Prometheus 概述
- promethues 是一套開源的監控&報警&時間序列數據庫的組合
- 基本原理是通過http協議周期性抓取被監控組件的狀態
- 適合Docker、Kubernetes環境的監控系統
Promethues 整體架構

一、抓取數據的兩種方式
- 1 )Short-lived jobs 短暫的任務
- 不會提供長時間的http去為promethues抓取數據
- 這個服務很短暫, 運行后就會關閉
- 短暫的服務怎么去監控
- 它是通過主動推送數據到網關,進而由 promethues server 端 去抓取 PushGateway 上推上來的數據
- 2 )另一種方式是 ClientLib/Exporters
- 可以通過不同的 exporters 提供http的方式
- 來給 promethues server 來抓取數據
二、Promethues Server 端
- 主要分為三個環節:抓取,存儲,查詢
- 在抓取網關的時候,promethues server 端如何知道抓取哪些鏈接
- 獲取目標的時候,是通過配置文件,文本文件,consul等方式
- 來存儲我們的抓取目標
- 比較常用的是通過配置文件來記錄下抓取的目標
- Promethues 根據抓取目標,定期采集數據
- 當 Promethues 抓取完成后,進行存儲階段
- Promethues 會根據報警規則計算是否滿足報警規則
- 在報警規則中,會提供報警消息,主動推送給報警模塊
- 報警模塊在收到消息后進行一系列的處理來進行報警
- 另外數據存儲進來,提供給客戶訪問的時候
- Promethues 還有一個簡單的web ui, 通過界面的方式查詢存儲的數據
- 以上就是 Promethues 整體架構圖
三、Promethues 重要組件
- 基于架構圖,可知里面有很多重要組件
- Prometheus Server
- 用于收集和存儲時間序列數據
- 客戶端存儲用的是 時序 數據庫
- Client Library
- 客戶端庫生成相應的 metrics 并暴露給 Prometheus Server 去采集
- 課程里就是 客戶端提供http的端口暴露給 Prometheus Server 讓它定期采用數據,達到監控能力
- Push Gateway
- 主要用于短期的jobs
- 短期任務,可能5s采集一次,短期任務可能5s內會完成
- 這樣server端可能采集不到
- 所以,短期任務,可以主動上報到 Push Gateway 上
- Server 定期采集 Push Gateway 上的數據
- Exporters
- 用于暴露已有的第三方服務的metrics 給 Prometheus
- 第三方服務,比如 mysql, redis, mongodb, 等等已經寫好的一些 exporters 拿來用
- 主動把需要采集的功能暴露出來,server主動來采集
- Alertmanager
- 報警模塊,從 Prometheus server 端接收到 alerts 后
- 會進行一些列去除重復,分組,并路由到接受方式,發出報警
- 通過微信,email, QQ等等,都是可以進行發送的
Promethues 工作流程
- promethues server 定期從配置好的 jobs/exporters/PushGateway中拉數據
- promethues server 記錄數據并根據報警規則推送 alert 數據
- alertmanager 根據配置文件,對接收到的警報進行處理,發出告警
- 在圖形界面中,可視化采集數據,提供一個簡單的 web ui,也有一個漂亮的ui工具,在后面介紹
Promethues 數據模型
- 規定方式存儲數據就是數據模型
- promethues 中存儲的數據為時間序列
- 格式上由 metric 的名字和一系列的標簽(鍵值對)唯一標識組成
- 不同的標簽則代表不同的時間序列
promethues 相關概念 - metric(指標)類型
- Counter 類型
- 一種累加的指標,如:請求的個數,出現的錯誤數等
- Gauge 類型
- 可以任意加減,如:溫度,運行的 goroutines 的個數
- Histogram 類型
- 可以對觀察結果采樣,分組以及統計,如:柱狀圖
- Summary 類型
- 提供觀測值的 count 和 sum 功能,如:請求持續時間
Promethues 相關概念 - instance 和 jobs
- instance: 一個單獨監控的目標,一般對應于一個應用進程
- jobs: 一組同類型的 instances 的組合 (主要用于保證可擴展性和可靠性)
- 理解:
- 假設應用程序處理能力不夠,橫向擴展了3個應用程序
- 分別調用這3個應用程序進行監控,但是代碼上寫的包括暴露端口都一樣
- 我們要監控這一塊,要通過 instance 和 jobs 來進行組合
- 它提供 handler,不同的服務,它認為是不同的 instance
- 它這個服務及時不一樣,但類型是一樣的,會基于相同類型組成一個 jobs
- 這樣,不管應用程序擴展了多少個,都可以很細粒度來監控我們的程序
微服務監控系統 grafana 看板
- 擁有豐富的 dashboard 和 圖表編輯的指標分析平臺
- 擁有自己的權限管理和用戶管理系統
- 如果要擴展它,可以在基礎上進行定制
- Grafana 更適合用于數據可視化展示
- 在日常工作中發現,它的數據可視化展示能力非常的強
微服務監控系統 Promethues + Grafana 安裝
1 )拉取鏡像
- $
docker pull prom/prometheus - $
docker pull grafana/grafana
2 )基于 docker-compose 部署
version: "2"services:prometheus:image: prom/prometheus# network_mode: "host"container_name: prometheus-composeports:- "9090:9090"volumes:- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml #prometheus主配置文件- ./prometheus/prometheus-data:/prometheus #數據存儲映射- ./prometheus/conf:/etc/prometheus/conf #prometheus子配置文件路徑command:- '--config.file=/etc/prometheus/prometheus.yml' #加載主配置文件- '--storage.tsdb.path=/prometheus' #啟動數據持久存儲restart: alwaysgrafana:image: grafana/grafana# network_mode: "host"container_name: grafana-composeports:- "3000:3000"volumes:# - ./grafana/grafana.ini:/etc/grafana/grafana.ini #grafana配置文件- ./grafana/grafana_data:/var/lib/grafana #數據存儲映射restart: always
下面開始寫這個 prometheus.yml
global:scrape_interval: 15s # 默認15s采集一次external_labels: # 額外的標簽 全局的配置monitor: 'go-micro-xxx-monitor'
scrape_configs:# 監控的服務:按照一個個的job來監控的- job_name: 'services-order'scrape_interval: 5s # 覆蓋默認值static_configs:- targets: ['192.168.1.7:9092'] # 這個地址是容器能夠訪問到的地址,寫本機地址, 這個地址在容器或k8s中是會變的, 這個端口是 services-order 的端口
- 運行:$
docker-compose up - 運行起來后,進入prometheus UI界面,訪問 ip:9090
- 注意:
- prometheus 如果運行在K8s中,這個地址就要特別注意
- 這里只是用本機來進行prometheus的搭建測試
- 上面9092端口是services-order中暴露出來的
- 服務自定義的prometheus端口,以此來采集自身服務的信息
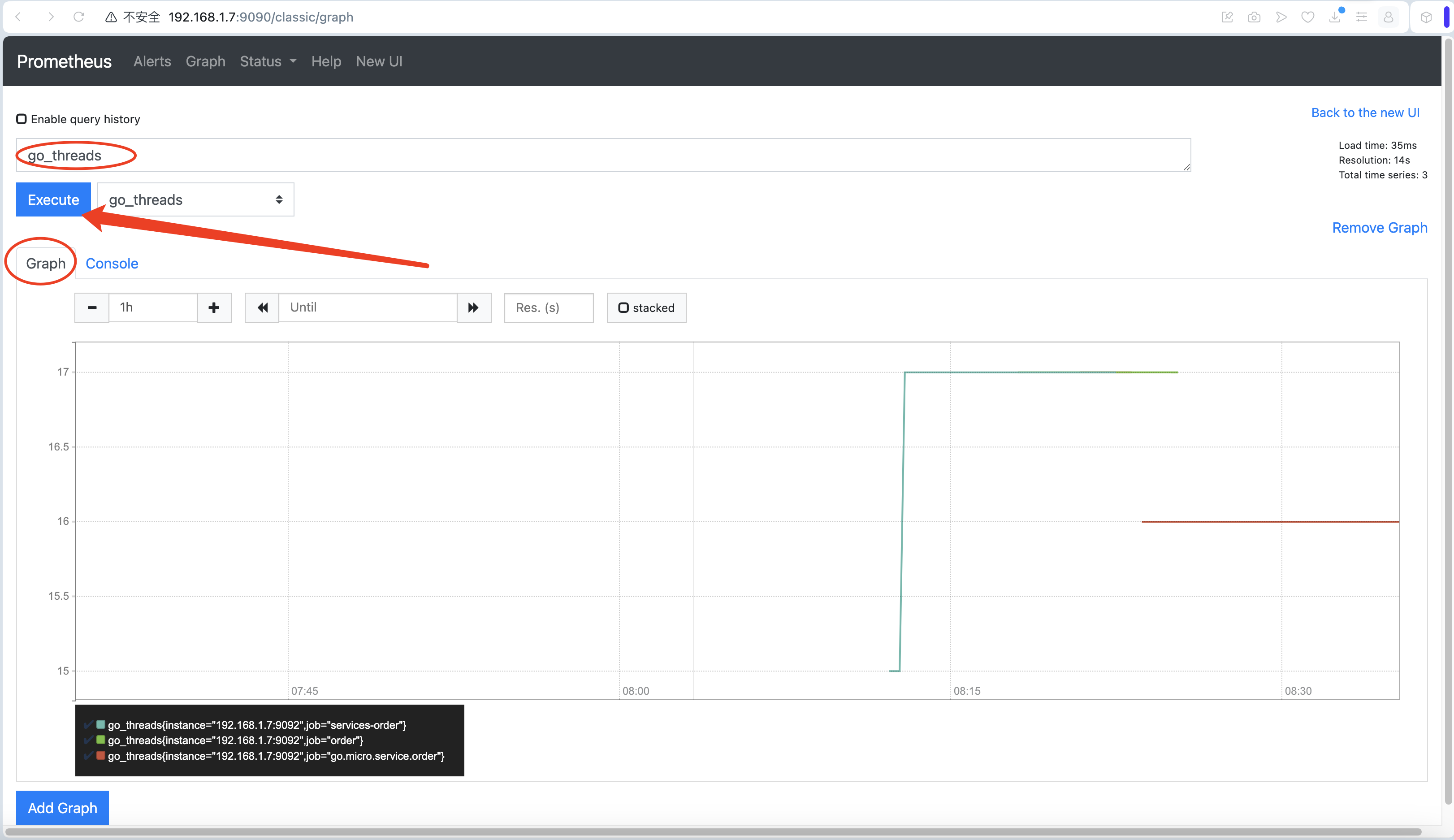
- 在界面上看下它的 targets ,位置 (上導航,Status 下拉 targets)

- 點進去 ip:9092/metrics 可以看到一些日志
- 也可以針對一些指標,使用圖表查看
- 監控系統控制臺 ip:3000 來訪問, 進入 grafana 看板
- 輸入 admin/admin 之后輸入新的密碼
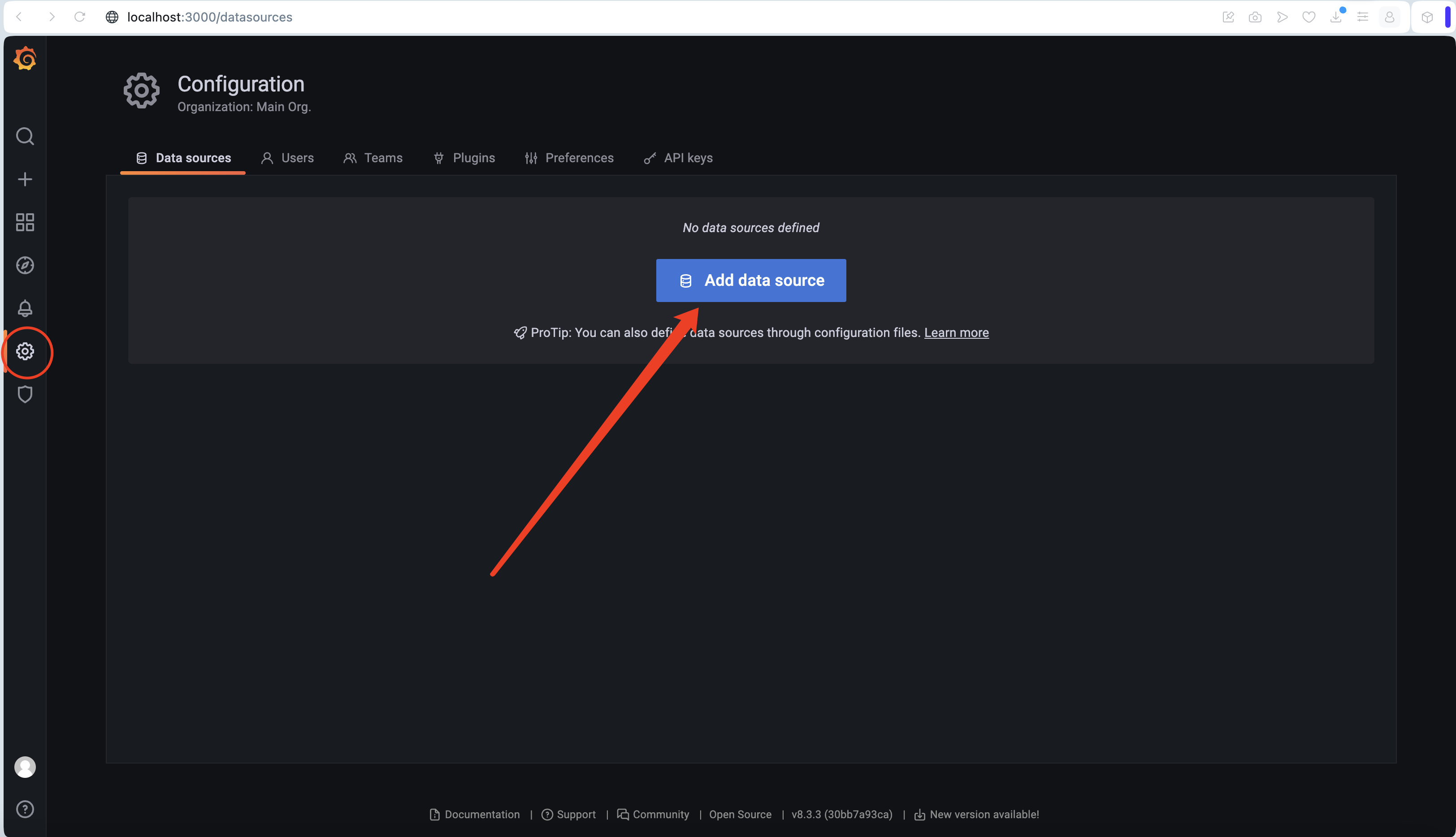
- 進入界面后,左側倒數第二個菜單,第一個 Configuration 點擊 Add data source
- 選擇 第一個 Prometheus 作為我們的源
- 配置url,這就是 Prometheus 在哪臺服務器,能訪問到 9090,這是本機,本機的ip:9090

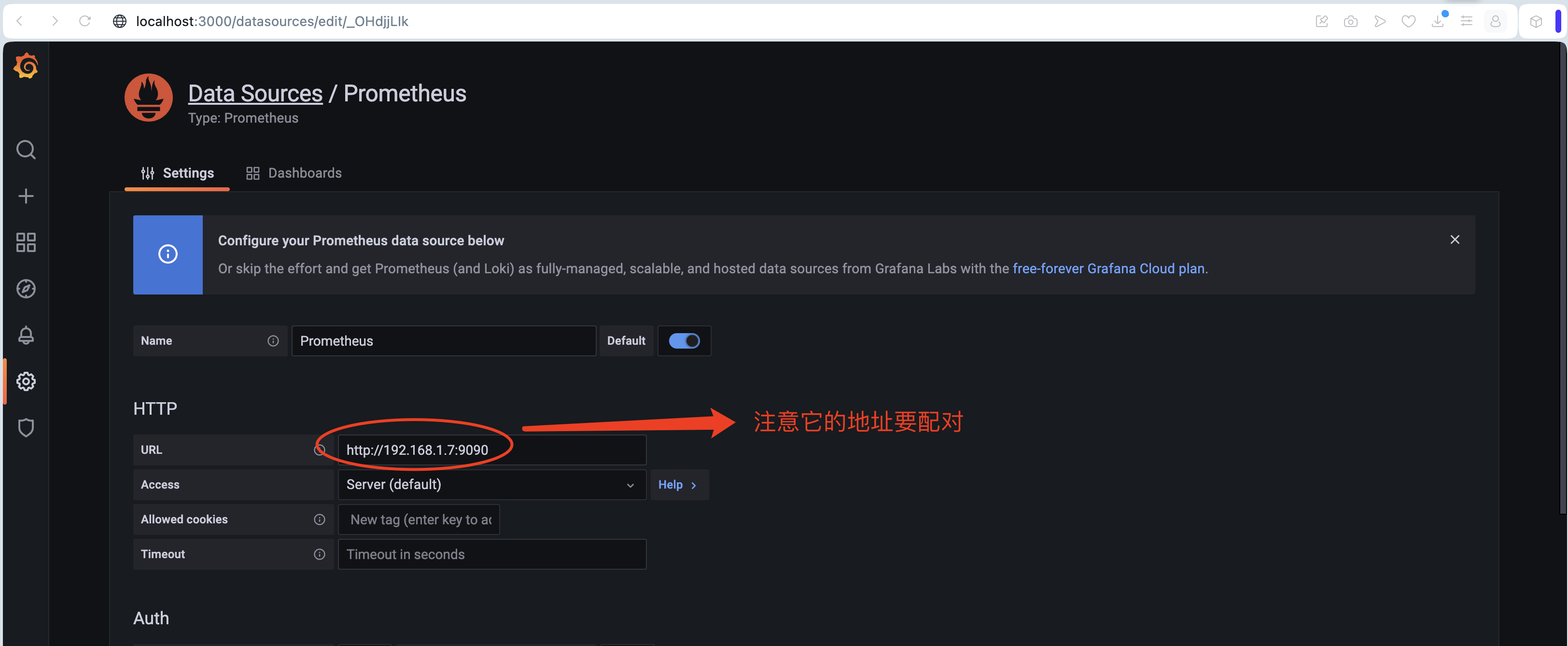
- 之后,點擊下面的 Save & test 按鈕
- 出現 Data source is working 的提示就說明成功了
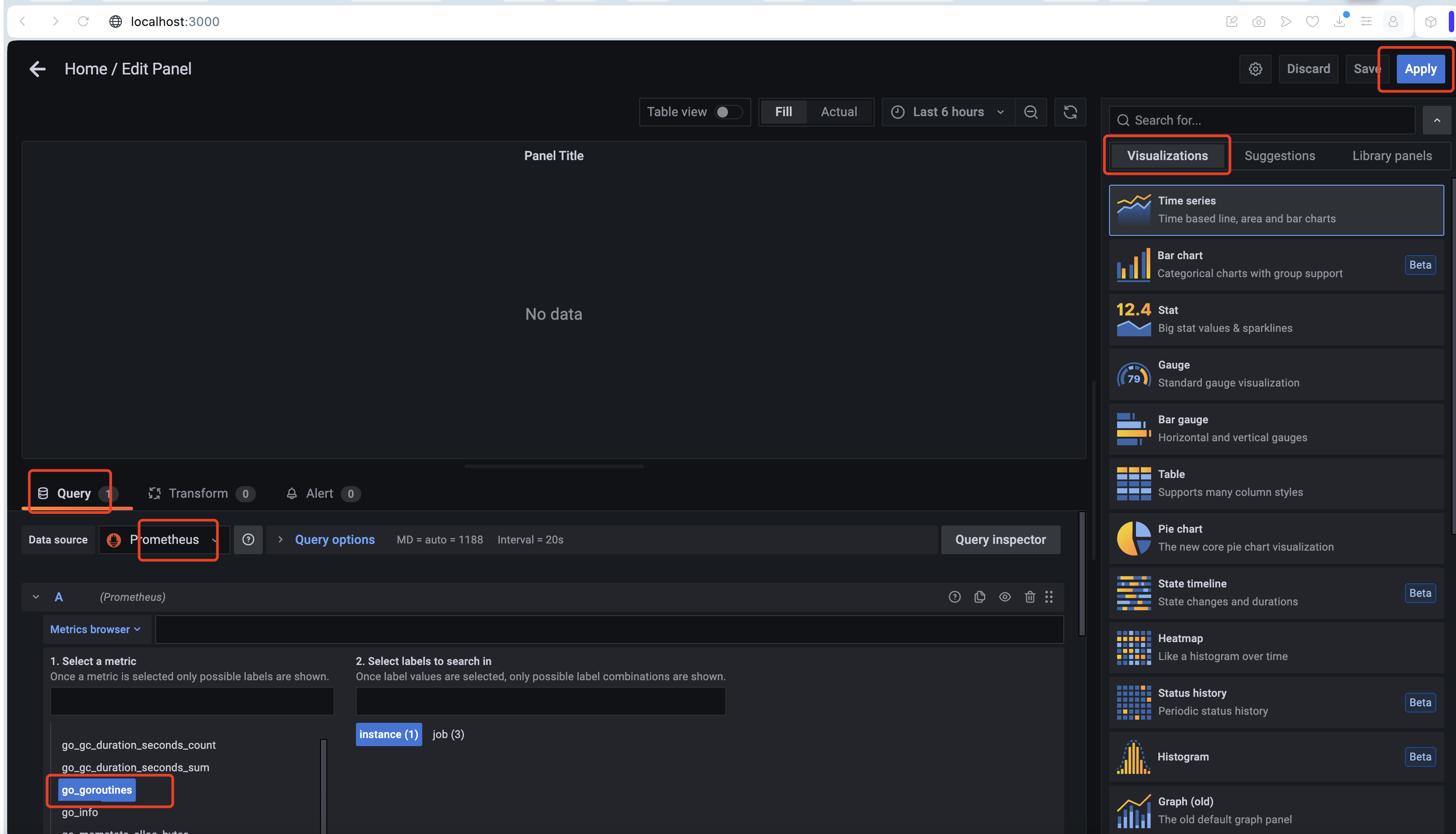
- 點擊導航頂部的 Add penel 圖表, 開始配置看板,如上圖
- 在 Query 下選擇 Prometheus
- 在 Metrics 中 選擇 go / go_memstats_gc_sys_bytes
- 在右側 Panel 下的 Visualization 選擇合適的 graphl
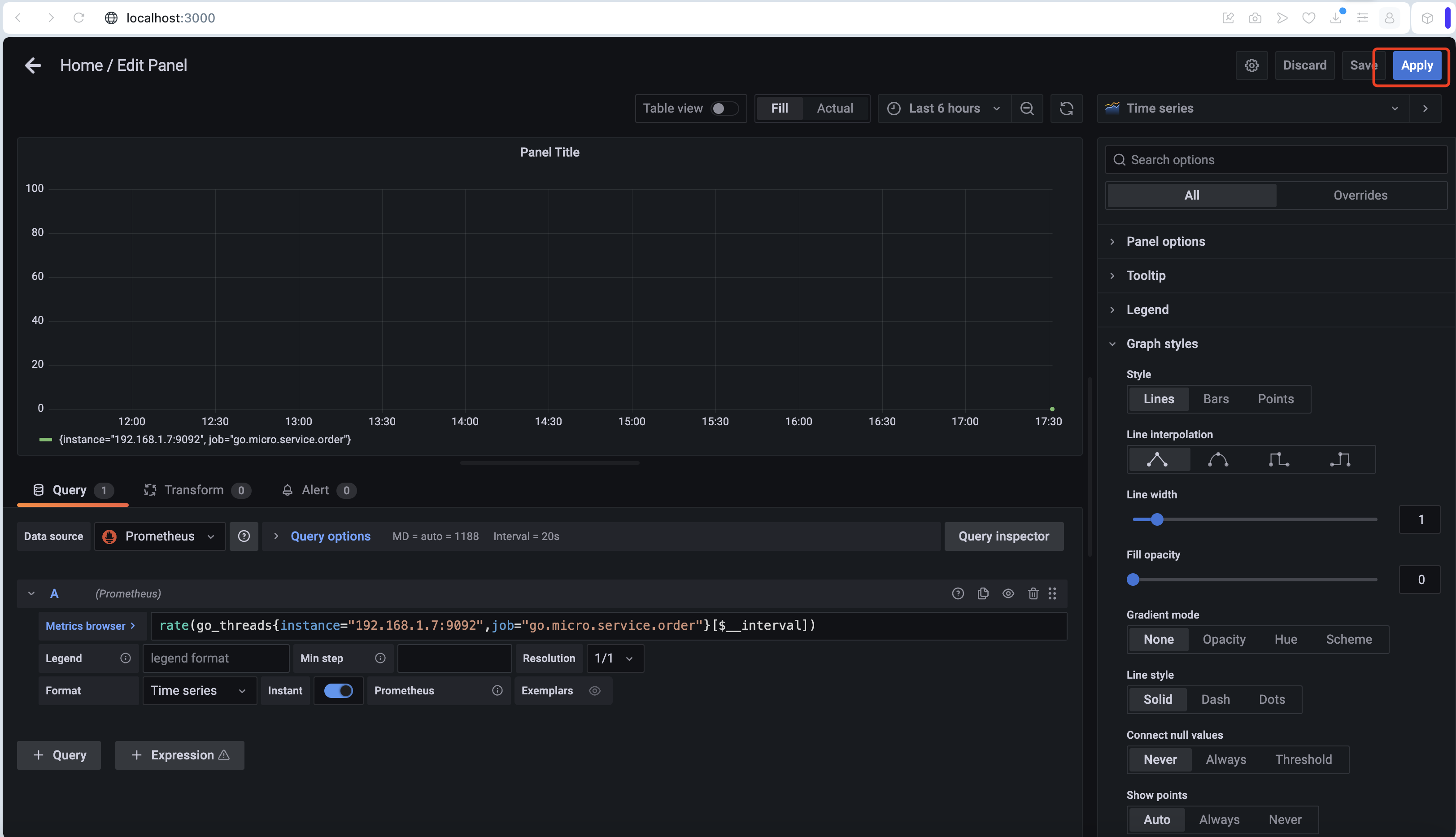
- 在生產環境上配置的需要注意,Prometheus 的地址
- 開發時,寫本機當前的地址
- 生產時,注意添加正確的地址




)
)




——兩種復數移相算法)
Spring教程——依賴注入與控制反轉)
)



 函數)
 ——路由請求與相關參數)

