1.概述
近年來,大型語言模型(LLMs),例如ChatGPT,致力于構建能夠輔助人類的個性化人工智能代理,這些代理以進行類似人類的對話為重點。在學術領域,尤其是社會科學中,一些研究報告已經指出,生成式代理具備模擬人類個性特征的能力。盡管在這一領域取得了顯著進展,但關于個性化LLM如何精確且持續地再現特定人格特質的研究評估卻相對匱乏。
在這種背景下,本文介紹了一項研究論文。該論文通過讓LLMs模擬基于五大人格特質的角色,并通過從生成的內容中提取心理語言特征、進行人類評分和人格預測,來探究LLMs是否能夠再現人格特征。這項研究為我們提供了對LLMs在個性化方面的潛力和挑戰的深入理解。
源碼地址:https://github.com/hjian42/personallm
論文地址:https://arxiv.org/pdf/2305.02547.pdf
2.五大人格特質
本文探討了"五大"人格特質理論,這是由美國心理學家劉易斯·戈德堡提出的一個框架,用于描述和理解人的個性差異。該理論認為,人的個性可以通過五個基本維度來分類,這五個維度共同構成了人格的框架。
"五大"人格特質,也被稱為五因素模型(Five-Factor Model),是心理學中一個廣泛接受的人格特質理論。這個模型認為人格可以通過五個基本維度來描述,這五個維度通常被縮寫為OCEAN:
- 開放性(Openness):與創造性、好奇心、想象力和對新體驗的開放態度相關。
- 責任心(Conscientiousness):涉及組織性、堅持、自律、成就導向和可靠性]。
- 外向性(Extraversion):與社交性、活躍度、樂觀和對外界刺激的需求相關。
- 宜人性(Agreeableness):與合作性、信任、利他、謙遜和對他人的同情相關。
- 神經質(Neuroticism):與情緒穩定性相反,涉及情緒波動、焦慮、抑郁和自我意識。
此外,本文還介紹了一個實驗,其中讓大型語言模型(LLM)根據上述五大人格特質之一來模擬角色。隨后,利用大五人格量表(Big Five Inventory,BFI)對LLM模擬的角色進行了評估。通過這種方式,本文旨在探索LLM是否能夠準確地再現和模擬特定的人格特質,這對于構建更加個性化和人性化的AI代理具有重要意義。
3. 實驗概述
項目部署:
conda activate audiencenlp
python3.9 run_bfi.py --model "GPT-3.5-turbo-0613"
python3.9 run_bfi.py --model "GPT-4-0613"
python3.9 run_bfi.py --model "llama-2"
本文的實驗工作流程如下圖所示。

如圖所示,本實驗按照以下步驟進行。
A. 首先,運行提示,生成具有獨特個性特征的LLM角色
B. 然后讓生成的 LLM 角色完成故事寫作任務
C. 使用 “語言探究和字數統計”(LIWC)框架,研究 "LLM角色 "所描述的故事是否包含表明指定個性特征的語言模式
D. 評估 LLM 角色(人類角色和 LLM 角色)所描述的故事。
E. 讓人類和 LLM 完成從故事中預測作家 LLM 角色性格特征的任務
3.1 LLM角色模擬
實驗使用了兩個 LLM 模型(GPT-3.5 和 GPT-4),分別針對五大人格特質模擬了 10 個 LLM 角色,總共生成了 320 個角色。
然后,使用上述的 "BFI "對所生成的 "LLM 角色 "進行了評估,以檢查它們是否充分再現了 “五大角色”。
3.2故事寫作
然后,320 個LLM**"角色 "被要求 "請分享一個 800 字左右的個人故事。 請不要在故事中明確提及你的性格特征**。**不要在故事中明確提及你的性格特征。不要在故事中明確提及你的性格特征。**要求參與者撰寫一個文本故事用于分析,并提示 "不要在故事中明確提及您的個性特征。
3.2 LIWC 分析
接下來,我們使用LIWC(語言調查和字數統計)框架從 "角色 "所描述的故事中提取心理語言特征,這是一種通過對文本中的詞匯進行抽象和分類來對屬性進行歸類的方法。
這項分析旨在通過研究故事中的性格特征與分配給LLM的性格特征之間的相關性,找出與性格特征的性格特征相對應的語言模式。
3.3 故事評價
然后,人類和本地語言學家根據以下標準對本地語言學家角色所描述的故事進行評分
- 可讀性:故事是否易讀、結構合理、流暢自然?
- 個性:故事是否獨特,是否清楚地表達了作者的思想和情感?
- 冗余:故事簡明扼要,沒有不必要的內容
- 凝聚力:故事寫得好嗎?
- 可讀性:閱讀是否有趣?
- 可信度:故事是否引人入勝,是否符合實際情況?
3.4 性格預測
最后,支持每個人和 LLM 從給定的故事中預測作家 LLM 角色的個性特征,評分標準為 1 到 5 分。本實驗的目的是評估 LLM 角色所描述的故事是否能有效地展示人類和 LLM 都能識別的人格特質。
4. 實驗結果
本文使用 GPT-3.5 和 GPT4 這兩個 LLM 模型生成的 320 個 LLM 角色進行了實驗,以確認以下兩個研究問題。
A. LLM的 "角色 "是否反映了指定的個性特征?
B. 從 "LLM 角色 "所描述的故事中,能否獲得每種人格特質的語言模式?
C. LLM角色所描述的故事是否寫得充分?
D. 故事能預測LLM角色的個性特征嗎?
4.1 LLM的 "角色 "是否反映了指定的個性特征?
為了證實這一研究問題,本實驗根據 320 個LLM角色對 BFI 的回答計算了他們的個性分數,并通過 t 檢驗分析了這些分數的分布與所分配的個性特征的函數關系。
結果如下。
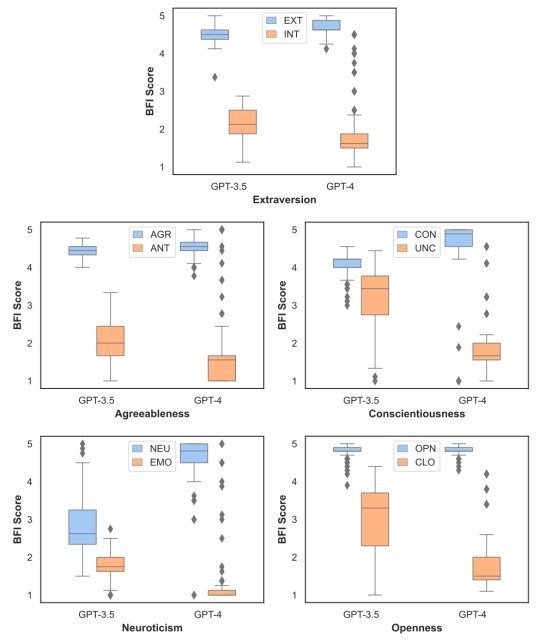
實驗結果表明,在統計學上,LLM的角色****在所有性格特征上都有明顯的差異,這證明他們反映了他們被賦予的角色。
4.2 LLM的 "角色 "是否反映了指定的個性特征?
為了證實這一研究問題,本實驗使用 LIWC 從 LLM 角色生成的故事中提取了心理語言特征,并計算了這些特征與指定人格特質之間的點比對相關性(PBCs)。
點雙項相關系數是一種適用于分析二元變量與連續變量之間關系的系數,在此用于研究指定的人格特質(=二元變量)與 LIWC 特征(=連續變量)之間的相關性。
下表概述了與個性特征有顯著統計學相關性的 LIWC 特征。

實驗結果表明,指定的人格特質對法學碩士角色的語言風格有顯著影響,例如,當LLM被賦予神經質角色時,更傾向于使用負面詞匯,如焦慮和負面語氣。結果表明,所分配的人格特質對法學碩士角色的語言風格有顯著影響。
此外,更重要的是,這些相關性反映了在人類描述的故事中觀察到的模式,證實了人類和 LLM 角色之間用詞的一致性。(與 GPT-3.5 相比,GPT-4 的結果與人類更加一致) 。
4.3 LLM角色所描述的故事是否寫得充分?
為了證實這一研究問題,本實驗評估了由 LLM 角色(包括人類角色和 LLM 角色)生成的故事。
評估結果見下表。
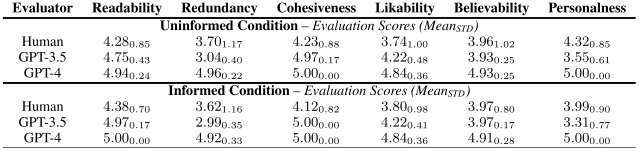
值得注意的是,GPT-4 角色所生成的故事在可讀性(可讀性)、內聚性(內聚性)和可信性(現實性)方面都獲得了人類和 LLM 4.0 或更高的評分。重點是在以下方面獲得了 4.0 或更高的評分。
結果證實,"角色 "所產生的故事不僅語言流暢、結構連貫,而且引人入勝。
4.4 故事能預測法學碩士角色的個性特征嗎?
為了證實這一研究問題,本實驗將每個角色的個性特征視為二元分類問題,并計算了人類和 LLM 預測個性特征的準確率。
實驗結果如下圖所示。
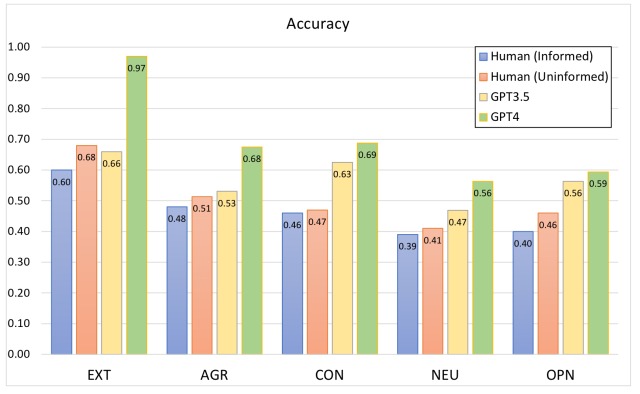
實驗結果表明,人類從 GPT-4 角色描述的故事中預測性格特征的準確率在外向性和宜人性方面分別低至 68% 和 51%,這證實了人類基于文本的性格預測任務的難度。.
另一方面,GPT-4 在 “外向性”、"宜人性 "和 "自覺性 "方面的準確率分別為 97%、68%和 69%,表明它可以非常準確地預測人格特質。研究結果如下
5.總結
本論文通過模擬基于五大人格特質的角色,并通過分析生成內容中的心理語言特征、人類評價以及人格預測,深入探討了大型語言模型(LLM)是否能夠再現人格特質。
實驗結果表明,LLM不僅能夠成功模擬特定的人物形象,而且還能通過用詞習慣反映出人格特質,進而實現對人格特質的預測。這一發現突顯了LLM在模擬人類個性方面的龐大潛力。
然而,研究也指出了未來需要進一步探索的領域。例如,當前的實驗并未模擬更自然的情境,如LLM角色之間的互動或協作。此外,研究主要關注英語,尚未擴展到其他語言的探索。
隨著這一研究領域的持續發展,我們有理由期待,未來將能夠開發出能夠精確復制人類個性和行為的人工智能代理,它們的行為模式將與人類無異。
正式啟動)
)












)




