大模型時代,任何行業,任何企業的數據治理未來將會以“語料庫”的自動化構建為基石。因此這一系列精選的論文還是圍繞在語料庫的建設以及自動化的構建。
通讀該系列的文章,猶如八仙過海,百花齊放。非結構的提取無外乎關注于非結構化的對象以及對象之間的關系,進而提煉為架構化的數據進行治理。目前優質的基座模型甚多,如何準備微調的語料庫樣本庫(如何標注)以及如何設計標注的結構則十分關鍵,好的設計將使得微調過的模型能夠快速學會自動化標注。
在醫學診斷與治療過程中,影像學扮演著至關重要的角色。無論是揭示腫瘤病變、追蹤神經系統狀況、評估心血管功能,還是解析肌肉骨骼問題,放射科醫師通過解讀復雜且非結構化的醫學影像,為臨床決策提供關鍵信息。這些信息通常以詳盡的放射學報告形式呈現,但其自由敘事的特性使得它們在進行二次利用時,如回顧性分析或臨床決策支持系統構建,面臨著結構化轉化的挑戰。如今,這一難題正因一項創新研究而得到突破性進展,本篇論文將創建了“Corpus of Annotated Medical Imaging Reports(CAMIR)”的獨特資源,首次將精細事件結構與概念標準化巧妙融合,革新了醫學影像報告的處理方式。

方法論
數據集:論文使用了一個現有的包含2007年至2020年間來自華盛頓大學醫學系統四個醫院的普通患者群體的臨床數據庫,其中包括1,417,586份CT報告、541,388份MRI報告和39,150份PET-CT報告。從每種成像模態中隨機抽取報告:CT報告203份、MRI報告202份、PET-CT報告204份。這些報告使用神經去標識符自動進行了去標識化處理。
標注模式:CAMIR事件模式中,每個事件包括一個標識事件的觸發器和描述事件的參數。下圖展示了在整個注解過程中使用的BRAT快速注解工具的注解示例。
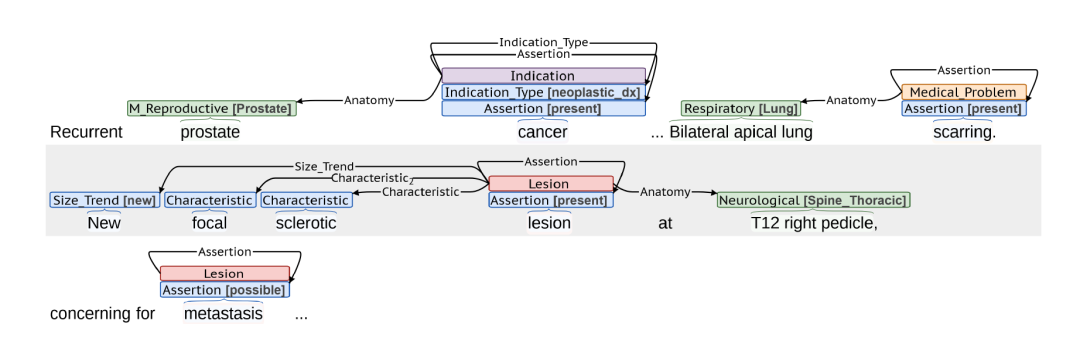
標注方式:四位醫學生對CAMIR進行了標注。兩兩組隊對357份報告進行了雙重標注,另有252份報告由相同的標注員進行了單次標注。經過五輪雙重標注后,標注員的水平達到了一致的交互式一致性評價(IAA)標準,隨后進行了4輪單次標注。數據集中訓練集、驗證集和測試集的比例為70%:10%:20%。訓練集中有41%為雙重標注,整個驗證集和測試集均為雙重標注,以確保評估的可靠性。雙重標注報告平均每份包含2.65±0.48個指征觸發器、10.15±1.31個醫學問題觸發器和9.77±0.99個病變觸發器,而單次標注報告平均每份包含2.14±0.26個指征觸發器、9.91±2.58個醫學問題觸發器和8.78±1.06個病變觸發器。
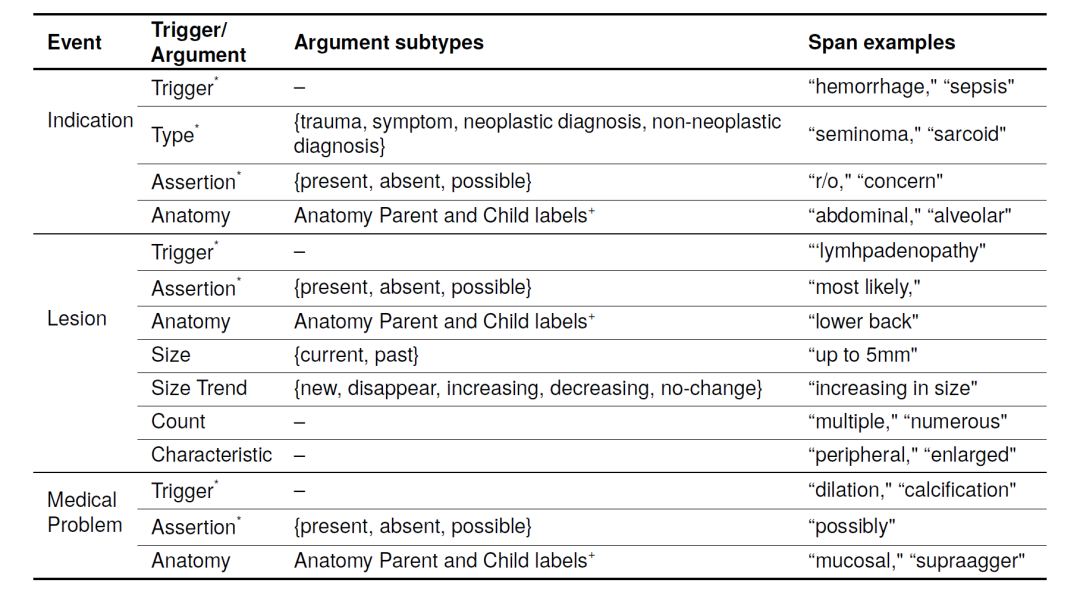
信息提取(IE)提取框架:為了提取CAMIR事件,研究團隊考察了兩種基于BERT的語言模型:(1)mSpERT和(2)增強版的PL-Marker,PL-Marker++。對于這兩套系統,研究團隊把事件分解為包含實體和關系的一個組,其中關系頭是觸發器,關系尾是參數。

mSpERT
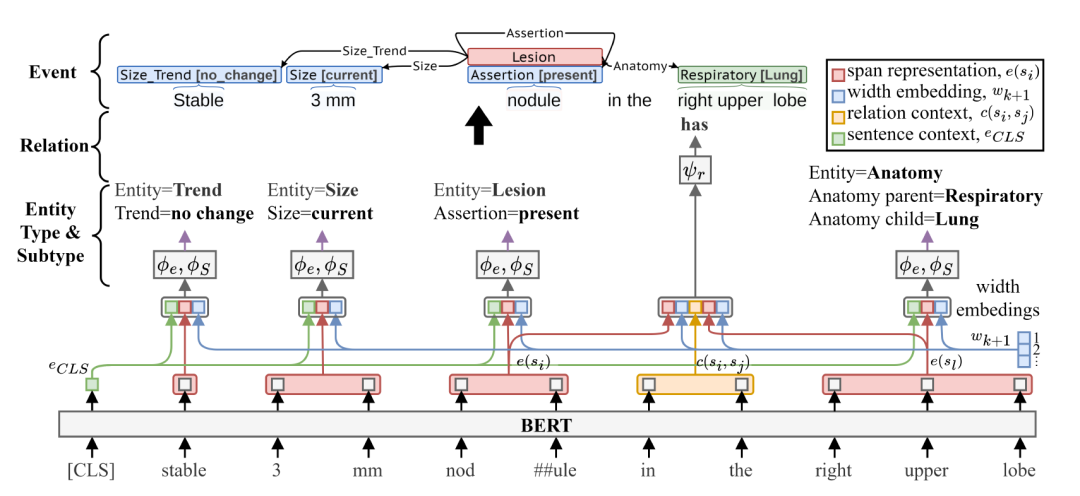
上圖顯示了mSpERT架構,包括各種主體類型、主體子類型和關系輸出層。這種嘗試較為直接,直接使用BERT聯合提取主體和關系。
輸出層通過外接Adapter負責分類跨度識別以及多標簽之間的關系預測。研究團隊因此也利用它來預測子類型標簽,mSpERT輸出的最終結果可以生成CAMIR預先定義的事件結構,進而完成數據自動化的抽取。

PL-Marker++
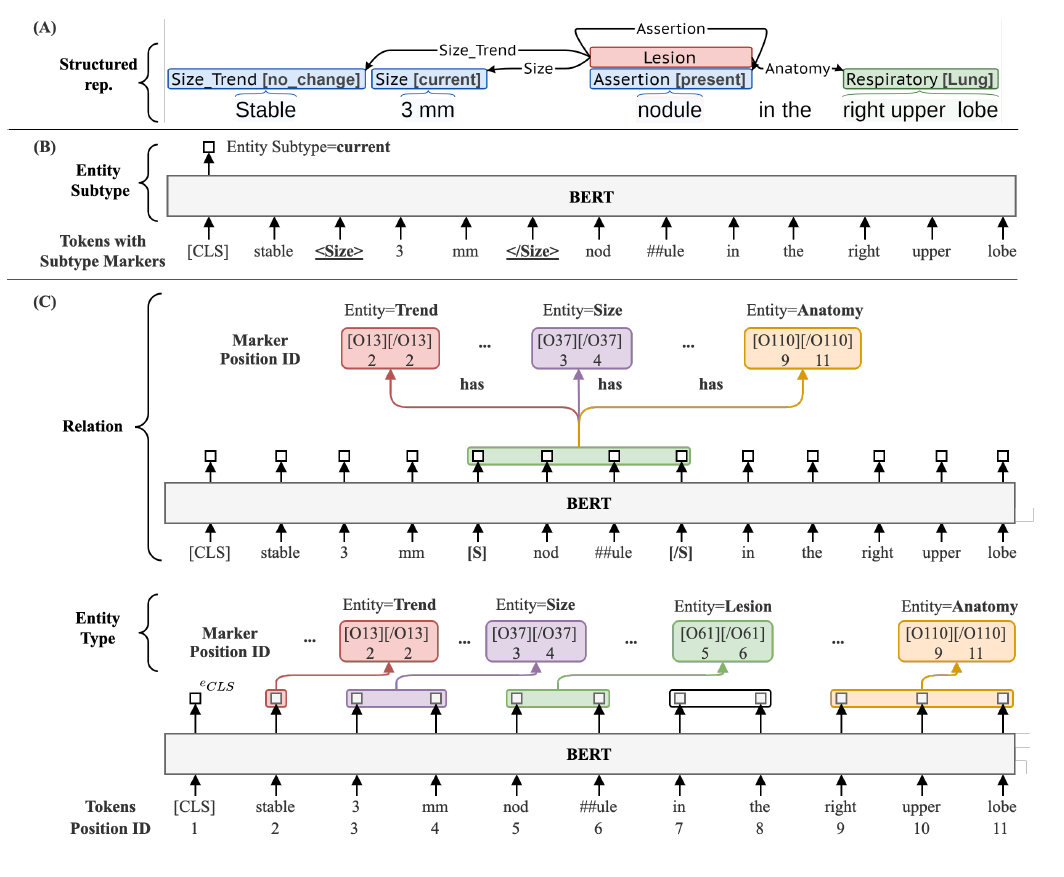
PL-Marker是一個多階段提取框架,第一階段識別各種主體信息,第二階段解析關系。為了提取CAMIR事件,研究團隊引入了PL-Marker的增強版PL-Marker++。唯一的區別在于第三個分類階段,用于帶值子類型的標簽。上圖展示了PL-Marker++架構,其中實體類型和關系階段與原始PL-Marker模型相同。
看到這里會比較燒腦,大白話的解釋就是C階段就是傳統的PL-marker框架,主要是提取每一段文字的各種主體信息(含開始和結束位置)、主體之間的關系。因為這樣的操作是并行計算,速度和效率可以得到保障。
而B階段就是所謂的第三分類階段,進一步將C階段的成果再次通過Bert基座識別出對應實體的額外信息。這個過程主要是C階段提煉的每一個實體對象插入標識符生成新的輸入。再講這個輸入利用Bert?CLS標記的隱藏狀態輸入外掛分類器,進而識別出每個主體的二級子類。最終一段文本被自動化的標注為結構化的語料庫。

標注結果
|
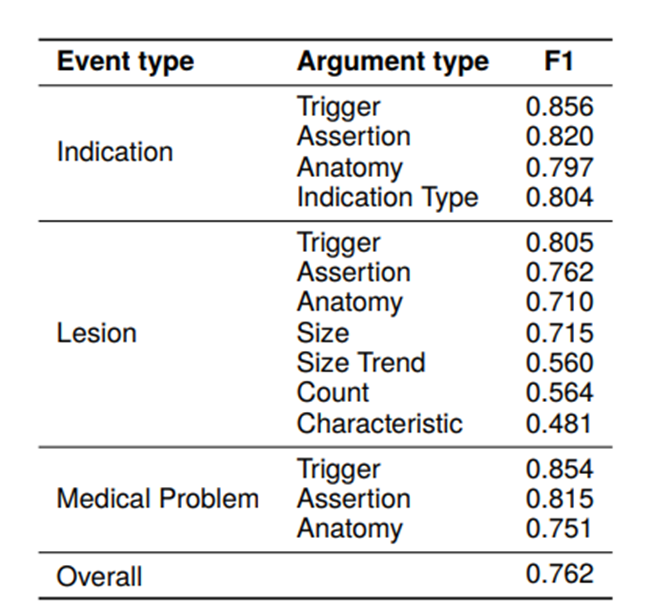
| 左圖給出了雙重標注報告的一致性(IAA)數據。對雙重標注報告中的所有觸發器和參數進行評估,總體一致性得分為0.762 F1。對于觸發器標注的一致性更高,指示(Indication)、病變(Lesion)和醫學問題(Medical Problem)分別為0.856、0.805和0.854 F1。尺寸(Size)、尺寸趨勢(Size Trend)和計數(Count)參數出現頻率遠低于其他參數,從而導致這些參數的一致性得分較低。特征(Characteristic)參數的語義非常多樣,導致頻繁的假陰性結果。 |
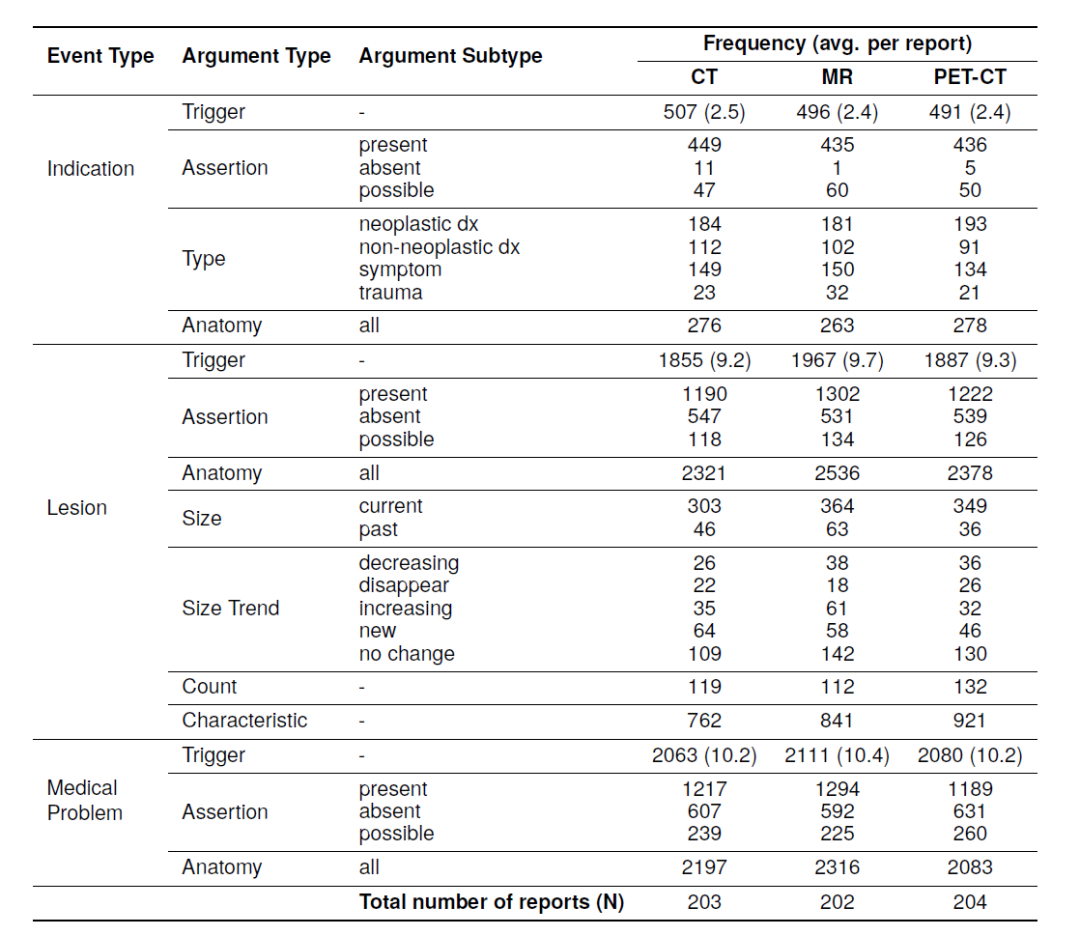
CAMIR中標注現象的分布情況。雖然成像方式的關注點可能有所不同,但大多數參數類型的標注在各成像方式間的分布相似。

兩種框架的效果對比
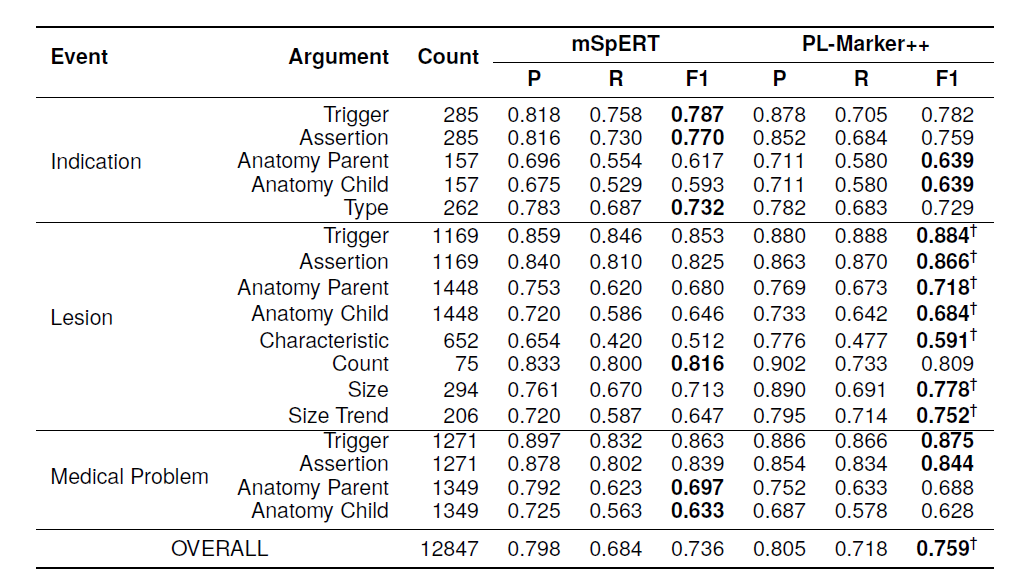
從上圖看,PL-Marker++相對于mSpERT取得了顯著更高的整體性能(0.759 F1 對比 0.736 F1)。盡管mSpERT和PL-Marker++模型在提取指示和醫學問題觸發器和參數方面的表現相似,但PL-Marker++在提取病變觸發器和除一種參數類型外的所有參數方面表現出色。PL-Marker++模型在提取病變事件的特征、尺寸和尺寸趨勢參數方面分別獲得了+?0.05 F1的提升。PL-Marker++整體性能的提高可歸因于通過BERT模型的所有層注入觸發器和參數位置信息。

總結
CAMIR語料庫憑借其獨特的事件結構與概念標準化結合的設計,連接了高度專業的放射學語言與機器學習算法。使海量非結構化的影像報告得以轉化為結構化數據,為科研人員、臨床醫生及醫療軟件開發者提供了寶貴的研究素材與開發資源。








)










