-
目錄
前言
一、簡介一下C++11
二、{}列表初始化
三、右值引用和移動語義
四、右值引用和移動語義的使用場景
五、右值引用和移動語義在傳參中的提效
六、引用折疊和完美轉發
七、可變參數模板

前言
? ? ? ? 本文主要介紹C++11中新增的一些重要語法:包括initializer_list列表初始化、右值引用和移動語義、引用折疊、萬能引用、完美轉發、可變參數模版、emplace系列接口等。
一、簡介一下C++11
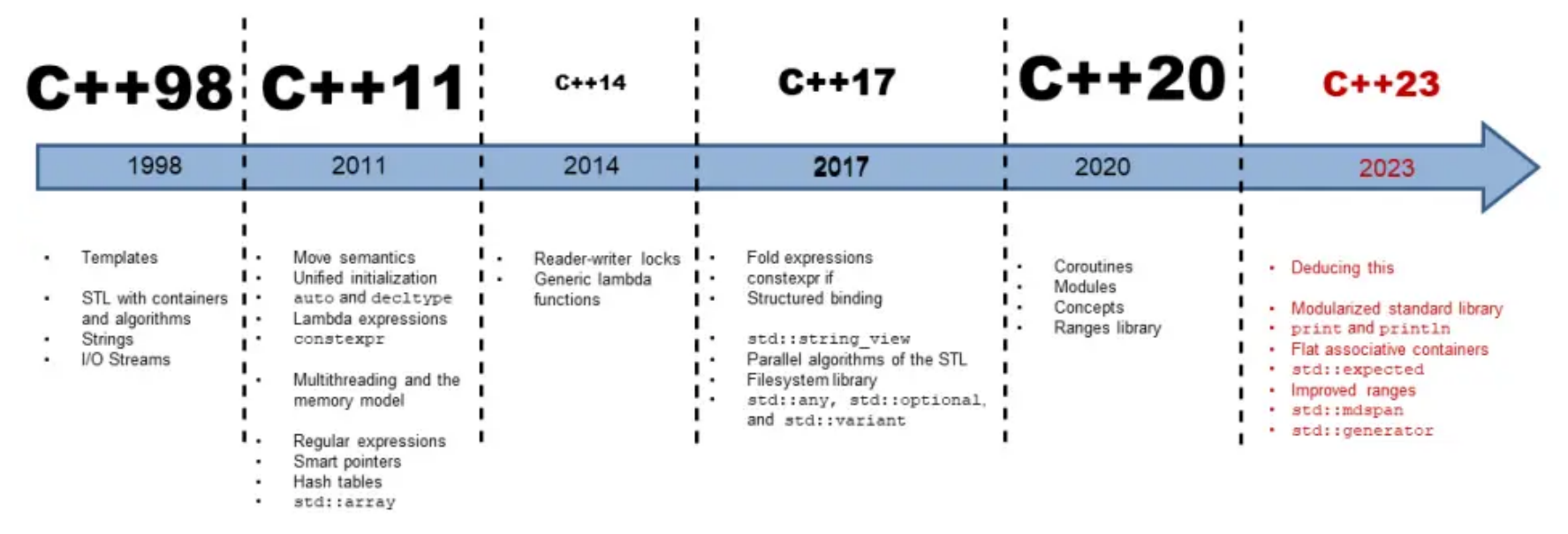
- C++11(曾用名 C++0x)是 C++ 編程語言的一次里程碑式更新,于 2011 年 8 月正式發布。它不僅修復了 C++98/03 標準中的諸多缺陷,更引入了大量現代編程語言特性,極大地提升了代碼的可讀性、安全性和開發效率,徹底改變了 C++ 的編程范式,為后續的 C++14、C++17 等標準奠定了基礎。
- C++03與C++11期間花了8年時間,故而這是迄今為為最?的版本間隔。從那時起,C++就有規律地每3年更新一次。
- (補:上圖中c++版本字體越大說明更新幅度越大)
二、{}列表初始化
1.c++98傳統的{}
C++98中一般數組和結構體可以用 {} 進行初始化。
#include <iostream>
using namespace std;struct Point
{int _x;int _y;
};int main()
{//c++98支持的{}初始化int array1[] = { 1, 2, 3, 4, 5 };int array2[5] = { 0 };Point p = { 1, 2 };return 0;
}2.c++11的{}
- C++11以后想統一初始化方式,試圖實現?切對象皆可用 {} 初始化,{}初始化也叫做列表初始化。
- 內置類型支持,自定義類型也支持,自定義類型本質是隱式類型轉換,中間會產生臨時對象,最后優化了以后變成直接構造。
#include <iostream>
using namespace std;class Date
{
public:Date(int year = 1, int month = 1, int day = 1):_year(year), _month(month), _day(day){cout << "Date(int year, int month, int day)" << endl;}Date(const Date& d):_year(d._year), _month(d._month), _day(d._day){cout << "Date(const Date& d)" << endl;}
private:int _year;int _month;int _day;
};int main()
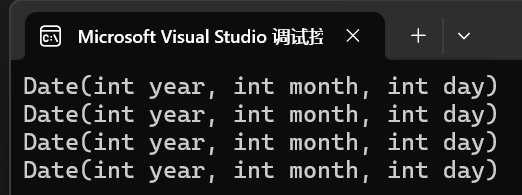
{//c++11{}支持內置類型//不過也沒人這么用int x = { 1 };//自定義類型//這里本質是用 {2025,9,1} 構造一個臨時對象//再用臨時對象拷貝構造 d1//編譯器合二為一優化成直接構造,也就是沒有臨時對象和拷貝構造了Date d1 = { 2025, 9, 1 };//那么這里就是引用臨時對象了const Date& d2 = { 2024, 9, 1 };//需要注意的是c++98支持單參數構造,也可以不用{}//前提是得有默認構造Date d3 = { 2025 };Date d4 = 2024;return 0;
}運行結果:
- {}初始化的過程中,可以省略掉=
- C++11列表初始化的本意是想實現一個大統一的初始化方式,其次他在有些場景下帶來的不少便利,如容器push/inset多參數構造的對象時,{}初始化會很方便。
#include <iostream>
#include <vector>
using namespace std;class Date
{
public:Date(int year = 1, int month = 1, int day = 1):_year(year), _month(month), _day(day){cout << "Date(int year, int month, int day)" << endl;}Date(const Date& d):_year(d._year), _month(d._month), _day(d._day){cout << "Date(const Date& d)" << endl;}
private:int _year;int _month;int _day;
};int main()
{//可以省略=int x1{ 1 };Date d1{ 2025,9,1 };const Date& d2{ 2024,9,1 };//比起有名對象和匿名對象傳參,這里直接使用{}更方便vector<Date> v1;v1.push_back({ 2025,10,1 });return 0;
}3.c++11中的std::initializer_list
- 上面的初始化已經很方便,但是對象容器初始化還是不太方便,比如?個vector對象,我想用N個值去構造初始化,那么我們得實現很多個構造函數才能支持。
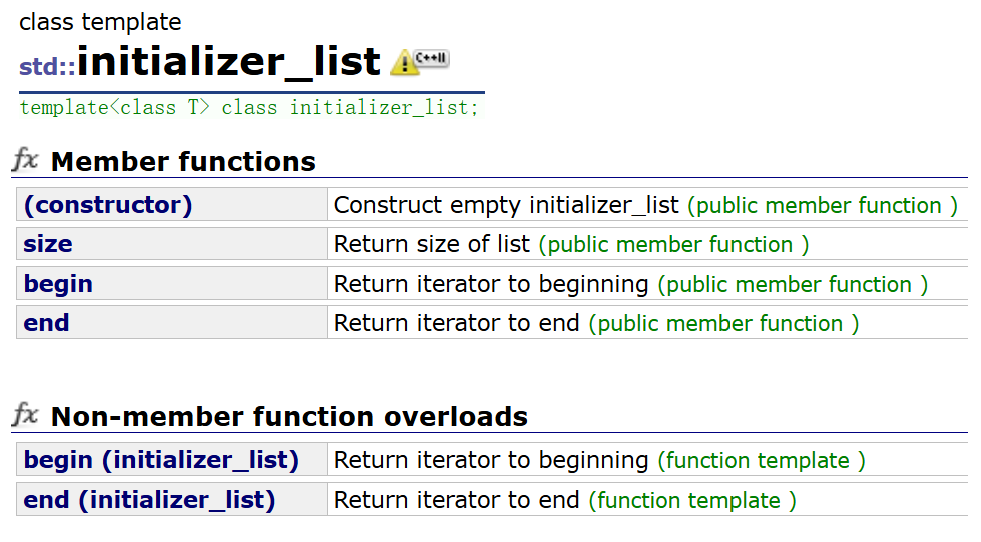
- C++11庫中提出了一個std::initializer_list的類,這個類的本質是底層開一個數組,將數據拷貝過來,std::initializer_list內部有兩個指針分別指向數組的開始和結束。std::initializer_list?持迭代器遍歷。
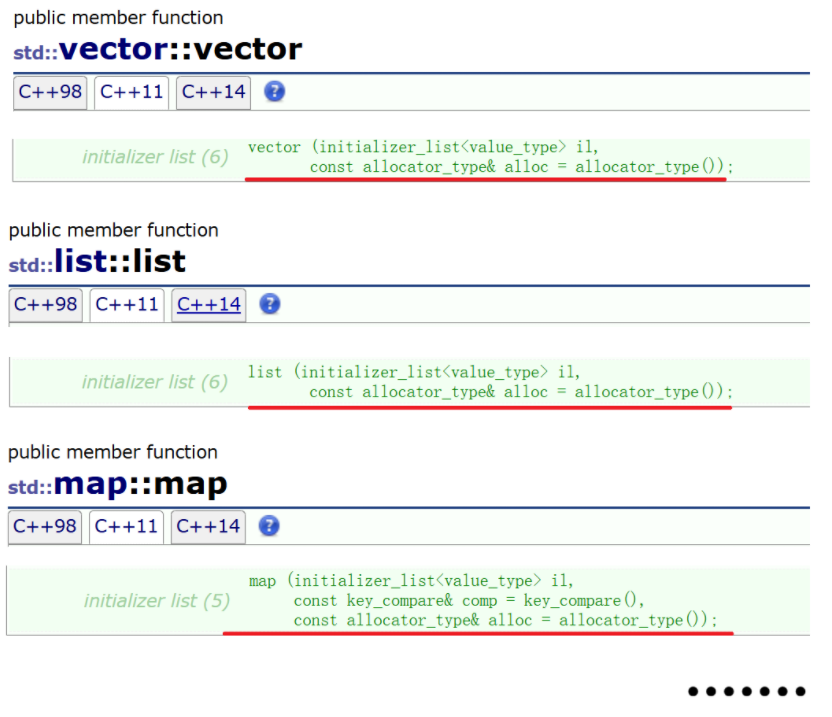
- 容器支持?個std::initializer_list的構造函數,也就支持任意多個值構成的 {x1,x2,x3 ...}進行初始化。。STL中的容器支持任意多個值構成的進行初始化,就是通過 std::initializer_list的構造函數支持的。可以通過文檔查到很多容器都支持std::initializer_list進行列表初始化構造或者賦值。
#include <iostream>
#include <vector>
#include <list>
#include <map>
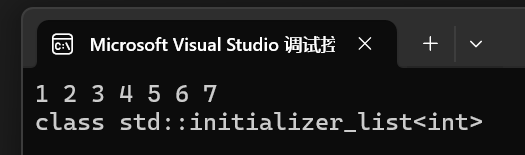
using namespace std;int main()
{auto it = { 1,2,3,4,5,6,7 };for (auto& e : it){cout << e << " ";}cout << endl << typeid(it).name() << endl << endl;//直接使用initializer_list進行初始化列表賦值構造vector<int> v1(it);list<int> l1({ 1,2,3,4,5,6 });map<int, int> m1({ {1,1},{2,2},{3,3 } });return 0;
}運行結果:
三、右值引用和移動語義
C++98的C++語法中就有引用的語法,而C++11中新增了的右值引用語法特性,C++11之后我們之前學習的引用就叫做左值引用。無論左值引用還是右值引用,都是給對象取別名。
1.左值和右值
- 左值是一個表示數據的表達式(如變量名或解引用的指針),一般是有持久狀態,存儲在內存中,我們可以獲取它的地址,左值可以出現賦值符號的左邊,也可以出現在賦值符號右邊。定義時const 修飾符后的左值,不能給他賦值,但是可以取它的地址。
- 右值也是一個表示數據的表達式,要么是字面值常量、要么是表達式求值過程中創建的臨時對象等,右值可以出現在賦值符號的右邊,但是不能出現出現在賦值符號的左邊,右值不能取地址。
- 值得?提的是,左值的英文簡寫為lvalue,右值的英文簡寫為rvalue。傳統認為它們分別是left value、right value 的縮寫。現代C++中,lvalue被解釋為loactorvalue的縮寫,可意為存儲在內存中、有明確存儲地址可以取地址的對象,而rvalue被解釋為readvalue,指的是那些可以提供數據值,但是不可以尋址,例如:臨時變量,字面量常量,存儲于寄存器中的變量等,也就是說左值和右值的核心區別就是能否取地址。
#include <iostream>
#include <string>
using namespace std;int main()
{//左值:可以取地址//以下的p、b、c、*p、s、s[0]都是常見的左值int* p = new int(1);int b = 1;const int c = b;*p = 10;string s("xxxxxxx");s[0] = '1';//左值都可以取地址cout << p << endl;cout << &b << endl;cout << &c << endl;cout << &(*p) << endl;cout << &s << endl;cout << (void*)&s[0] << endl;//右值:不可以取地址double x = 1.1, y = 2.2;//以下的10、x+y、fmin(x,y)、string("111111")都是一些常見的右值10;x + y;fmin(x, y);string("111111");//無法取地址,會報錯/*cout << &10 << endl;cout << &(x+y) << endl;cout << &(fmin(x, y)) << endl;cout << &string("11111") << endl;*/return 0;
}我對右值的理解是那些臨時對象,比如x+y的結果是存儲在一個臨時對象中,fmin的返回值也是一個臨時對象。string("111111")則本身是一個匿名對象,10則是一個字面量本身。很明顯它們的生命周期只有它們存在的那一行,是一些即將消亡的值。
詳細的左值右值分類可訪問該網站:Value categories - cppreference.com
- 該網站中對右值進行了分類,右值被劃分純右值(purevalue,簡稱prvalue)和將亡值 (expiring value,簡稱xvalue)。
- 純右值是指那些字面值常量或求值結果相當于字面值或是一個不具名的臨時對象。將亡值是指返回右值引用的函數的調用表達式和轉換為右值引用的轉換函數的調用表達式(如move)。
- 還有泛左值(generalizedvalue,簡稱glvalue),泛左值包含將亡值和左值。
- 該分類僅做了解即可,感興趣可以訪問網址閱讀。
2.左值引用和右值引用
- Type& r1 = x;? Type&& rr1 = y;??第一個語句就是左值引用,左值引用就是給左值取別 名,第二個就是右值引用,同樣的道理,右值引用就是給右值取別名。
#include <iostream>
#include <string>
using namespace std;int main()
{//左值:可以取地址//以下的p、b、c、*p、s、s[0]都是常見的左值int* p = new int(1);int b = 1;const int c = b;*p = 10;string s("xxxxxxx");s[0] = '1';//左值引用給左值取別名int*& r1 = p;int& r2 = b;const int& r3 = c;int& r4 = *p;string& r5 = s;char& r6 = s[0];//右值引用給右值取別名double x = 1.1, y = 2.2;int&& rr1 = 10;double&& rr2 = x + y;double&& rr3 = fmin(x, y);string&& rr4 = string("111111");return 0;
}
- 左值引用不能直接引用右值,但是const左值引用可以引用右值。
#include <iostream>
#include <string>
using namespace std;int main()
{//const左值引用給右值取別名double x = 1.1, y = 2.2;const int& r1 = 10;const double& r2 = x + y;const double& r3 = fmin(x, y);const string& r4 = string("111111");return 0;
}
- 右值引用不能直接引用左值,但是右值引用可以引用move(左值)。
- move是庫里面的一個函數模板,本質內部是進行強制類型轉換,當然他還涉及一些引用折疊的知識,這個我們下面會細講。

#include <iostream>
#include <string>
#include <utility>
using namespace std;int main()
{//左值:可以取地址int* p = new int(1);int b = 1;const int c = b;*p = 10;string s("xxxxxxx");//可以用move將左值屬性轉為右值,再用右值引用取別名int*&& rr1 = move(p);int&& rr2 = move(b);const int&& rr3 = move(c);int&& rr4 = move(*p);string&& rr5 = move(s);string&& rr6 = (string&&)s;//這樣也能側面證明move本質是一個強制類型轉換return 0;
}補:move屬于<utility>頭文件,如果編譯器識別不到move可以包一下這個頭文件
- 需要注意的是變量表達式都是左值屬性,也就意味著?個右值被右值引用綁定后,右值引用變量變量表達式的屬性是左值。(右值引用本身屬性是左值)
- 語法層?看,左值引用和右值引用都是取別名,不開空間。從匯編底層的角度看下面代碼中r1和rr1匯編層實現,底層都是用指針實現的,沒什么區別。底層匯編等實現和上層語法表達的意義有時是背離的,所以不要揉到一起去理解,互相佐證,這樣反而是陷入迷途。
#include <iostream>
#include <string>
#include <utility>
using namespace std;int main()
{//右值引用本身(rr1)是左值屬性string&& rr1 = string("xxxxxxxx");cout << &rr1 << endl;//所以如果還要對rr1取別名,可以用move強轉一下,或者const左值引用const string& r1 = rr1;string&& rr2 = move(rr1);return 0;
}
- 右值引用本身是左值,這樣就可以使用右值引用進行管理操控資源,之前說臨時對象具有常性是因為沒有主體對其進行操控,現在有了右值引用,那么這些臨時對象就能夠進行修改了。
3.引用延遲生命周期
- 右值引用可用于為臨時對象延長生命周期,const的左值引用也能延長臨時對象生存期,但這些對象無法被修改(右值引用支持修改)。
#include <iostream>
#include <string>
using namespace std;int main()
{//可以延長臨時對象或者匿名對象的生命周期const string& r1 = string("xxxxx");string&& rr1 = string("1111111");//r1 += "1111";//這里const左值引用不能修改rr1 += "xxxx";//右值引用是支持修改的cout << rr1 << endl;return 0;
}運行結果:
4.左值和右值的參數匹配
- C++98中,我們實現一個const左值引用作為參數的函數,那么實參傳遞左值和右值都可以匹配。
- C++11以后,分別重載左值引用、const左值引用、右值引用作為形參的 f函數,那么實參是左值會匹配 f(左值引用),實參是const左值會匹配 f(const左值引用),實參是右值會匹配 f(右值引用)。
- 右值引用變量在用于表達式時屬性是左值,這個設計這里會感覺跟怪,下一節我們講右值引用的使用場景和引用折疊后,就能體會這樣設計的價值了。
#include <iostream>
#include <string>
#include <utility>
using namespace std;void f(int& x)
{cout << "左值引用重載 f(int& x)" << endl;
}void f(const int& x)
{cout << "const左值引用重載 f(const int& x)" << endl;
}void f(int&& x)
{cout << "右值引用重載 f(int&& x)" << endl;
}int main()
{int i = 1;const int ci = 2;f(i); //調用f(int x)f(ci); //調用f(const int& x)f(3); //調用f(int&& x)f(move(i)); //調用f(int&& x)cout << endl;//右值引用本身屬性是左值int&& rr1 = 4;f(rr1); //調用f(int& x);f(move(rr1)); //調用f(int&& x);return 0;
}四、右值引用和移動語義的使用場景
先劇透:右值引用和移動語義的最主要功能就是提效,下面我們注重理清楚它是怎么提效的
1.回顧左值引用使用場景,以及存在的問題
- 左值引用主要使用場景是在函數中左值引用傳參和左值引用傳返回值時減少拷貝,同時還可以修改實參和修改返回對象的價值。
- 左值引用已經解決大多數場景的拷貝效率問題,但是有些場景不能使用傳左值引用返回,如下面的 addStrings 和 generate 函數,原因是函數結束后其函數棧幀會被銷毀,其中產生的局部對象都會調用析構一起被釋放。
- C++98中的解決方案只能是被迫使用輸出型參數解決,但是很明顯,傳值返回會調用拷貝構造,當函數返回的數據量非常大時,這種傳值返回的效率是非常低下的。
//計算數字字符串num1和numl的和
class Solution1
{
public://傳值返回需要拷貝string addStrings(string num1, string num2) {string str;int end1 = num1.size() - 1, end2 = num2.size() - 1;//進位int next = 0;while (end1 >= 0 || end2 >= 0){int val1 = end1 >= 0 ? num1[end1--] - '0' : 0;int val2 = end2 >= 0 ? num2[end2--] - '0' : 0;int ret = val1 + val2 + next;next = ret / 10;ret = ret % 10;str += ('0' + ret);}if (next == 1)str += '1';reverse(str.begin(), str.end());return str;}
};//打印楊輝三角
class Solution2 {
public:// 這里的傳值返回拷貝代價就太大了vector<vector<int>> generate(int numRows){vector<vector<int>> vv(numRows);for (int i = 0; i < numRows; ++i){vv[i].resize(i + 1, 1);}for (int i = 2; i < numRows; ++i){for (int j = 1; j < i; ++j){vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];}}return vv;}
};
- 那么C++11以后這里可以使用右值引用做返回值解決嗎?顯然是不可能的,因為這里的本質是返回對象是一個局部對象,函數結束這個對象就析構銷毀了,右值引用返回也無法改變對象已經析構銷毀的事實。(引用不能延長函數內部局部對象的生命周期,因為該局部對象是存儲在函數的棧幀里,函數消亡局部對象也消亡)
- C++11解決方法就是實現移動語義:使用移動構造和移動賦值。
2.移動構造和移動賦值
什么是移動語義:C++11 移動語義的核心是:將一個對象的資源所有權(如內存、文件句柄)?直接 “轉移” 給另一個對象,而非拷貝資源,從而避免不必要的內存拷貝,提升性能。實現移動語義依賴兩個關鍵機制:右值引用、移動構造和移動賦值。
移動構造和移動賦值:
- 移動構造函數是一種構造函數,類似拷貝構造函數,移動構造函數要求第一個參數是該類類型的引用,但是不同的是要求這個參數是右值引用,如果還有其他參數,額外的參數必須有缺省值。
- 移動賦值是一個賦值運算符的重載,他跟拷貝賦值構成函數重載,類似拷貝賦值函數,移動賦值函數要求第一個參數是該類類型的引用,但是不同的是要求這個參數是右值引用。
- 對于像string/vector這樣的深拷貝的類或者包含深拷貝的成員變量的類,移動構造和移動賦值才有意義,因為移動構造和移動賦值的第?個參數都是右值引用的類型,他的本質是要“竊取”引用的右值對象的資源,而不是像拷貝構造和拷貝賦值那樣去拷貝資源,從提高效率。下面的txp::string 樣例實現了移動構造和移動賦值,我們需要結合場景理解。
- 補充:c++11后,基本所有的STL容器都增加了移動構造和移動賦值
首先為了便于觀察和實現,我們需要自己實現一個string類,這個類我們前面文章實現過就不多敘述了;然后為了避免重復展現實現的string類,這里先將完整的包含移動構造和移動賦值的string類代碼展示出來:
mystring.h:
#pragma once
#include <iostream>
#include <cassert>
using namespace std;namespace txp
{class string{public://迭代器typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}//默認構造string(const char* str = ""):_size(strlen(str)), _capacity(_size){cout << "string(char* str)構造" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}//底層指針交換void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}//拷貝構造string(const string& s):_str(nullptr){cout << "string(const string& s) -- 拷貝構造" << endl;reserve(s._capacity);for (auto ch : s){push_back(ch);}}//移動構造string(string&& s){cout << "string(string&& s) -- 移動構造" << endl;swap(s);}//拷貝賦值string& operator=(const string& s){cout << "string& operator=(const string& s) -- 拷貝賦值" << endl;if (this != &s){_str[0] = '\0';_size = 0;reserve(s._capacity);for (auto ch : s){push_back(ch);}}return *this;}//移動賦值string& operator=(string&& s){cout << "string& operator=(string&& s) -- 移動賦值" << endl;swap(s);return *this;}//析構~string(){cout << "~string() -- 析構" << endl;delete[] _str;_str = nullptr;}//[]重載char& operator[](size_t pos){assert(pos < _size);return _str[pos];}//擴容void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];if (_str){strcpy(tmp, _str);delete[] _str;}_str = tmp;_capacity = n;}}//尾插void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}//+=重載string& operator+=(char ch){push_back(ch);return *this;}//返回C語言版底層字符串const char* c_str() const{return _str;}//返回字符串大小size_t size() const{return _size;}private:char* _str = nullptr;size_t _size = 0;size_t _capacity = 0;};//驗證代碼string addStrings(string num1, string num2){string str;int end1 = num1.size() - 1, end2 = num2.size() - 1;int next = 0;while (end1 >= 0 || end2 >= 0){int val1 = end1 >= 0 ? num1[end1--] - '0' : 0;int val2 = end2 >= 0 ? num2[end2--] - '0' : 0;int ret = val1 + val2 + next;next = ret / 10;ret = ret % 10;str += ('0' + ret);}if (next == 1)str += '1';reverse(str.begin(), str.end());cout << "******************************" << endl;return str;}
}移動構造和移動賦值的實現:
//底層指針交換void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}//移動構造string(string&& s){cout << "string(string&& s) -- 移動構造" << endl;swap(s);}//移動賦值
string& operator=(string&& s)
{cout << "string& operator=(string&& s) -- 移動賦值" << endl;swap(s);return *this;
}
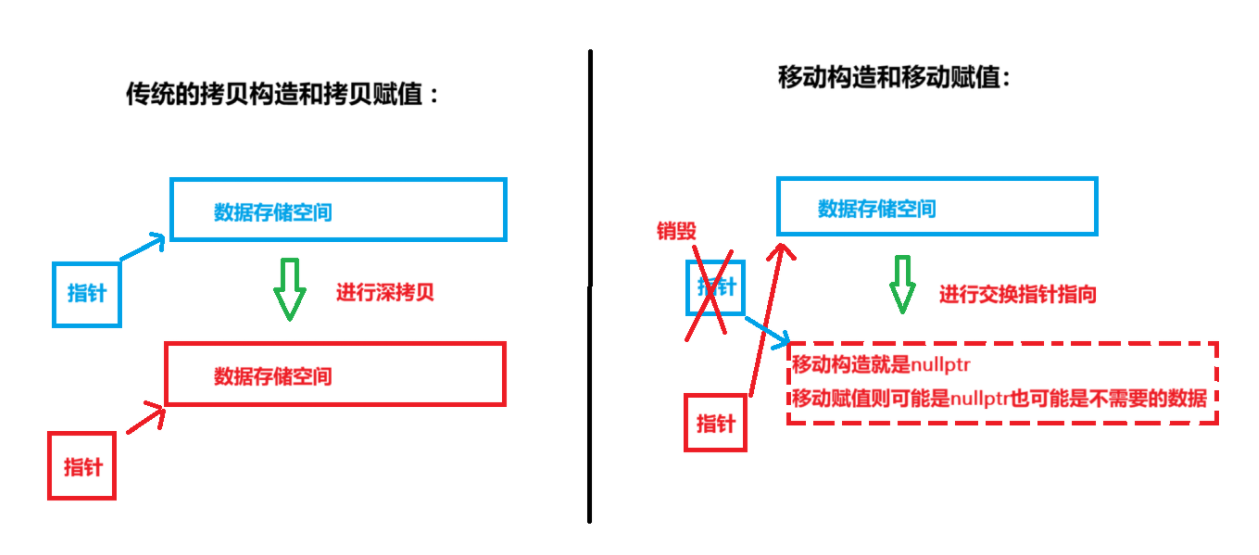
- 很明顯,移動構造和移動賦值的實現并不復雜,除了參數變為右值引用,函數體的實現就是交換底層指針。這就很符合前面提到拷貝構造和移動賦值是“竊取”引用右值對象的資源,而非進行深拷貝。
- 注意,移動構造和移動賦值后,通常形參中的右值引用的對象會被銷毀或者置空,這是因為右值引用的一般都是臨時對象之類(也有move等方式)的,而我們只需要臨時對象中的數據,但又不想進行深拷貝,因此使用交換指針的方式進行"掠奪"資源,一般自己原指向的空間是空nullptr或者是不需要的數據,交換之后,形參部分就會帶著不需要的數據或空數據自動銷毀了,這樣既完成了拷貝,效率又高,也不會導致內存泄漏。
- 千萬注意,移動構造和移動賦值只針對右值,也就是一些即將消亡的臨時對象等值,對于左值還是老老實實進行拷貝構造或者拷貝賦值。
(vs2022)我們先觀察一下參數匹配,以及強轉s1進行移動構造后的情況:
#define _CRT_SECURE_NO_WARNINGS 1
#include <utility>
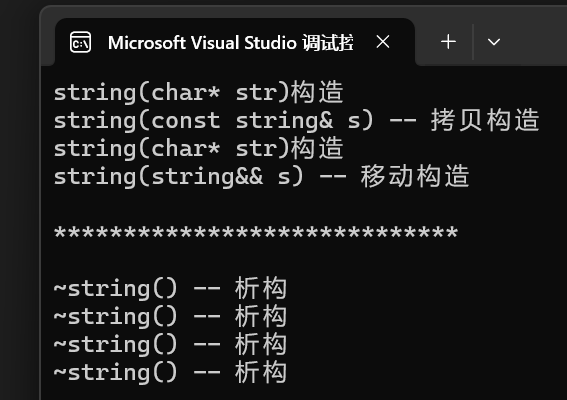
#include "mystring.h"int main()
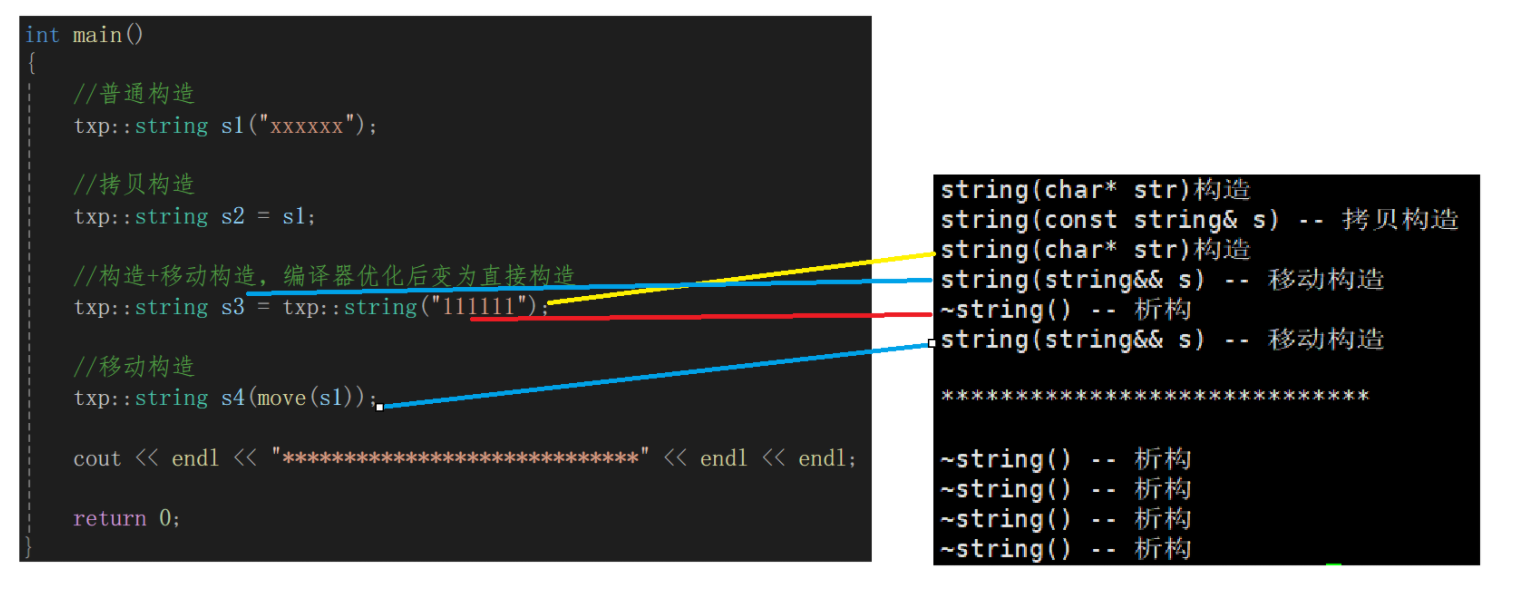
{//普通構造txp::string s1("xxxxxx");//拷貝構造txp::string s2 = s1;//構造+移動構造,編譯器優化后變為直接構造txp::string s3 = txp::string("111111");//移動構造txp::string s4(move(s1));cout << endl << "*****************************" << endl << endl;return 0;
}
運行結果:
- 首先這個運行結果是受編譯器優化后的結果,稍后我會在Linux下展示編譯器完全不進行優化的運行結果。
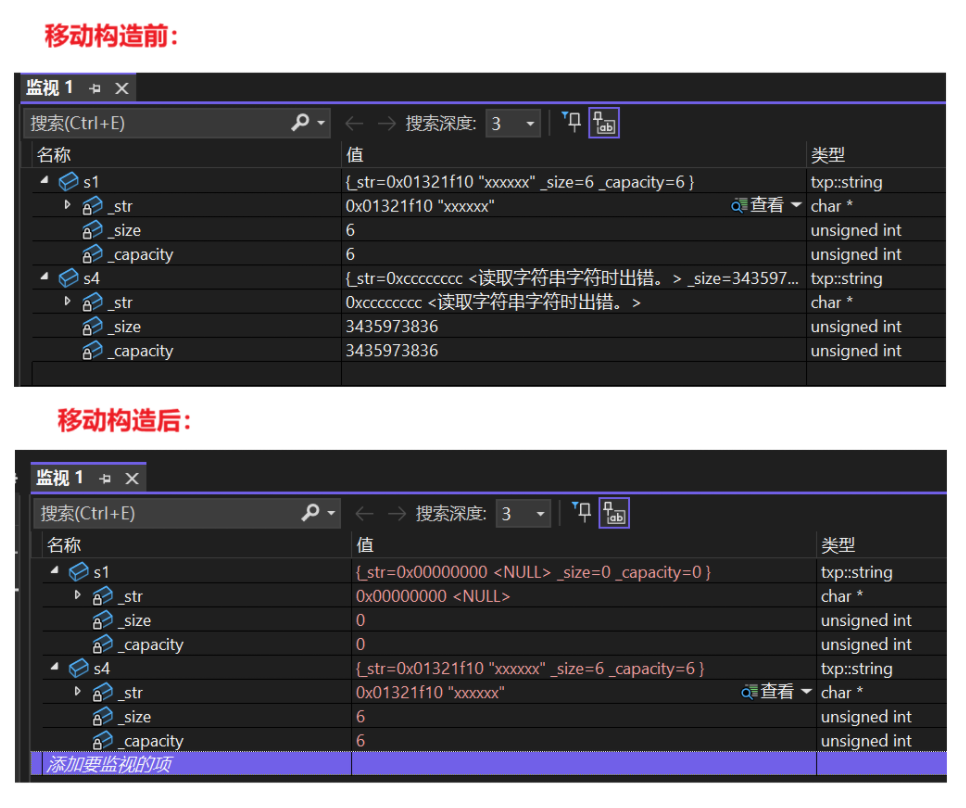
- 然后我們先看一下將s1進行移動構造的前后結果:
- 很明顯,s1的資源被轉移,并且自身變為空,跟被銷毀了沒什么兩樣(注意沒有立即調用析構)。所以對于將左值強轉成右值進行移動構造的情況中,我們需要謹慎,假如不希望s1置空就不要這樣使用,當然本身就是臨時對象的就沒有這種顧慮。
- 右值引用構造的意義:就是當傳遞的參數是右值時,也就是一些臨時對象時,不需要進行拷貝之類的,直接將資源進行轉移就行,當然移動構造和移動賦值是只針對右值的,左值是去匹配普通構造和普通賦值的,這就是它的用處,專門針對右值拷貝構造和拷貝賦值的場景。
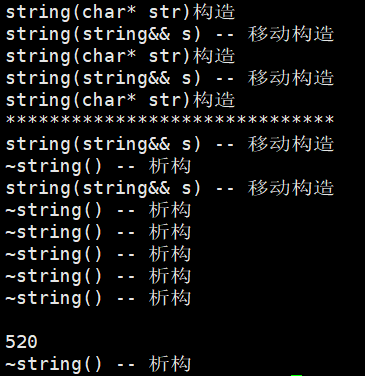
- 下面我們看在Linux下,上面代碼完全不優化的運行結果,關閉優化指令:g++ -std=c++11 test.cpp -fno-elide-constructors(其中的test.cpp換成你的文件名)
(Linux)運行結果:
- 上邊的第一個析構就是臨時對象string("111111")被移動構造后調用的析構。第二個構造也是string("111111")調用的構造,第一個移動構造是s3,第二個移動構造是s4。
3.右值引用和移動語義解決傳值返回的問題
場景1:
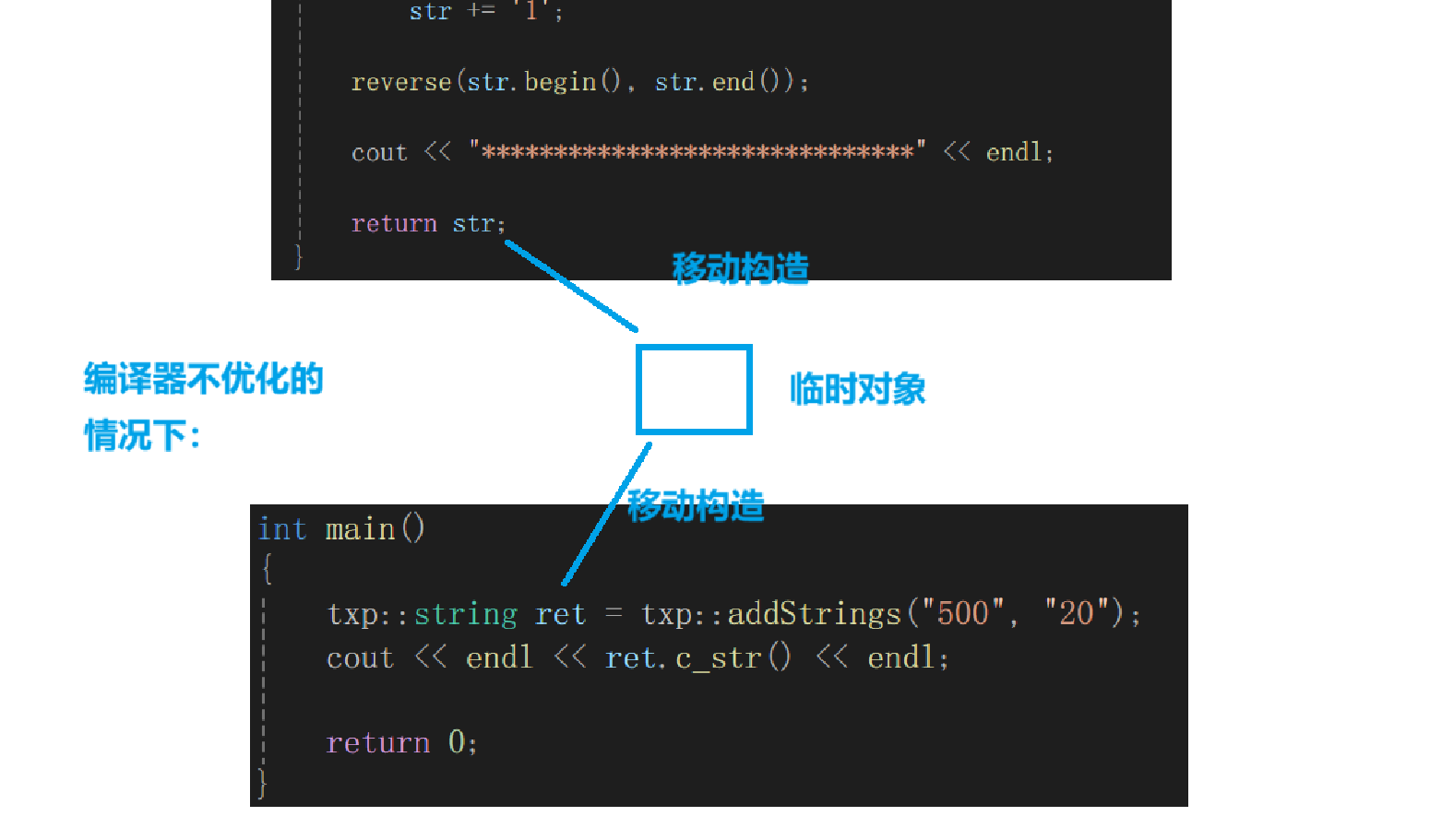
//傳值返回場景代碼(兩個數字字符串相加)string addStrings(string num1, string num2){string str;int end1 = num1.size() - 1, end2 = num2.size() - 1;int next = 0;while (end1 >= 0 || end2 >= 0){int val1 = end1 >= 0 ? num1[end1--] - '0' : 0;int val2 = end2 >= 0 ? num2[end2--] - '0' : 0;int ret = val1 + val2 + next;next = ret / 10;ret = ret % 10;str += ('0' + ret);}if (next == 1)str += '1';reverse(str.begin(), str.end());cout << "******************************" << endl;return str;}int main()
{txp::string ret = txp::addStrings("500", "20");cout << endl << ret.c_str() << endl;return 0;
}(Linux無優化)運行結果:
- 首先,虛線上面兩組 構造+移動構造 是"500"和"20"傳值給形參時進行的構造。剩余一個構造是str的構造。
- 虛線下面的情況我們看下面這張圖:
- 下面我們注重解釋移動構造的作用:
- (注意此時討論的都是編譯器不優化的情況下)因為此時已經走到addStrings函數的末尾了,需要傳值返回,傳值方法是會產生臨時對象的,為啥有臨時對象呢,因為函數結束局部對象都會銷毀,所以需要臨時對象來儲存函數的返回結果,這個臨時對象需要被構造,假如我們沒有實現移動構造,而只是實現了拷貝構造,那么這里的兩次移動構造就都是拷貝構造了,想一想,如果數據量非常大編譯器又沒有優化,兩次拷貝構造的消耗是非常大的,所以,當我們實現移動構造后,str因為是即將消亡的值,是被當做右值處理的,那么臨時對象的構造就會調用移動構造,同理,這個臨時對象本身也即將消亡,也是右值,所以ret調用的也是移動構造,這就是虛線下面兩次移動構造的由來。
- 移動構造本質就是交換底層指針嘛,所以基本沒什么性能消耗,兩次移動構造中間的析構則是str的析構。剩下的析構調用就是函數內部的以及臨時對象的,最后一個析構就是ret的。
- 所以經過這個場景我們應該能理解右值引用和移動構造最主要的意義——提效,就是提升效率。
- 注意上面的str嚴格意義上應該是左值,但它又處于函數內部又即將消亡,編譯器就將它識別為右值。
關于編譯器的優化:
- 因為C++11出來的比較晚,所以對于上面這樣類似的傳值返回場景等,早期的巨大性能消耗迫使編譯器進行了優化,比如上面的代碼在vs2022下的運行結果如下:
- 因為vs2022的極致優化,很多需要連續拷貝構造的場景都被優化成直接構造。具體優化細節這里就不贅述了,前面類和對象的文章應該有提及到。
- 那么既然編譯器有優化,那我們為啥還要寫移動構造和移動賦值呢?這就是需要考慮到代碼的泛用性,換句話說你不能指望每個編譯環境都有優化,另外,最主要的是有些場景會干擾編譯器的優化,比如下面這個場景:
場景2:
int main()
{txp::string ret;ret = txp::addStrings("500", "20");cout << endl << ret.c_str() << endl;return 0;
}
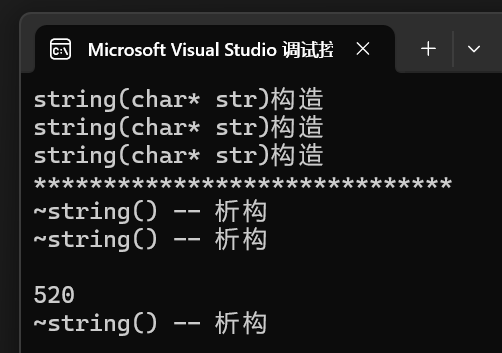
- 其他什么都不變,僅僅只是將ret先定義再賦值,這時編譯器就不得不調用拷貝賦值了,我們看vs2022的運行結果:
運行結果(VS2022):
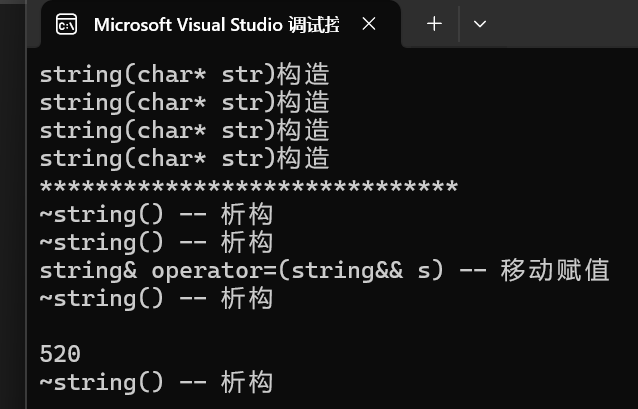
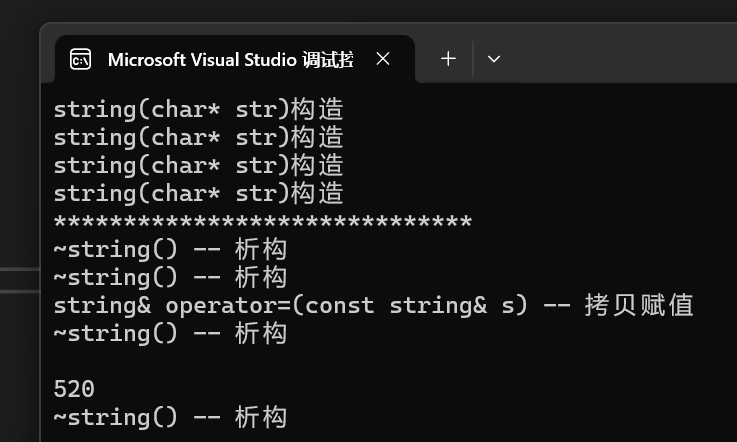
- 很明顯,編譯器是用到了移動賦值,這還是極致優化的結果,依舊調用了移動賦值,那么當我們沒有實現移動賦值呢?我們看下面結果:
- 很明顯,將移動賦值注釋后,調用的就是拷貝賦值,那么假如數據量非常大時,一次拷貝賦值的代價就很大了,所以你說有沒有必要學習右值引用和移動語義,答案是肯定的,效率的提升是很明顯的。
- 總結就是一句話:不管編譯器有沒有優化,我們移動構造和移動賦值的效率依然很高。
最后注意主要是涉及深拷貝的情況,才有移動構造和移動賦值,因為淺拷貝本身消耗并不大
五、右值引用和移動語義在傳參中的提效
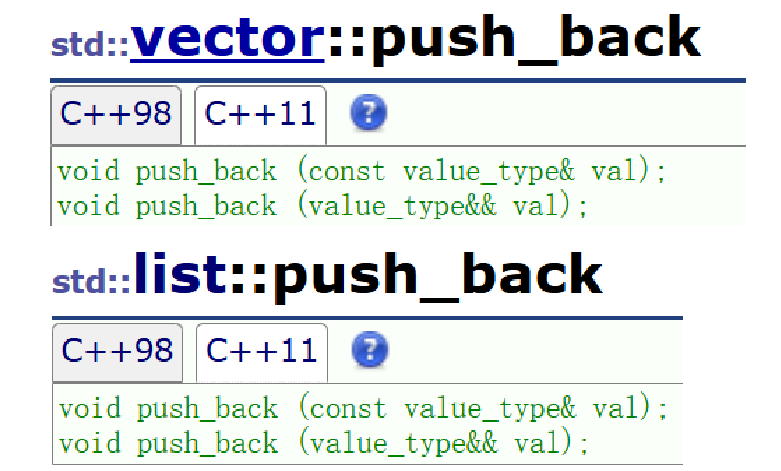
- 查看STL文檔我們發現C++11以后很多容器的push和insert系列的接口都增加的右值引用版本。
- 當實參是一個左值時,容器內部繼續調用拷貝構造進行拷貝,將對象拷貝到容器空間中的對象。
- 當實參是一個右值,容器內部則調用移動構造,右值對象的資源到容器空間的對象上。
我們使用標準庫中的list進行傳參演示:
#define _CRT_SECURE_NO_WARNINGS 1
#include <utility>
#include <list>
#include "mystring.h"int main()
{list<txp::string> lt;txp::string s1("xxxxxxxxxxx");lt.push_back(s1);cout << "*************************************" << endl;lt.push_back(txp::string("11111111"));cout << "*************************************" << endl;lt.push_back("22222222");cout << "*************************************" << endl;lt.push_back(move(s1));cout << "*************************************" << endl;return 0;
}運行結果:
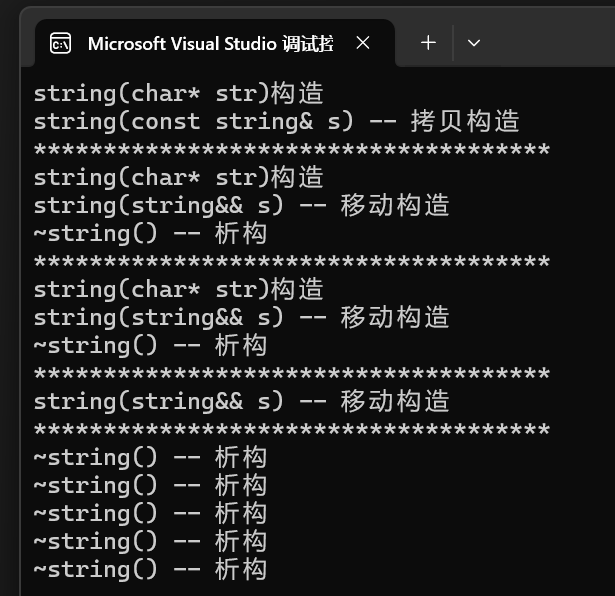
- 運行結果很好的展示了,當傳參的參數為右值時,就會調用移動構造為list中的元素進行構造。當傳參為左值也就是第一個時,調用的就是拷貝構造,所以在傳參這一塊,右值明顯效率高。
- 接下來,我們把之前模擬實現的txp::list拷貝過來,當然以下實現的是精簡版的,沒有用上的功能都閹割了,然后我們自己實現右值引用版本的push_back和insert,看看其中具體的實現過程,加深理解。
mylist.h:先將完整版展示出來,再具體談實現過程
#pragma once
#include <utility>
using namespace std;namespace txp
{//鏈表節點template<class T>struct ListNode{ListNode<T>* _next;ListNode<T>* _prev;T _data;//普通節點構造ListNode(const T& data = T()):_next(nullptr), _prev(nullptr), _data(data){}//移動構造ListNode(T&& data):_next(nullptr), _prev(nullptr), _data(move(data)){}};//鏈表迭代器template<class T, class Ref, class Ptr>struct ListIterator{typedef ListNode<T> Node;typedef ListIterator<T, Ref, Ptr> Self;Node* _node;ListIterator(Node* node):_node(node){}Self& operator++(){_node = _node->_next;return *this;}Ref operator*(){return _node->_data;}bool operator!=(const Self& it){return _node != it._node;}};//鏈表template<class T>class list{typedef ListNode<T> Node;public:typedef ListIterator<T, T&, T*> iterator;typedef ListIterator<T, const T&, const T*> const_iterator;iterator begin(){return iterator(_head->_next);}iterator end(){return iterator(_head);}//初始化void empty_init(){_head = new Node();//哨兵位_head->_next = _head;_head->_prev = _head;}//構造list(){empty_init();}//普通尾插void push_back(const T& x){insert(end(), x);}//右值引用版尾插void push_back(T&& x){insert(end(), move(x));}//普通插入iterator insert(iterator pos, const T& x){Node* cur = pos._node;Node* newnode = new Node(x);Node* prev = cur->_prev;// prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);}//右值引用版插入iterator insert(iterator pos, T && x){Node* cur = pos._node;Node* newnode = new Node(move(x));Node* prev = cur->_prev;// prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);}private:Node* _head;};
}現在,我們將具體新增的代碼展示出來:
namespace txp
{//鏈表節點template<class T>struct ListNode{//...//移動構造ListNode(T&& data):_next(nullptr), _prev(nullptr), _data(move(data)){}};//... //鏈表template<class T>class list{//...//普通尾插void push_back(const T& x){insert(end(), x);}//右值引用版尾插void push_back(T&& x){insert(end(), move(x));}//普通插入iterator insert(iterator pos, const T& x){Node* cur = pos._node;Node* newnode = new Node(x);Node* prev = cur->_prev;// prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);}//右值引用版插入iterator insert(iterator pos, T && x){Node* cur = pos._node;Node* newnode = new Node(move(x));Node* prev = cur->_prev;// prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);}private:Node* _head;};
}
- 首先,想要實現右值引用版的push_back,那就必須新增一個參數為右值引用版本?void push_back(T&& x)
- 然后就是第一個需要注意的點,因為push_back是復用insert進行尾插的,所以insert也必須新增一個右值引用版本的?iterator insert(iterator pos, T&& x),這還不是需要注意的點,需要注意的是push_bcak(T&& x)中的x雖然是右值引用的別名,但x本身還是左值屬性,想要傳參給右值引用版本的insert就必須使用move進行強轉。
- 然后是第二個需要注意的點,因為insert中需要創建新節點,也就是 new Node(x),new 會調用Node的構造函數,Node就是ListNode,所以我們需要實現ListNode的右值引用版本的構造函數,也就是實現移動構造ListNode(T&& data)
- 然后這個 x 也是insert形參中右值引用的別名,這個x本身屬性也是左值,所以第三點需要注意將右值引用版的insert中的 new Node(x) ->改為 new Node(move(x)),這樣才能調用到移動構造。
- 最后還有第四點需要注意,ListNode(T&& data)的移動構造中的形參 date,右值引用別名date的屬性是左值,ListNode最終是需要調用T類型的移動構造,所以初始化列表中_data(data)想調用T類型的移動構造必須傳右值才能匹配T類型的移動構造,當然前提是T類型支持移動構造,所以_data(data)->改為_data(move(data))
- 這就是右值引用版本的push_back和insert的實現,有點復雜,但只需要記住一點,就是右值引用變量的別名屬性是左值,往下面傳遞時想要保證右值屬性并匹配右值引用參數,就需要使用move進行強制轉換。
使用我們自己實現的list和自己的string進行演示:
#define _CRT_SECURE_NO_WARNINGS 1
#include <utility>
#include "mylist.h"
#include "mystring.h"int main()
{txp::list<txp::string> lt;txp::string s1("xxxxxxxxxxx");lt.push_back(s1);cout << "*************************************" << endl;lt.push_back(txp::string("11111111"));cout << "*************************************" << endl;lt.push_back("22222222");cout << "*************************************" << endl;lt.push_back(move(s1));cout << "*************************************" << endl;return 0;
}運行結果:
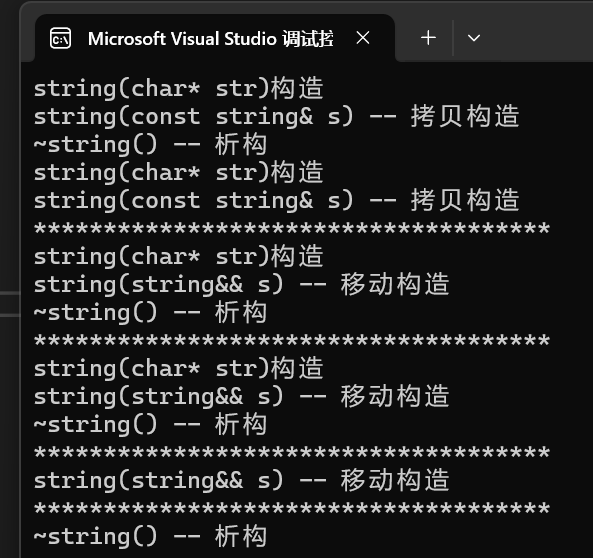
- 注意開頭的構造、拷貝構造、析構,是list構造函數調用初始化函數empty_init中new Node()創建哨兵位所進行的操作。new Node()需要調用ListNode的構造,因為是無參,所以ListNode使用缺省參數T(),T()就會調用string的構造,然后_date(date)就是涉及拷貝構造,最后T()構造的臨時對象析構。這就是開頭的三個調用操作。
- 其余的和標準庫中的list調用一樣,就不細說了。
六、引用折疊和完美轉發
在學習可變參數模板前,我們需要了解一些機制
1.引用折疊
- C++中不能直接定義引用的引用如 int& && r = i;,這樣寫會直接報錯。
- 但是通過模板或typedef中的類型操作可以構成引用的引用,這就是引用折疊。
- 通過模板或typedef中的類型操作可以構成引用的引用時,這時C++11給出了一個引用折疊的規則:右值引用的右值引用折疊成右值引用,所有其他組合均折疊成左值引用。


這個引用折疊的規則我們先通過typedef類型操作展示一下:
int main()
{typedef int& lref;typedef int&& rref;int n = 0;//引用折疊lref& r1 = n; //r1的類型是 int&lref&& r2 = n; //r2的類型是 int&rref& r3 = n; //r3的類型是 int&rref&& r4 = 1; //r4的類型是 int&&return 0;
}
- 很明顯,對于左值引用lref,lref加上左值引用還是左值引用,lref加上右值引用還是左值引用,總結:左值引用加上任何引用都是左值引用。
- 對于右值引用rref,rref加上左值引用是左值引用,rref加上右值引用則是右值引用,總結:右值引用只有加上右值引用才折疊為右值引用,加上左值引用就是左值引用,這一點和左值引用的總結相呼應。
- 以上就是引用的折疊規則了。
現在我們繼續看在函數模板的類型操作下的引用折疊:
#include <iostream>
using namespace std;//左值引用
template<class T>
void f1(T& x)
{}//萬能引用
template<class T>
void f2(T&& x)
{}int main()
{int n = 0;f1<int>(n);//沒有折疊->實例化為void f1(int& x)//f1(0);報錯f1<int&>(n);//折疊->實例化為void f1(int& x);//f1<int&>(0);報錯f1<int&&>(n);//折疊->實例化為void f1(int& x);//f1<int&&>(0);報錯//折疊->實例化為void f1(const int& x);f1<const int&>(n);f1<const int&>(0);//折疊->實例化為void f1(const int& x);f1<const int&&>(n);f1<const int&&>(0);//------------------------------------f2(n);f2<int>(0);//沒有折疊->實例化為void f2(int&& x);f2<int&>(n);//折疊->實例化為void f2(int& x);f2(0);f2(n);f2<int&&>(0);//折疊->實例化為void f2(int&& x);//折疊->實例化為void f2(const int& x);f1<const int&>(n);f1<const int&>(0);f2(n);f2<const int&&>(0);//折疊->實例化為void f2(const int&& x);return 0;
}
- 很明顯,當函數模板參數為引用類型時,只要傳遞的參數是引用類型的,就會觸發引用折疊,折疊的規律依舊是:右值引用的右值引用折疊成右值引用,所有其他組合均折疊成左值引用
- 函數模板void f1(T& x),因為本身是左值引用,所以傳什么都會變為左值引用。
- 但是f2不一樣,就是函數模板void f2(T&& x),為什么給它標注為萬能引用,因為它接收左值引用就是左值引用,它接收右值引用就是右值引用。當然正常接收右值也是右值引用。
- 當然,以上例子都是手動實例化,現實中也不會這樣傳參,接下來我們讓萬能函數模板自動實例化,觀察萬能引用的一些現象。

萬能引用函數模板:
#include <iostream>
#include <utility>
using namespace std;template<class T>
void Function(T&& t)
{int a = 0;T x = a;x++;//觀察地址判斷x是不是a的引用別名cout << &a << endl;cout << &x << endl << endl;
}int main()
{//10是右值,推導出T為int,模版實例化為void Function(int&& t)Function(10);//打印出的地址不同,佐證了T為int類型//a是左值,推導出T為int&,模板實例化為void Function(int& t)int a;Function(a);//打印出的地址相同,佐證了T為int&類型//move(a)是右值,推導出T為int,模板實例化為void Function(int&& t)Function(move(a));//打印出的地址不同,佐證了T為int類型return 0;
}運行結果:
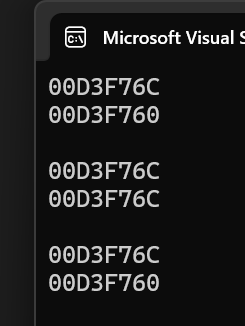
- 結合運行結果以及注釋,我們可以發現一個問題,就是傳右值給萬能引用模板,雖然最終形參類型為右值引用,但是T本身卻是int類型。
- 然后傳左值給萬能引用模板是,T本身會變為int&類型。當然形參類型依舊是左值引用。
- 我們接著觀察const類型的引用,然后再總結。
const類型參數傳參給萬能引用函數模板:
#include <iostream>
#include <utility>
using namespace std;template<class T>
void Function(T&& t)
{int a = 0;T x = a;//x++; const無法修改//觀察地址判斷x是不是a的引用別名cout << &a << endl;cout << &x << endl << endl;
}int main()
{//b是const左值,推導出T為const int&,模板實例化為void Function(const int& t)const int b = 1;//因為T是const修飾,所以不能x++Function(b);//然后地址依舊相同,佐證T為const int&類型//move(b)是const右值,推導出T為const int,模板實例化為void Function(const int&& t)Function(move(b));//同樣,x不能修改,地址不同,佐證T為const int類型return 0;
}運行結果:
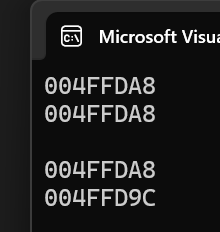
- 除了多了個const修飾,規律和上面一樣。
- 總結:萬能引用模板傳參時( template<class T>void Function(T&& t) )
- 當傳遞左值時,T會識別為數據類型的左值引用,傳遞const類型時,T會識別為const數據類型的左值引用。
- 當傳遞右值時,T會識別為數據類型本身的類型,傳遞const類型時,T會識別為const數據類型本身的類型。
- 這一點是新發現,也是一個容易混淆的點,至于為啥這樣規定應該是語法規定,我們不用管。然后形參的類型依舊參考引用折疊的規律。
2.完美轉發
以上引用折疊就是為了引出萬能引用,但是萬能引用存在一些問題,比如下面這種情況:
#include <iostream>
#include <utility>
using namespace std;void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const右值引用" << endl; }//萬能引用
template<class T>
void Function(T&& t)
{Fun(t);
}int main()
{//10是右值,模版實例化為void Function(int&& t)Function(10);//打印出的地址不同,佐證了T為int類型//a是左值,模板實例化為void Function(int& t)int a;Function(a);//move(a)是右值,模板實例化為void Function(int&& t)Function(move(a));//b是const左值,模板實例化為void Function(const int& t)const int b = 1;Function(b);//move(b)是const右值,模板實例化為void Function(const int&& t)Function(move(b));return 0;
}運行結果:
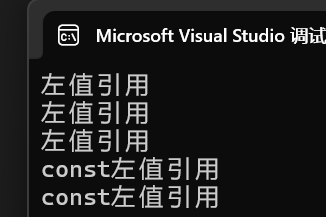
萬能引用存在的問題:
- 以上出現的問題就是,Function函數的形參 t 無論是左值引用還是右值引用,它本身的屬性就是左值,這樣往Fun傳參時就只會匹配左值。而我們想要達到的效果是自動匹配Fun函數,t是左值匹配左值引用的Fun,t是右值匹配右值引用的Fun。
- 你可能會覺得move似乎能解決問題,但當我們將Fun(t)變為Fun(move(t))后,運行結果:
- 也就是說move是不區分左值右值的,它只是強制轉換為右值,所以這里并不能解決問題,我們需要的是傳參給Fun時?t 依舊保持它類型的屬性。
- 這時候,完美轉發就是解決這個問題的關鍵。
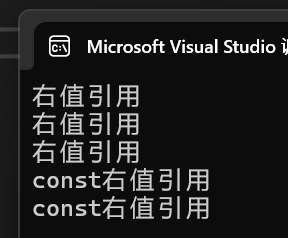
完美轉發:forward
- 完美轉發forward本質是一個函數模板,他主要還是通過引用折疊的方式實現,下面示例中傳遞給Function的實參是右值,T被推導為int,沒有折疊,forward內部 t 被強轉為右值引用返回;傳遞給 Function的實參是左值,T被推導為int&,引用折疊為左值引用,forward內部 t 被強轉為左值引用返回。
- 完美轉換底層依舊是強制類型轉換,觀察上面forward函數模板,左值匹配第一個,右值則匹配第二個。
- forward和move一樣,都是<utility>頭文件中的函數,但是不同的是,forward使用時需要手動實例化:

//萬能引用
template<class T>
void Function(T&& t)
{//forward完美轉發Fun(forward<T>(t));
}運行結果:
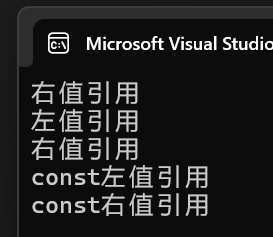
- 使用完美轉發后,就能達到自動匹配重載函數的效果。
七、可變參數模板
- C++11支持可變參數模板,也就是說支持可變數量參數的函數模板和類模板,可變數目的參數被稱為參數包,存在兩種參數包:模板參數包,表示零或多個模板參數;函數參數包,表示零或多個函數參數。
- 簡單來說,C++11之前我們寫模板是不確定類型但參數數量確定,現在有了可變參數模板,那么我們也可以在參數數量不確定的情況下去寫函數模板或者類模板。
- 因為可變參數的函數模板使用較多,我們來看其語法:
- template<class ...Args> void Func(Args... args) {}
- template<class ...Args> void Func(Args&... args) {}
- template<class ...Args> void Func(Args&&... args) {}
- 其中藍色部分叫模板參數包,綠色部分叫函數參數包。
- 我們用省略號來指出一個模板參數或函數參數的表示?個包,在模板參數列表中,class...或 typename...指出接下來的參數表示零或多個類型列表;在函數參數列表中,類型名后面跟...指出接下來表示零或多個形參對象列表;函數參數包可以用左值引用或右值引用表示,跟前面普通模板一樣,每個參數實例化時遵循引用折疊規則。
- 這里我們可以使用sizeof...運算符去計算參數包中參數的個數。
#include <iostream>
using namespace std;//可變參數模板
template<class ...Args>
void Print(Args&&... args)
{cout << sizeof...(args) << endl;
}int main()
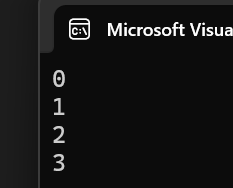
{double x = 2.2;Print(); //保留有0個模板參數Print(1); //包里有1個模板參數Print(1, string("xxxxx")); //包里有2個模板參數Print(1.1, string("xxxx"), x); //包里有3個模板參數return 0;
}運行結果:
1.可變參數模板的原理
- 可變參數模板的原理跟模板類似,本質還是去實例化對應類型和個數的多個函數。
- 比如上面演示代碼中,可變參數模板本質上實例化出了以下四個函數:
//原理1:編譯本質這里會結合引用折疊規則實例化出以下四個函數 void Print(); void Print(int&& arg1); void Print(int&& arg1, string&& arg2); void Print(double&& arg1, string&& arg2, double& arg3);
- 沒有可變參數模板之前,想要達到上面的效果就得寫四個函數模板:
// 原理2:更本質去看沒有可變參數模板, // 我們實現出這樣的多個函數模板才能支持這里的功能, // 有了可變參數模板,我們進?步被解放, // 他是類型泛化基礎上疊加數量變化,讓我們泛型編程更靈活。 void Print();template <class T1> void Print(T1&& arg1);template <class T1, class T2> void Print(T1 && arg1, T2 && arg2);template <class T1, class T2, class T3> void Print(T1&& arg1, T2&& arg2, T3&& arg3);
- 現在有了可變參數模板,面對有多參數類型的函數就很方便了,換句話說,讓我們泛型編程更靈活。
2.包擴展
可變參數模板雖然好用,但是我們怎么拿到具體的參數值呢,這就是包擴展該做的事
- 對于一個參數包,我們除了能計算他的參數個數,我們能做的唯一的事情就是擴展它,當擴展一個包時,我們還要提供用于每個擴展元素的模式,擴展一個包就是將它分解為構成的元素,對每個元素應用模式,獲得擴展后的列表。我們通過在模式的右邊放一個省略號(...)來觸發擴展操作。
- 注意:我們不能把函數參數包理解為一個數組然后用[ ]去取參數,這是錯誤的。第一,C++還么有存儲不同類型的數組。第二,就算有,模板也是編譯期間解析,而[ ]這種是運行時獲取和解析,所以也不支持這樣使用。
- 以下是通過遞歸函數拿到參數包中參數的包擴展:
第一種包擴展方式:編譯期遞歸推導的包擴展
#include <iostream>
using namespace std;//遞歸的終止函數,當參數包是0個時匹配這個函數
void ShowList()
{cout << endl;
}template<class T,class ...Args>
void ShowList(T x, Args... args)
{//args是N個參數的參數包//調用ShowList,參數包的第一個傳給x,剩下的N-1個傳給第二個參數包cout << x << " ";ShowList(args...);
}//可變參數模板
template<class ...Args>
void Print(Args&&... args)
{ShowList(args...);//注意傳參時(...)是放在參數包后面
}int main()
{double x = 2.2; Print(1); Print(1, string("xxxxx")); Print(1.1, string("xxxx"), x);return 0;
}運行結果:
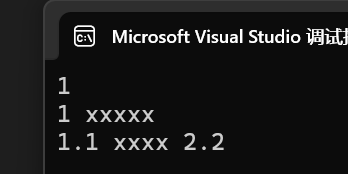
- 首先需要注意的是,參數包args往其他函數傳遞時三個點(...)是放在參數包的后面。
- 第二個需要注意的是,你可能會疑惑為什么要寫一個ShowList()的空函數來終止遞歸,而不是使用 if(sizeof...(args) == 0){return;} 判斷參數包個數是否為0來終止遞歸,我們以前終止遞歸都是使用if判斷。首先這里比較特殊,涉及模板實例化和遞歸以及可變參數,我們觀察下圖,模板實例化是在編譯期完成,所以編譯期就會在最后一個函數中生成ShowList()的代碼需要進行調用,但此時我們沒有實現ShowList(),只實現了if判斷,而if判斷是在運行時進行判斷,所以無法在調用ShowList()前終止函數調用,最后就是編譯器認為調用不到ShowList(),存在語法錯誤。
- 底層的實現細節如下圖所示:
- 這張圖中就展示了編譯時的遞歸推導過程,編譯期底層就實例化出了上面四種函數。可以清晰看到右上角函數生成了ShowList()的代碼需要進行調用。

第二種包擴展方式:直接將參數包依次展開依次作為實參給一個函數去處理。
#include <iostream>
using namespace std;//獲取每個參數
template<class T>
const T& GetArgs(const T& x)
{cout << x << " ";return x;
}//可變參數模板
template<class ...Args>
void Arguments(Args... args)
{cout << endl;
}//可變參數模板
template<class ...Args>
void Print(Args&&... args)
{//利用參數的特殊性,//在傳參前調用GetArgs將每個參數打印出來Arguments(GetArgs(args)...);
}int main()
{double x = 2.2;Print(1);Print(1, string("xxxxx"));Print(1.1, string("xxxx"), x);return 0;
}運行結果:
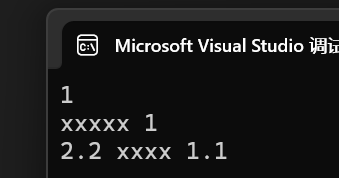
- 初次見到這種包擴展的方式確實抽象,我們將模版實例化,以Print(1, string("xxxx"), x) 為例:
// 本質可以理解為編譯器編譯時,包的擴展模式 // 將上面的函數模板擴展實例化為下面的函數 // 是不是很抽象,C++11以后,只能說委員會的大佬設計語法思維跳躍得太厲害 void Print(int x, string y, double z) {Arguments(GetArgs(x), GetArgs(y), GetArgs(z)); }
- 將模板實例化后就應該豁然開朗了,相當于在傳參前,將每個參數拿出去打印再放回來一樣。
3.emplace系列接口
以上的包擴展方式我們實踐中也不會那樣去使用,實踐中的使用方式就參考emplace系列接口
- C++11以后,所有的STL容器,只要有push_back接口的就增加了emplace_back接口,只要有insert接口的就增加了emplace接口。
- emplace系列接口的特點:
- 支持萬能引用,因為是函數模板的形式,所以形參的類型可以自己推導。
- 支持多參數傳遞,可變模板參數也就是參數包帶來的優勢。
- 功能上兼容push和insert系列,但是emplace還支持新玩法,假設容器為其多參數模版和萬能引用的特性,可以直接在容器空間上構造T對象。
- 下面我們來對比一下push_back和emplace_back的區別:
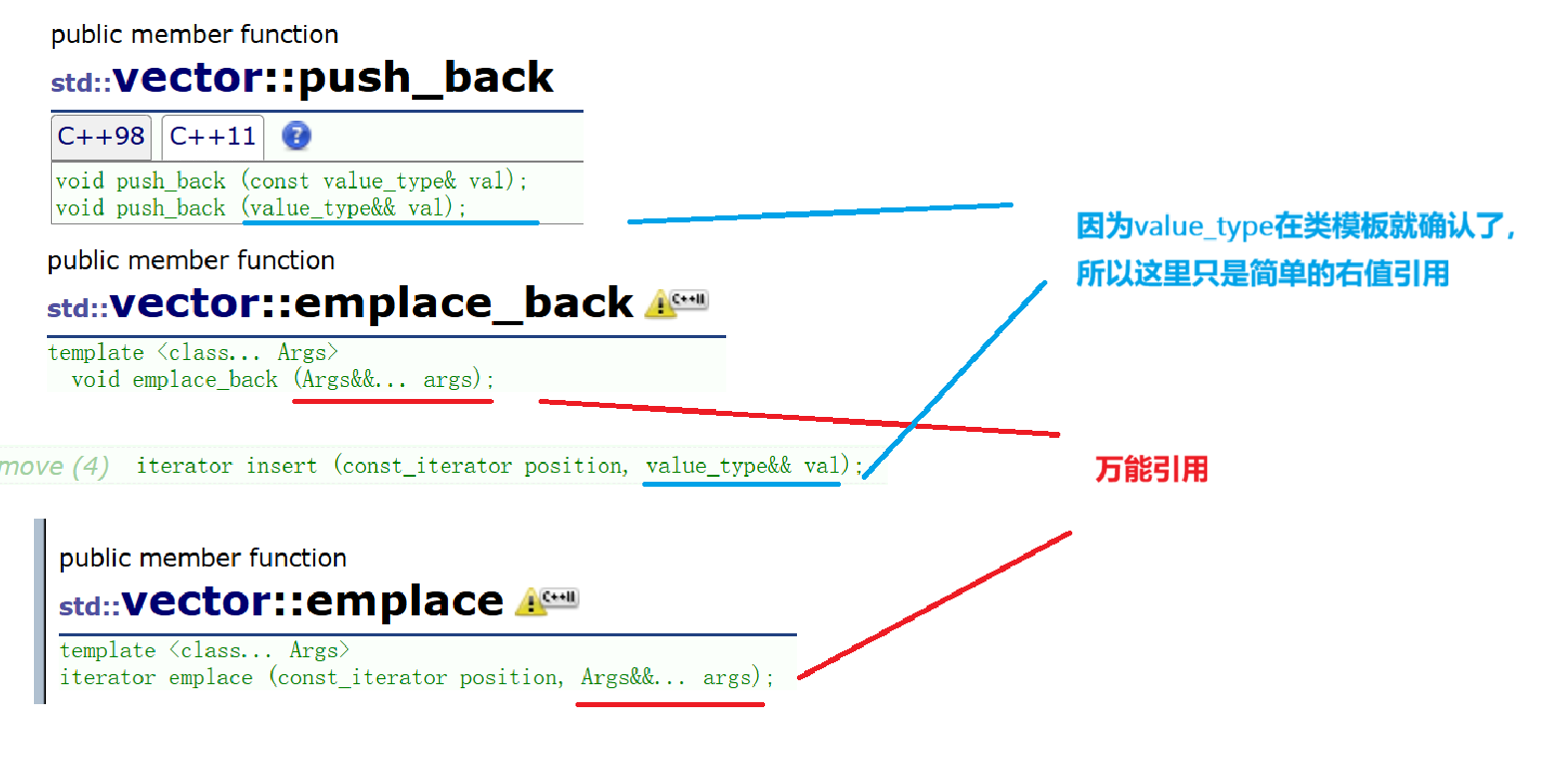
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
#include <utility>
#include <list>
#include "mystring.h"int main()
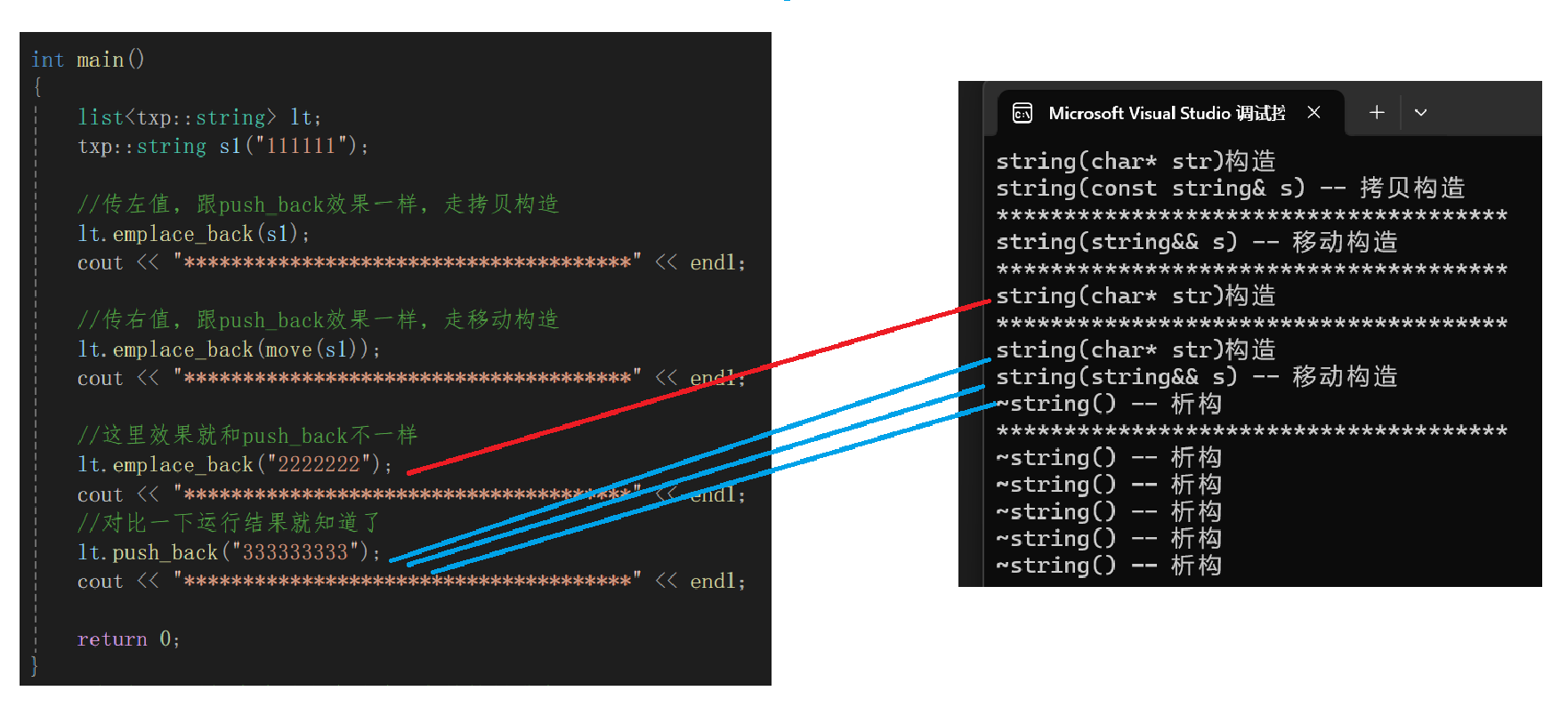
{list<txp::string> lt;txp::string s1("111111");//傳左值,跟push_back效果一樣,走拷貝構造lt.emplace_back(s1);cout << "**************************************" << endl;//傳右值,跟push_back效果一樣,走移動構造lt.emplace_back(move(s1));cout << "**************************************" << endl;//這里效果就和push_back不一樣lt.emplace_back("2222222");cout << "**************************************" << endl;//對比一下運行結果就知道了lt.push_back("333333333");cout << "**************************************" << endl;return 0;
}運行結果:
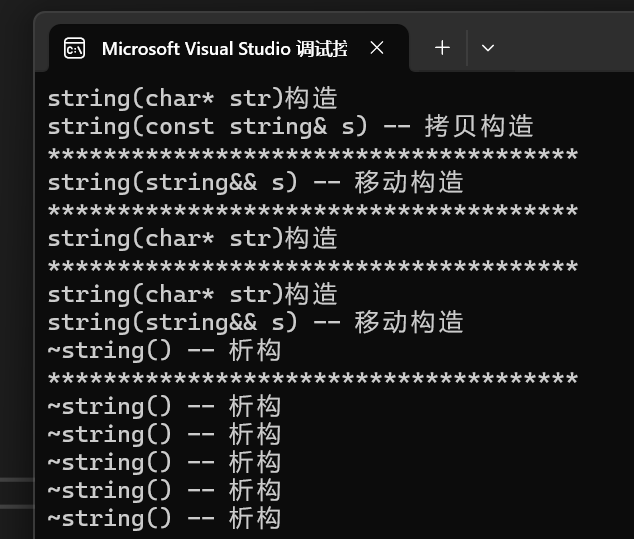
- 前面的運行結果和push_back一樣,最主要的區別就是最后一組:lt.emplace_back("2222222");
- 根據上圖就能看出,同樣是使用字符串進行傳參,emplace_back只調用了string(char* str)構造,而push_back則是先后調用了構造、移動構造、析構。push_back的調用操作我們前面都理解了。那為什么emplace_back只調用了構造呢?
- 原因就在于emplace_back的萬能引用,"222222"傳給template <class... Args>void emplace_back (Args&&... args)時,因為"222222"的右值特性,Args就能推導出其 const char* 的字符串類型,從而直接調用list中的string的構造進行直接構造。
- push_back為什么不行,"33333333"傳給void push_back (value_type&& val)時,value_type早在類模板確認參數類型時就確認value_type是txp::string類型,所以const char*并不能直接構造list中的string,而是需要"3333333"先構造臨時對象傳給 val ,再進行移動構造,最后析構臨時對象。
- 這就是emplace系列接口萬能引用的優勢,當然,push_back的移動構造效率一定低很多嗎,深拷貝上其實并沒有什么差距,反而淺拷貝上emplace系列可以直接構造的優勢明顯。
- 除此emplace還有其他優勢,比如參數包支持多參數傳遞直接構造:
多參數傳參:
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
#include <utility>
#include <list>
#include "mystring.h"int main()
{list <pair<txp::string, int>> lt;pair<txp::string, int> kv("蘋果", 1);//傳左值,跟push_back效果一樣lt.emplace_back(kv);cout << "**************************************" << endl;//傳右值,跟push_back效果一樣lt.emplace_back(move(kv));cout << "**************************************" << endl;//這里是多參數傳參lt.emplace_back("蘋果", 1);cout << "**************************************" << endl;//push_back無法直接傳參,需要{}進行隱式類型轉換lt.push_back({ "蘋果",1 });//相對應的,emplace_back是不支持使用{}進行轉換的cout << "**************************************" << endl;return 0;
}運行結果:
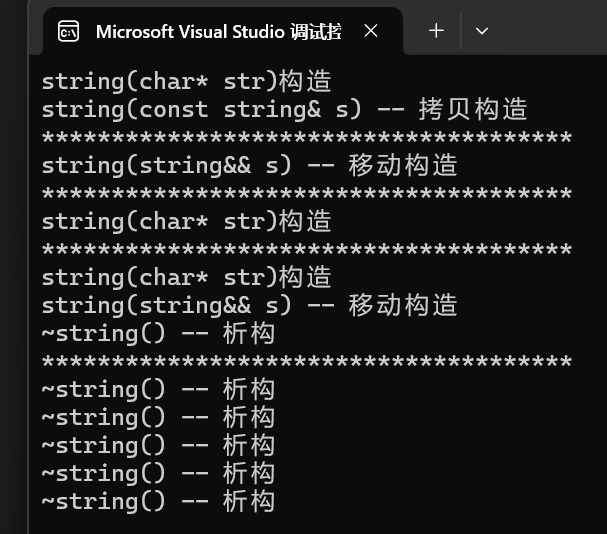
- 運行結果和上面一樣,這次的區別在于多參數構造上:
- push_back需要{}進行隱式類型轉換,轉換為pair類型再進行移動構造。
- 而emplace_back是支持多參數傳參,所以可以直接傳 "蘋果,"1",然后萬能引用就會識別出 const char* 和 int 類型進行直接構造,和前面一樣,只不多是多參數。
總結:emplace_back總體而言是更高效,推薦以后使用emplace系列替代insert和push系列
4.emplace系列接口模擬實現
namespace txp
{//鏈表節點template<class T>struct ListNode{//...//參數包構造template<class ...Args>ListNode(Args&&... args): _next(nullptr), _prev(nullptr), _data(forward<Args>(args)...){}};//...//鏈表template<class T>class list{//...//emplace_back尾插template <class... Args>void emplace_back(Args&&... args){emplace(end(), forward<Args>(args)...);//參數包往下傳需要加...}//emplace插入template <class... Args>iterator emplace(iterator pos, Args&&... args){Node* cur = pos._node;Node* newnode = new Node(forward<Args>(args)...);Node* prev = cur->_prev;// prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);}private:Node* _head;};
}
- 以上就是新增的代碼,和前面實現右值版本的push_back和insert類似。
- 首先emplace系列都是模板函數,并且是多參數模板+萬能引用。
- 那么萬能引用就會涉及到一個完美轉發的問題,需要保持它原本的屬性,所以上面三個函數中涉及到需要往下傳參的地方就需要 forward<Args> 進行完美轉發。
- 其實從實現角度看并不復雜,因為它最終還是需要調用到底層數據類型的參數包構造。
總結
????????以上就是本文的全部內容了,感謝支持!

![U8g2庫為XFP1116-07AY(128x64 OLED)實現菜單功能[ep:esp8266]](http://pic.xiahunao.cn/U8g2庫為XFP1116-07AY(128x64 OLED)實現菜單功能[ep:esp8266])
















)
