StNet: Local and Global Spatial-Temporal Modeling for Action Recognition 論文閱讀
- Abstract
- 1 Introduction
- 2 Related Work
- 3 Proposed Approach
- 4 Experiments
- 5 Conclusion
文章信息:

原文鏈接:https://ojs.aaai.org/index.php/AAAI/article/view/4855
源碼:https://github.com/hyperfraise/Pytorch-StNet/tree/master
發表于:AAAI 2019
Abstract
這篇論文探討了視頻中的空間-時間建模的最有效網絡架構。與現有的CNN+RNN或純粹基于3D卷積的方法不同,我們提出了一種新穎的空間-時間網絡(StNet)架構,用于視頻中的局部和全局建模。具體而言,StNet將N個連續的視頻幀堆疊成一個超級圖像,該圖像具有3N個通道,并在超級圖像上應用2D卷積來捕獲局部空間-時間關系。為了建模全局空間-時間結構,我們在局部空間-時間特征圖上應用時間卷積。具體來說,StNet提出了一個新穎的時間Xception塊,它在視頻的特征序列上分別使用通道級和時間級的卷積。在Kinetics數據集上進行的大量實驗表明,我們的框架在動作識別方面優于幾種最先進的方法,并且可以在識別準確性和模型復雜性之間取得令人滿意的權衡。我們進一步展示了學習到的視頻表示在UCF101數據集上的泛化性能。
1 Introduction

圖1:局部信息足以區分“砌磚”和“砌石”,而全局空間-時間線索對于區分“疊牌”和“飛牌”是必要的。
視頻中的動作識別已經引起了計算機視覺和機器學習社區的重視(Karpathy等人,2014年;Wang和Schmid,2013年;Wang、Qiao和Tang,2016年;Simonyan和Zisserman,2014年;Fernando等人,2015年;Wang等人,2016年;Qiu、Yao和Mei,2017年;Carreira和Zisserman,2017年;Shi等人,2017年;Zhang等人,2016年)。錄制設備的普及使得我們遠遠超出了手動處理的能力。因此,開發自動視頻理解算法以用于各種應用(如視頻推薦、人類行為分析、視頻監控等)變得非常重要。在這個任務中,局部和全局信息都很重要,如圖1所示。例如,要識別“砌磚”和“砌石”,局部空間信息對于區分磚和石頭至關重要;而要分類“疊牌”和“飛牌”,全局空間-時間線索是關鍵證據。
受深度網絡在圖像理解任務上取得的可喜成果(Ioffe和Szegedy,2015年;He等人,2016年;Szegedy等人,2017年)的啟發,深度學習被應用到視頻理解問題中。針對動作識別,主要探索了兩個研究方向,即采用CNN+RNN架構進行視頻序列建模(Donahue等人,2015年;Yue-Hei Ng等人,2015年),以及純粹采用基于ConvNet的架構進行視頻識別(Simonyan和Zisserman,2014年;Feichtenhofer、Pinz和Wildes,2016年;2017年;Wang等人,2016年;Tran等人,2015年;Carreira和Zisserman,2017年;Qiu、Yao和Mei,2017年)。
盡管取得了相當大的進展,但當前的動作識別方法在動作識別準確性方面仍然落后于人類表現。主要挑戰在于從視頻中提取具有區分性的空間-時間表示。對于CNN+RNN解決方案,前饋CNN部分用于空間建模,而時序建模部分,即LSTM(Hochreiter和Schmidhuber,1997年)或GRU(Cho等人,2014年),由于其循環架構,使得端到端優化變得非常困難。然而,分別訓練CNN和RNN部分對于整合的空間-時間表示學習來說并不是最優的。
用于動作識別的卷積神經網絡可以大致分為2D卷積網絡和3D卷積網絡兩類。2D卷積架構(Simonyan和Zisserman,2014年;Wang等人,2016年)從采樣的RGB幀中提取外觀特征,僅利用局部空間信息而不是局部空間-時間信息。至于時間動態,它們簡單地融合了從幾個片段中獲得的分類分數。雖然對幾個片段的分類分數進行平均是直接而有效的,但可能不太有效地捕獲時空信息。C3D(Tran等人,2015年)和I3D(Carreira和Zisserman,2017年)是典型的基于3D卷積的方法,它們同時建模了空間和時間結構,并實現了令人滿意的識別性能。眾所周知,與更深的網絡相比,淺層網絡在從大規模數據集中學習表示方面表現出較差的能力。當涉及到大規模人類動作識別時,一方面,將淺層2D卷積網絡膨脹到它們的3D對應物可能不足以生成有區別的視頻描述符;另一方面,深層2D卷積網絡的3D版本將導致模型過大以及在訓練和推理階段的計算成本過高。
考慮到上述問題,我們提出了我們的新穎空間-時間網絡(StNet)來解決大規模動作識別問題。首先,我們通過在由N個連續視頻幀組成的3N通道超級圖像上應用2D卷積來考慮局部空間-時間關系。因此,與在N個圖像上進行3D卷積相比,局部空間-時間信息可以更有效地編碼。其次,StNet在超級圖像的特征圖上插入時間卷積,以捕獲它們之間的時間關系。局部空間-時間建模后接時間卷積可以逐步建立全局空間-時間關系,并且具有輕量級和計算友好的特點。第三,在StNet中,我們進一步使用我們提出的時間Xception塊(TXB)而不是對幾個片段的分數進行平均來編碼時間動態。受到可分離的深度卷積的啟發(Chollet,2017年),TXB以獨立的通道級和時間級的1D卷積方式編碼時間動態,以獲得更小的模型尺寸和更高的計算效率。最后,TXB是基于卷積而不是循環架構的,因此可以輕松通過隨機梯度下降(SGD)進行端到端的優化。
我們在新發布的大規模動作識別數據集Kinetics(Kay等人,2017年)上評估了提出的StNet框架。實驗結果表明,StNet優于幾種最先進的基于2D和3D卷積的解決方案,同時從FLOP數量的角度獲得了更好的效率,并在識別準確性方面比其3D CNN對應物更有效。此外,我們將StNet學習到的表示轉移到UCF101(Soomro、Zamir和Shah,2012年)數據集上,以驗證其泛化能力。
2 Related Work
在文獻中,基于視頻的動作識別解決方案可以分為兩類:使用手工特征的動作識別和使用深度卷積網絡的動作識別。為了開發有效的空間-時間表示,研究人員提出了許多手工特征,如HOG3D(Klaser、Marsza?ek和Schmid,2008年)、SIFT3D(Scovanner、Ali和Shah,2007年)、MBH(Dalal、Triggs和Schmid,2006年)。目前,改進的密集軌跡(Wang和Schmid,2013年)是手工特征中的最先進方法。盡管其表現良好,但這種手工特征設計用于局部空間-時間描述,難以捕獲語義級別的概念。由于引入深度卷積神經網絡取得了巨大進展,基于ConvNet的動作識別方法已經實現了比傳統手工特征方法更高的準確性。至于利用CNN進行基于視頻的動作識別,存在以下兩個研究方向:
Encoding CNN Features:CNN通常用于從視頻幀中提取空間特征,然后使用循環神經網絡或特征編碼方法對提取的特征序列進行建模。在LRCN(Donahue等人,2015年)中,視頻幀的CNN特征被饋送到LSTM網絡進行動作分類。ShuttleNet(Shi等人,2017年)引入了生物學啟發的反饋連接來模擬空間CNN描述符的長期依賴關系。TLE(Diba、Sharma和Van Gool,2017年)提出了捕捉視頻片段之間交互作用的時間線性編碼,并將這些交互作用編碼成緊湊的表示形式。類似地,VLAD(Arandjelovic等人,2016年;Girdhar等人,2017年)和AttentionClusters(Long等人,2018年)已被提出用于局部特征集成。
ConvNet as Recognizer:首次嘗試使用深度卷積網絡進行動作識別是由Karpathy等人(Karpathy et al. 2014年)完成的。盡管Karpathy等人(Karpathy et al. 2014年)在動作識別方面取得了強大的結果,但融合了基于RGB的空間流和基于光流的時間流的預測分數的雙流ConvNet(Simonyan和Zisserman 2014年)在性能上取得了顯著改進。STResNet(Feichtenhofer、Pinz和Wildes 2016年)在(Simonyan和Zisserman 2014年)的兩個流之間引入了殘差連接,并展示了結果上的巨大優勢。為了建模視頻的長期時間結構,提出了Temporal Segment Network(TSN)(Wang等人,2016年),通過稀疏時間采樣策略實現了有效的視頻級監督,并進一步提升了基于ConvNet的動作識別器的性能。
觀察到2D卷積網絡不能直接利用動作的時間模式,因此空間-時間建模技術被更加顯式地引入。C3D(Tran等人,2015年)將3D卷積濾波器應用于視頻中以學習空間-時間特征。與2D卷積網絡相比,C3D具有更多的參數,要獲得良好的收斂性要困難得多。為了克服這一困難,T-ResNet(Feichtenhofer、Pinz和Wildes,2017年)在空間卷積網絡的層之間注入了時間快捷連接,以擺脫3D卷積。I3D(Carreira和Zisserman,2017年)通過將傳統的2D卷積網絡架構擴展為3D卷積網絡,同時從視頻中學習空間-時間表示。P3D(Qiu、Yao和Mei,2017年)將3D卷積濾波器解耦為2D空間卷積濾波器,后跟1D時間卷積濾波器。最近,有許多框架提出了改進3D卷積的方法(Zolfaghari、Singh和Brox,2018年;Wang等人,2018a年;Xie等人,2018年;Tran等人,2018年;Wang等人,2018b年;Chen等人,2018年)。我們的工作不同之處在于,通過對局部空間-時間特征圖進行時間卷積逐漸建模空間-時間關系。
3 Proposed Approach
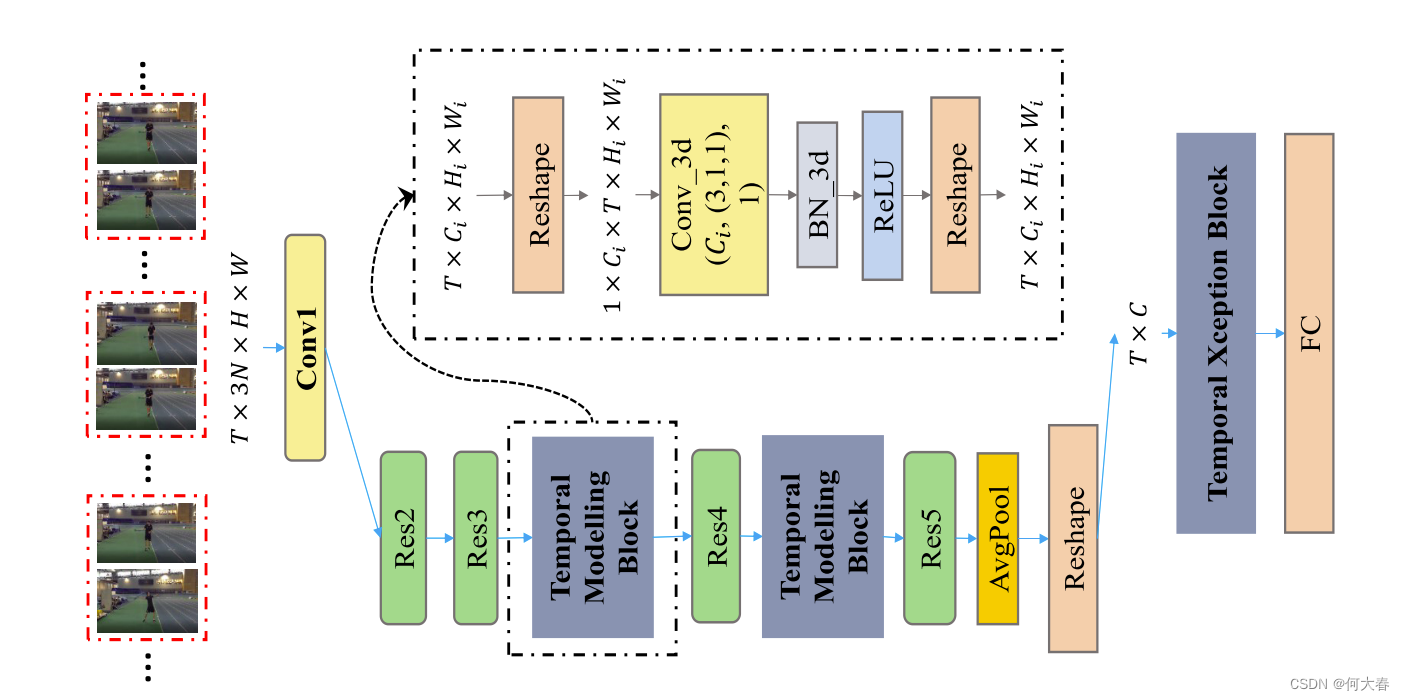
圖2:基于ResNet(He等人,2016年)骨干構建StNet的示意圖。StNet的輸入是一個 T × 3 N × H × W T\times3N\times H\times W T×3N×H×W張量。局部空間-時間模式通過2D卷積進行建模。3D卷積被插入到Res3和Res4塊之后,用于長期時間動態建模。3D卷積的設置(# 輸出通道數,(時間核大小,高度核大小,寬度核大小),# 組)是 ( C i , ( 3 , 1 , 1 ) , 1 ) (C_i,(3,1,1),1) (Ci?,(3,1,1),1)。
提出的StNet可以從現有的最先進的2D卷積網絡框架中構建,例如ResNet(He等人,2016年)、InceptionResNet(Szegedy等人,2017年)等等。以ResNet為例,圖2說明了我們如何從現有的2D卷積網絡構建StNet。從其他2D卷積網絡框架(如InceptionResNetV2(Szegedy等人,2017年)、ResNeXt(Xie等人,2017年)和SENet(Hu、Shen和Sun,2018年))構建StNet類似。因此,我們在這里不詳細說明所有這些細節。
Super-Image:受TSN(Wang等人,2016年)啟發,我們選擇通過對時間片段進行采樣來建模長期的時間動態,而不是輸入整個視頻序列。與TSN的一個不同之處在于,我們對T個時間段進行采樣,每個時間段由N個連續的RGB幀組成,而不是單個幀。這N幀在通道維度上堆疊以形成一個超級圖像,因此網絡的輸入是大小為T×3N×H×W的張量。超級圖像不僅包含由單個幀表示的局部空間外觀信息,還包含這些連續視頻幀之間的局部時間依賴關系。為了共同建模其中的局部空間-時間關系,并且節省模型權重和計算成本,我們在每個T個超級圖像上利用2D卷積(其輸入通道大小為3N)。具體來說,局部空間-時間相關性由ResNet的Conv1、Res2和Res3塊內的2D卷積核建模,如圖2所示。在我們當前的設置中,N被設置為5。在訓練階段,除了第一個卷積層外,2D卷積塊的權重可以直接從ImageNet預訓練的骨干2D卷積模型中初始化。Conv1的權重可以按照I3D(Carreira和Zisserman,2017年)中作者的做法進行初始化。
Temporal Modeling Block:應用在T個超級圖像上的2D卷積產生了T個局部空間-時間特征圖。構建采樣的T個超級圖像的全局空間-時間表示對于理解整個視頻至關重要。具體而言,我們選擇在Res3塊和Res4塊之后插入兩個時間建模塊。這些時間建模塊被設計用于捕獲視頻序列中的長期時間動態,它們可以通過利用Conv3d-BN3d-ReLU的架構輕松實現。值得注意的是,現有的2D卷積網絡框架已經足夠強大,可以用于空間建模,因此我們將3D卷積的空間卷積核大小都設置為1,以節省計算成本,而將時間卷積核的大小經驗性地設置為3。在Res3塊和Res4塊之后應用兩個時間卷積層的計算成本增加非常有限,但能夠有效地逐步捕獲全局空間-時間相關性。在時間建模塊中,Conv3d層的權重初始設置為 1 / ( 3 × C i ) 1/(3×C_i) 1/(3×Ci?),其中 C i C_i Ci?表示輸入通道的大小,偏置設置為0。BN3d被初始化為一個恒等映射。
Temporal Xception Block:我們的時間Xception塊是為了在特征序列中進行高效的時間建模并以端到端的方式進行簡單優化而設計的。我們選擇時間卷積來捕獲時間關系,而不是循環架構,主要是為了端到端訓練的目的。與普通的1D卷積不同,后者同時捕獲通道維和時間維信息,我們將通道維和時間維的計算分開,以提高計算效率。時間Xception架構如圖3(a)所示。特征序列被視為一個 T × C i n T×C_{in} T×Cin?的張量,這個張量是通過從T個超級圖像的特征圖上進行全局平均池化得到的。然后,沿著通道維度應用1D批量歸一化(Ioffe和Szegedy,2015年)來處理已知的協方差偏移問題,輸出信號是V。
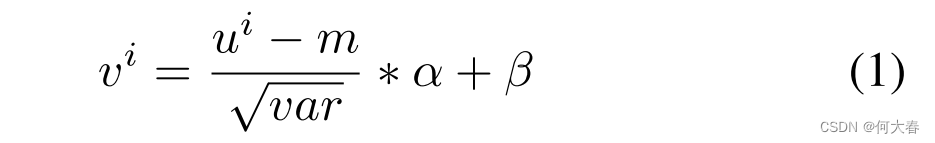
其中, v i v^i vi和 u i u^i ui分別表示輸出信號和輸入信號的第 i i i行; α \alpha α和 β \beta β是可訓練參數, m m m和 v a r var var是輸入小批量數據的累積運行均值和方差。為了建模時間關系,沿著時間維度的卷積應用于 V V V。我們將時間卷積分解為單獨的通道維和時間維的1D卷積。從技術上講,對于通道維的1D卷積,時間核大小設置為3,并且核的數量和組數設置為與輸入通道數相同。在這種情況下,每個核在單個通道內沿時間維進行卷積。對于時間維的1D卷積,我們將核的大小和組數都設置為1,這樣時間維的卷積核可以在每個時間步上跨越沿著通道維的所有元素進行操作。形式上,通道維和時間維的卷積可以分別描述為方程2和方程3。
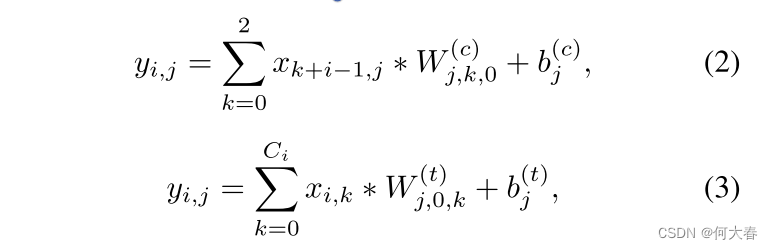
其中, x ∈ R T × C i x\in \mathbb{R}^{T\times C^i} x∈RT×Ci 是長度為 T T T的輸入 C i C_i Ci?維特征序列, y ∈ R T × C o y\in \mathbb{R}^{T\times C_o} y∈RT×Co? 表示輸出特征序列, y i , j y_{i,j} yi,j?是第 i i i個特征的第 j j j個通道的值,*表示乘法。在方程2中, W ( c ) ∈ R C o × 3 × 1 W^{(c)}\in \mathbb{R}^{C_o\times 3\times 1} W(c)∈RCo?×3×1 表示通道維卷積核,其參數為(#核,核大小,#組)=( C o C_o Co?,3, C i C_i Ci?)。在方程3中, W ( t ) ∈ R C o × 1 × C i W^{(t)}\in \mathbb{R}^{C_o\times 1\times C_i} W(t)∈RCo?×1×Ci? 表示時間維卷積核,其參數為(#核,核大小,#組)=( C o C_o Co?,1,1)。 b b b表示偏置。本文中, C o C_o Co?被設定為1024。單獨通道和時間維卷積的直觀示意圖可以在圖3(b)中找到。
如圖3(a)所示,與(He等人,2016年)的瓶頸設計類似,時間Xception塊有一個長支路和一個短支路。短支路是一個單一的1D時間維卷積,其核大小和組大小都為1。因此,短支路具有1的時間感受野。與此同時,長支路包含兩個通道維1D卷積層,因此具有5的時間感受野。直覺是,融合具有不同時間感受野大小的支路有助于更好地建模時間動態。時間Xception塊的輸出特征被送入沿時間維度的1D最大池化層,池化后的輸出被用作空間-時間聚合描述符進行分類。
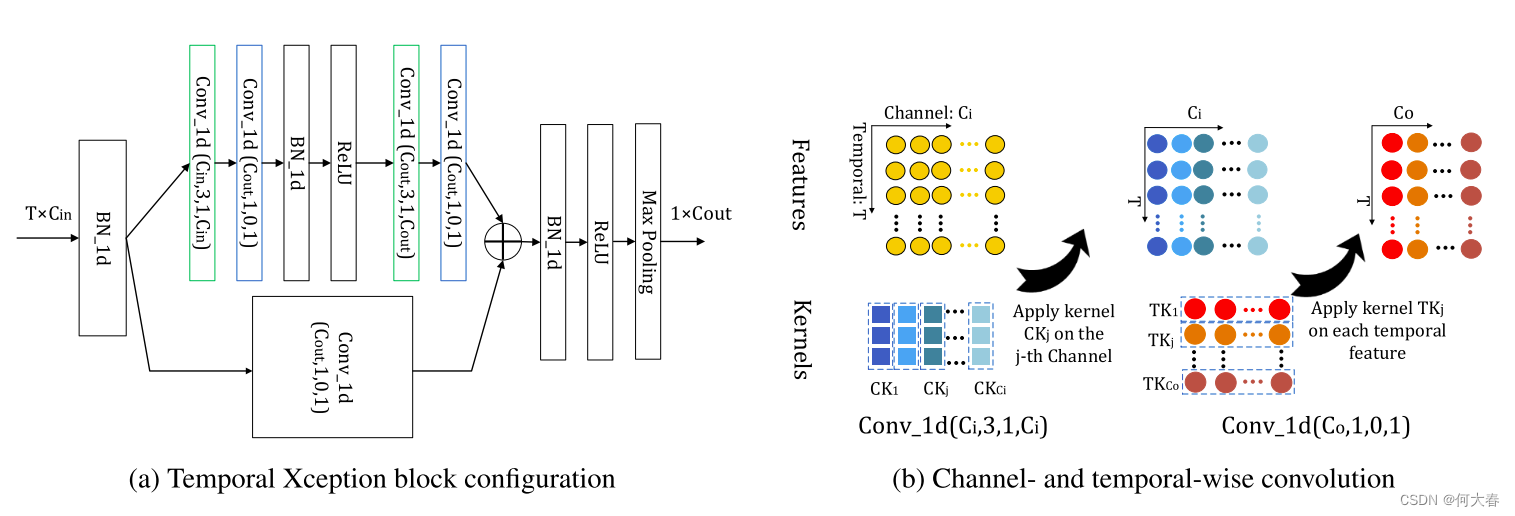
圖3:時間Xception塊(TXB)。我們提出的時間Xception塊的詳細配置如(a)所示。括號中的參數表示1D卷積的(#核,核大小,填充,#組)配置。綠色塊表示通道維1D卷積,藍色塊表示時間維1D卷積。 (b)描述了通道維和時間維的1D卷積。TXB的輸入是視頻的特征序列,表示為一個 T × C i n T\times C_{in} T×Cin?的張量。通道維1D卷積的每個核只沿著一個通道的時間維進行應用。時間維1D卷積核在每個時間步上跨越所有通道進行卷積。
4 Experiments
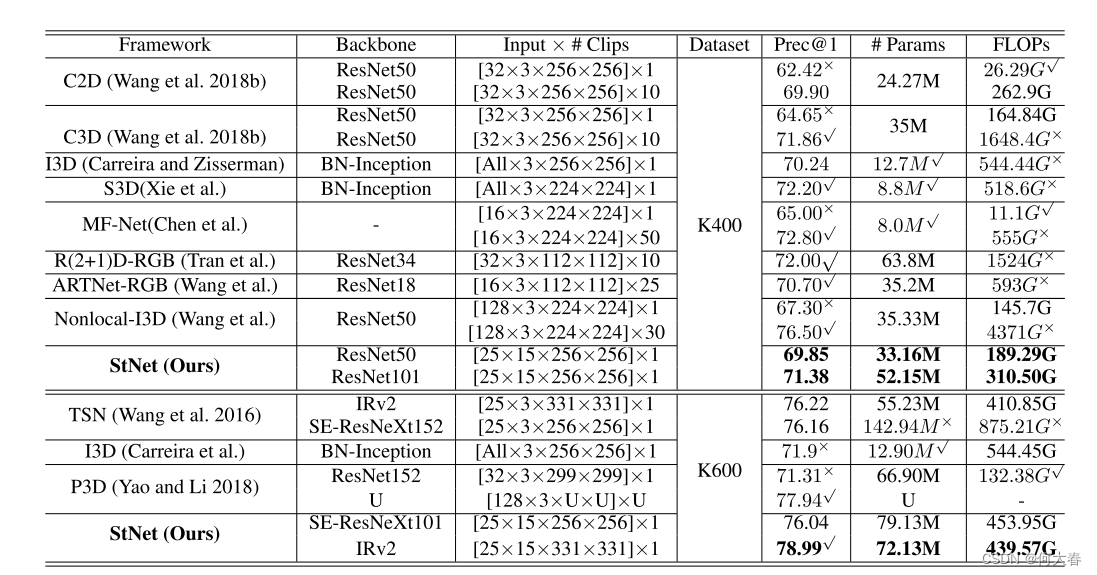
5 Conclusion
在本文中,我們提出了StNet,用于聯合局部和全局空間-時間建模,以解決視頻動作識別問題。通過在采樣的超級圖像上應用2D卷積來對局部空間-時間信息進行建模,同時通過對超級圖像的局部空間-時間特征圖進行時間卷積來編碼全局時間交互。此外,我們提出了一個時間Xception塊來增強建模時間動態的能力。這樣的設計選擇使得我們的模型在訓練和推理階段都相對輕量級和計算效率高。因此,它允許使用最強大的2D CNN在大規模數據集上實例化StNet,并提高最終的動作識別準確性。在大規模動作識別基準Kinetics上進行了大量實驗證實了StNet的有效性。此外,在Kinetics數據集上訓練的StNet在UCF101數據集上展現出了相當好的遷移學習能力。

)
)




——兩種復數移相算法)
Spring教程——依賴注入與控制反轉)
)



 函數)
 ——路由請求與相關參數)




