在企業級應用場景中,Redis 作為高性能緩存利器,極大提升了系統響應速度,但隨著業務復雜度和并發量的攀升,緩存相關的各類挑戰也接踵而至。比如系統啟動時緩存缺失導致的數據庫壓力、大量緩存同時失效引發的連鎖故障、熱點數據過期引發的集中查詢風暴,以及惡意請求穿透緩存直擊數據庫等問題,都可能成為系統穩定運行的隱患。接下來,我們將深入剖析緩存預熱、緩存雪崩、緩存擊穿、緩存穿透這四大企業級緩存難題,并詳解對應的解決方案。
企業級解決方案
緩存預熱
緩存預熱是在系統上線或重啟后,提前將一些熱點數據加載到緩存中的操作,主要目的是避免用戶首次訪問相關數據時,因緩存中無對應數據,都去查詢數據庫等后端數據源 ,從而產生較高延遲或給后端帶來巨大壓力。
解決方案
準備工作:
- 日常例行統計數據訪問記錄,統計訪問頻度較高的熱點數據
- 將統計結果中的數據分類,根據級別,redis優先加載級別較高的熱點數據
實施:
- 使用腳本程序固定觸發數據預熱過程
- 如果條件允許,使用了CDN(內容分發網絡),效果會更好

總結
緩存預熱就是系統啟動前,提前將相關的緩存數據直接加載到緩存系統。避免在用戶請求的時候,先查 詢數據庫,然后再將數據緩存的問題!用戶直接查詢事先被預熱的緩存數據
緩存雪崩
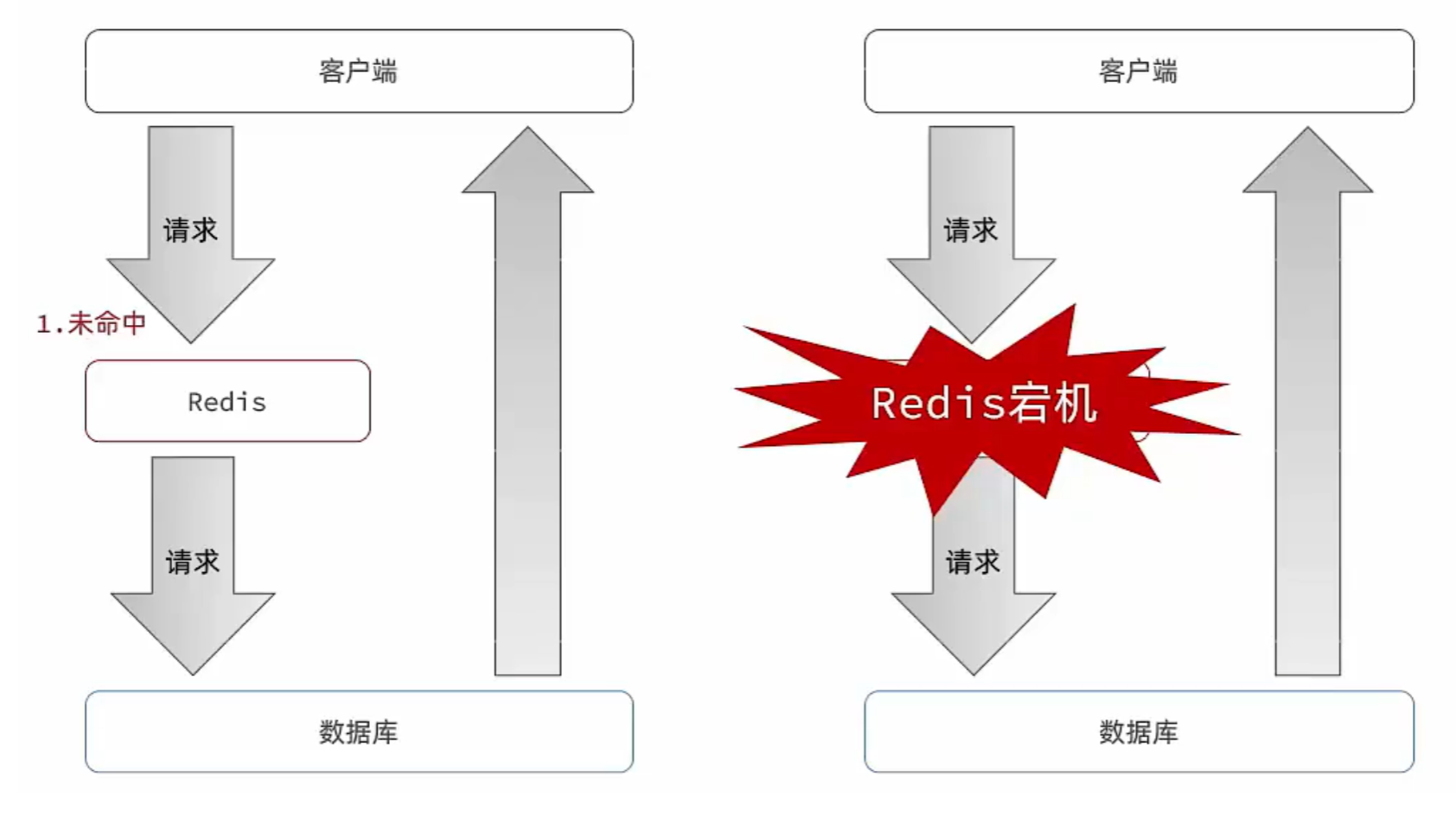
緩存雪崩是指在某一時間段內,緩存中大量熱點數據同時過期失效,或緩存服務因故障(如宕機、網絡中斷)突然不可用,導致所有原本應訪問緩存的請求全部轉向后端數據庫等數據源,引發數據庫壓力驟增、響應延遲甚至宕機,最終導致整個系統服務不可用的連鎖故障。
解決方案:
- 給不同的Key的TTL添加隨機值
- 利用Redis集群提高服務的可用性
- 給緩存業務添加降級限流策略
- 給業務添加多級緩存
緩存擊穿
緩存擊穿指的是在緩存中,某個熱點數據(訪問頻率極高的數據 )的緩存過期,大量并發請求同時到達,由于緩存已失效,導致所有原本應訪問緩存的請求全部轉向后端數據庫等數據源,進而可能導致數據庫負載過高甚至服務崩潰?。
常見的解決方案有兩種:
- 互斥鎖
- 邏輯過期
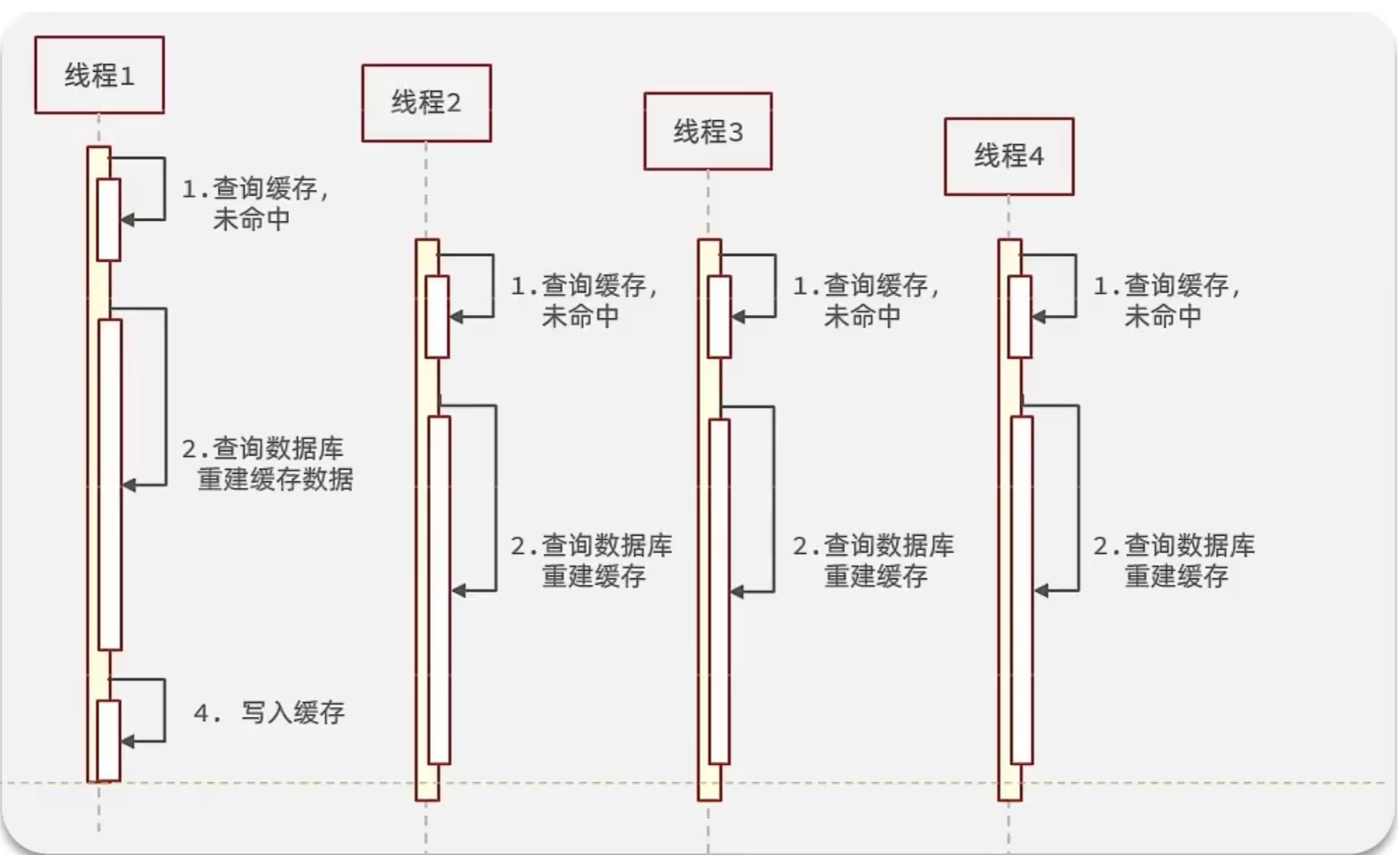
邏輯分析:假設線程1在查詢緩存之后,本來應該去查詢數據庫,然后把這個數據重新加載到緩存的, 此時只要線程1走完這個邏輯,其他線程就都能從緩存中加載這些數據了,但是假設在線程1沒有走完的 時候,后續的線程2,線程3,線程4同時過來訪問當前這個方法, 那么這些線程都不能從緩存中查詢到 數據,那么他們就會同一時刻來訪問查詢緩存,都沒查到,接著同一時間去訪問數據庫,同時的去執行 數據庫代碼,對數據庫訪問壓力過大
解決方案一,使用鎖來解決:
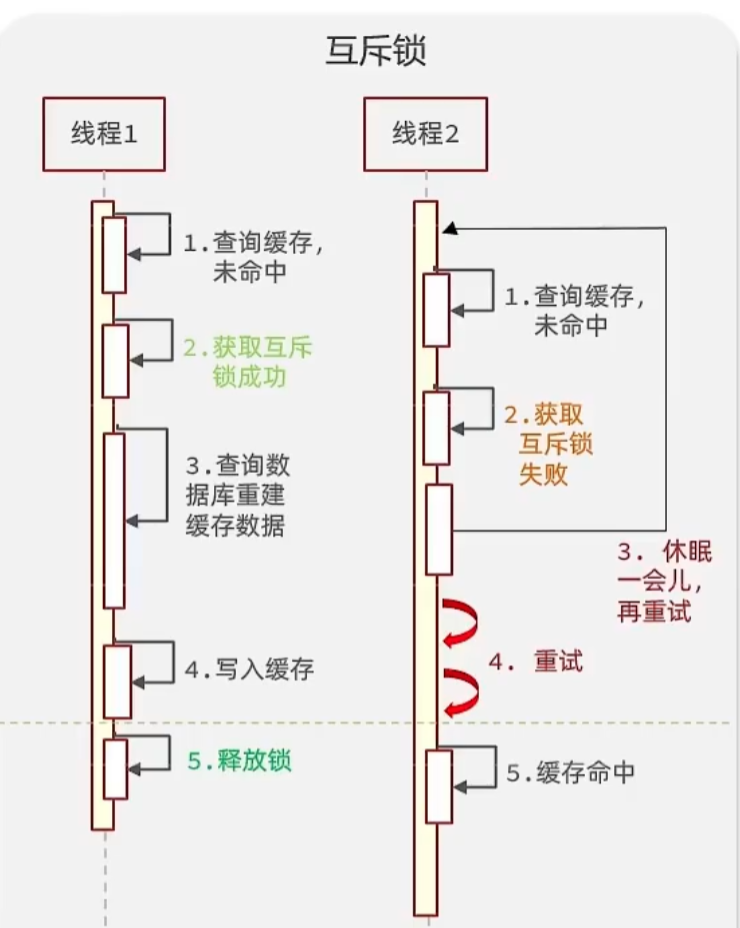
因為鎖能實現互斥性。假設線程過來,只能一個人一個人的來訪問數據庫,從而避免對于數據庫訪問壓 力過大,但這也會影響查詢的性能,因為此時會讓查詢的性能從并行變成了串行,我們可以采用 tryLock方法 + double check來解決這樣的問題。
假設現在線程1過來訪問,他查詢緩存沒有命中,但是此時他獲得到了鎖的資源,那么線程1就會一個人 去執行邏輯,假設現在線程2過來,線程2在執行過程中,并沒有獲得到鎖,那么線程2就可以進行到休 眠,直到線程1把鎖釋放后,線程2獲得到鎖,然后再來執行邏輯,此時就能夠從緩存中拿到數據了。?
解決方案二,邏輯過期方案?
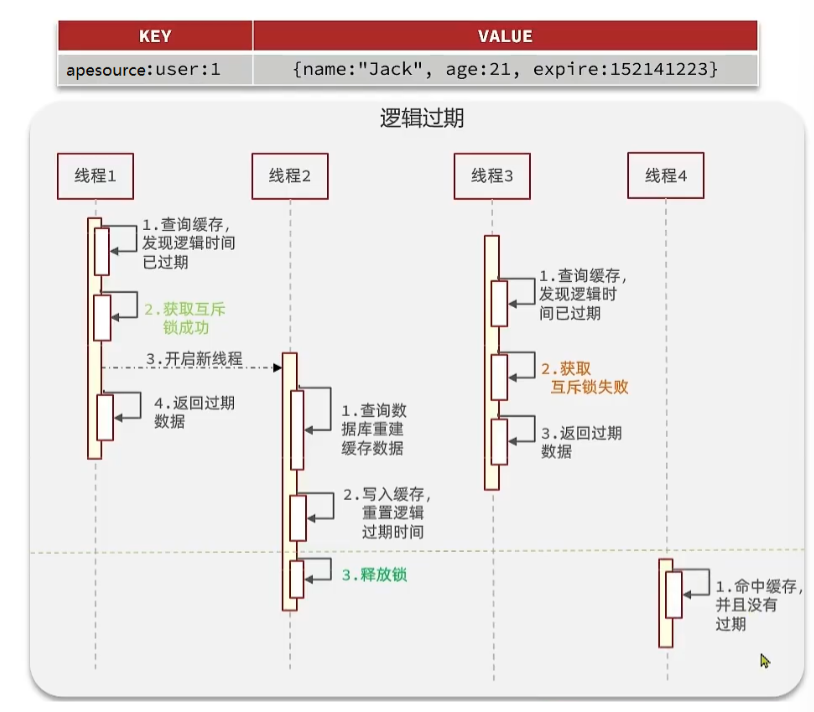
方案分析:我們之所以會出現這個緩存擊穿問題,主要原因是在于我們對key設置了過期時間,假設我 們不設置過期時間,其實就不會有緩存擊穿的問題,但是不設置過期時間,這樣數據不就一直占用我們 內存了嗎,我們可以采用邏輯過期方案。
我們把過期時間設置在 redis的value中,注意:這個過期時間并不會直接作用于redis,而是我們后續 通過邏輯去處理。假設線程1去查詢緩存,然后從value中判斷出來當前的數據已經過期了,此時線程1 去獲得互斥鎖,那么其他線程會進行阻塞,獲得了鎖的線程他會開啟一個 線程去進行 以前的重構數據 的邏輯,直到新開的線程完成這個邏輯后,才釋放鎖, 而線程1直接進行返回,假設現在線程3過來訪 問,由于線程線程2持有著鎖,所以線程3無法獲得鎖,線程3也直接返回數據,只有等到新開的線程2把 重建數據構建完后,其他線程才能走返回正確的數據。
這種方案巧妙在于,異步的構建緩存,缺點在于在構建完緩存之前,返回的都是臟數據。?
進行對比:
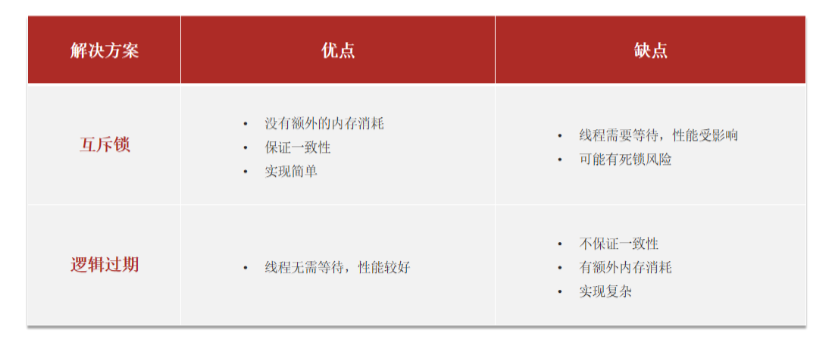
互斥鎖方案:由于保證了互斥性,所以數據一致,且實現簡單,因為僅僅只需要加一把鎖而已,也沒其他的事情需要操心,所以沒有額外的內存消耗,缺點在于有鎖就有死鎖問題的發生,且只能串行執行性能肯定受到影響
邏輯過期方案:線程讀取過程中不需要等待,性能好,有一個額外的線程持有鎖去進行重構數據,但是在重構數據完成前,其他的線程只能返回之前的數據,且實現起來麻煩
緩存穿透
緩存穿透是指客戶端請求的是不存在于緩存中,也不存在于后端數據庫(或其他數據源)中的數據,導致每次請求都會 “穿透” 緩存,直接訪問數據庫,若此類請求大量并發,會造成數據庫資源浪費、壓力驟增,甚至引發服務不可用的問題。
常見的解決方案有兩種:
緩存空對象
優點:實現簡單,維護方便
缺點:
- 額外的內存消耗
- 可能造成短期的不一致
布隆過濾
優點:內存占用較少,沒有多余key
缺點:
- 實現復雜
- 存在誤判可能
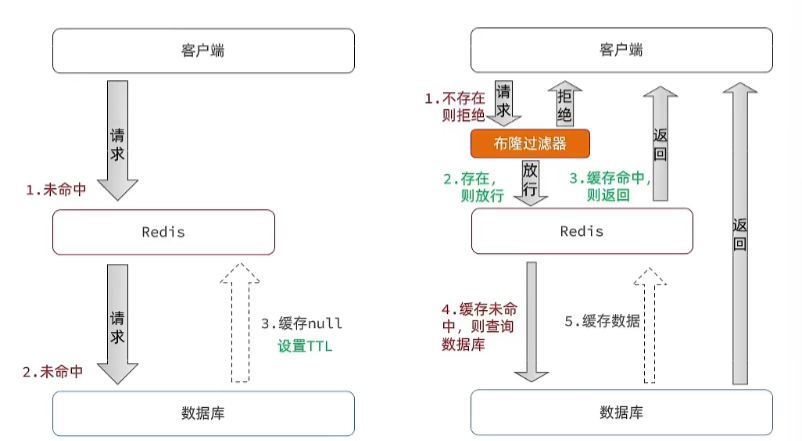
緩存空對象思路分析:當我們客戶端訪問不存在的數據時,先請求redis,但是此時redis中沒有數據, 此時會訪問到數據庫,但是數據庫中也沒有數據,這個數據穿透了緩存,直擊數據庫,我們都知道數據 庫能夠承載的并發不如redis這么高,如果大量的請求同時過來訪問這種不存在的數據,這些請求就都會 訪問到數據庫,簡單的解決方案就是哪怕這個數據在數據庫中也不存在,我們也把這個數據存入到redis 中去,這樣,下次用戶過來訪問這個不存在的數據,那么在redis中也能找到這個數據就不會進入到緩存 了
布隆過濾:布隆過濾器其實采用的是哈希思想來解決這個問題,通過一個龐大的二進制數組,走哈希思 想去判斷當前這個要查詢的這個數據是否存在,如果布隆過濾器判斷存在,則放行,這個請求會去訪問 redis,哪怕此時redis中的數據過期了,但是數據庫中一定存在這個數據,在數據庫中查詢出來這個數 據后,再將其放入到redis中, 假設布隆過濾器判斷這個數據不存在,則直接返回 這種方式優點在于節約內存空間,存在誤判,誤判原因在于:布隆過濾器走的是哈希思想,只要哈希思 想,就可能存在哈希沖突
緩存預熱、雪崩、擊穿、穿透,是企業級應用中 Redis 緩存面臨的典型挑戰。通過提前加載熱點數據的緩存預熱,能避免系統啟動初期的數據庫壓力;采用多樣化策略應對的緩存雪崩方案,保障了緩存大規模失效時系統的穩定;互斥鎖與邏輯過期兩種思路解決的緩存擊穿問題,平衡了數據一致性與訪問性能;緩存空對象和布隆過濾應對的緩存穿透方案,攔截了無效請求對數據庫的沖擊。掌握這些解決方案,能讓 Redis 在企業級場景中更穩定、高效地發揮緩存價值,為系統性能保駕護航。
有問題歡迎留言!!!😗
肥嘟嘟左衛門就講到這里啦,記得一鍵三連!!!😗

![P3918 [國家集訓隊] 特技飛行](http://pic.xiahunao.cn/P3918 [國家集訓隊] 特技飛行)



(通過GBK編碼繞過實現文件包含讀取flag))
Kubernetes 資源控制器關系圖)






)



![U8g2庫為XFP1116-07AY(128x64 OLED)實現菜單功能[ep:esp8266]](http://pic.xiahunao.cn/U8g2庫為XFP1116-07AY(128x64 OLED)實現菜單功能[ep:esp8266])

