maxSize即可}bool Empty() const//判空{return _q.empty();//復用即可}private:queue<T> _q;//內部封裝的STL的queuepthread_mutex_t _mutex;//一把互斥鎖即可 (因為生產者之間互斥,消費者之間互斥,生產者和消費者之間互斥,因此阻塞隊列在同一時刻只允許一個線程進行訪問!!)pthread_cond_t _p_cond;//productor生產者的條件變量pthread_cond_t _c_cond;//consumer消費者的條件變量int _maxSize;//阻塞隊列的大小(因為阻塞隊列需要能夠判滿)
};
4.測試代碼的編寫

代碼:
#include <iostream>
#include <unistd.h>
using namespace std;
#include "BlockQueue.hpp"#include <random>
#include <chrono> // 生成指定范圍內的隨機整數(不用管這個)
int generateRandomInt(int min, int max) { // 使用基于當前時間的種子 static random_device rd; static mt19937 gen(rd()); // 定義隨機數分布 uniform_int_distribution<> dis(min, max); // 生成隨機數 return dis(gen);
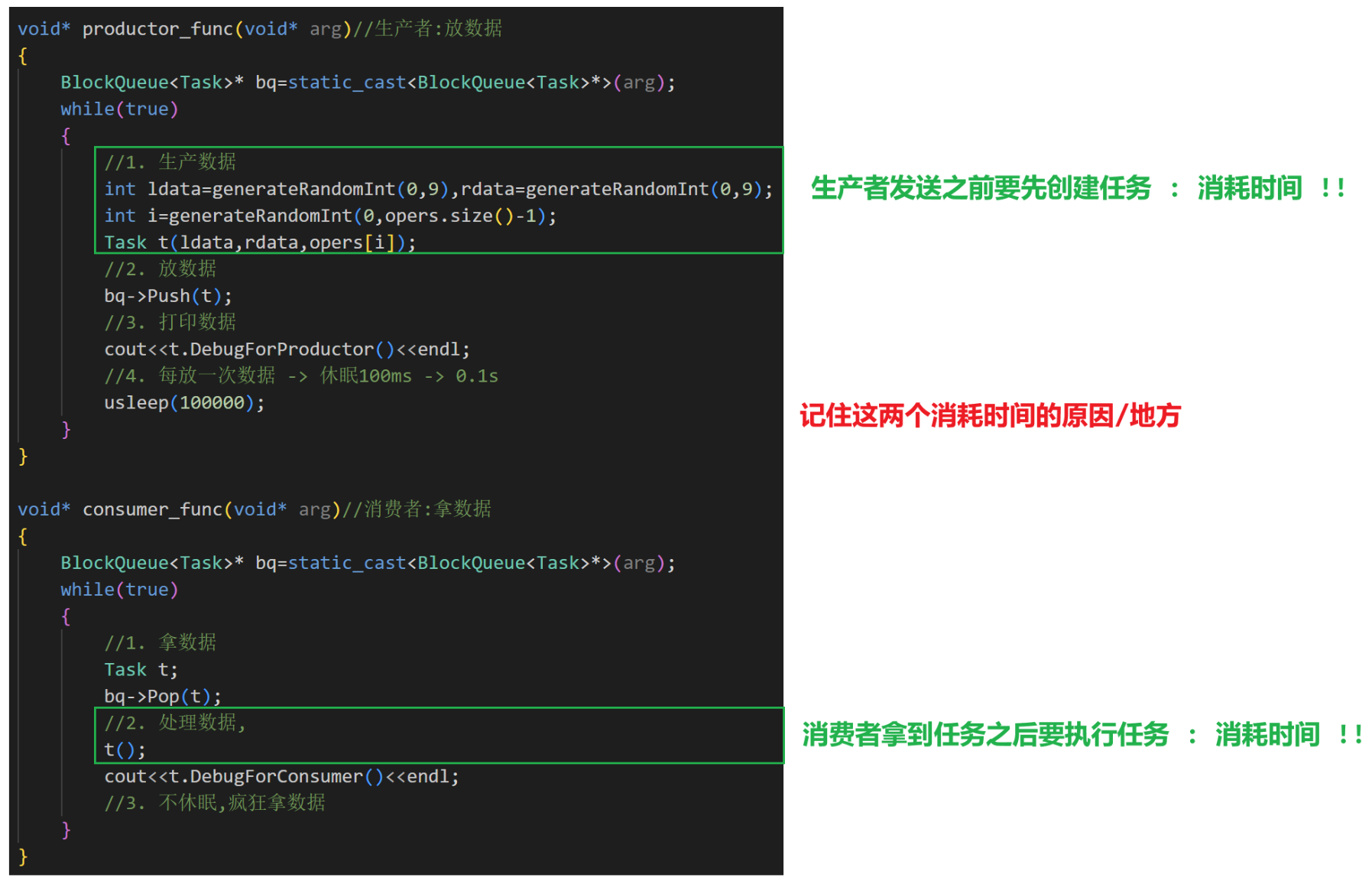
} void* productor_func(void* arg)//生產者:放數據
{BlockQueue<int>* bq=static_cast<BlockQueue<int>*>(arg);while(true){//1. 生產數據int data=generateRandomInt(1,9);//2. 放數據bq->Push(data); //3. 打印數據cout<<"productor_func put data: "<<data<<endl;//4. 休眠/不休眠隨意sleep(1);}
}void* consumer_func(void* arg)//消費者:拿數據
{BlockQueue<int>* bq=static_cast<BlockQueue<int>*>(arg);while(true){//1. 拿數據int data=-1;bq->Pop(data);//2. 處理數據,我們就先暫且打印了cout<<"consumer_func get data: "<<data<<endl;//3. 休眠/不休眠隨意}
}int main()
{srand(time(nullptr));BlockQueue<int>* bq=new BlockQueue<int>;pthread_t consumer_id,productor_id;pthread_create(&consumer_id,nullptr,consumer_func,bq);pthread_create(&productor_id,nullptr,productor_func,bq);pthread_join(consumer_id,nullptr);pthread_join(productor_id,nullptr);delete bq;return 0;
}
5.演示
情況1: 生產者不休眠,消費者休眠

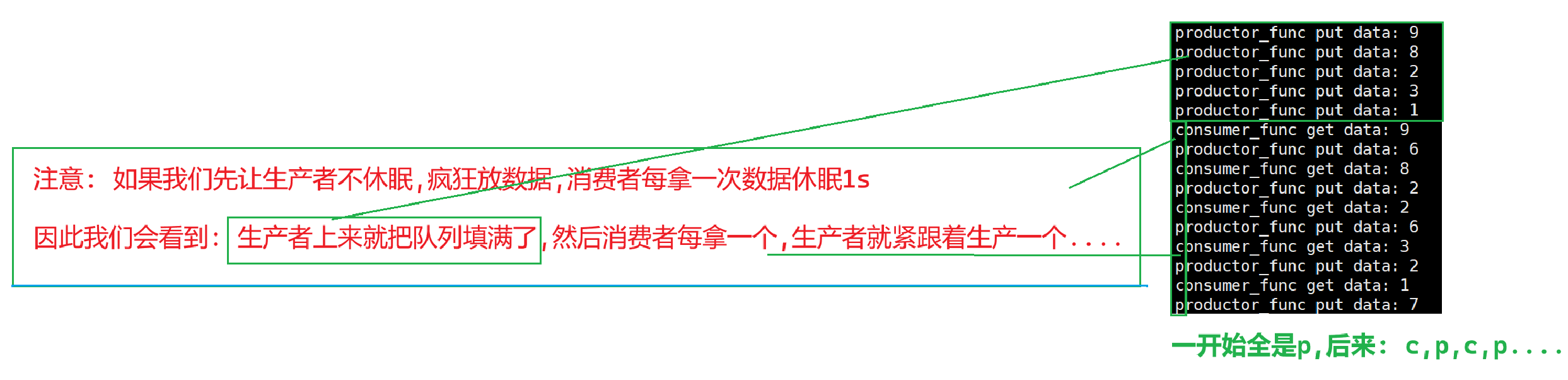
情況2: 消費者不休眠,生產者休眠


看到了生產者和消費者的確具有同步的關系
三.基于阻塞隊列的生產者消費者模型的擴展代碼
1.傳遞任務版本
剛才的時候我們的阻塞隊列當中放的是純數據,我們可不可以放任務呢?
就像是我們進程池當中主進程向其他進程發送任務讓其他線程執行似的
所以我們創建一個Task.hpp
1.Task.hpp
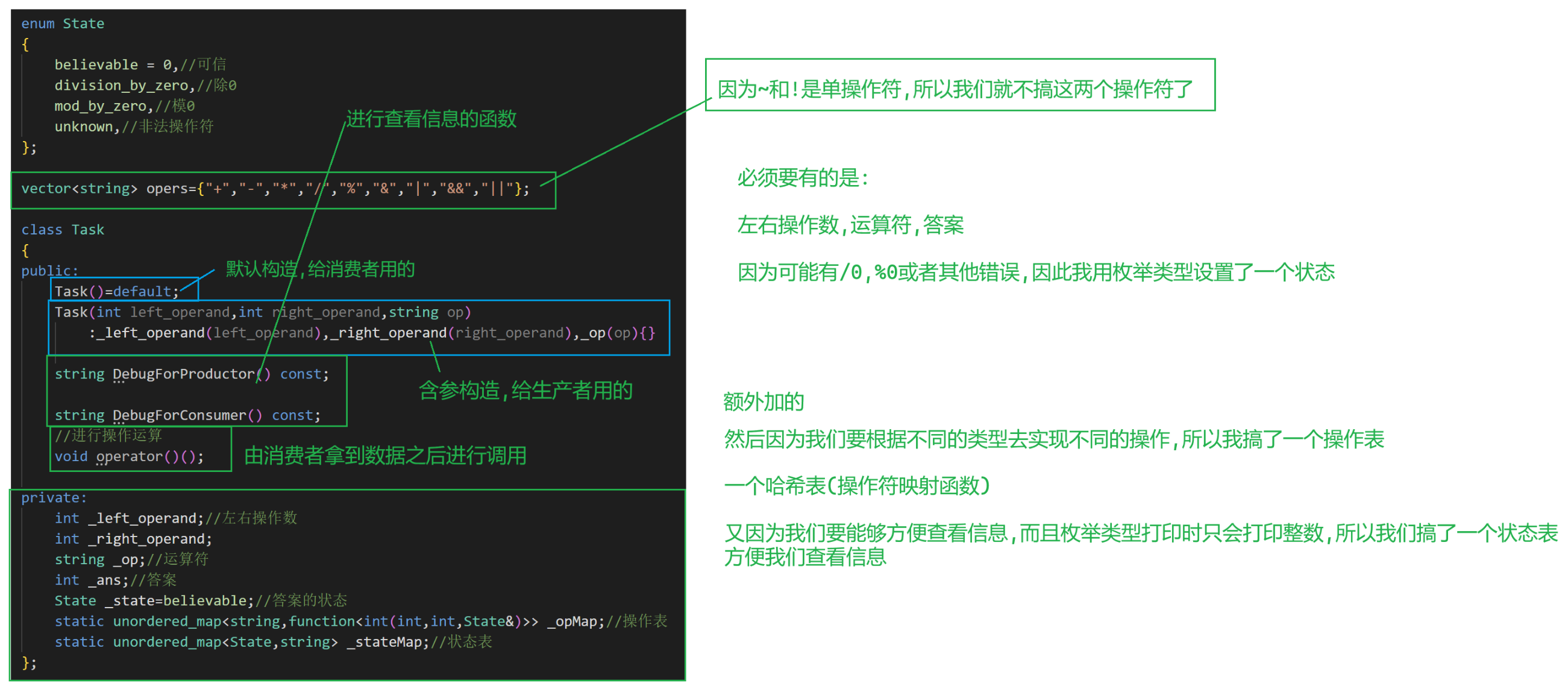
代碼:
#pragma once
#include <unordered_map>
#include <functional>
//我們就模擬數學運算吧: + - * / % & | && ||
//因為~和!是單操作符,所以我們就不搞這兩個操作符了enum State
{believable = 0,//可信division_by_zero,//除0mod_by_zero,//模0unknown,//非法操作符
};vector<string> opers={"+","-","*","/","%","&","|","&&","||"};class Task
{
public:Task()=default;Task(int left_operand,int right_operand,string op):_left_operand(left_operand),_right_operand(right_operand),_op(op){}string DebugForProductor() const{return to_string(_left_operand)+_op+to_string(_right_operand)+" = ?";}string DebugForConsumer() const{return to_string(_left_operand)+_op+to_string(_right_operand)+" = "+to_string(_ans)+"["+_stateMap[_state]+"]";}//進行操作運算void operator()(){if(_opMap.count(_op)==0)//操作符非法{_state=unknown;return;}_ans=_opMap[_op](_left_operand,_right_operand,_state);}private:int _left_operand;//左右操作數int _right_operand;string _op;//運算符int _ans;//答案State _state=believable;//答案的狀態static unordered_map<string,function<int(int,int,State&)>> _opMap;//操作表static unordered_map<State,string> _stateMap;//狀態表
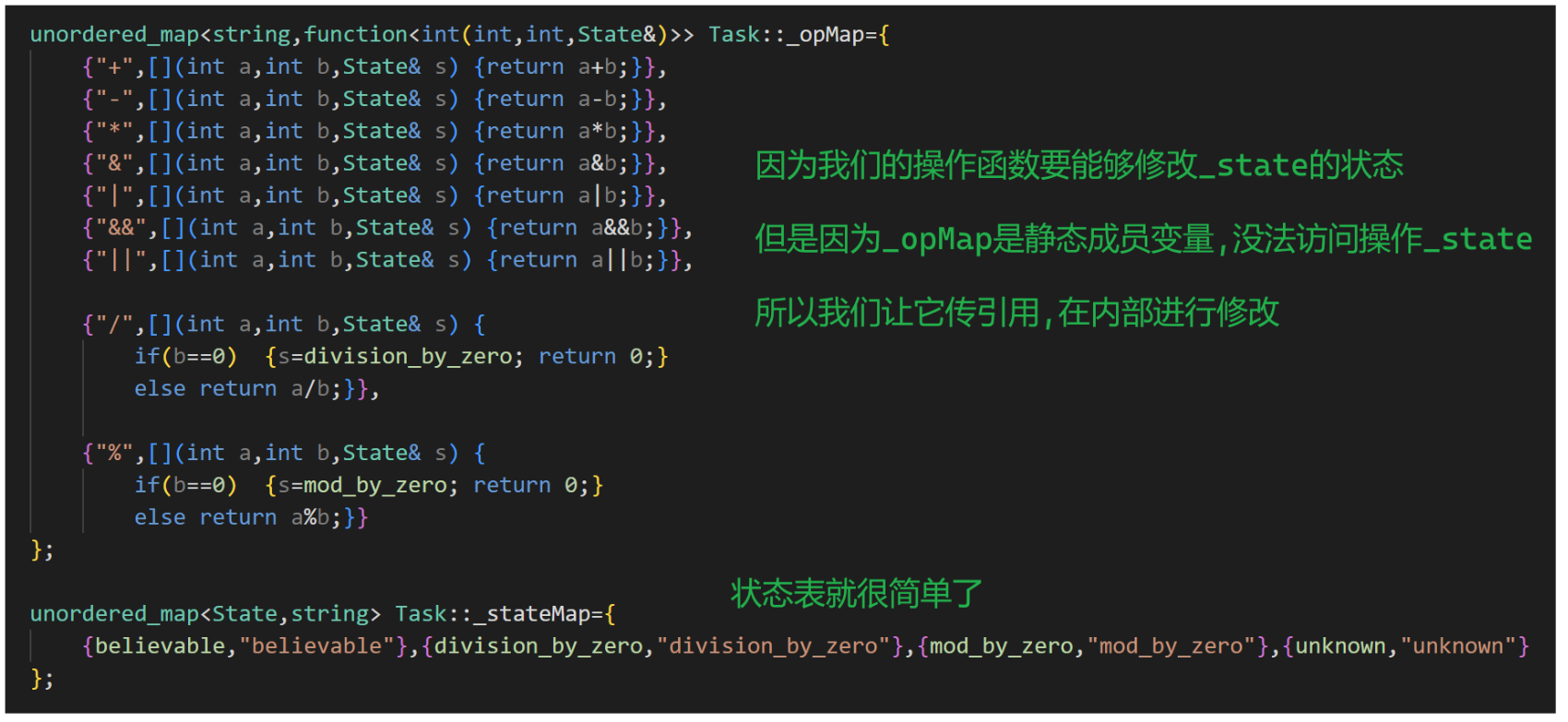
};unordered_map<string,function<int(int,int,State&)>> Task::_opMap={{"+",[](int a,int b,State& s) {return a+b;}},{"-",[](int a,int b,State& s) {return a-b;}},{"*",[](int a,int b,State& s) {return a*b;}},{"&",[](int a,int b,State& s) {return a&b;}},{"|",[](int a,int b,State& s) {return a|b;}},{"&&",[](int a,int b,State& s) {return a&&b;}},{"||",[](int a,int b,State& s) {return a||b;}},{"/",[](int a,int b,State& s) {if(b==0) {s=division_by_zero; return 0;}else return a/b;}},{"%",[](int a,int b,State& s) {if(b==0) {s=mod_by_zero; return 0;}else return a%b;}}
};unordered_map<State,string> Task::_stateMap={{believable,"believable"},{division_by_zero,"division_by_zero"},{mod_by_zero,"mod_by_zero"},{unknown,"unknown"}
};
我們這份代碼的好處是方便擴展,壞處是效率有些慢,沒有瘋狂if else或者switch case快
2.測試代碼
3.演示

運行成功
2.多生產者多消費者版本
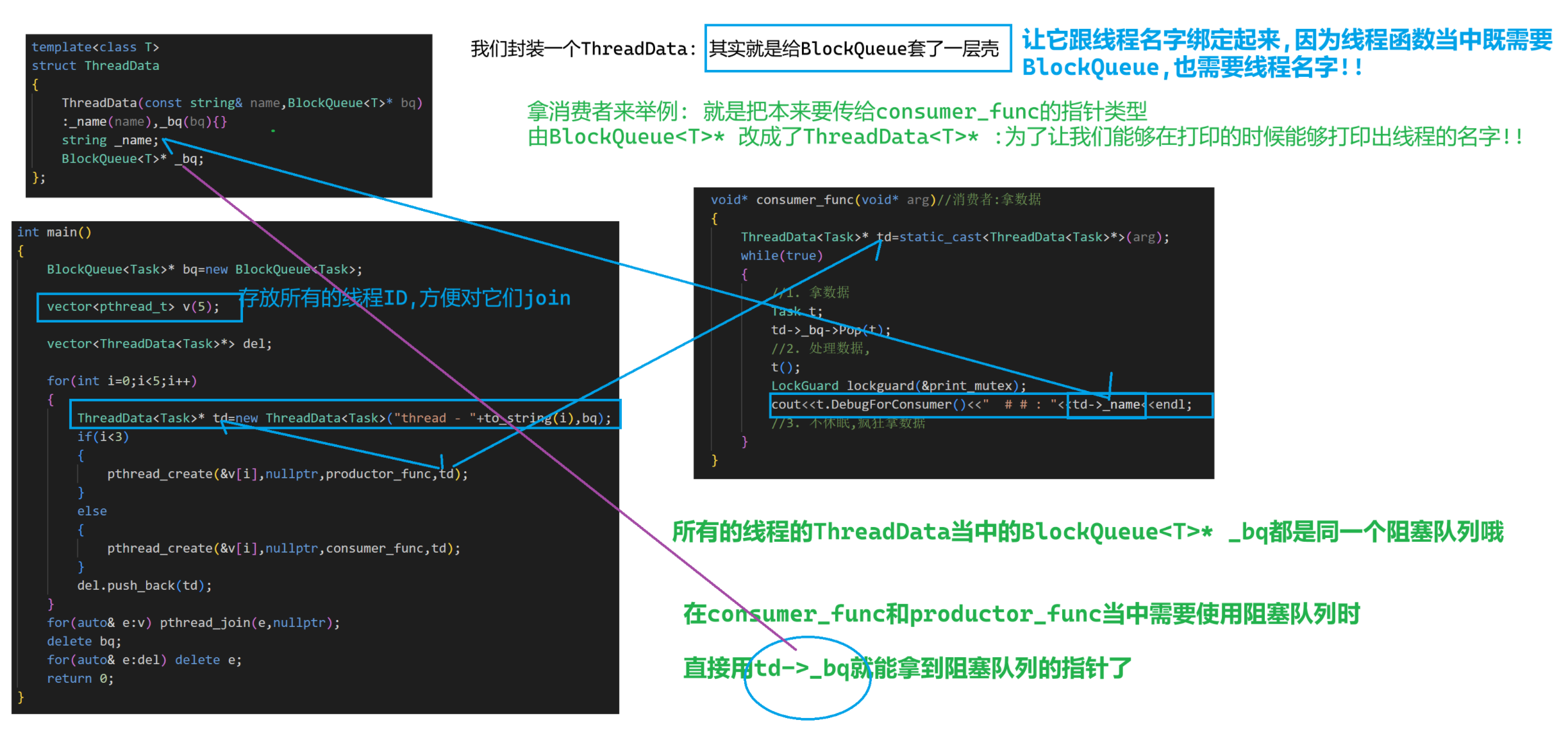
下面我們把它"改"成多生產多消費,這里加""是因為我們實現的時候就已經確保生產者生產者互斥,消費者消費者互斥,生產者消費者互斥了,所以根本無需改動我們的阻塞隊列
但是我們要改測試代碼了
因為有多生產,多消費,所以我們搞3生產者,2消費者,給它們做個編號,這5個線程共用同一個阻塞隊列
因此我們封裝一下阻塞隊列,把阻塞隊列和編號/名字封裝一下,并且用一下我們的lockguard
1.改測試代碼

代碼:
#include <iostream>
#include <unistd.h>
#include <vector>
using namespace std;
#include "BlockQueue.hpp"
#include "Task.hpp"
#include <random>
#include <chrono>
// 生成指定范圍內的隨機整數
int generateRandomInt(int min, int max) { // 使用基于當前時間的種子 static random_device rd; static mt19937 gen(rd()); // 定義隨機數分布 uniform_int_distribution<> dis(min, max); // 生成隨機數 return dis(gen);
} template<class T>
struct ThreadData
{ThreadData(const string& name,BlockQueue<T>* bq):_name(name),_bq(bq){}string _name;BlockQueue<T>* _bq;
};pthread_mutex_t print_mutex=PTHREAD_MUTEX_INITIALIZER;void* productor_func(void* arg)//生產者:放數據
{ThreadData<Task>* td=static_cast<ThreadData<Task>*>(arg);while(true){//1. 生產數據int ldata=generateRandomInt(0,9),rdata=generateRandomInt(0,9);int i=generateRandomInt(0,opers.size()-1);Task t(ldata,rdata,opers[i]);//2. 放數據td->_bq->Push(t);//3. 打印數據LockGuard lockguard(&print_mutex);cout<<t.DebugForProductor()<<" # # : "<<td->_name<<endl;//4. 每放一次數據 -> 休眠100ms -> 0.1susleep(1000000);}
}void* consumer_func(void* arg)//消費者:拿數據
{ThreadData<Task>* td=static_cast<ThreadData<Task>*>(arg);while(true){//1. 拿數據Task t;td->_bq->Pop(t);//2. 處理數據,t();LockGuard lockguard(&print_mutex);cout<<t.DebugForConsumer()<<" # # : "<<td->_name<<endl;//3. 不休眠,瘋狂拿數據}
}int main()
{BlockQueue<Task>* bq=new BlockQueue<Task>;vector<pthread_t> v(5);vector<ThreadData<Task>*> del;for(int i=0;i<5;i++){ThreadData<Task>* td=new ThreadData<Task>("thread - "+to_string(i),bq);if(i<3){pthread_create(&v[i],nullptr,productor_func,td);}else{pthread_create(&v[i],nullptr,consumer_func,td);}del.push_back(td);}for(auto& e:v) pthread_join(e,nullptr);delete bq;for(auto& e:del) delete e;return 0;
}
演示:

當然,大家可以自定義生產者生產多少數據之后再喚醒消費者,消費者消費多少數據之后在喚醒生產者
四.生產者消費者模型的再一次理解與阻塞隊列版本的優劣
我們解釋一下生產者消費者模型的優點:
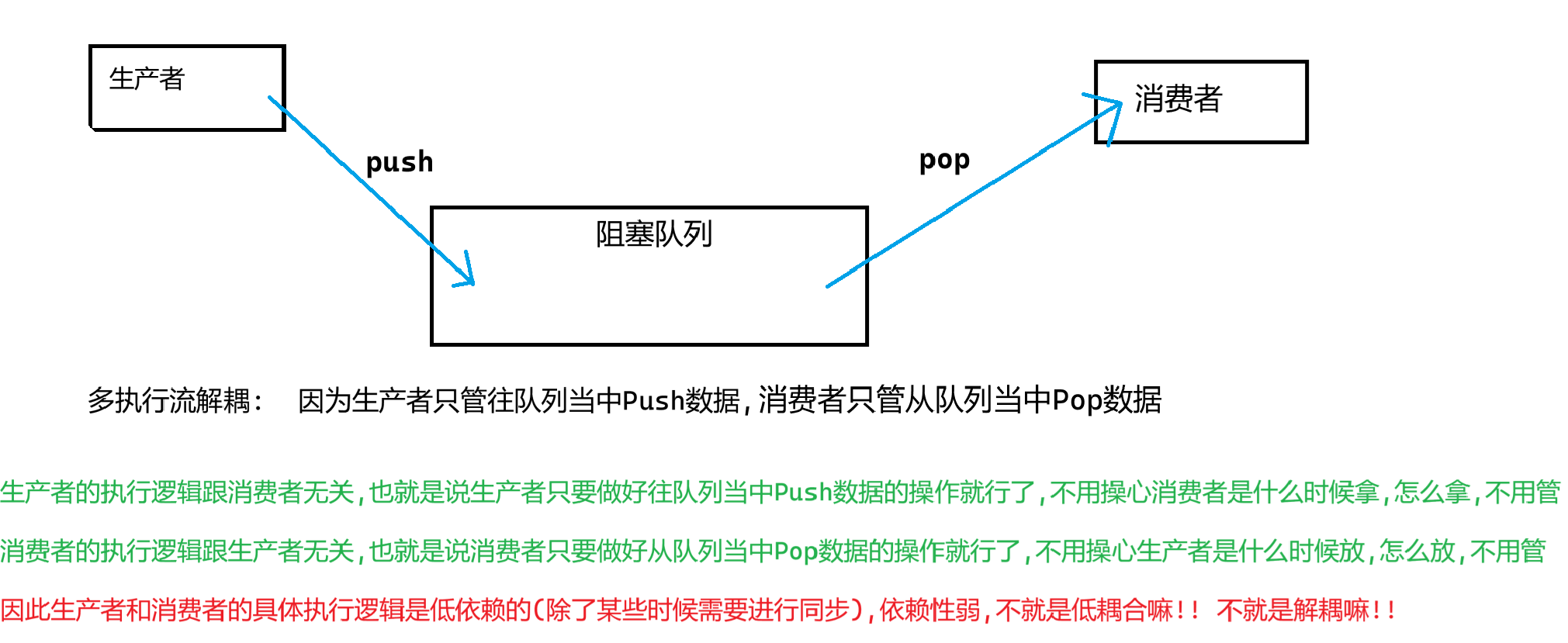
1.多執行流解耦
2.提高效率
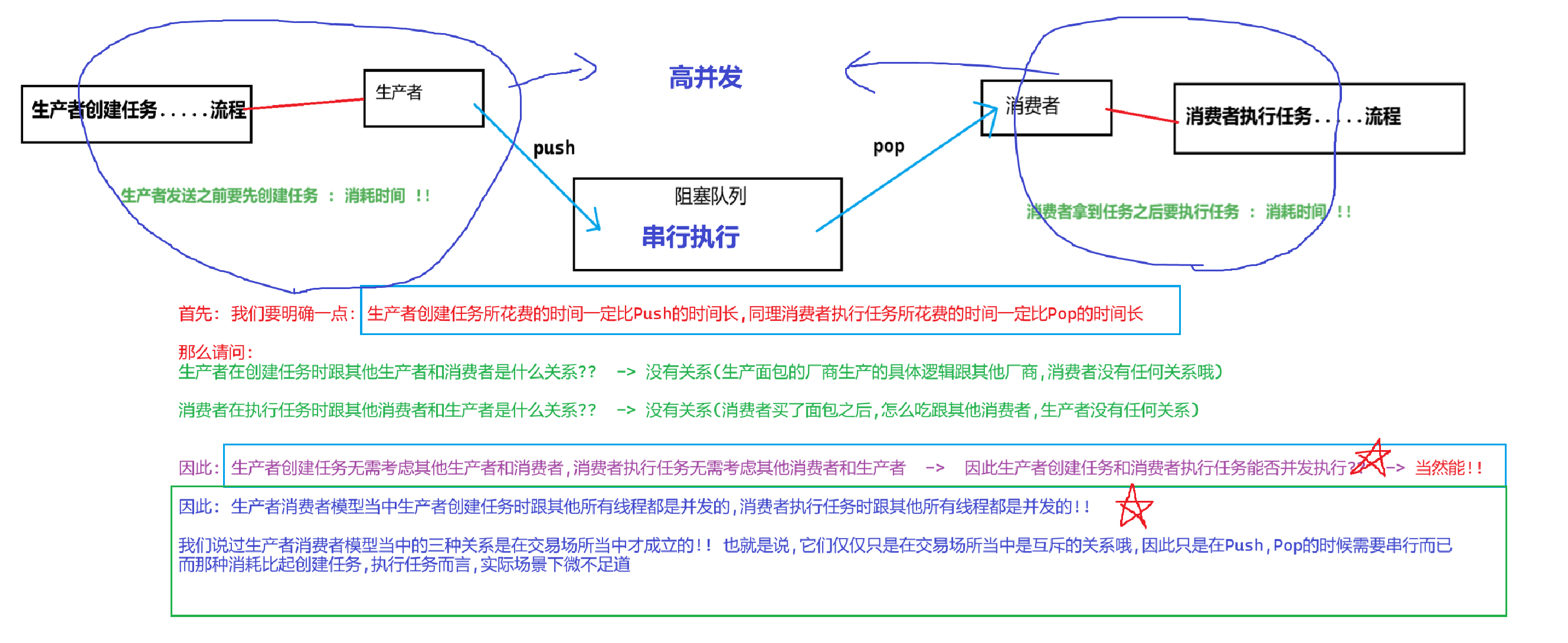
3.小結一下
生產者消費者模型:
通過交易場所這個大的臨界資源來存放交易數據實現了多執行流之間的解耦,
從而使得生產者創建數據和消費者處理數據的工作能夠跟其他線程實現并發執行,從而提高效率
只不過因為阻塞隊列是把整個隊列當作一個整體,所以阻塞隊列在任意時刻只允許一個線程進行訪問,其他線程必須正在阻塞
這個操作降低了阻塞隊列的一點點效率,但是跟阻塞隊列帶來的優勢相比,在權衡之下,依舊是優點大大高于不足
五.信號量的深入理解與使用
1.理論
我們之前在介紹System V版本的進程間通信的時候,介紹了信號量的理論,并且用信號量實現了共享內存的協同機制
下面我們稍微復習總結一下信號量的理論
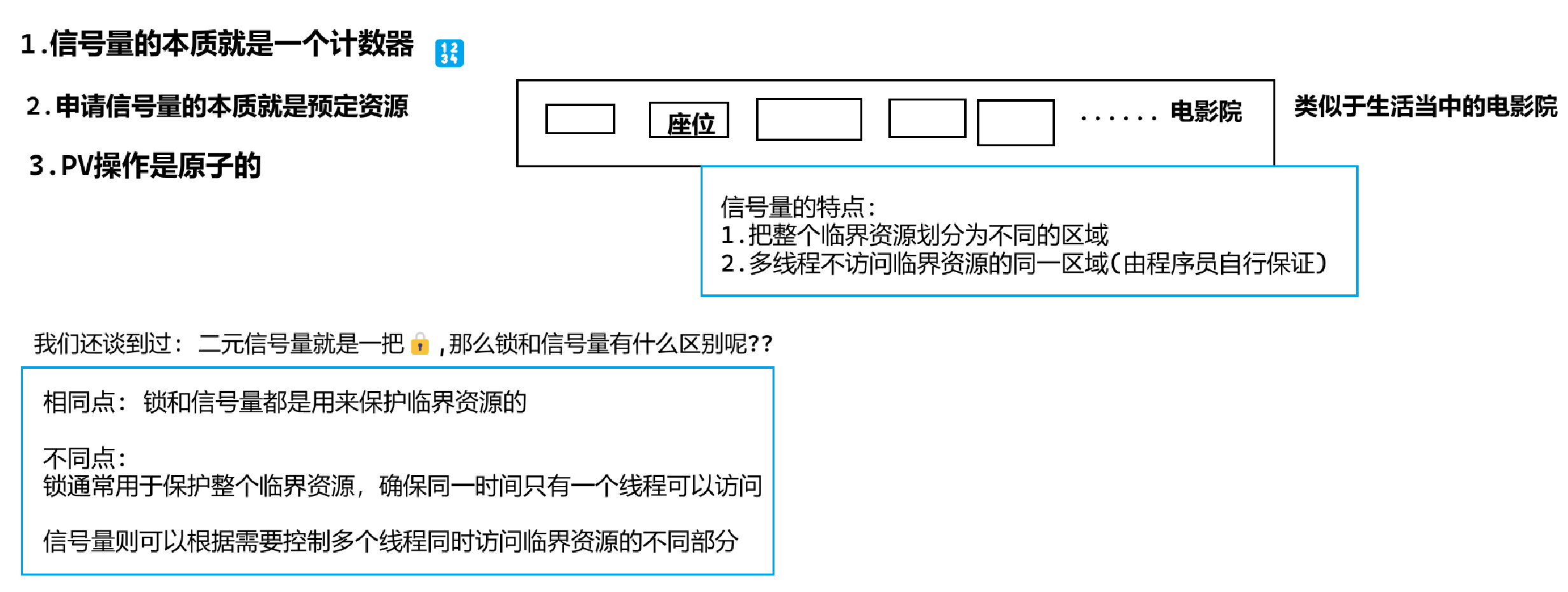
還有一點:
信號量本身就具有互斥和同步的功能!!
而鎖只有互斥的功能,想要同步,必須配合條件變量等等機制才能實現同步
記住: 鎖:🔒,條件變量:🔔,信號量:🔢(計數器)
2.接口介紹
相比于System V的接口來說,pthread庫當中信號量的接口就簡潔很多

我們就只需要用這4個接口即可,下面直接在基于環形隊列的生產者消費者模型的代碼當中用一下信號量了

因為環形隊列的生產者和消費者之間的互斥可以用信號量🔢來維護,所以我們用一下環形隊列這個數據結構作為交易場所
又因為生產者和生產者,消費者和消費者之間也是互斥的,而它們之間的互斥怎么保證呢?
這點比起阻塞隊列的統統掛鎖🔒要難以理解一點,所以我們先實現單生產者單消費者模型,然后再改成多生產者多消費者模型
六.基于環形隊列的單生產者單消費者模型
1.思路

這里我們用了信號量之后根本就不需要條件變量了,因為
隊列為空時: Pop會阻塞消費者,但是當生產者Push數據之后,sem_data就++了,因此Pop阻塞的消費者就能夠申請到sem_data了
同理,隊列為滿時: Push會阻塞生產者,但是當消費者Pop數據之后,sem_space就++了,因此Push阻塞的生產者就能夠申請到sem_space了
而且環形隊列的大小就是vector一開始初始化的size().因此也無需我們在設置一個變量了
2.基礎代碼
剛寫完阻塞隊列的生產者消費者模型,那單生產單消費的環形隊列沒啥大區別,這里直接用ThreadData了
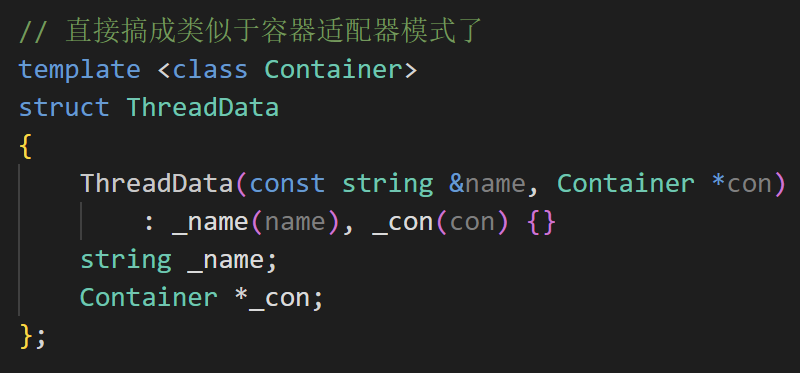
用一下類似于適配器模式的樣子,你給我傳什么阻塞隊列/環形隊列/xxx容器/yyy容器,無所謂,我都給你綁定一個字符串
1.RingQueue.hpp
1.結構

2.代碼
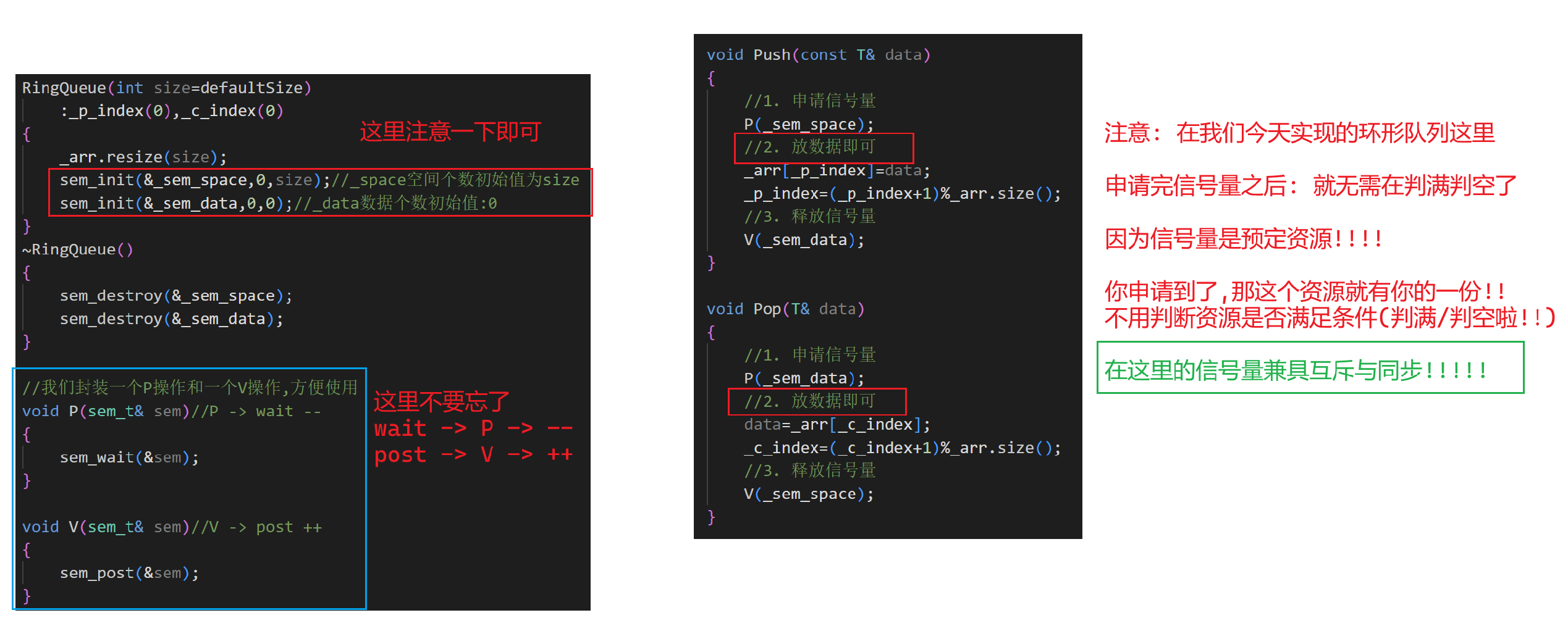
這里就先不給出源碼了,因為這個場景對多生產多消費并不適用,為何?
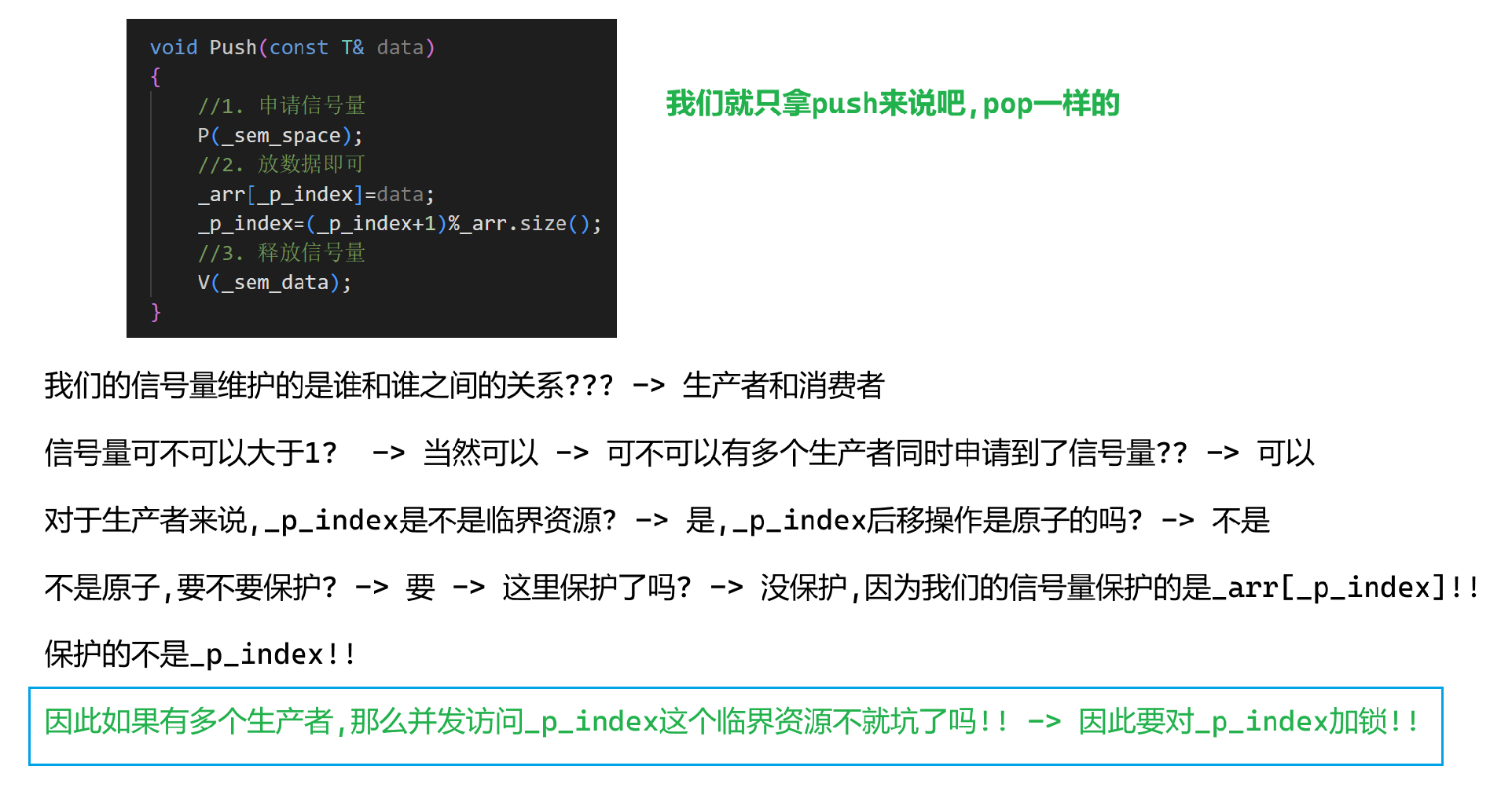
那么push的時候先加鎖還是先申請信號量呢??
這里比較不太好理解,我們放到改成多生產多消費的時候再談,因為現在有一個更重要的發現需要我們介紹
3.細節
需要實現同步+互斥的時候
鎖必須配合條件變量進行使用(不考慮鎖能配合信號量一起使用)
而有時信號量可以無需配合條件變量進行使用
因此信號量才被稱為"對資源的預定機制",因為這種情況下它不知不覺就自動實現了同步
因此信號量本身就具有互斥和同步的功能!!
而鎖只有互斥的功能,想要同步,必須配合條件變量等等機制才能實現同步
3.擴展代碼
下面直接用我們的Task.hpp,啥也不用改,拿過頭文件來直接用就行
跟阻塞隊列的一樣,沒啥好解釋的

七.基于環形隊列的多生產者多消費者模型
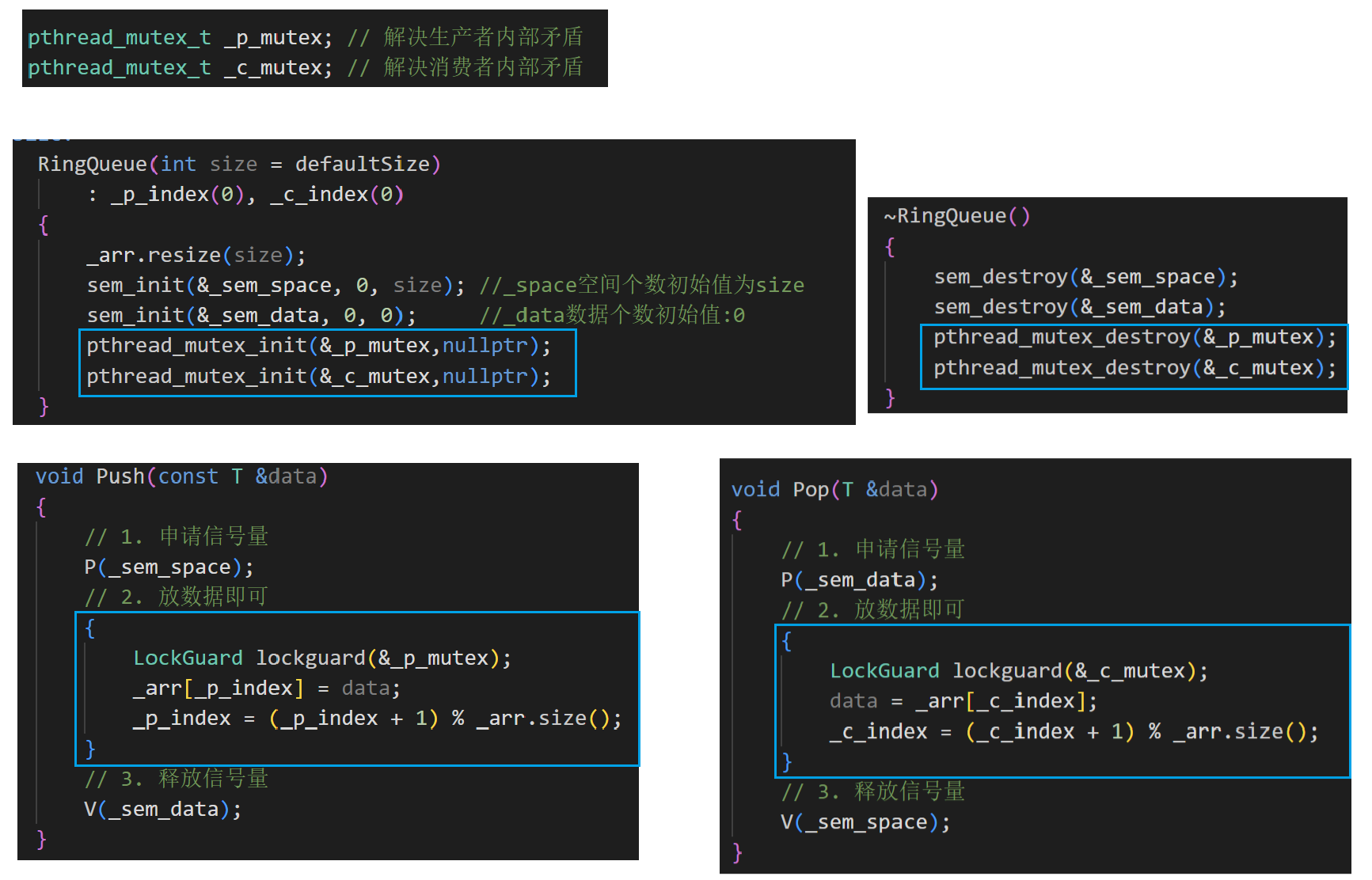
1.先申請信號量,后申請鎖的原因
剛才我們說了,Push和Pop想要改成多生產者多消費者一定要加鎖,那么先加鎖還是先申請信號量呢?
代碼的正確性上講,其實是都可以,但是效率上是有區別的


申請信號量🔢: 本質是解決生產者和消費者之間的互斥(解決座位數目(圖書館資源)和讀者需求之間的互斥)
申請鎖🔒: 本質是解決生產者和生產者之間的互斥,消費者和消費者之間的互斥
因此申請信號量是解決外部矛盾,而申請鎖是解決內部矛盾
而對于同時面臨內外的非常嚴重的問題時: 解決矛盾一定是先解決外部矛盾,后解決內部矛盾
2.RingQueue代碼
直接用我們的LockGuard秒了它
#pragma once
#include <semaphore.h>const int defaultSize = 5;template <class T>
class RingQueue
{
public:RingQueue(int size = defaultSize): _p_index(0), _c_index(0){_arr.resize(size);sem_init(&_sem_space, 0, size); //_space空間個數初始值為sizesem_init(&_sem_data, 0, 0); //_data數據個數初始值:0pthread_mutex_init(&_p_mutex,nullptr);pthread_mutex_init(&_c_mutex,nullptr);}~RingQueue(){sem_destroy(&_sem_space);sem_destroy(&_sem_data);pthread_mutex_destroy(&_p_mutex);pthread_mutex_destroy(&_c_mutex);}// 我們封裝一個P操作和一個V操作,方便使用void P(sem_t &sem) // P -> wait --{sem_wait(&sem);}void V(sem_t &sem) // V -> post ++{sem_post(&sem);}void Push(const T &data){// 1. 申請信號量P(_sem_space);// 2. 放數據即可{LockGuard lockguard(&_p_mutex);_arr[_p_index] = data;_p_index = (_p_index + 1) % _arr.size();}// 3. 釋放信號量V(_sem_data);}void Pop(T &data){// 1. 申請信號量P(_sem_data);// 2. 放數據即可{LockGuard lockguard(&_c_mutex);data = _arr[_c_index];_c_index = (_c_index + 1) % _arr.size();}// 3. 釋放信號量V(_sem_space);}private:vector<T> _arr; // 環形隊列底層容器,環形隊列大小就是_arr.size()sem_t _sem_space; // 空間信號量sem_t _sem_data; // 數據信號量int _p_index; // 生產者放數據的下標int _c_index; // 消費者拿數據的下標pthread_mutex_t _p_mutex; // 解決生產者內部矛盾pthread_mutex_t _c_mutex; // 解決消費者內部矛盾
};
3.測試
直接上測試代碼,2個消費者,3個生產者,給cout加鎖,走起
#include <iostream>
using namespace std;
#include <vector>
#include <unistd.h>
#include <pthread.h>
#include "Lock_guard.hpp"
#include "RingQueue.hpp"
#include "Task.hpp"
#include <random>
#include <chrono>// 生成指定范圍內的隨機整數
int generateRandomInt(int min, int max)
{// 使用基于當前時間的種子static random_device rd;static mt19937 gen(rd());// 定義隨機數分布uniform_int_distribution<> dis(min, max);// 生成隨機數return dis(gen);
}// 直接搞成類似于容器適配器模式了
template <class Container>
struct ThreadData
{ThreadData(const string &name, Container *con): _name(name), _con(con) {}string _name;Container *_con;
};pthread_mutex_t print_mutex = PTHREAD_MUTEX_INITIALIZER;void *consumer_func(void *arg)
{ThreadData<RingQueue<Task>> *td = static_cast<ThreadData<RingQueue<Task>> *>(arg);while (true){int Ldata = generateRandomInt(0, 9), Rdata = generateRandomInt(0, 9), opi = generateRandomInt(0, opers.size() - 1);Task t(Ldata, Rdata, opers[opi]);td->_con->Push(t);LockGuard lockguard(&print_mutex);//改成多生產者多消費者時再給打印加鎖cout << t.DebugForProductor() << " " << td->_name << endl;sleep(1); // 生產者休眠1s}
}void *productor_func(void *arg)
{ThreadData<RingQueue<Task>> *td = static_cast<ThreadData<RingQueue<Task>> *>(arg);while (true){Task t;td->_con->Pop(t);LockGuard lockguard(&print_mutex);//改成多生產者多消費者時再給打印加鎖t();cout << t.DebugForConsumer() << " " << td->_name << endl;}
}int main()
{RingQueue<Task> *rq = new RingQueue<Task>;vector<pthread_t> v(5);vector<ThreadData<RingQueue<Task>>*> delv;//先生產者for(int i=0;i<3;i++){ThreadData<RingQueue<Task>> *td = new ThreadData<RingQueue<Task>>("thread - p"+to_string(i+1), rq);delv.push_back(td);pthread_create(&v[i],nullptr,productor_func,td);}//后消費者for(int i=0;i<2;i++){ThreadData<RingQueue<Task>> *td = new ThreadData<RingQueue<Task>>("thread - c"+to_string(i+1), rq);delv.push_back(td);pthread_create(&v[i+3],nullptr,consumer_func,td);}for(auto& e:v) pthread_join(e,nullptr);delete rq;for(auto& e:delv) delete e;return 0;
}
多生產多消費測試的修改跟阻塞隊列的差不多,唯一最大的變化就是這里給cout也加鎖了

八.基于環形隊列的生產者消費者模型與基于阻塞隊列的生產者消費者模型的對比
環形隊列的生產者消費者模型通過將整個交易場所劃分為若干個區域,
從而將使得生產者和消費者可以在一定條件下實現并發訪問環形隊列,從而相比于阻塞隊列來說在這一點上提高了效率
但是也不能單純地下定義說環形隊列就是比阻塞隊列好
別忘了: 阻塞隊列還能夠由我們自定義生產者生產多少數據之后再喚醒消費者,消費者消費多少數據之后在喚醒生產者的
條件變量允許開發者根據特定的條件來決定何時喚醒線程,而信號量則通過控制資源的并發訪問量來實現同步
因此阻塞隊列中互斥鎖配合條件變量能夠使得代碼更加易于控制和變化
所以兩種方法各有千秋,使用哪種看具體需求和場景而定
以上就是Linux多線程系列三: 生產者消費者模型,信號量使用,基于阻塞隊列和環形隊列的這兩種生產者消費者代碼的實現的全部內容,希望能對大家所有幫助!!!

)


開發平臺數據統計如何配置?)




正式啟動)
)








