【數據集介紹】
我們基于公開的大規模航空圖像數據集構建了AI-TOD,這些數據集包括:DOTA-v1.5的訓練驗證集[1]、xView的訓練集[19]、VisDrone2018-Det的訓練驗證集[20]、Airbus Ship的訓練驗證集1以及DIOR的訓練驗證+測試集[3]。這些數據集的詳細信息如下:
DOTA-v1.5 訓練驗證集:這是原始 DOTA-v1.0 數據集 [1] 的升級版本,并已用于航空圖像目標檢測(DOAI2019)的性能評估。DOTA-v1.5 訓練驗證集包含 1,869 張圖像,尺寸從 800 × 800 到 4000 × 4000 像素不等,以及 280,196 個目標實例,這些實例被標注為 16 個類別(例如,船只、小型車輛、儲罐)。
xView訓練集:這是一個大規模的目標檢測數據集,包含1,415平方公里的WorldView-3圖像,分辨率為30厘米。該標注數據集用于目標檢測,涵蓋了60個類別中的超過100萬個目標實例,包括各種類型的車輛、飛機和船只[19]。
VisDrone2018-Det 訓練驗證集。該數據集包含 7,019 張圖像,這些圖像由無人機平臺在不同地點、不同高度拍攝。圖像經過人工標注,包含邊界框和 10 個預定義類別(例如行人、人、汽車)。
Airbus-Ship訓練驗證集。這是一個用于Kaggle挑戰賽中的船舶檢測數據集。Airbus-Ship訓練驗證集包含42,559張圖像和81,724艘船舶,所有對象均以多邊形標注。
DIOR 訓練驗證+測試集。該數據集包含 23,463 張圖像和 192,472 個目標實例,涵蓋 20 個類別(例如,飛機、船舶、風車)。
為了構建AI-TOD數據集,我們從上述數據集中提取圖像和對象實例,具體步驟如下:
圖像尺寸。原始圖像被劃分為800×800像素的塊,重疊部分為200像素。如果原始圖像小于800×800像素,則通過填充零像素將其擴展到800×800像素。
對象類型。我們在AI-TOD數據集中選擇了八種類別,包括飛機(AI)、橋梁(BR)、儲罐(ST)、船舶(SH)、游泳池(SP)、車輛(VE)、人(PE)和風車(WM)。這些類別的選擇基于某類對象在低分辨率航空圖像中是否常見及其尺寸。airplane (AI), bridge (BR), storage-tank (ST), ship (SH), swimming-pool (SP), vehicle (VE)
類別轉換。在選定類別后,我們將相應數據集中的舊類別轉換為新類別。在此過程中,一些類別不在AI-TOD中的對象將被剔除。
圖片預覽:

標注例子:

數據集官方大小22GB大小且默認不是YOLO格式,這里將官方圖片無損壓縮成jpg格式并轉成YOLO格式,壓縮包體積變成1.08GB大小,大大節約下載時間且不影響訓練效果。
【訓練步驟】
這里以yolo11訓練為例。首先我們獲取數據集壓縮包7z格式或者zip格式后解壓到一個非中文或者有空格路徑下面。比如解壓到C:\Users\Administrator\Downloads目錄,下面都是以這個目錄演示訓練流程。
打開coco128.yaml看到下面類似格式:
train: train/images
val: val/images
# Number of classes
nc: 8
# Class names
names:0: airplane1: bridge2: storage-tank3: ship4: swimming-pool5: vehicle6: person7: wind-mill?這些都不用修改,我們只需要檢查一下是不是對的就行。
之后就是開始訓練了,注意訓練yolov11模型需要自己提前安裝好環境。
使用預訓練模型開始訓練
yolo task=detect mode=train model=yolo11n.pt data=coco128.yaml epochs=100 imgsz=640 batch=8 workers=2
參數說明:
model: 使用的模型類型,如 yolo11s.pt(小模型)、yolo11m.pt(中)、yolo11l.pt(大)
data: 指定數據配置文件
epochs: 訓練輪數
imgsz: 輸入圖像尺寸
batch: 批量大小(根據顯存調整)
workers:指定進程數(windows最好設置0或者1或2,linux可以設置8)
訓練完成后,最佳權重保存路徑為:runs/detect/train/weights/best.pt,如果多次運行命令runs/detect/train2,runs/detect/train3文件夾生成只需要到數字最大文件夾查看就可以找到模型
圖片預測:
from ultralytics import YOLO# 加載訓練好的模型
model = YOLO('runs/detect/train/weights/best.pt')# 圖像預測
results = model('path_to_your_image.jpg')
視頻或攝像頭預測
results = model('path_to_video.mp4') # 視頻
#results = model(0) # 攝像頭
?驗證集評估
yolo task=detect mode=val model=runs/detect/train/weights/best.pt data=data.yaml
輸出指標圖像,一般在模型訓練后生成,文件位置在runs/detect/train/results.png:
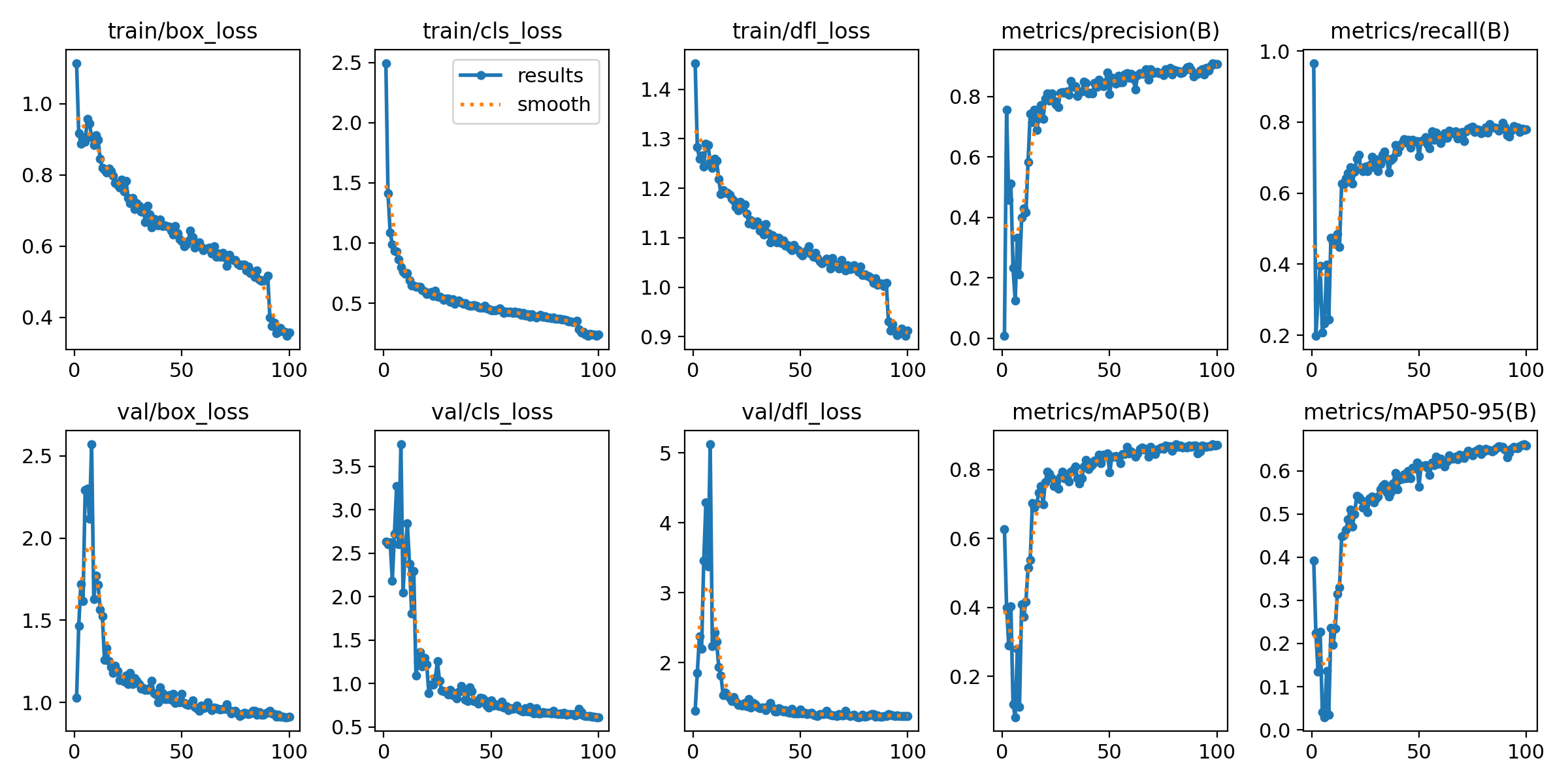
上面訓練結果圖片常用評估參數介紹
【常用評估參數介紹】
在目標檢測任務中,評估模型的性能是至關重要的。你提到的幾個術語是評估模型性能的常用指標。下面是對這些術語的詳細解釋:
- Class:
- 這通常指的是模型被設計用來檢測的目標類別。例如,一個模型可能被訓練來檢測車輛、行人或動物等不同類別的對象。
- Images:
- 表示驗證集中的圖片數量。驗證集是用來評估模型性能的數據集,與訓練集分開,以確保評估結果的公正性。
- Instances:
- 在所有圖片中目標對象的總數。這包括了所有類別對象的總和,例如,如果驗證集包含100張圖片,每張圖片平均有5個目標對象,則Instances為500。
- P(精確度Precision):
- 精確度是模型預測為正樣本的實例中,真正為正樣本的比例。計算公式為:Precision = TP / (TP + FP),其中TP表示真正例(True Positives),FP表示假正例(False Positives)。
- R(召回率Recall):
- 召回率是所有真正的正樣本中被模型正確預測為正樣本的比例。計算公式為:Recall = TP / (TP + FN),其中FN表示假負例(False Negatives)。
- mAP50:
- 表示在IoU(交并比)閾值為0.5時的平均精度(mean Average Precision)。IoU是衡量預測框和真實框重疊程度的指標。mAP是一個綜合指標,考慮了精確度和召回率,用于評估模型在不同召回率水平上的性能。在IoU=0.5時,如果預測框與真實框的重疊程度達到或超過50%,則認為該預測是正確的。
- mAP50-95:
- 表示在IoU從0.5到0.95(間隔0.05)的范圍內,模型的平均精度。這是一個更嚴格的評估標準,要求預測框與真實框的重疊程度更高。在目標檢測任務中,更高的IoU閾值意味著模型需要更準確地定位目標對象。mAP50-95的計算考慮了從寬松到嚴格的多個IoU閾值,因此能夠更全面地評估模型的性能。
這些指標共同構成了評估目標檢測模型性能的重要框架。通過比較不同模型在這些指標上的表現,可以判斷哪個模型在實際應用中可能更有效。
將模型導出為ONNX、TensorRT等格式以用于部署:
yolo export model=runs/detect/train/weights/best.pt format=onnx
支持格式包括:onnx, engine, tflite, pb, torchscript 等。
經過上面訓練可以使用模型做進一步部署,比如使用onnx模型在嵌入式部署,使用engine模型在jetson上deepstream部署,使用torchscript模型可以在C++上部署等等。


)



![U8g2庫為XFP1116-07AY(128x64 OLED)實現菜單功能[ep:esp8266]](http://pic.xiahunao.cn/U8g2庫為XFP1116-07AY(128x64 OLED)實現菜單功能[ep:esp8266])












