本文來源公眾號“CVHub”,僅用于學術分享,侵權刪,干貨滿滿。
原文鏈接:CVPR 2024 | 英偉達發布新一代視覺基礎模型: AM-RADIO = CLIP + DINOv2 + SAM

標題:《AM-RADIO: Agglomerative Vision Foundation Model Reduce All Domains Into One》
論文:https://arxiv.org/pdf/2312.06709
源碼:https://github.com/NVlabs/RADIO
1 導讀
AM-RADIO是什么?一張圖先來感受它的魅力:
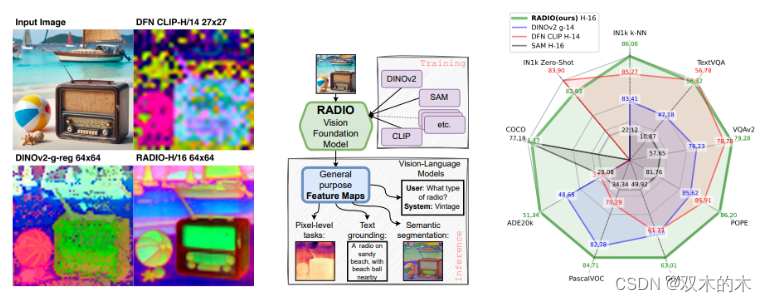
簡單來說,AM-RADIO 是一個由英偉達提出的一個視覺基礎模型框架,其集成了多個預訓練的視覺基礎模型如 CLIP、DINOv2及SAM 的能力,以獲得強大的表征能力,同時也以幾乎可以忽略不計的額外成本實現了SOTA級別的零樣本分類或開集實例分割性能。
如上圖左邊所示的PCA特征可視化結果,RADIO 模型可以處理任何分辨率和寬高比,并產生語義豐富的稠密編碼;上圖中間則展示了 RADIO 的框架圖;右側顯示了在分類、分割和視覺語言建模任務上的基準測試。
2 背景
Visual Foundation Models,VFMs,即視覺基礎模型是一個非常重要的概念,諸如 CLIP、DINOv2、SAM 這樣的 VFMs 通過不同的目標進行訓練,已逐漸成為許多下游任務的核心。
例如,CLIP 這樣的預訓練視覺語言模型在不同的下游視覺任務上展現了強大的零樣本泛化性能。這些模型通常使用從網絡收集的數百上千萬圖像-文本對進行訓練,并提供具有泛化和遷移能力的表示。因此,只需通過簡單的自然語言描述和提示,這些預訓練的基礎模型完全被應用到下游任務,例如使用精心設計的提示進行零樣本分類。
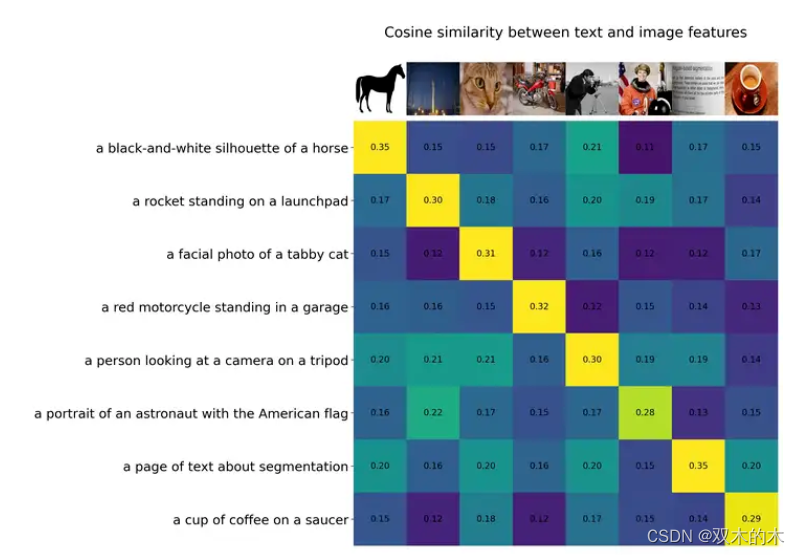
除了此類大型視覺語言基礎模型外,一些研究工作也致力于開發可以通過視覺輸入提示的大型基礎模型。例如,最近 meta 推出的 SAM 能夠執行與類別無關的分割,給定圖像和視覺提示(如框、點或蒙版),指定要在圖像中分割的內容。這樣的模型可以輕松適應特定的下游任務,如醫學圖像分割、視頻對象分割、機器人技術和遙感等。

最后,像 DINOv2,這種用于在大型圖像數據集上預訓練圖像編碼器,以獲得具有語義的視覺特征。這些特征可用于廣泛的視覺任務,無需微調即可獲得與有監督模型相當的性能。

本文發現,盡管它們在概念上存在差異,但這些模型可以通過多教師蒸餾有效地合并成一個統一模型,稱為Agglomerative Model – Reduce All Domains Into One,AM-RADIO,即聚合模型,旨在將所有領域縮減為一個。
這種整合方法不僅超越了單個教師模型的性能,而且融合了它們的獨特特征,如零樣本視覺-語言理解、詳細的像素級理解以及開放詞匯分割能力。
此外,為了追求最硬件效率高的主干網絡,本文在多教師蒸餾流程中評估了多種架構,使用相同的訓練策略;最終得到的新框架其性能超過了此前的SOTA模型,并且至少比教師模型在相同分辨率下快6倍,同時也在各大視覺任務取得了非常不錯的性能表現。
關于“視覺大模型”的更多介紹,請參考萬字長文帶你全面解讀視覺大模型。
3 方法
如上所述,本文提出一個框架,旨在通過多教師蒸餾從零開始訓練視覺基礎模型。這種方法的核心思想是利用多個已經在不同領域或任務上表現優異的教師模型來共同訓練一個新的模型,這個新模型將集成所有教師模型的獨特屬性。
在選擇的教師模型方面,作者選定了 CLIP、DINOv2 和 SAM 這三個主流的視覺基礎模型,因為它們在各自的領域(如圖像-文本匹配任務上,自監督學習任務上,開集分割任務)上都展現出了SOTA性能。
在訓練過程中,本文沒有使用額外的標簽信息,而是將ImageNet、LAION-400M和DataComp1B等數據集中的圖像作為訓練數據。這樣的做法使得模型能夠在沒有明確標簽指導的情況下學習到圖像的豐富表征。
為了評估模型的性能,作者采用了一系列度量標準,涵蓋了圖像級推理、像素級視覺任務、大型視覺-語言模型以及SAM-COCO實例分割等多個方面。
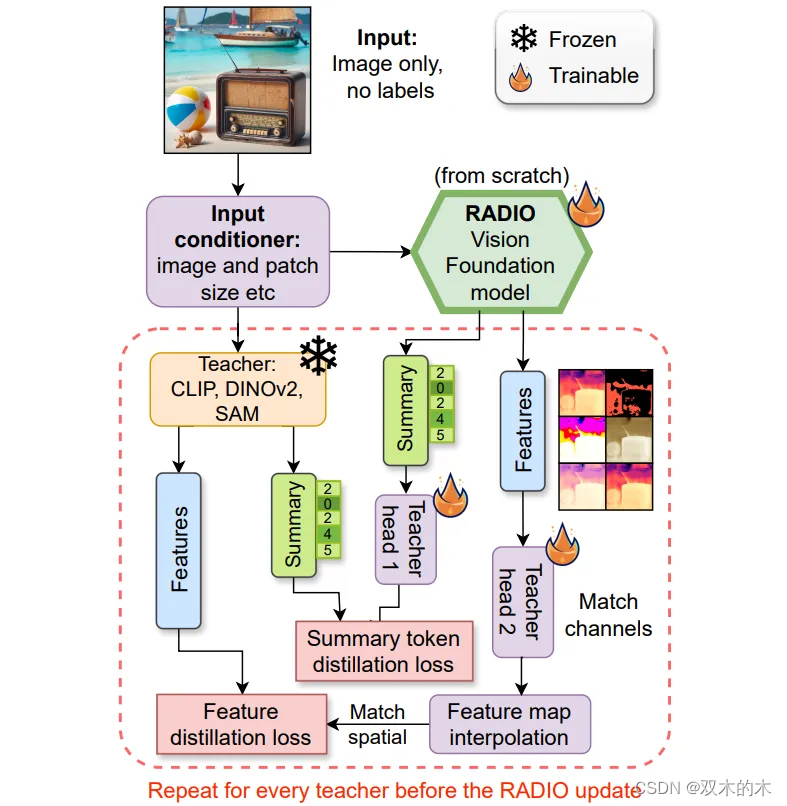
AM-RADIO: 多教師統一蒸餾框架
3.1 Adaptor Heads
在這一步中,作者選擇了簡單的設計方案,使用了一個簡單的2層多層感知機(MLP),中間夾雜著 LayerNorm 和 GELU 激活函數。Head 部分的輸入維度是學生模型嵌入的維度,中間維度是所有教師模型中最大的嵌入維度,輸出維度與特定教師模型相匹配。對于每個教師,作者使用了兩個 head,一個用于提取整體特征向量,另一個則用于保留空間特征。
3.2 Distillation Dataset
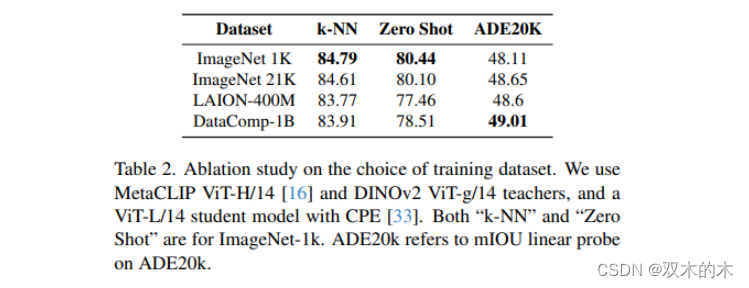
本文研究了不同數據集對下游指標的影響。雖然使用ImageNet-1K作為訓練數據集可以獲得最高的圖像分類指標,但作者認為這并不能公平地衡量“零樣本”性能,因為學生在評估域中直接學習到了教師的特征。因此,最終選擇了 DataComp-1B 數據集。
3.3 Loss Formulation
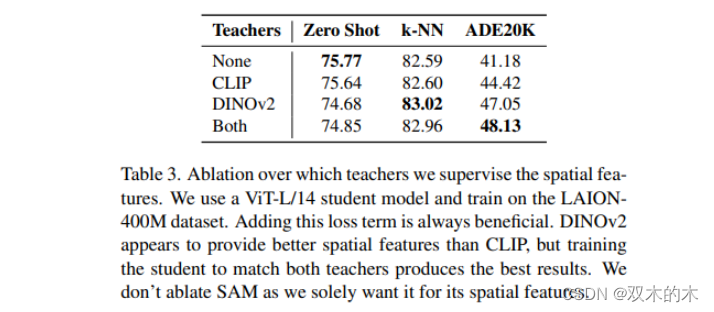
上面我們提到,這里訓練的時候不使用原有的GT,因此是通過選擇匹配來自每個教師視覺編碼器的特征。特別是,AM-RADIO 區分了每個教師的 Summary 特征向量和 Spatial 特征向量。
需要注意的是,對于CLIP和DINOv2,這里 Summary 特征向量使用的是“類 token”;而對于SAM,則不匹配此部分特征。
實驗發現,與 L1、MSE、Smooth-L1 相比,余弦距離損失能夠產生更好的結果。此外,通過匹配教師的空間特征來監督模型的 spatial features 不僅對下游密集任務重要,而且提高了模型的總體質量。
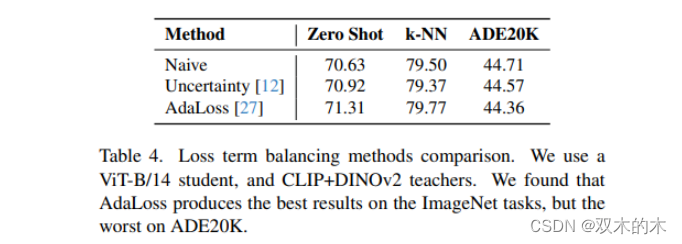
為此,對于匹配空間特征,作者采用了余弦相似性和Smooth L1的組合。
4 實驗細節
本文架構本質上沒有創新,只是對現有能力的充分利用,因此實驗的細節部分算是比較有價值的,下面簡單的總結羅列下,感興趣的可以看下原文。
-
訓練設置:
-
使用AdamW優化器、1024的批量大小、余弦退火學習率計劃和學習率基數為0.001。
-
訓練600k步,共查看614M個樣本。
-
最好的學生模型使用DFN CLIP ViT-H/14 378px、OpenAI CLIP ViT-L/14 336px、DINOv2 ViT-g/14 224px和SAM ViTDet-H 1024px作為教師。
-
對學生和教師的輸入應用隨機縮放+裁剪。
-
選擇DataComp-1B數據集,因為它在作者可訪問的網頁規模數據集中質量最高。
-
分兩個階段訓練:首先用CLIP+DINOv2在256px訓練300k步,然后用CLIP+DINOv2在432px加上SAM在1024px訓練300k步。
-
-
學生模型架構:
-
研究了兩種學生模型架構設置:標準ViT架構以匹配教師架構,以及高效架構變體優先考慮GPU上的高吞吐量。
-
-
多尺度教師:
-
學生模型選擇ViT-H/16架構。
-
為了匹配SAM特征的分辨率,學生模型輸入預期分辨率為1024^2。
-
由于CLIP和DINOv2教師是patch-14模型,學生輸入選擇432^2,這是patch-14模型378^2分辨率的有效分辨率。
-
發現插值DINOv2特征不會降低結果,因此教師以224px運行,并上采樣輸出以匹配學生。
-
-
排名/教師分區:
-
按照批次大小和輸入分辨率將教師模型分組,然后將這些組分配給不同的GPU,以便每個GPU處理一致的批次大小和輸入分辨率。
-
對于包含SAM的訓練設置,使用64個GPU,其中一半處理CLIP+DINOv2組,每個GPU的批次大小為32,輸入分辨率為432,另一半處理SAM,每個GPU的批次大小為2,輸入分辨率為1024,有效批次大小為1,152。對于CLIP+DINOv2訓練,使用32個GPU,批次大小為1024。
-
-
多分辨率ViTs:
-
許多學生模型使用ViT作為基礎視覺架構。
-
使用Cropped Position Embedding (CPE)增強,位置數等于128^2。
-
即使在224分辨率下訓練CLIP+DINOv2,也發現這種技術對摘要指標的影響可以忽略不計,但提高了語義分割線性探測的mIOU。
-
-
高分辨率ViT學生模型:
-
在SAM中,使用ViTDet架構減少高分辨率下ViT模型的計算和內存負擔。
-
將這種架構改寫為訓練增強,從中采樣窗口大小。
-
發現高分辨率訓練不穩定,因此應用譜重參數化和0.02的權重衰減以防止注意力熵崩潰。
-
-
學生/教師分辨率不匹配:
-
當學生和教師通過處理堆棧以不同速率下采樣圖像時,輸出特征向量的分辨率會不同。
-
對于Lfeatures,使用雙線性插值輸出以匹配學生和教師特征之間的較大分辨率。
-
5 實驗
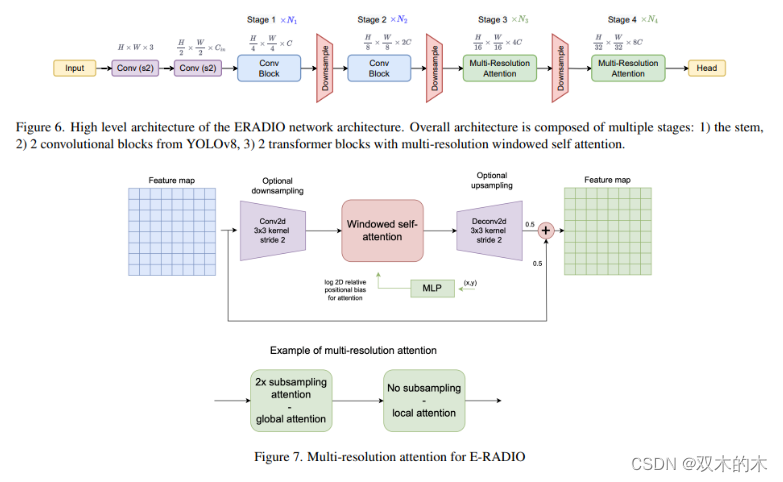
如上圖所示,E-RADIO是一個高效的RADIO架構,通過融合卷積塊和Transformer,以及局部和全局注意力機制,實現了對密集型預測任務的高性能和快速推理,相比全ViT架構效率顯著提高。
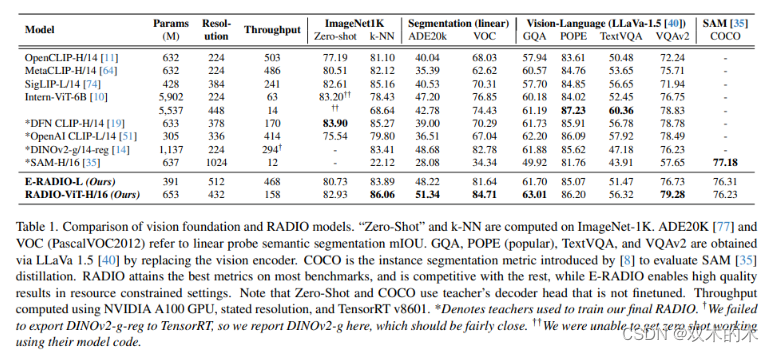
從表1的結果可以明顯的看出基于 MetaCLIP 比 OpenCLIP 效果更好,DFN CLIP 則能取得最佳的零樣本分類性能。DINOv2 則有助于語義分割這種任務。
此外,所設計的 ERADIO-L 模型比所有ViT模型都要快得多。同時,它在匹配吞吐量的情況下,在大多數指標上都明顯優于 MetaCLIP,并且還實現了 DINOv2 和 SAM 中缺失的零樣本能力。最終,完整模型 ViT-H/16 可以表現得與教師模型一樣快,但在9項任務中有6項超過了它們,這足以證明所提出的蒸餾框架是高效的。
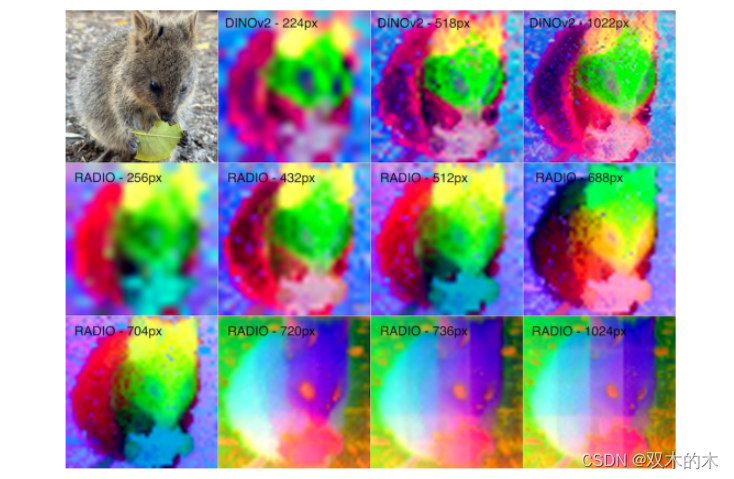
上圖展示了 RADIO 在分辨率增加時的“模式切換”。在圖表中,顯示了來自RADIO的DINOv2頭在不同分辨率下的特征之間的均方誤差(MSE),以及DINOv2在518px分辨率下實際產生的特征。通過將RADIO特征進行雙線性插值以匹配DINOv2特征的分辨率。在720px時,可以看出誤差突然增加,這對應于圖像中完全的顏色空間變化。
6 總結
大多數視覺基礎模型具有各自的優勢,例如語言定位(CLIP)、表征(DINOv2)和細粒度分割(SAM),但也存在各自的局限性。通過蒸餾,可以將所有這些優勢整合到一個模型中,該模型通常優于任何教師模型。
我們從實驗中還觀察到,更好的教師會產生更好的學生。此外,對于特征蒸餾損失。我們觀察到完整的特征蒸餾對于提高教師在密集圖像理解任務中的性能至關重要,例如在ADE20K上相對提高了18%。SAM與DINOv2的對比。
還有個有趣的結論,SAM 其實并不適合下游任務,而DINOv2在零樣本和少樣本任務中明顯優于前者,這大概還是得益于其強大的表征能力。不過,u1s1,SAM 在檢測邊緣和分割對象方面的表現還是非常出色的,但在高層對象描述和結合多個對象語義方面表現不佳。
本文提出的 RADIO 能夠產生高分辨率和低噪聲的特征。然而,我們可以發現的一個問題是,RADIO 似乎具有潛在的“低分辨率”和“高分辨率”模式,這可能是由于CLIP+DINO和SAM目標之間的分階段訓練導致的,這算是一個缺陷。
THE END !
文章結束,感謝閱讀。您的點贊,收藏,評論是我繼續更新的動力。大家有推薦的公眾號可以評論區留言,共同學習,一起進步。







)
)




——兩種復數移相算法)
Spring教程——依賴注入與控制反轉)
)



 函數)